【前言】
本专题为PyTorch专栏。从本专题开始,我将通过使用PyTorch编写基础神经网络,带领大家学习PyTorch。并顺便带领大家复习以下深度学习的知识。希望大家通过本专栏学习,更进一步了解人更智能这个领域。
PyTorch编写思路
对于大部分的神经网络模型,我们应该要有以下编写思路:
1.构建数据集
2.设计模型
3.构造损失函数和优化器
4.周期训练模型
5.测试模型
【前言】本节课我们实现的是二分类,因此标签是0或1.
PyTorch数据集获取:
1. MNIST 数据集
MNIST 数据集是一个非常著名且广泛使用的手写数字识别数据集,常被用于机器学习和深度学习领域的入门实验和基准测试。
- 数据集内容
MNIST 数据集包含灰度化的手写数字图像及其对应的标签。具体来说:
**图像**:每个图像的大小为 28×28 像素,包含灰度值(像素值范围为 0 到 255),其中 0 表示白色背景,255 表示黑色前景。
**标签**:每个图像对应一个标签,标签是一个介于 0 到 9 的整数,表示图像中手写的数字。
- 数据集划分
MNIST 数据集通常分为两部分:
**训练集**:包含 60,000 张图像及其标签,用于训练模型。
**测试集**:包含 10,000 张图像及其标签,用于评估模型的性能。
python
import torchvision
train_set=torchvision.datasets.MNIST(root='D:\学习\数据集\PyTorch逻辑回归数据集',train=True,download=True)
test_set=torchvision.datasets.MNIST(root='D:\学习\数据集\PyTorch逻辑回归数据集',train=False,download=True)
参数root:数据集保存地址
参数train:True=将数据集作为训练集,False=将数据集作为测试集
参数download:True=下载,False=不下载
2. CIFAR 数据集
CIFAR 数据集分为两个主要版本:CIFAR-10 和 CIFAR-100。
CIFAR-10
图像数量:包含 60,000 张 32×32 的彩色图像。
类别数量:分为 10 个类别,每个类别包含 6,000 张图像。
类别内容:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。
数据划分:50,000 张训练图像和 10,000 张测试图像。
CIFAR-100
图像数量:包含 60,000 张 32×32 的彩色图像。
类别数量:分为 100 个类别,每个类别包含 600 张图像。
类别内容:类别更加丰富,例如动物、交通工具、自然场景等。
数据划分:50,000 张训练图像和 10,000 张测试图像。
- 数据集特点
图像尺寸小:每张图像的尺寸为 32×32 像素,适合快速实验。
类别丰富:CIFAR-10 有 10 个类别,CIFAR-100 有 100 个类别。
类别均衡:每个类别的样本数量相同,有助于模型学习。
真实场景:图像来自真实世界,具有一定的复杂性和多样性。
python
import torchvision
train_set=torchvision.datasets.CIFAR10(root='D:\学习\数据集\PyTorch逻辑回归数据集',train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root='D:\学习\数据集\PyTorch逻辑回归数据集',train=False,download=True)参数root:数据集保存地址
参数train:True=将数据集作为训练集,False=将数据集作为测试集
参数download:True=下载,False=不下载
一、构建数据集
python
import torch
#torch.Tensor()用来创建张量,即创建矩阵
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[0],[0],[1]])【注意】y_data与上节课不同,因为这节课讲的是二分类问题,因此标签是0或1。
二、设计模型
1.构造计算图
当你有了一个计算图之后,你将会加深对神经网络计算过程的理解,更加便于你构造神经网络模型

2.代码实现
python
import torch.nn.functional as F
#torch.nn.functional 是 PyTorch 中的一个模块,提供了许多用于构建神经网络的函数式接口。
#这些函数通常用于定义网络的前向传播过程,包括激活函数、损失函数、卷积操作、池化操作等。
#使用 torch.nn.functional 可以使代码更加灵活和简洁。
class LogisticRegressionModel(torch.nn.Module):
"""
定义了一个类,继承自PyTorch的torch.nn.Module模块.
是 PyTorch 中所有神经网络模块的基类,所有自定义的模型都应该继承自这个类。
"""
def __init__(self):
#是 PyTorch 中所有神经网络模块的基类,所有自定义的模型都应该继承自这个类。
super(LogisticRegressionModel,self).__init__()
"""
调用了父类 torch.nn.Module 的初始化方法。这是必要的,
因为 torch.nn.Module 的初始化方法会进行一些内部的初始化操作,确保模型能够正常工作。
"""
self.linear=torch.nn.Linear(1,1)
#创建了一个线性层
#第一个参数为输入特征的数量。即输入张量的最后一个维度的大小。
#第二个参数为输出特征的数量。即输出张量的最后一个维度的大小。
#定义了一个前向传播
def forward(self,x):
y_pred=F.sigmoid(self.linear(x))
return y_pred
#类实例化
model=LogisticRegressionModel()代码中的注释很详细,大家仔细看一下。
三、构造损失函数和优化器
这章节我们将使用新的损失函数------交叉熵损失函数
python
#方差损失函数
criterion=torch.nn.BCELoss(size_average=False)
#优化器optim.SGD
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)交叉熵损失函数

我们之前在深度学习中一开始学习的就是交叉熵损失函数,因此在这里再给大家复习一下
四、周期训练模型
我们定周期为1000,并打印周期内的方差损失函数的损失值
python
for epoch in range(1000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()其中的函数我们上节课中讲过,如果有遗忘的话大家可以再看看上节课的文章,这里就不再过多赘述了
运行结果:
python
0 1.754103660583496
1 1.7506103515625
2 1.7472782135009766
3 1.744094967842102
4 1.7410497665405273
5 1.7381312847137451
6 1.735330581665039
7 1.7326380014419556
8 1.7300457954406738
9 1.727545976638794
10 1.7251315116882324
11 1.7227959632873535
12 1.7205333709716797
13 1.7183377742767334
14 1.7162041664123535
15 1.7141282558441162
16 1.7121050357818604
17 1.710131049156189
18 1.7082021236419678
19 1.7063149213790894
20 1.704466700553894
21 1.7026541233062744
22 1.7008745670318604
23 1.6991257667541504
24 1.6974055767059326
...
996 0.963502049446106
997 0.9631128907203674
998 0.9627243280410767
999 0.9623361825942993
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...我们可以直观的看到,随着训练次数越来越多,损失值在不断的减少,这也就意味着模型的效果越来越好。这也就是梯度下降过程。
五、测试模型
python
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(0,10,200)
x_test=torch.Tensor(x).view((200,1))
y_test=model(x_test)
y=y_test.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()测试结果:
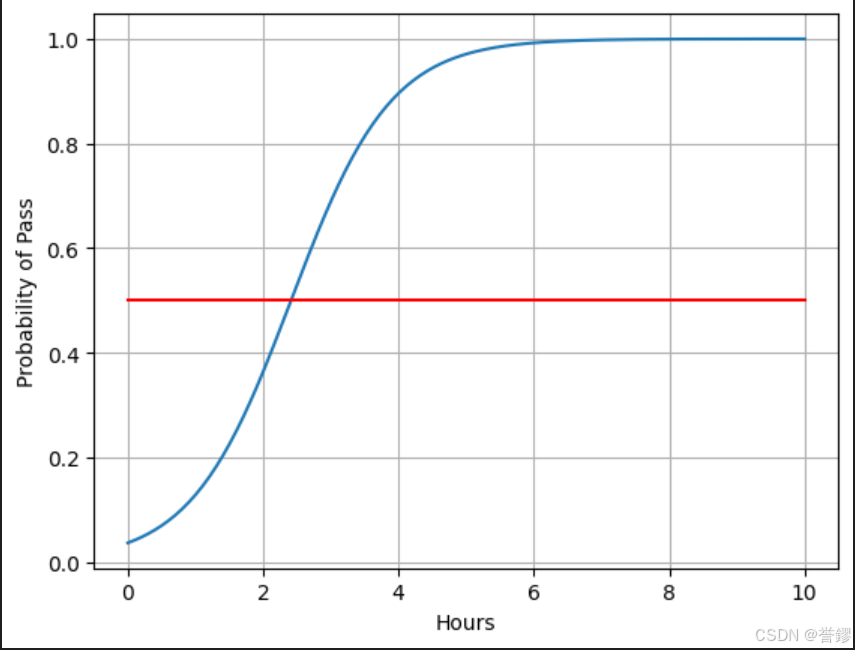
我们可以看到,这张图片其实就是Sigmoid函数的一部分。
pythonimport numpy as np import matplotlib.pyplot as plt
- 导入了 NumPy 和 Matplotlib 的
pyplot模块,分别用于数值计算和绘图。
pythonx = np.linspace(0, 10, 200)
使用
np.linspace创建了一个包含 200 个点的数组x,这些点均匀分布在 0 到 10 之间。这些点将作为输入数据,用于测试模型的预测。
pythonx_test = torch.Tensor(x).view((200, 1))
将 NumPy 数组
x转换为 PyTorch 张量x_test。使用
.view((200, 1))将张量的形状调整为(200, 1),表示有 200 个样本,每个样本有 1 个特征。这是因为 PyTorch 的模型通常期望输入是一个二维张量。
pythony_test = model(x_test)
将输入张量
x_test传递给模型model,计算模型的预测值y_test。假设
model是一个已经训练好的模型,它会输出每个输入点对应的预测值。
pythony = y_test.data.numpy()
将 PyTorch 张量
y_test转换为 NumPy 数组y,以便用于绘图。
.data是 PyTorch 中用于访问张量数据的属性,但请注意,在较新的 PyTorch 版本中,建议直接使用张量本身(例如y_test.numpy())。
pythonplt.plot(x, y)
使用 Matplotlib 的
plot函数绘制输入x和预测值y的关系图。这条曲线展示了模型预测的概率随输入的变化情况。
pythonplt.plot([0, 10], [0.5, 0.5], c='r')
在图上绘制一条红色的水平线,表示概率为 0.5 的阈值。
这条线可以帮助观察模型预测的概率在不同输入下的位置。
pythonplt.xlabel('Hours') plt.ylabel('Probability of Pass')
设置 x 轴和 y 轴的标签,分别为 "Hours" 和 "Probability of Pass"。
这表明输入
x可能表示某种时间(例如学习时间),而输出y表示通过的概率。
pythonplt.grid()
- 添加网格线,使图形更易于阅读。
pythonplt.show()
- 显示图形。