Hue(Hadoop User Experience)是一个用于大数据平台、数据库以及数据仓库查询的开源工具,旨在通过 Web 界面简化用户与 Hadoop 生态系统以及各种数据存储的交互。
Hue 支持的数据源包括数据库(Apache Hive、Apache Impala、MySQL、Presto、Trino、Oracle、PostgreSQL、AWS Athena、Apache Phoenix、Apache Druid、Apache Flink、ksqlDB、Google BigQuery、Materialize、Teradata、DB2、Apache Spark SQL、Azure SQL Database、MS SQL Server、Vertica、AWS Redshift、Apache Drill、SAP Sybase、SAP Hana、Apache Solr、Apache Kylin、Dask SQL、Clickhouse、Apache Kyuubi、Elastic Search、Apache Pinot DB、Snowflake、Sqlite、Google Sheets、Greenplum)、存储(HDFS、Apache Ozone、S3、Azure File Systems、GCS、HBase)、元数据(Apache Atlas)、任务调度(Apache Spark、Apache Pig、Apache Oozie、Apache YARN、Apache Sentry、Apache Knox)等。

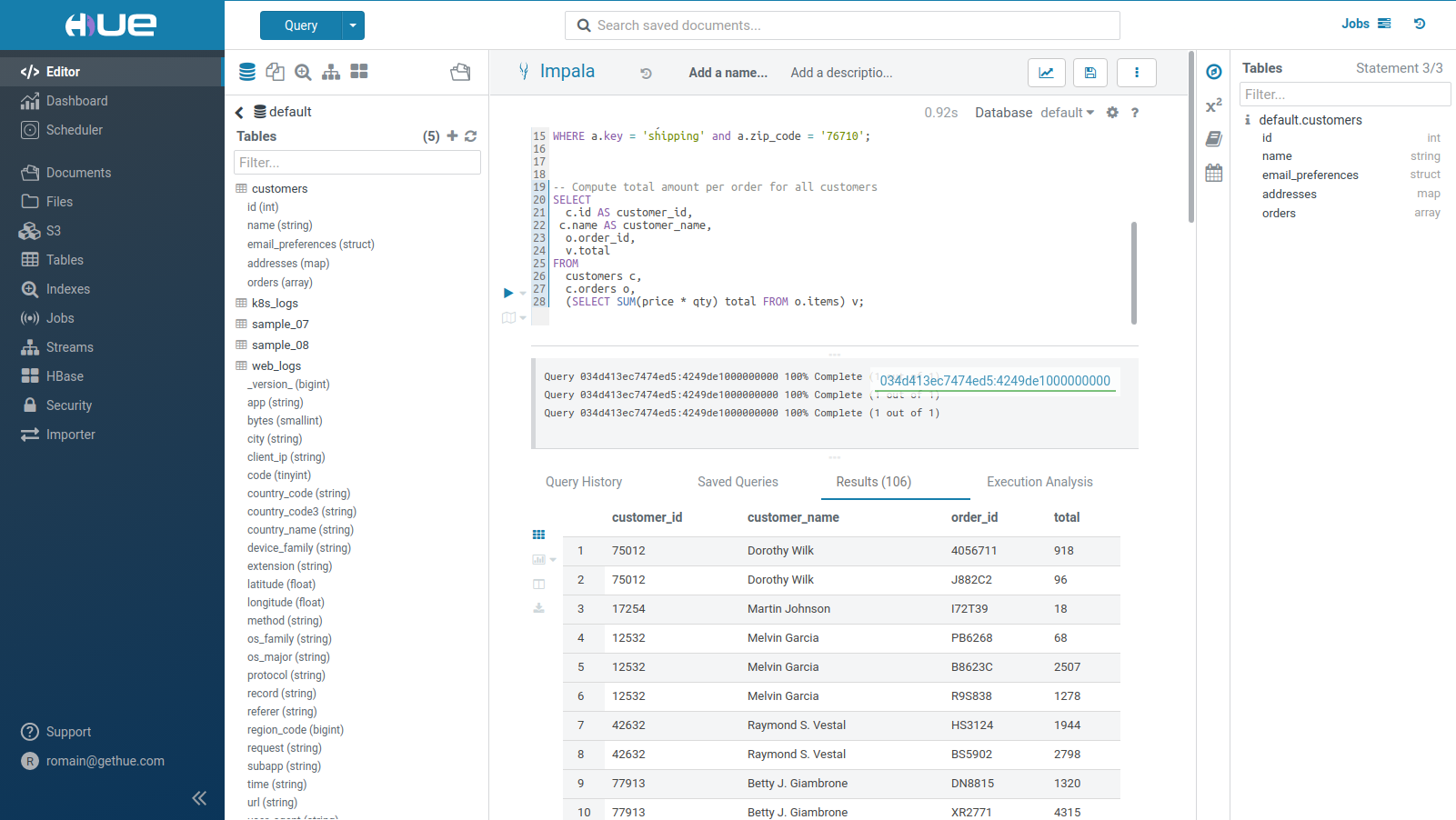
Hue 提供了简单易用的 SQL编辑器,包含智能语法补全、查询优化以及文档支持等功能。

面板(Dashboard)可以通过拖拽方式实现交互式分析。

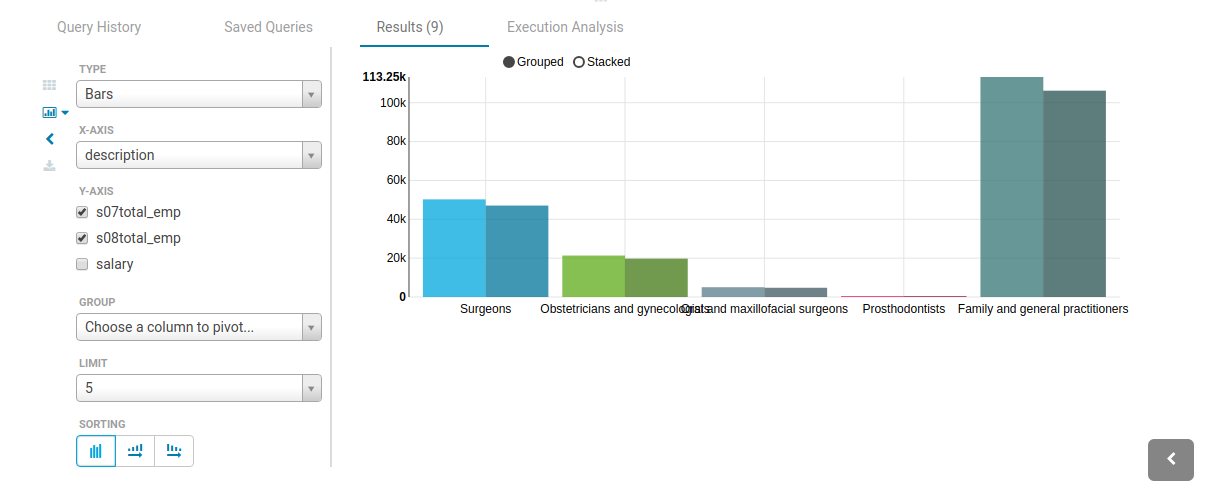
Hue 支持查询结果的可视化图表,饼图、折线图、柱状图、时序图、散点图、地图等。
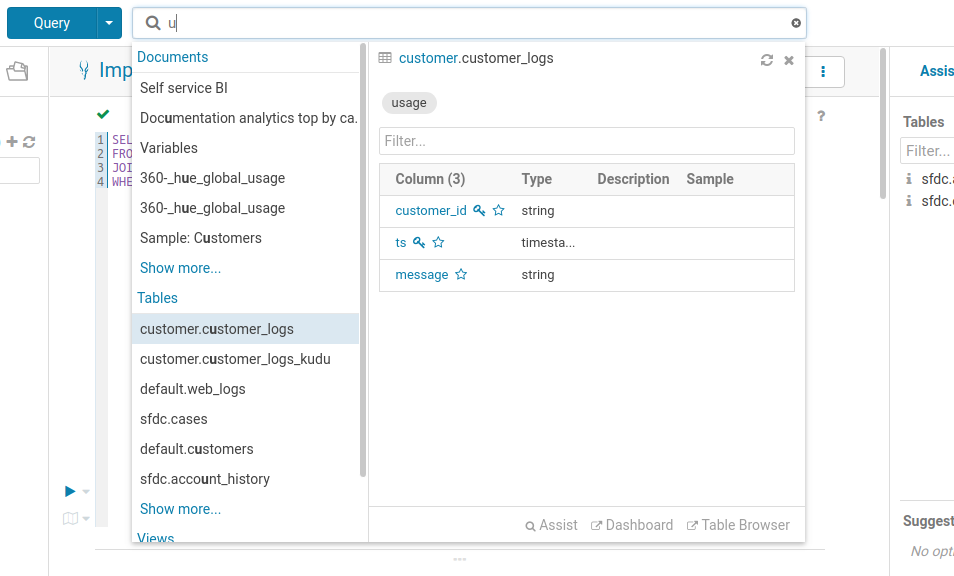
Hue 提供了数据浏览与管理,通过数据目录搜索表和存储,快速定位和分析海量数据。
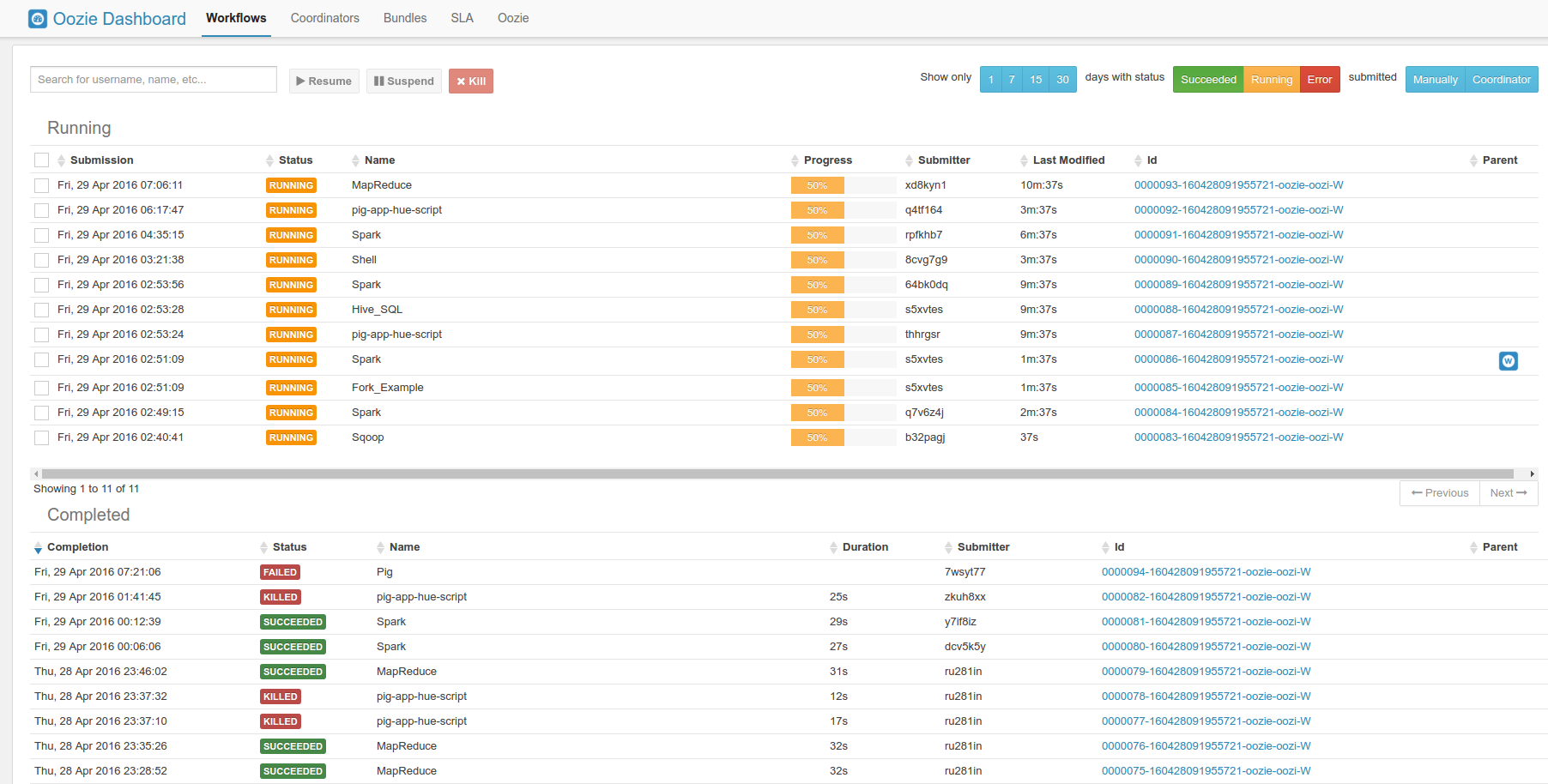
Hue 支持任务调度与监控,集成 Oozie 工作流、YARN 任务监控等功能。
用户可以分享 SQL 查询、工作流、面板等内容。

使用 Docker 快速体验 Hue 方式如下:
bash
docker run -it -p 8888:8888 gethue/hue:latest然后在浏览器中输入以下地址:
首次使用需要创建一个超级管理员账号,输入用户名和密码,点击"Create Account"创建并登录。