Transformer架构:并行计算革命与Encoder-Decoder设计
2017年,Google团队在《Attention Is All You Need》中提出的Transformer架构彻底改变了序列建模范式。与传统循环神经网络(RNN)逐 token 处理不同,Transformer 通过自注意力机制实现了序列的并行处理,这一突破使其成为 BERT、GPT 等革命性模型的基础。
Transformer 的核心创新在于自注意力机制,它允许序列中每个 token 同时关注所有其他 token,直接计算任意位置间的关联权重。这种机制的计算复杂度为 O(n²×d),其中 n 是序列长度,d 是模型维度。虽然平方级复杂度对长序列构成挑战,但并行处理能力使 Transformer 在 8 块 V100 GPU 上的训练速度比 RNN 快 8 倍。
Encoder-Decoder 架构是 Transformer 的另一支柱。编码器负责将输入序列转换为上下文向量,解码器则基于此生成目标序列。每个编码器层包含多头自注意力和前馈神经网络,解码器层额外增加编码器 - 解码器注意力模块。这种模块化设计使模型能灵活适应翻译、摘要等多种任务。
位置编码解决了 Transformer 缺乏固有序列感知的问题。原始论文采用正弦函数生成位置向量,而现代模型如 LLaMA 已改用旋转位置编码(RoPE),在长文本处理中表现更优。
循环神经网络:序列依赖建模的局限与突破
循环神经网络(RNN)通过隐藏状态的时间传递实现序列建模,其核心公式 ht = σ(Wxxt + Whht - 1 + bh) 体现了当前状态对历史信息的依赖。这种设计使其在早期 NLP 任务中占据主导地位,尤其适用于语音识别、时间序列预测等领域。
然而,RNN 存在致命缺陷:梯度消失/爆炸问题。在处理长序列时,反向传播的梯度会随时间步指数级衰减或增长,导致模型难以捕捉长期依赖。例如,在 WMT14 英德翻译任务中,LSTM 在序列长度超过 50 时 BLEU 值骤降 30%。
为解决这一问题,研究者提出 LSTM 和 GRU 等改进结构。LSTM 通过输入门、遗忘门和输出门控制信息流动,在文本生成任务中能有效缓解梯度消失;GRU 则简化门控机制,参数减少 30% 仍保持相近性能。双向 RNN(BiRNN)通过正向和反向两个方向的 RNN 捕捉双向上下文,在命名实体识别任务中 F1 值提升 5 - 8%。
尽管有这些改进,RNN 的串行计算本质使其训练效率远低于 Transformer。在机器翻译任务中,基于 RNN 的 Seq2Seq 模型推理速度比 Transformer 慢 4 - 6 倍,这也导致 2017 年后 Transformer 逐渐取代 RNN 成为主流架构。
注意力机制:从能效优化到模拟内存计算
注意力机制模拟人类视觉的选择性关注能力,通过动态权重分配聚焦关键信息。在 Transformer 中,自注意力通过 Query(Q)、Key(K)、Value(V)矩阵计算注意力分数:
SelfAttention(Q, K, V) = softmax(QK^T / √dk)V
其中 √dk 缩放因子用于避免 softmax 饱和。多头注意力将此过程并行化到多个子空间,使模型能同时捕捉语法、语义等不同维度的关联。
近年来,注意力机制的能效优化成为研究热点。DeepSeek 提出的原生稀疏注意力(NSA) 通过动态分层剪枝,将计算复杂度从 O(n²) 降至 O(n log n)。在 128k 法律合同解析任务中,NSA 使推理速度提升 11 倍,同时保持 99.3% 准确率。模拟内存计算(In - Memory Computing)则通过电荷脉冲电路实现注意力计算,在 GPT - 2 单头注意力测试中,实现 65ns 延迟和 6.1nJ/ token 能耗,比 NVIDIA A100 快 7000 倍,能效提升 90000 倍。
混合专家注意力(MoH)是另一重要突破。谷歌将多头注意力改造为动态路由的专家系统,包含语法分析头、语义关联头等专业模块,推理时仅激活 3 - 5 个相关专家。在 ImageNet 分类任务中,MoH 降低 45% 计算量,同时保持精度损失小于 1%。
扩散模型:NLP 生成范式的新探索
扩散模型最初在图像生成领域取得成功,2025 年以来,LLaDA、Mercury 等模型将其引入 NLP,开创了非自回归生成的新路径。与自回归模型逐词生成不同,扩散模型通过前向加噪 - 反向去噪的迭代过程生成文本,从完全掩码的序列逐步恢复出完整内容。
LLaDA(Large Language Diffusion with mAsking)是首个开源扩散语言模型,在 2.3 万亿 token 上预训练的 8B 参数版本,在 MMLU、GSM8K 等任务上性能媲美 LLaMA3 8B。其创新点在于掩码扩散机制:前向过程以概率 t 独立掩码每个 token,反向过程通过 Transformer 预测被掩码位置。这种双向建模使 LLaDA 在逆向推理任务中表现突出,在诗歌补全测试中超越 GPT - 4o,尤其擅长恢复上下文逻辑连贯性。
商业模型 Mercury 则专注于推理效率优化,通过离散扩散过程实现 5 - 10 倍加速。Inception 公司公布的数据显示,在相同硬件条件下,Mercury 的代码生成速度比 GPT - 4 快 7 倍,同时 HumanEval 通过率保持在 78%。其核心优化包括:
-
动态噪声调度:根据文本复杂度调整去噪步数,简单句子可在 8 步内完成生成
-
分组预测反馈:将长序列分块并行去噪,通过交叉注意力保持全局一致性
-
硬件感知训练:针对 GPU Tensor Core 优化稀疏矩阵运算,内存带宽利用率提升 3 倍
北京大学提出的可逆扩散模型(IDM)进一步将图像重建的推理步数从 100 步降至 3 步,PSNR 指标提升 2dB。这种端到端训练框架为文本生成的效率优化提供了新思路。
四大架构的综合对比与未来趋势
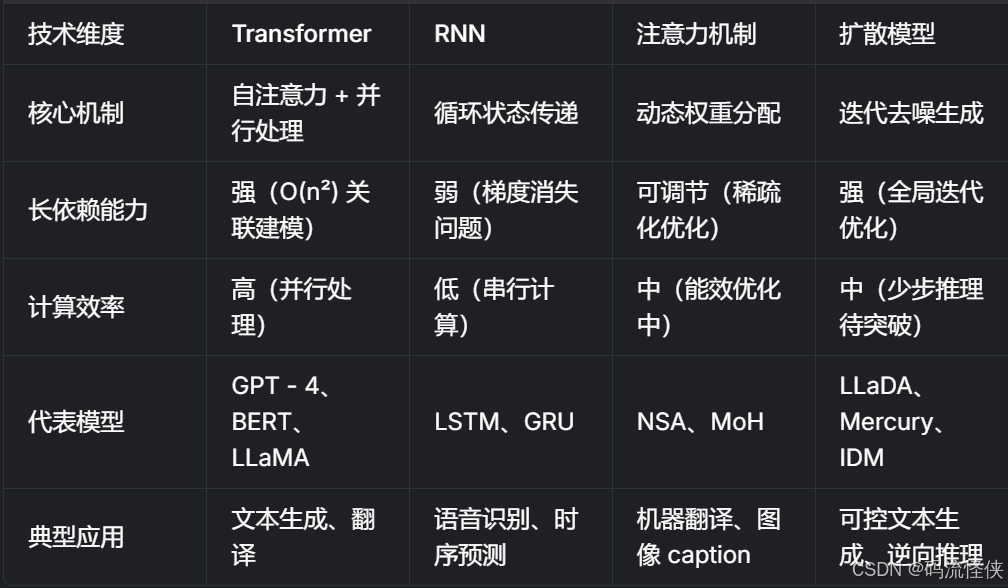
当前研究呈现两大融合趋势:一是 Transformer 与扩散模型的结合,如 Dream - 7B 将自回归初始化与扩散精炼结合,在数学推理任务中 GSM8K 准确率达 78.2%;二是注意力机制的硬件级创新,如 DeepSeek 的 MLA 技术通过低秩分解将 KV 缓存压缩 68%,使 671B 模型可在消费级 GPU 运行。
未来,扩散模型的少步推理和 Transformer 的效率优化将成为竞争焦点。随着 MoE 架构和稀疏注意力的成熟,模型将在参数量不显著增加的情况下,通过动态激活实现能力跃升。对于开发者而言,理解这些架构的底层逻辑,将为模型选型和优化提供关键指导------自回归模型仍是通用任务首选,扩散模型在可控生成和特定推理场景更具潜力,而 RNN 在资源受限的实时处理中仍有一席之地。
技术演进永无止境,但核心目标始终不变:在效率与性能间找到最佳平衡点,让 AI 真正实现"智能"与"实用"的统一。