目录
技术栈介绍
Canal简介
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志 解析,提供增量数据订阅和消费。
从官方介绍就能看出,canal主要就是用来解决增量日志,增量数据订阅和消费的工具
Canal可与很多数据源进行对接,将数据由MySQL同步到ES、MQ、DB等各个数据源。
Canal的意思是水道/管道/沟渠,它相当于一个数据管道,通过解析MySQL的binlog日志完成数据同步工作。

工作原理:想要理解Canal的工作原理就需要先了解MySQL主从数据同步的原理:
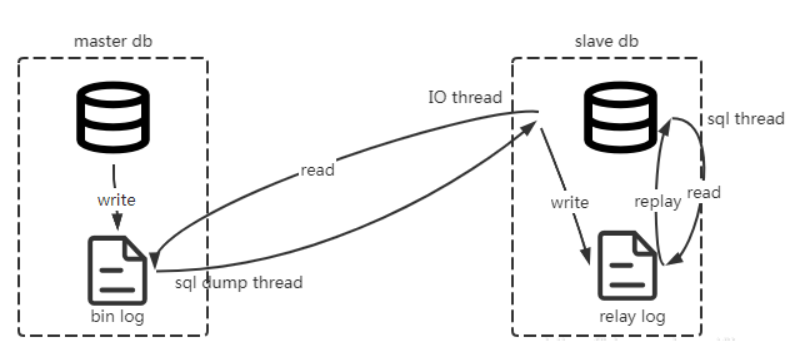
MySQL主从集群由MySQL主服务器(master)和MySQL从服务器(slave)组成,MySQL主从数据同步是一种数据库复制技术,进行写数据会先向主服务器写,写成功后将数据同步到从服务器,流程如下:
1、主服务器将所有写操作(INSERT、UPDATE、DELETE)以二进制日志(binlog)的形式记录下来。
2、从服务器连接到主服务器,发送dump 协议,请求获取主服务器上的binlog日志。
MySQL的dump协议是MySQL复制协议中的一部分。
3、MySQL master 收到 dump 请求,开始推送 binary log 给 slave
4、从服务器解析日志,根据日志内容更新从服务器的数据库,完成从服务器的数据保持与主服务器同步。
根据MySQL主从同步的原理,不难看出Canal在整个过程中充当的是一个冒牌Slave的角色,流程如下:
1、Canal模拟 MySQL slave 的交互协议 ,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) 。一旦连接建立成功,Canal 会一直等待并监听来自MySQL主服务器的binlog事件流 ,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
通过以上流程可知Canal和MySQL master主服务器之间建立了长连接。
RabbitMQ
RabbitMQ 是一个开源的消息队列中间件,基于 AMQP(高级消息队列协议)实现。它支持多种消息传递模式,如点对点、发布 - 订阅等,具有高可用性、可扩展性和可靠性等特点。
RabbitMQ 的特点
- 高可用性:RabbitMQ 支持集群模式,可以通过多个节点组成一个高可用的集群,当某个节点出现故障时,其他节点可以接管其工作,从而保证系统的可用性。
- 可扩展性:RabbitMQ 支持水平扩展,可以通过增加节点的方式提高系统的处理能力和吞吐量。
- 可靠性:RabbitMQ 提供了消息持久化、消息确认机制等可靠性机制,可以保证消息不会丢失。
- 灵活性:RabbitMQ 支持多种消息传递模式,如点对点、发布 - 订阅、请求 - 响应等,可以根据不同的应用场景选择合适的消息传递模式。
关于MQ技术方案,后续文档会详细给出
分库分表
场景分析
随着订单数据的增加,当MySQL单表存储数据达到一定量时其存储及查询性能会下降,在阿里的《Java 开发手册》中提到MySQL单表行数超过 500 万行 或者单表容量超过 2GB 时建议进行分库分表 ,分库分表可以简单理解为原来一个表存储数据现在改为通过多个数据库及多个表去存储,这就相当于原来一台服务器提供服务现在改成多台服务器组成集群共同提供服务,从而增加了服务能力。
这里说的500万行或单表容量超过 2GB并不是定律,只是根据生产经验而言 ,为什么MySQL单表当达到一定数量时性能会下降呢?我们知道为了提高表的查询性能会增加索引 ,MySQL在使用索引时会将索引加入内存 ,如果数据量非常大内存肯定装不下,此时就会从磁盘去查询索引就会产生很多的磁盘IO,从而影响性能,这些和表的设计及服务器的硬件配置都有关,所以如果当表的数据量达到一定程度并且还在不断的增加就需要考虑进行分库分表了。
分库分表
这里举一个例子来说明什么是分库分表
例如给定一个电商系统的数据库,涉及了店铺、商品的相关业务
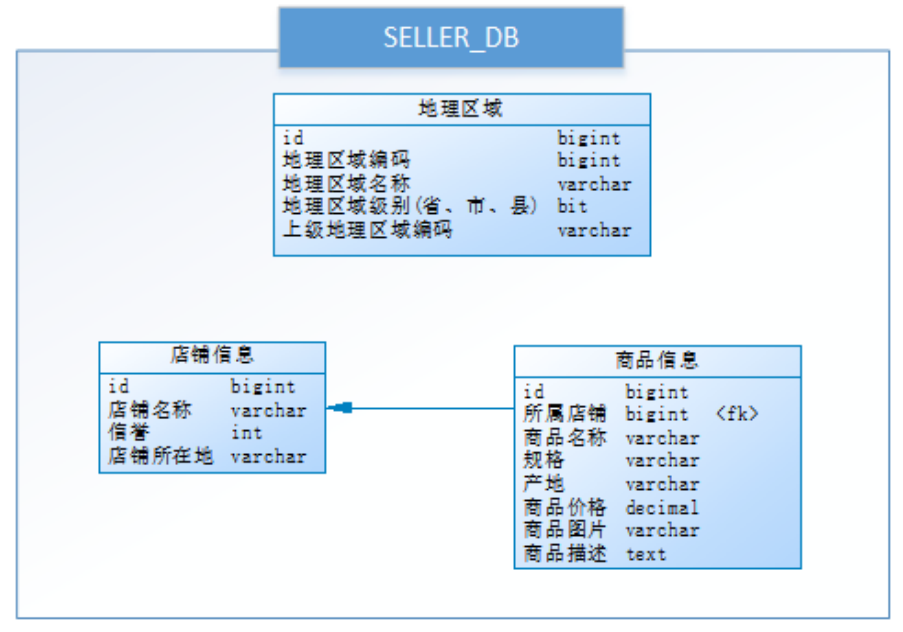
随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,如何进行优化呢?
我们可以把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库拆分的方法来解决数据库的性能问题
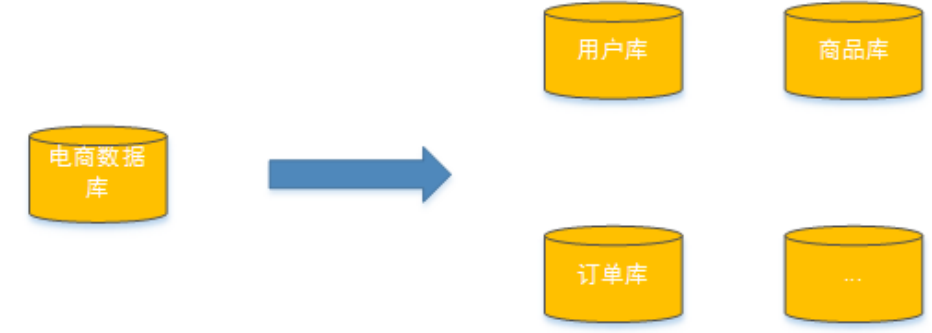
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的
分库分表四种方式
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
垂直分表
垂直分表是将一个表按照字段分成多表,每个表存储其中一部分字段,比如按冷热字段进行拆分
以商品信息为例,用户在选择商品界面,希望看到的是商品的名称、规格、价格等重要信息,相比之下,商品的具体描述便成为不太重要的信息了,而用户只有在对某商品感兴趣时才会查看该商品的详细描述。这些相对来说字段访问频次较低 的商品信息的字段占用存储空间较大 ,访问单个数据IO时间较长,而商品名称、图片、价格等信息的访问频次较高。
因此根据两种数据的特性不同,就可以考虑将商品信息表拆分:将访问频次低的商品描述信息单独存放在一张表中,访问频次高的商品基本信息单独放在另一张表中
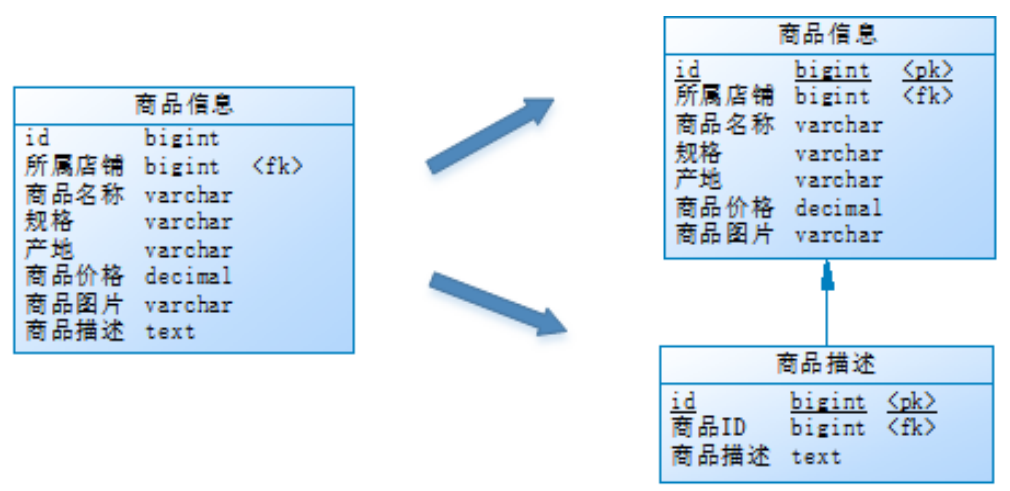
垂直分表的优点:充分发挥了热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累
通常按照以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表
- 把text,blob等大字段拆分出来放在附表中
- 经常组合查询的列放在一张表中
垂直分库
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是时钟限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
垂直分库 是指按照业务将表进行分类,分布到不同的数据库上面 ,每个库可以放在不同的服务器上,它的核心理念是专库专用,微服务架构下通常会对数据库进行垂直分类,不同业务数据放在单独的数据库中,比如:客户信息数据库、订单数据库等。
再次拿电商平台举例,可以将原有的卖家库(SELLER_DB),分为商品库(PRODUCT_DB)和店铺库(STORE_DB),并把这两个库分散到不同服务器,如图:
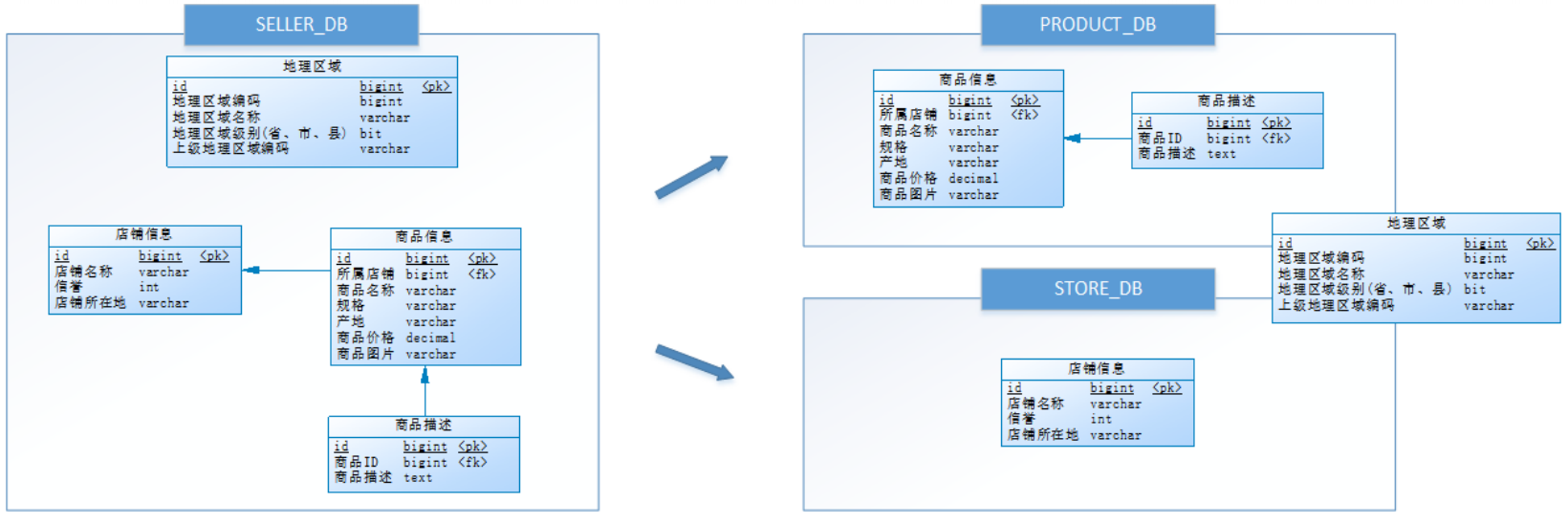
但是又因为商品信息和商品描述业务耦合度较高,因此一起被存放在商品库(PRODUCT_DB),店铺信息就相对独立,被单独存放在店铺库(STORE_DB)。
垂直分库的优点:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、降低单机硬件资源的瓶颈。
但是依旧不能解决单表数据量过大的问题
水平分库
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,商品库(PRODUCT_DB)单库存储数据已经超出预估。粗略估计,目前有8w店铺,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且PRODUCT_DB(商品库)属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
尝试水平分库,将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中。
水平分库 是把同一个表 的数据按一定规则拆到不同的数据库 中,每个库可以放在不同的服务器上,比如:单数订单在db_orders_0数据库,偶数订单在db_orders_1数据库。
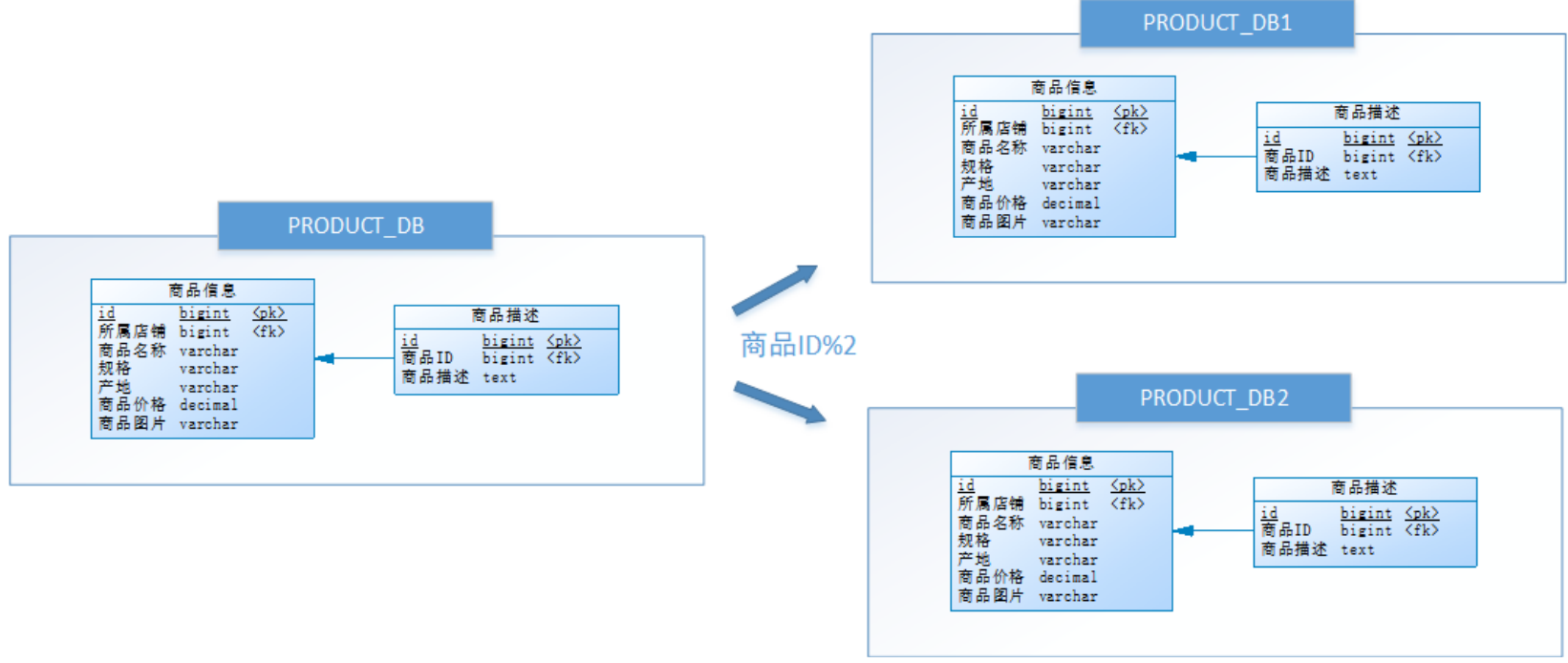
也就是说,要操作某条数据,先分析这条数据所属的店铺ID。
如果店铺ID为双数,将操作映射至商品库1(PRODUCT_DB1);
如果店铺ID为单数,将操作映射至商品库2(PRODUCT_DB2)。
优点:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量以及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
水平分表
按照水平分库的思路把商品库(PRODUCT_DB_X)内的表也可以进行水平拆分,其目的也是为了解决单表数据量巨大的问题,如下图:
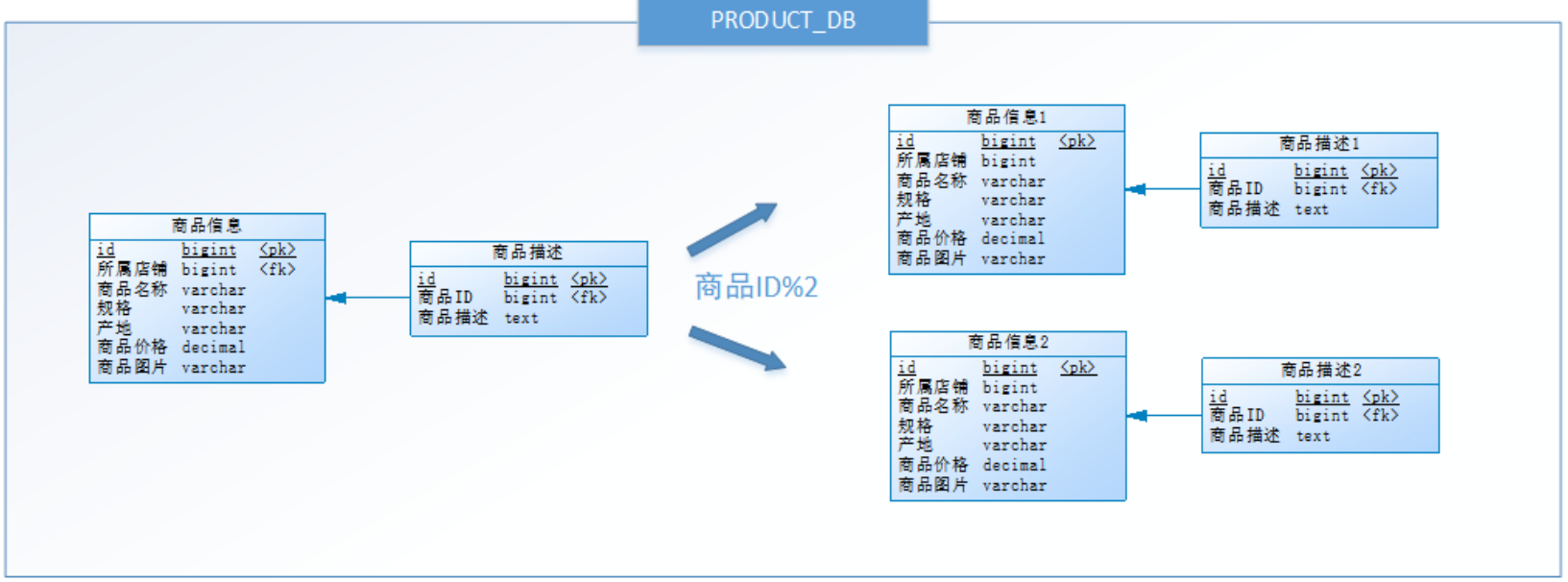
与水平分库思路类似,不过这次操作的目标是表。商品信息和商品描述都被分成了两套表。对数据可以这样操作:
如果商品ID为双数,将操作映射至商品信息1表;
如果商品ID为单数,将操作映射至商品信息2表。
表达式:商品信息商品ID%2+1
水平分表实在同一个数据库内,把同一个表的商户按一定规则拆到多个表中,比如0到500万的订单在orders_0数据、500万到1000万的订单在orders_1数据表。
水平分表优化了单一表数据量过大而产生的性能问题
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库、垂直分表方案,在数据量以及访问压力不是特别大的情况,首先需要考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表
分库分表方案
对订单数据进行分表分表。
1、Hash方式
拿分库举例:将订单号除以数据库个数求余数,假如有3台数据库,计算表达式为:db_订单号%3, 比如:10号订单会存入到db_1数据库,11号订单存储到db_2数据库。
此方式的优点是:数据均匀。
缺点:扩容时需要迁移数据。比如:3台数据库改为4台数据库,此时计算表达式为:db_订单号%4,10号订单存储到db_2数据库,11号订单存储到db_3数据库,此时就需要进行数据迁移,将10号订单由db_1迁移到db_2。
2、rang方式(范围方式)
比如:0到500万到db_1数据库,500万到1000万到db_2数据库,依次类推。
此方式的优点:扩容时不需要迁移数据。
缺点:存在数据热点问题,因为订单号是从0开始依次往上累加,前期所有的数据都是访问db_1数据库,db_1的压力较大。
3、综合方案
综合1、2方案的优缺点制定综合方案。
分库方案:设计三个数据库,根据用户id哈希,分库表达式为:db_用户id % 3
参考历史经验,前期设计三个数据库,每个数据库使用主从结构部署,可以支撑项目几年左右的运行,虽然哈希存在数据迁移问题,在很长一段时间也不用考虑这个问题。
分表方案:根据订单范围分表,0---1500万落到table_0,1500万---3000万落到table_1,依次类推。
根据范围分表不存在数据库迁移问题,方便系统扩容。
整体方案如下图:

ShardingSphere
Apache ShardingSphere 是一款分布式的数据库生态系统,可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
所以数据分片是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储。使用ShardingSphere 的数据分片功能即可实现分库分表。
官方文档:概览 :: ShardingSphere
需求分析
订单数据库结构
订单数据库分为三个库:zhilian-orders-0,zhilian-orders-1,zhilian-orders-2
然后向三个数据库中导入sql脚本,将表数据导入数据库中:
zhilian-orders-0库:orders-serve-1,orders-serve-2
zhilian-orders-1库:orders-serve-1,orders-serve-2
zhilian-orders-2库:orders-serve-1,orders-serve-2
配置shardingsphere-jdbc-dev.yml
在orders-base工程的resources下配置shardingsphere-jdbc-dev.yml(可直接拷贝项目源码目录下的shardingsphere-jdbc-dev.yml)。
配置文件如下:
zhilian-orders-0、zhilian-orders-1、zhilian-orders-2表示三个数据源对应三个订单数据库。
每个数据库中对orders-serve进行分表。
配置如下:
dataSources:
zhilian-orders-0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/zhilian-orders-0?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
zhilian-orders-1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/zhilian-orders-1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
zhilian-orders-2:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/zhilian-orders-2?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
rules:
- !TRANSACTION
defaultType: BASE
- !SHARDING
tables:
orders:
actualDataNodes: zhilian-orders-${0..2}.orders_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orders_table_inline
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: orders_database_inline
orders_serve:
actualDataNodes: zhilian-orders-${0..2}.orders_serve_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orders_serve_table_inline
databaseStrategy:
standard:
shardingColumn: serve_provider_id
shardingAlgorithmName: orders_serve_database_inline
biz_snapshot:
actualDataNodes: zhilian-orders-${0..2}.biz_snapshot_${0..2}
tableStrategy:
standard:
shardingColumn: biz_id
shardingAlgorithmName: biz_snapshot_table_inline
databaseStrategy:
standard:
shardingColumn: db_shard_id
shardingAlgorithmName: biz_snapshot_database_inline
shardingAlgorithms:
# 订单-分库算法
orders_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: zhilian-orders-${user_id % 3}
# 分库支持范围查询
allow-range-query-with-inline-sharding: true
# 订单-分表算法
orders_table_inline:
type: INLINE
props:
# 分表算法表达式
algorithm-expression: orders_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# id生成器
keyGenerators:
snowflake:
type: SNOWFLAKE
- !BROADCAST
tables:
- breach_record
- orders_canceled
- orders_refund
- orders_dispatch
- orders_seize
- serve_provider_sync
- state_persister
- orders_dispatch_receive
- undo_log
- history_orders_sync
- history_orders_serve_sync
props:
sql-show: true说明:
dataSources:数据源
zhilian-orders-x:与actualDataNodes对应。
下边以orders表为例说明分库分表策略:
分库键:user_id
分库表达式:zhilian-orders-${user_id % 3}
根据用户id计算落到哪个数据库
分表键:id
分表表达式:orders_${(int)Math.floor(id % 10000000000 / 15000000)}
!BROADCAST:指定广播表
广播表在zhilian-orders-0、zhilian-orders-1、zhilian-orders-2每个数据库的数据一致。
具体实现
流程如下:
- 订单完成、取消、关闭后在写入订单同步表。
- Canal读取同步表的binlog,解析数据发送至MQ
- 历史订单服务监听MQ,获取到订单信息后写入待迁移表(history_orders_sync和history_orders_serve_sync表)。
在订单数据库创建订单同步表和服务单的同步表:

当订单完成、取消、关闭时向同步表写入记录,通过historyOrdersSyncService.writeHistorySync(orderSnapshotDTO.getId());方法将订单数据同步上边两张同步表当中。
首先进入RabbitMQ,配置exchange.canal-zhilian交换机绑定的队列
com.zhilian.orders.history.handler.HistoryOrdersServeSyncHandler代码:
package com.zhilian.orders.history.handler;
import com.zhilian.canal.listeners.AbstractCanalRabbitMqMsgListener;
import com.zhilian.orders.history.model.domain.HistoryOrders;
import com.zhilian.orders.history.model.domain.HistoryOrdersServe;
import com.zhilian.orders.history.model.domain.HistoryOrdersServeSync;
import com.zhilian.orders.history.service.IHistoryOrdersServeService;
import com.zhilian.orders.history.service.IHistoryOrdersServeSyncService;
import com.zhilian.orders.history.service.IHistoryOrdersService;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Component
public class HistoryOrdersServeSyncHandler extends AbstractCanalRabbitMqMsgListener<HistoryOrdersServeSync> {
@Resource
private IHistoryOrdersServeSyncService historyOrdersServeSyncService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal-mq-zhilian-orders-serve-history",durable = "true"),
exchange = @Exchange(name = "exchange.canal-zhilian", type = ExchangeTypes.TOPIC),
key = "canal-mq-zhilian-orders-serve-history"),
concurrency = "1"
)
public void onMessage(Message message) throws Exception {
parseMsg(message);
}
@Override
public void batchSave(List<HistoryOrdersServeSync> historyOrdersServeSyncs) {
historyOrdersServeSyncService.saveOrUpdateBatch(historyOrdersServeSyncs);
}
@Override
public void batchDelete(List<Long> ids) {
}
}com.zhilian.orders.history.handler.HistoryOrdersSyncHandler代码:
package com.zhilian.orders.history.handler;
import com.zhilian.canal.listeners.AbstractCanalRabbitMqMsgListener;
import com.zhilian.orders.history.model.domain.HistoryOrdersSync;
import com.zhilian.orders.history.service.IHistoryOrdersSyncService;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Component
public class HistoryOrdersSyncHandler extends AbstractCanalRabbitMqMsgListener<HistoryOrdersSync> {
@Resource
private IHistoryOrdersSyncService historyOrdersSyncService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal-mq-zhilian-orders-history", durable = "true"),
exchange = @Exchange(name = "exchange.canal-zhilian", type = ExchangeTypes.TOPIC),
key = "canal-mq-zhilian-orders-history"),
concurrency = "1"
)
public void onMessage(Message message) throws Exception {
parseMsg(message);
}
@Override
public void batchSave(List<HistoryOrdersSync> historyOrdersSyncs) {
historyOrdersSyncService.saveOrUpdateBatch(historyOrdersSyncs);
}
@Override
public void batchDelete(List<Long> ids) {
}
}Canal-sync同步抽象监听器代码:上面两个同步方法都是继承自该方法
package com.zhilian.canal.listeners;
import com.zhilian.canal.constants.FieldConstants;
import com.zhilian.canal.constants.OperateType;
import com.zhilian.canal.core.CanalDataHandler;
import com.zhilian.canal.model.CanalMqInfo;
import com.zhilian.canal.model.dto.CanalBaseDTO;
import com.zhilian.common.utils.BeanUtils;
import com.zhilian.common.utils.CollUtils;
import com.zhilian.common.utils.JsonUtils;
import com.zhilian.common.utils.NumberUtils;
import org.springframework.amqp.core.Message;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public abstract class AbstractCanalRabbitMqMsgListener<T> implements CanalDataHandler<T> {
public void parseMsg(Message message) throws Exception {
try {
// 1.数据格式转换
CanalMqInfo canalMqInfo = JsonUtils.toBean(new String(message.getBody()), CanalMqInfo.class);
// 2.过滤数据,没有数据或者非插入、修改、删除的操作均不处理
if (CollUtils.isEmpty(canalMqInfo.getData()) || !(OperateType.canHandle(canalMqInfo.getType()))) {
return;
}
if (canalMqInfo.getData().size() > 1) {
// 3.多条数据处理
batchHandle(canalMqInfo);
} else {
// 4.单条数据处理
singleHandle(canalMqInfo);
}
} catch (Exception e) {
//出现错误延迟1秒重试
Thread.sleep(1000);
throw new RuntimeException(e);
}
}
/**
* 单条数据处理
*
* @param canalMqInfo
*/
private void singleHandle(CanalMqInfo canalMqInfo) {
// 1.数据转换
CanalBaseDTO canalBaseDTO = BeanUtils.toBean(canalMqInfo, CanalBaseDTO.class);
Map<String, Object> fieldMap = CollUtils.getFirst(canalMqInfo.getData());
canalBaseDTO.setId(parseId(fieldMap));
canalBaseDTO.setFieldMap(fieldMap);
canalBaseDTO.setIsSave(canalMqInfo.getIsSave());
Class<T> messageType = getMessageType();
if (messageType == null) {
return;
}
if (canalBaseDTO.getIsSave()) {
T t1 = JsonUtils.toBean(JsonUtils.toJsonStr(canalBaseDTO.getFieldMap()), messageType);
List<T> ts = Arrays.asList(t1);
batchSave(ts);
} else {
Long id = canalBaseDTO.getId();
List<Long> ids = Arrays.asList(id);
batchDelete(ids);
}
}
private void batchHandle(CanalMqInfo canalMqInfo) {
Class<T> messageType = getMessageType();
if (messageType == null) {
return;
}
if(canalMqInfo.getIsSave()){
List<T> collect = canalMqInfo.getData().stream().map(fieldMap -> {
CanalBaseDTO canalBaseDTO = CanalBaseDTO.builder()
.id(parseId(fieldMap))
.database(canalMqInfo.getDatabase())
.table(canalMqInfo.getTable())
.isSave(canalMqInfo.getIsSave())
.fieldMap(fieldMap).build();
return JsonUtils.toBean(JsonUtils.toJsonStr(canalBaseDTO.getFieldMap()), messageType);
}).collect(Collectors.toList());
batchSave(collect);
}else{
List<Long> ids = canalMqInfo.getData().stream().map(fieldMap -> {
return parseId(fieldMap);
}).collect(Collectors.toList());
batchDelete(ids);
}
}
private Long parseId(Map<String, Object> fieldMap) {
Object objectId = fieldMap.get(FieldConstants.ID);
return NumberUtils.parseLong(objectId.toString());
}
/**
* 批量保存
*
* @param data
*/
public abstract void batchSave(List<T> data);
/**
* 批量删除
*
* @param ids
*/
public abstract void batchDelete(List<Long> ids);
//获取泛型参数
public Class<T> getMessageType() {
Type superClass = getClass().getGenericSuperclass();
if (superClass instanceof ParameterizedType) {
ParameterizedType parameterizedType = (ParameterizedType) superClass;
Type[] typeArgs = parameterizedType.getActualTypeArguments();
if (typeArgs.length > 0 && typeArgs[0] instanceof Class) {
return (Class<T>) typeArgs[0];
}
}
return null;
}
}后续可以阅读以下文档:
爆肝3万字,为你吃透RabbitMQ,最详细的RabbitMQ讲解(VIP典藏版)-腾讯云开发者社区-腾讯云