声明:
本文基于哔站博主【Shusenwang】的视频课程【RNN模型及NLP应用】,结合自身的理解所作,旨在帮助大家了解学习NLP自然语言处理基础知识。配合着视频课程学习效果更佳。
材料来源:【Shusenwang】的视频课程【RNN模型及NLP应用】
视频链接:Transformer模型(1/2): 剥离RNN,保留Attention_哔哩哔哩_bilibili
一、学习目标
1.本节课我们来学习剥离RNN的Attention和Self-Attention
2.掌握Attention和Self-Attention的基本原理
3.熟悉并掌握Attention和Self-Attention的底层逻辑
Transformer模型基本框架:
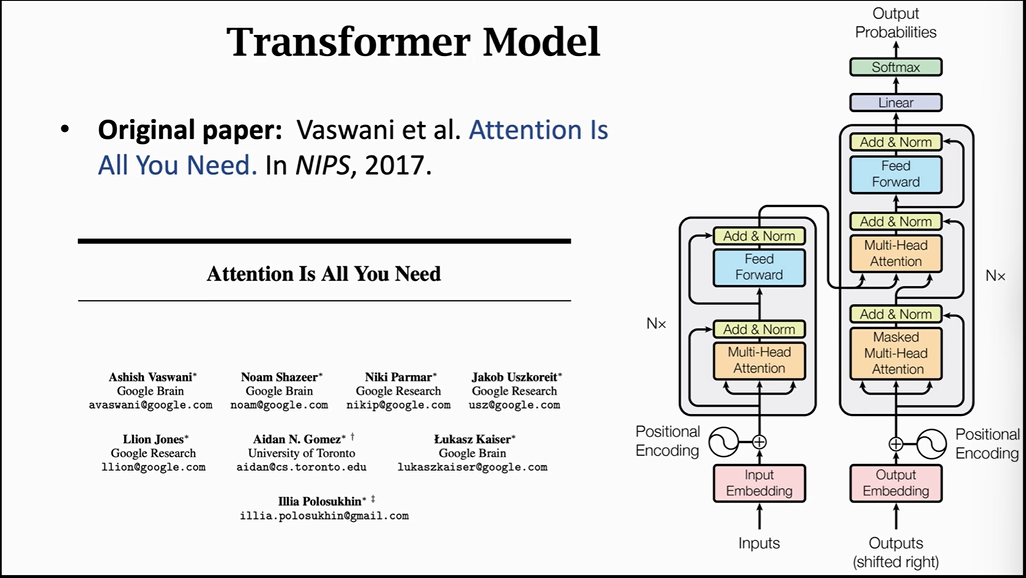
Transformer的效果非常惊人,可以完爆所有的RNN+Attention
二、剥离RNN,用Attention打一个深度神经网络
(1)搭建Attention层(for Seq2Seq Model)
【前言】
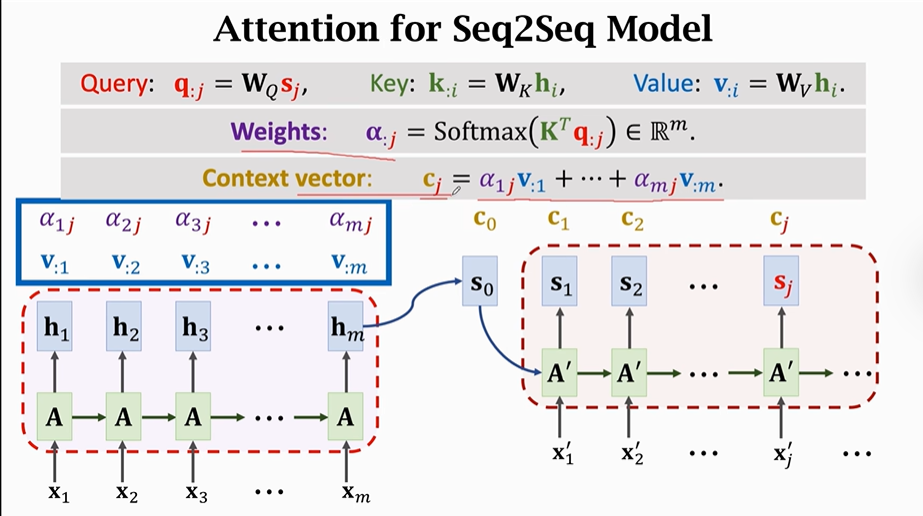
之前的课程里我们用Attention来改进Sequence to Sequence模型,Sequence to Sequence有一个Encoder层和一个Decoder层。
Encoder的输入是m个向量,Encoder将这些信息压缩到状态向量h中,最后一个hm是对所有信息的概括。
Decoder是一个文本生成器,依次生成状态S,然后根据状态S生成新的单词X',新的单词X'将作为下一个输入用来生成新的状态向量h。
如果用Attention的话还需要计算contect vector(C),要计算Attention的话需要先计算每一个S对应的权重α。就是计算出每个状态S向量与所有的h向量的相关性。

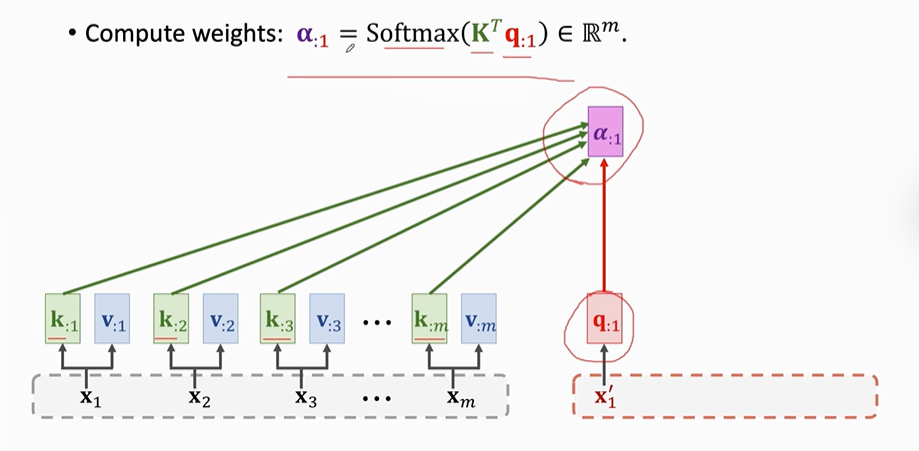
我们具体来看一下权重α是怎么计算出来的:
α计算过程如下:
这里引入三个向量:
图中的q为Query,用来匹配key值
图中的k为key,用来被Query匹配
图中的Value,是用来被进行加权平均的
由
这一步我们知道α就是K与Q的匹配程度,匹配程度越高则权重越大。
Wq、Wk、Wv这三个参数矩阵都需要从训练数据中学习


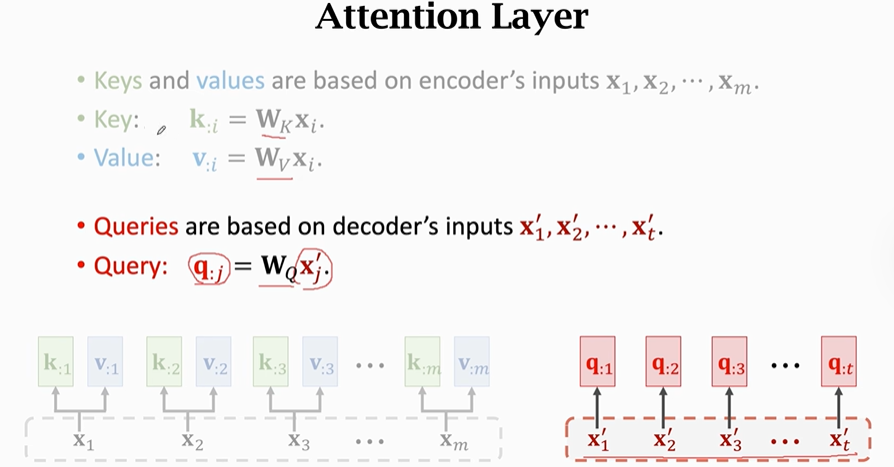
接下来我们整合一下刚刚讲述的计算过程:
①将Decoder第j个状态向量Sj与Wq相乘得到Query向量qj.
②将Encoder中全部的状态向量h与Wk相乘得到key,也就是将h映射到Key向量上
③将Encoder中全部的状态向量h与Wv相乘得到Value,每一个Value对应一个h
④用softmax函数对比K矩阵和Qj计算权重α
⑤计算加权平均Cj:将每一个α与v相乘求和得到Cj
【提示】这种α和C的计算方法就是Transformer里面用的
(1)搭一个Aentioin层用于Seq2Seq模型
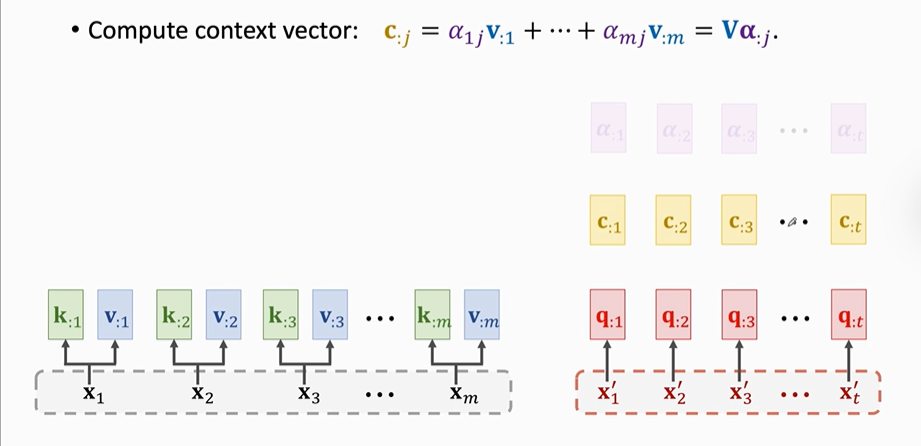
【第一步】计算K、q、V
【第二步】计算权重α将计算q1与每一个key值的相关性得到α:1(意思是第一个α矩阵,不是第一个α值)
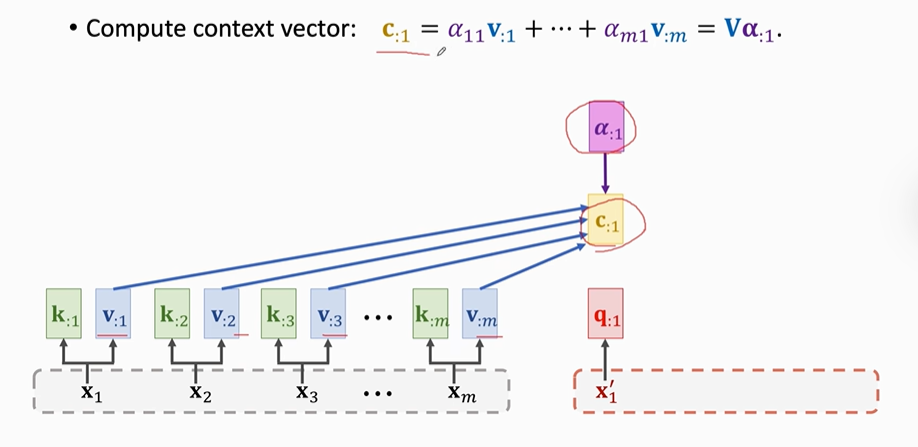
然后计算contect vector(C)
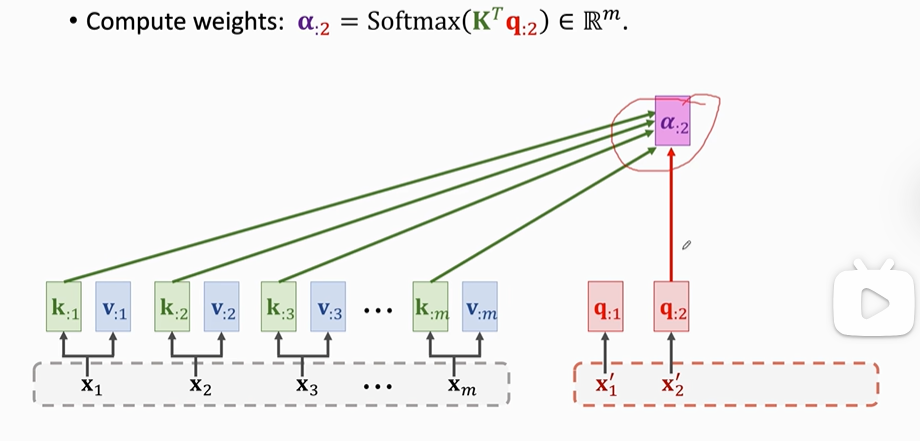
以此类推:
......
......
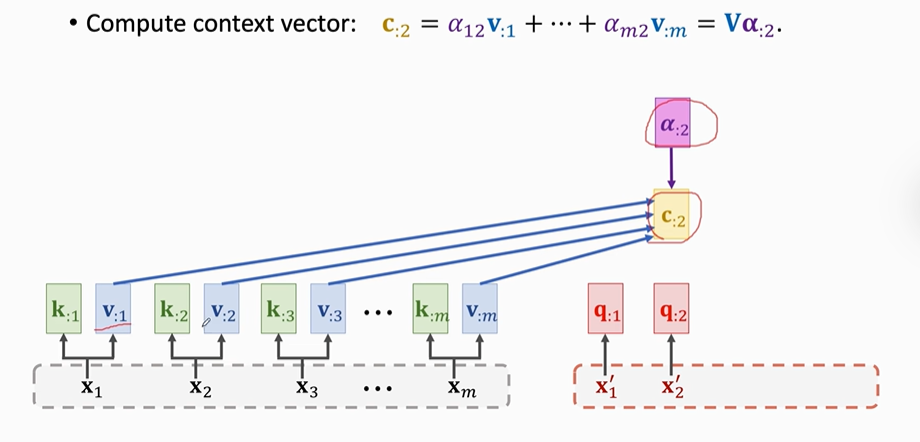
可以用同样的方法计算出contect vector(C)。每一个C对应一个X'。
输出矩阵C=C:1,C:2,C:3......Ct
以下是对Attention的总结:
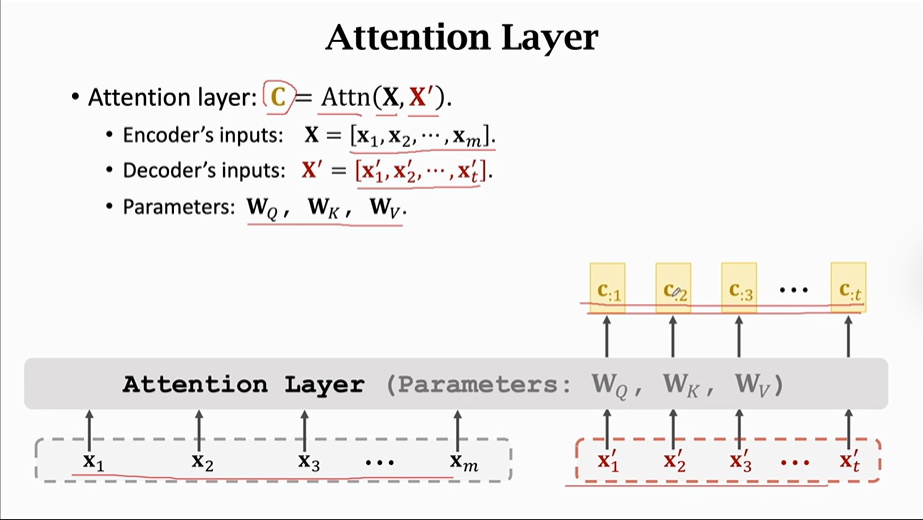
①我们将Attention层记作Attn()函数
②Encoder的输入记作矩阵X=X1,X2,X3...Xm
③Decoder的输入记作矩阵X'=X1',X2',X3'...Xt'
【注意】参数Wq、Wk、Wv这是三个参数矩阵需要从训练数据中获得
④计算出来的每一个contect vector (C)对应一个X'。
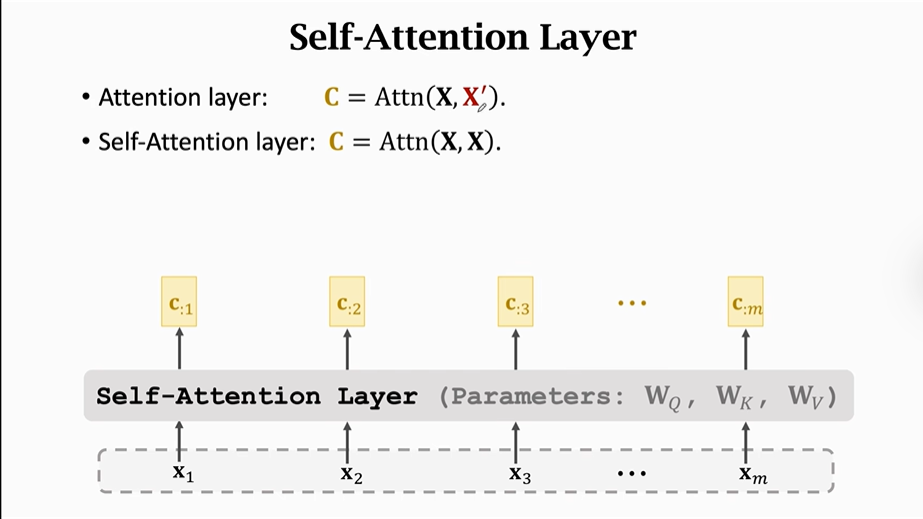
(2)搭一个Self-Attention层
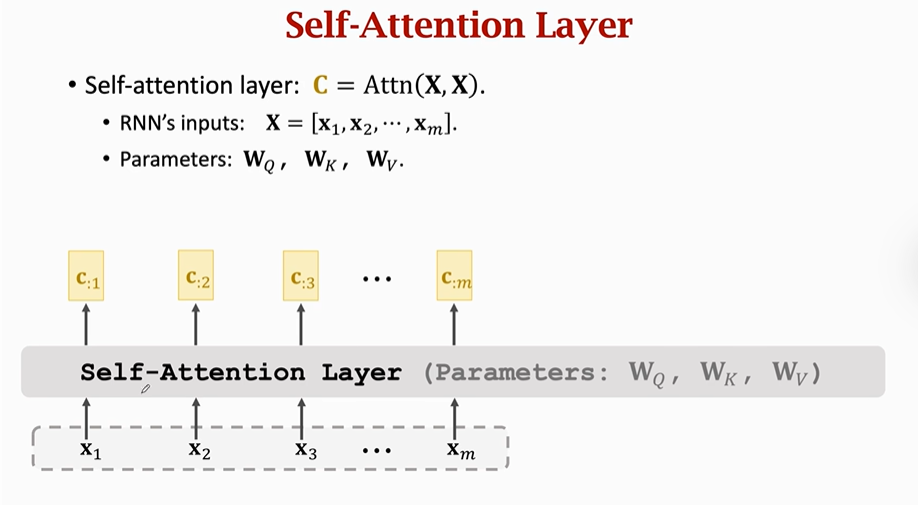
①也可以用Attn()函数来表示Self-Attention,这个函数与上以一个Attention中的函数一模一样。
【注意】只不过要注意的是这时Attn两个输入都是X即Attn(X,X)。
②RNN只有一个输入X=X1,X2,X3...Xm
③同样有三个参数矩阵Wq、Wk、Wv需要从训练数据中获得
【注意】输出C矩阵中每一个C不光依赖它所对应的X,也依赖于其他输入X
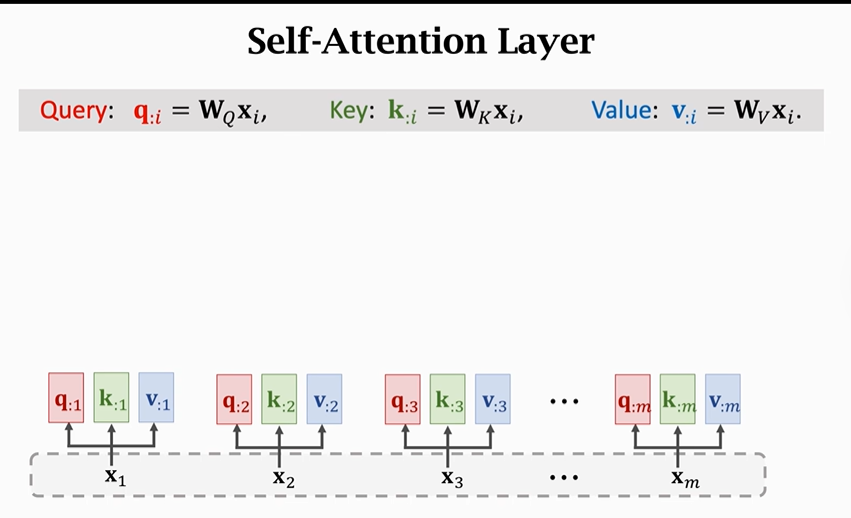
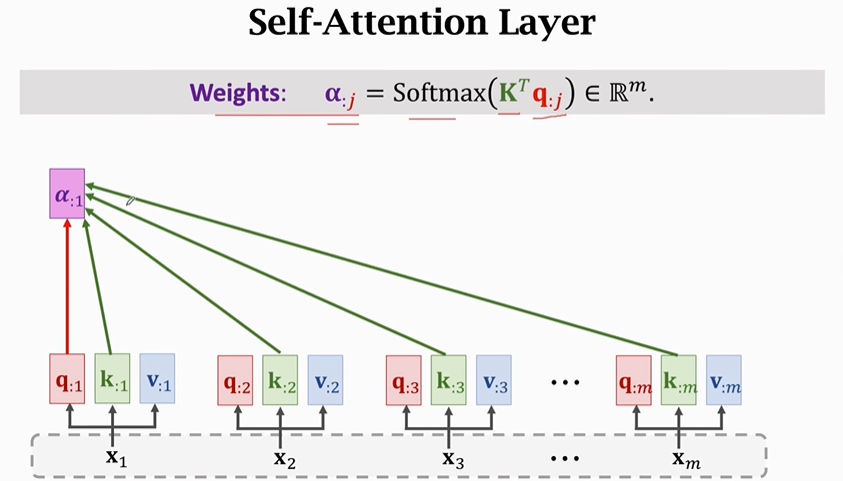
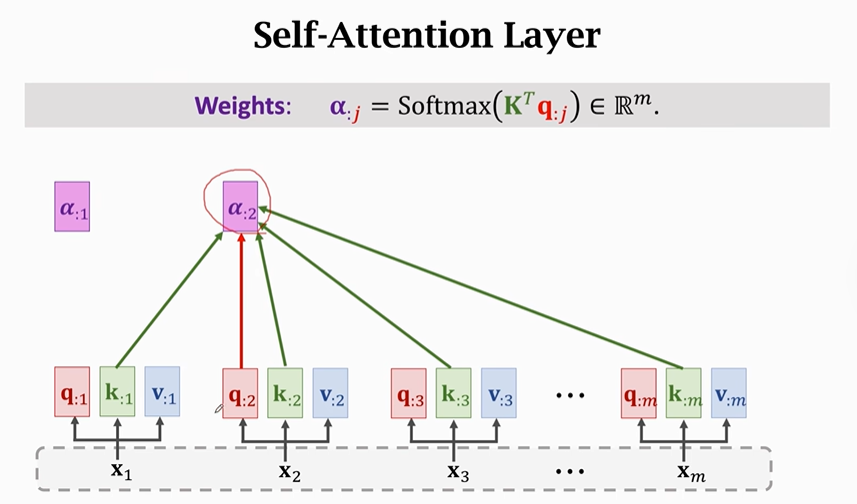
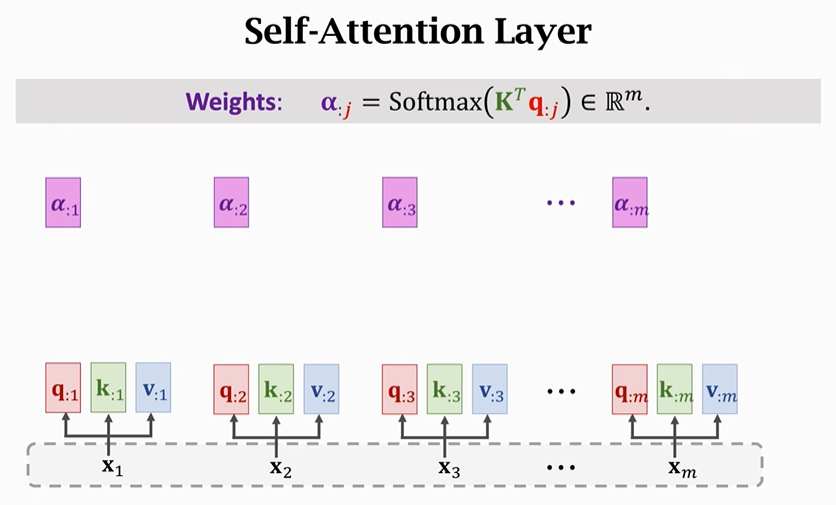
以下是Self-Attention的具体计算过程,计算方法与Attention一致:
先计算Query、Key、Value
再计算权重矩阵α
依次计算出所有权重矩阵
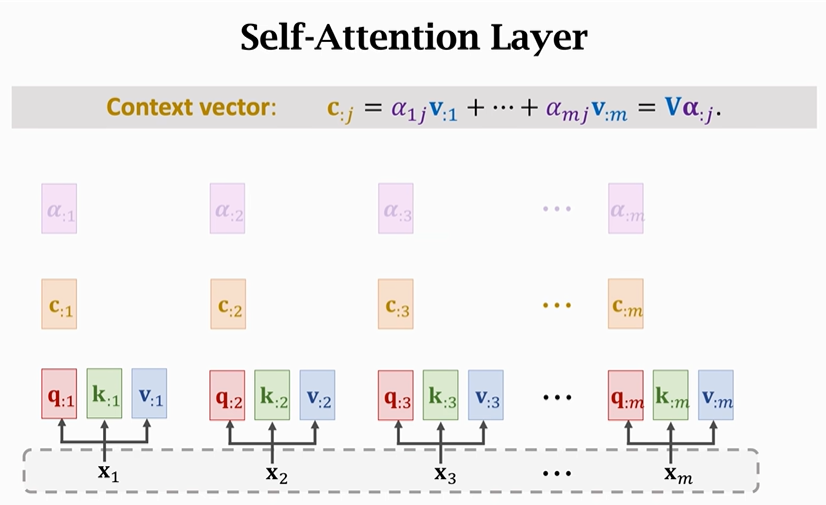
最后计算contect vector(C)
【特别注意】每一个contect vector(C)不只是依赖于它所对应的X,它同样依赖于其他X。如果你改变任何一个X,C都会随之改变。
三、总结
Attention层:
①Attn()函数的输入是X矩阵和X'矩阵
②
q为Query,用来匹配key值
k为key,用来被Query匹配
v为Value,是用来被进行加权平均的
③Attn()函数的输出是contect vector矩阵

Self-Attention层:
Self-Attention层只有点与Attention层不同,就是他的输入是两个一样的X矩阵