一、背景
sys高的问题往往属于底层同学更需要关注的问题,sys高的问题往往表现为几种情况,一种是瞬间的彪高,一种是持续的彪高。这篇博客里,我们总结一下常用的分析方法和分析工具的使用来排查这类sys高的问题。
二、通过mpstat配合pidstat来抓峰值
2.1 通过mpstat捕获到cpu使用率超过50%时记下来date时间
我们可以通过mpstat来周期性的抓系统的整体状态,mpstat抓取的状态比较简练,不像top那么多,所以运行期间对系统的性能影响相对小一些。
下面代码是用mpstat用来捕获到cpu使用率超过50的情况:
bash
#!/bin/bash
OUTPUT_FILE="cpu50.txt"
> "$OUTPUT_FILE"
# 无限循环
while true; do
# 获取 mpstat 的输出
output=$(mpstat 1 1 | tail -1)
# 提取 %idle 的值
idle=$(echo $output | awk '{print $12}') # %idle 在第十二列
# 计算 CPU 使用率
cpu_usage=$(echo "100 - $idle" | bc)
# 判断 CPU 使用率是否超过 50%
if (( $(echo "$cpu_usage > 50" | bc -l) )); then
echo "CPU 使用率超过 50%: $cpu_usage%" >> "$OUTPUT_FILE"
echo "Timestamp: $(date)" >> "$OUTPUT_FILE"
#else
# echo "CPU 使用率在 50% 以下: $cpu_usage%" >> "$OUTPUT_FILE"
# echo "Timestamp: $(date)" >> "$OUTPUT_FILE"
fi
# 等待一段时间再进行下一次检查(例如,5秒)
#sleep 5
done可以用mpstat -P <cpuid> <周期秒数> <周期次数>来抓取指定<cpuid>的cpu的使用率等情况。
如果周期次数不填,那就一直抓取。mpstat也可以获取系统的其他cpu状态,如%iowait,%irq等,关于iowait这个指标见之前的博客 cpu的iowait指标解释及示例-CSDN博客。
2.2 使用pidstat每隔1秒抓取一次所有任务的%usr和%sys情况
因为有 2.1 里的打印输出异常状态下的date时间。这里就不再去判断条件了,而是定期1秒去抓各个进程的%usr和%sys的情况,脚本如下:
bash
#!/bin/bash
OUTPUT_FILE="system_monitor_output.txt"
> "$OUTPUT_FILE"
INTERVAL=1
while true; do
echo "Monitoring system performance..." >> "$OUTPUT_FILE"
echo "Timestamp: $(date)" >> "$OUTPUT_FILE"
echo "====================================" >> "$OUTPUT_FILE"
echo "----- Top Output -----" >> "$OUTPUT_FILE"
top -b -n 1 | head -n 20 >> "$OUTPUT_FILE"
echo "----- pidstat Output -----" >> "$OUTPUT_FILE"
pidstat -p ALL 1 1 | grep -v "^Average" | sort -k5 -r | head -n 20 >> "$OUTPUT_FILE"
echo "------------------------------------" >> "$OUTPUT_FILE"
done上面代码里,使用pidstat -p ALL表示是抓的所有进程,后面 1 1 表示抓1秒,抓一次。
这里要特别注意,pidstat -p ALL抓的是非常短的时间,除非你去指定秒数,如果pidstat -p ALL 这样持续去执行或者睡眠一个很短的时间再立马再执行的话,它会相当消耗cpu,尤其sys的cpu。
2.2.1 pidstat可以带上-t参数来抓所有线程
执行的命令如下:
bash
pidstat -t 1 1抓取来的情况如下:
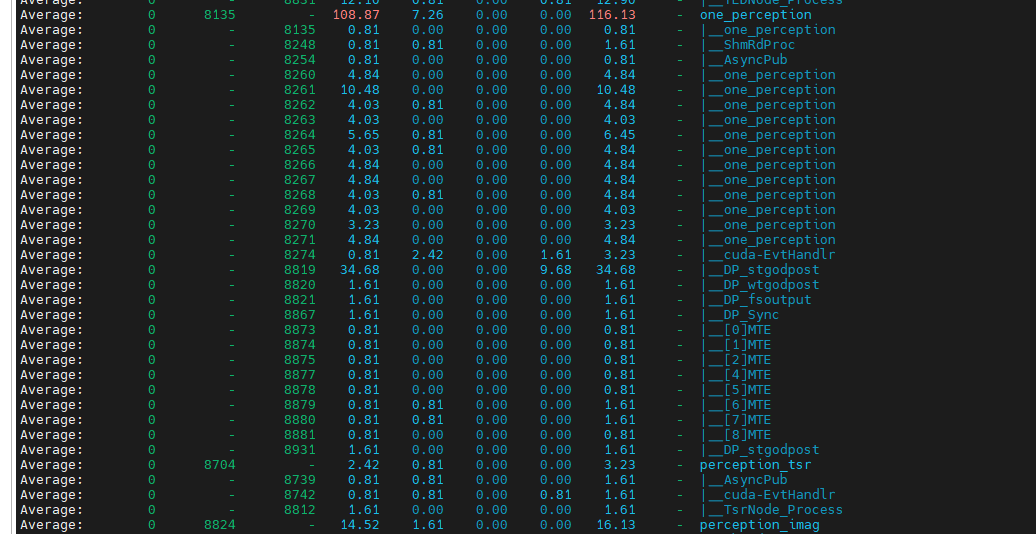
三、通过top -b -d <周期时间> -n <次数>来抓取系统状态
使用top的批处理-b选项,b表示batch mode,通过-b后面再去带上-d也就是delay这个周期时间,再加-n也就是number这个次数来抓取系统状态。
top抓取的系统状态会比较全面,还包含了uptime的系统负载信息。
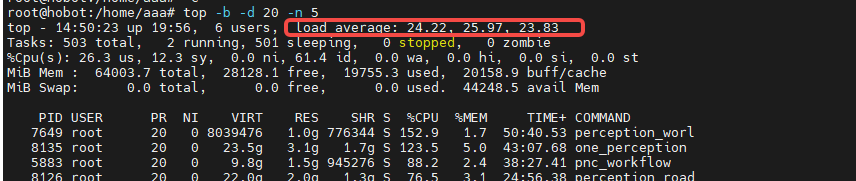

比如下面的命令就是批处理方式抓取,周期2秒,执行5次抓取:
bash
top -b -d 2 -n 53.1 top的批处理方式抓取,第一次输出会不达到设的delay的周期时间
但是,要特别注意,top这种方式-d后面设置的这个周期时间,第一次的输出并不会持续满。设了5还是设10还是20,都是很快输出第一次的,所以,我们需要忽略top -b出来的第一次输出内容。
3.2 top -p可以看执行进程的情况
top -p可以看执行进程的情况,另外再带-H,可以看指定进程里所有线程的情况
四、通过ps -eo来指定需要抓取的任务的信息
ps命令可以用来抓取任务的细节信息,里面也包含了cpu平均使用率信息,但是没有包含sys或usr的平均使用率,注意,这里说的是平均使用率,并不是最近一段时间的使用率。所以,如果要看最近一段时间的cpu使用率状态,使用ps的命令是不行的。但是可以用ps来获取任务的其他信息,如何运行在哪个核上,线程id,进程id,父进程id,优先级,cmdline,任务状态,睡眠前最后的函数等关键信息。
4.1 通过ps命令按线程抓取所有任务相关关键信息,并按cpu号排序
下面这句命令是总结的常用的关键的ps可以获取到的任务相关信息,并且用cpu号进行了按数字排序:
bash
ps -L -eo pid,tid,psr,rtprio,ni,args:48,%cpu,state,stat,lstart,etime,cls,wchan:32,flags:10 | sort -k3 -n注意上面-L表示的是抓取覆盖到每个线程,但是要注意,如果是进程里的主线程的话,抓取到的cpu使用率的信息是汇总的整个进程的总cpu使用率,如下图(使用率是130,大于了100,所以不可能是一个单个线程):

4.2 通过ps -eo配合pidstat抓取指定cpu上的sys排序后的任务运行情况
这个方法要注意,只能抓取固定的进程的情况,对于那种新创建的各种小进程导致的usr或sys的彪高的情形并不能覆盖。另外,要注意的是,启动脚本来执行的这种方式属于fork出来的进程,不会被计算到父进程的运行时间里去,要看还得看/proc/<pid>/stat下的红色框出的位置的第16和第17个值(cutime和cstime):

下面的脚本是通过ps -eo筛选出的在31核上运行的所有进程,再通过pidstat -p去得到相关的cpu使用率有关的%sys和%usr的信息,然后用sort按照sys的使用率由高到低排序:
bash
watch -n 0.1 "pidstat -p $(echo $(ps -eo pid,psr,comm | grep '^[ ]*[0-9]' | grep ' 31 ' | awk '{print $1}') | sed 's/ /,/g') 1 1 | grep -v '^Average' | sort -k6 -r | head -n 20"上面的脚本还用到了空格和,的替换为了满足pidstat -p 进程id要用,隔开别的符号不行的要求。上面脚本里的其他的细节可以自行慢慢研究。
五、使用ftrace配合perfetto来查看cpu上的调度行为
ftrace抓取sched相关的信息的脚本如下:
bash
#!/bin/bash
if [ -n "$1" ]; then
sleeptime=$1
else
echo "no input sleep time"
sleeptime=10
fi
#echo 1 > /sys/kernel/tracing/events/sched/sched_wakeup_new/enable
#echo 1 > /sys/kernel/tracing/events/sched/sched_process_exec/enable
#echo 1 > /sys/kernel/tracing/events/sched/sched_process_fork/enable
#pkill testwakeaff
echo 1 > /sys/kernel/tracing/events/sched/enable
echo 1 > /sys/kernel/tracing/events/irq/enable
#echo 1 > /sys/kernel/tracing/events/block/enable
#echo 1 > /sys/kernel/tracing/events/writeback/folio_wait_writeback/enable
echo 80960 > /sys/kernel/tracing/buffer_size_kb
echo 4096 > /sys/kernel/tracing/buffer_size_kb
echo 1 > /sys/kernel/tracing/options/record-tgid
echo 1280 > /sys/kernel/tracing/saved_cmdlines_size
echo > /sys/kernel/tracing/trace
echo 1 > /sys/kernel/tracing/tracing_on
#mkdir -p record
#sleep 10
#echo 1 > /sys/kernel/tracing/snapshot
#./testwakeaffine.out &
sleep $sleeptime
echo 0 > /sys/kernel/tracing/tracing_on
#cat /sys/kernel/tracing/snapshot > record/snapshot.txt
cat /sys/kernel/tracing/trace > trace.txt上面的脚本如下输入sleep的时间:
bash
./ftrace.sh 3脚本抓出来的内容,会自动抓到了trace.txt里了。
抓出来的内容可以放到perfetto的网页里去加载。
perfetto的网页是:
点击下图里的open trace file选上面ftrace抓出来生成的output的文件trace.txt即可:
加载之后,显示如下,可以看到,下图就是频繁执行pstree的命令,导致ftrace看到所在cpu核上特别繁忙:

上面是通过ftrace来抓,通过perfetto来显示。另外,通过perf sched record来抓,通过perf的生态来显示也是可以的,但是我感觉并没有ftrace+perfetto显示得那么直观。但是perf sched record -g -a可以抓到上下文切换的调用栈,这在某些情况下是有很大的帮助的,抓出来的内容可以通过perf script出来的内容来慢慢看慢慢分析。
但是有时候,我们会发现抓的时间可能并不是我们想要抓的时间,可能会抓不到。这时候,我们就可以通过下面第六章里的perf top的方法
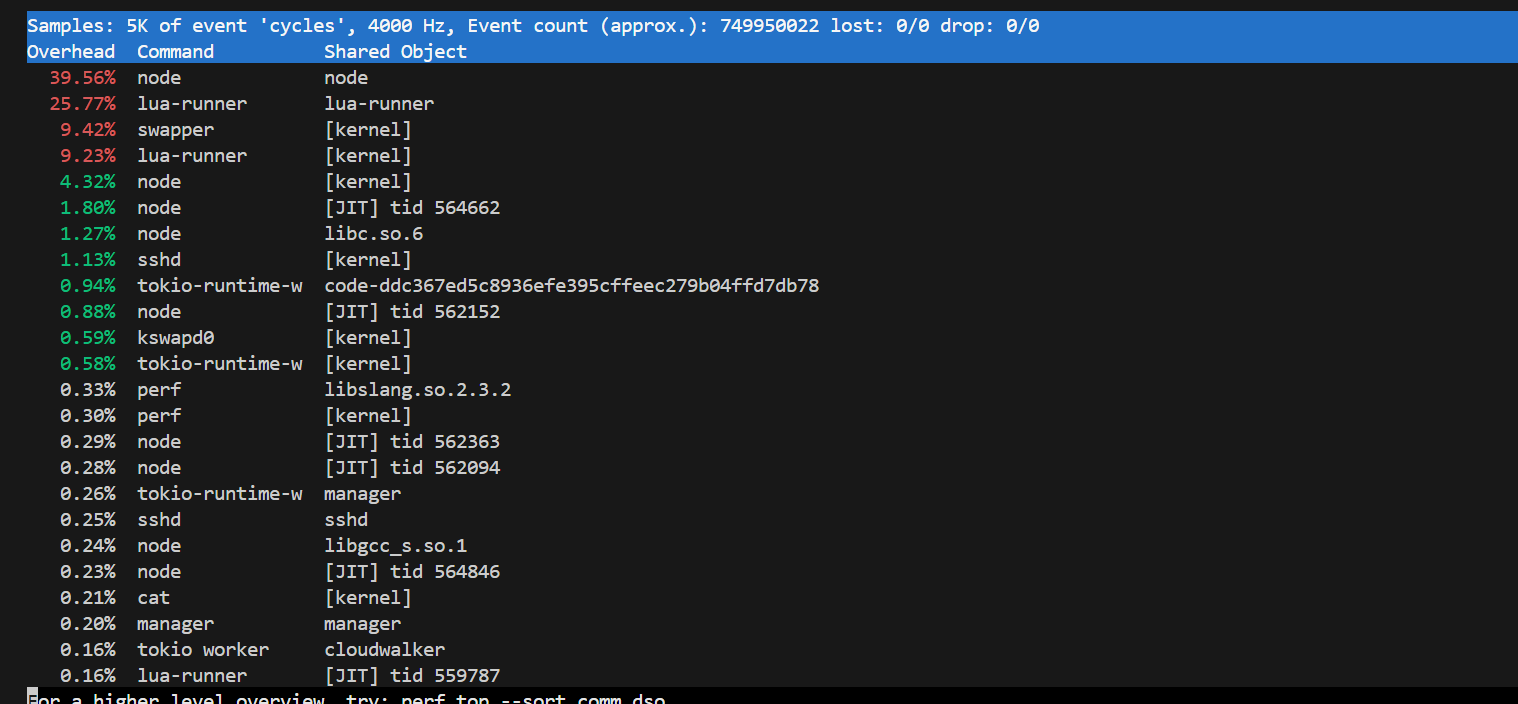
六、perf top -C <cpuid> --sort comm,dso来查看是哪个进程的哪类符号占比较高
这个perf top -C <cpuid> --sort comm,dso命令真的是一个利器,可用于发觉是哪类名字的进程用的哪类符号比较多,要注意,这里的哪类名字的进程,它是一类名字的进程,这类名字里可能会存在非常多的进程,也就是那种频繁创建和释放的进程。
抓到的情形例子如下:
七、通过bpftrace的execsnoop-bpfcc工具抓系统上新创建的进程
bpftrace是一个强大的工具集,安装方法比较简单,如下:
bash
sudo apt-get install bpfcc-tools安装后,就可以执行:
bash
sudo execsnoop-bpfcc执行后的情况如下:
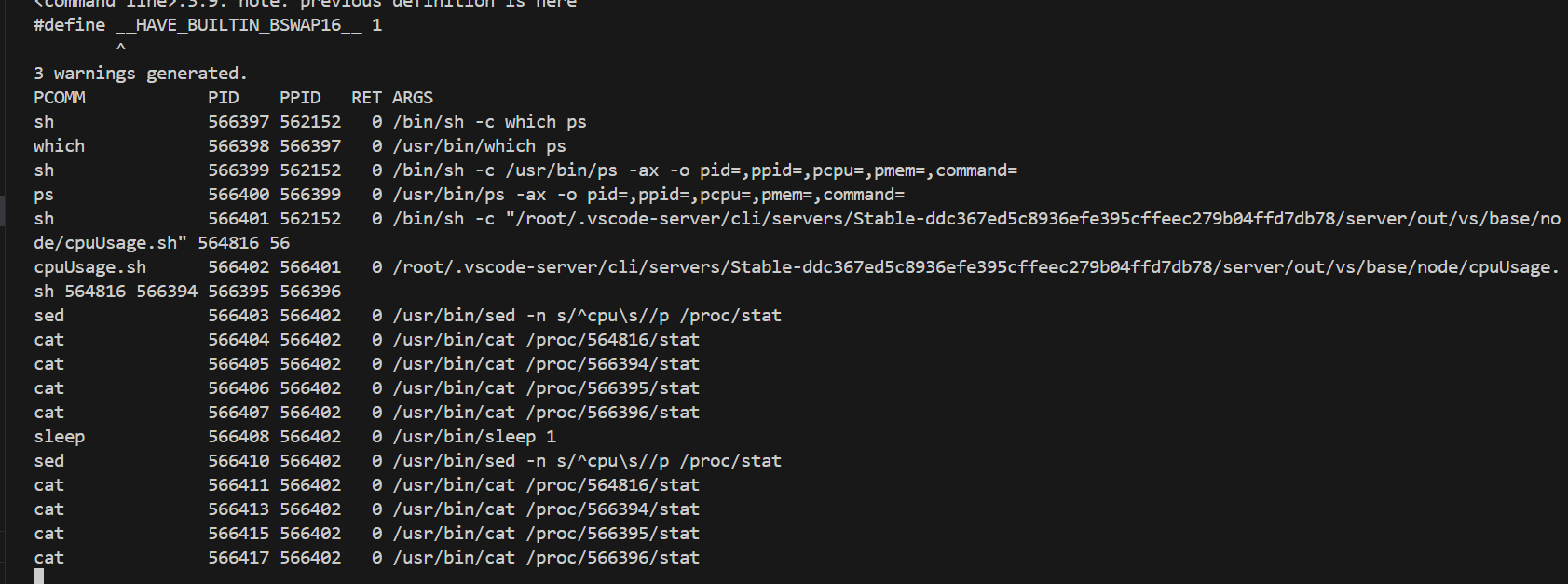
如上图显示,它可以把父进程id,和本进程id,已经本进程的cmdline给打出来,而且它是能做到不遗漏的,方便跟踪进程创建的完整链。