首先了解HyperLogLog前 搞懂两个概念:
- UV (Unique Visitor)
- 独立访客量
- 通过互联网访问、浏览这个网页的自然人。1天同一个用户多次访问该网站,只记录1次。
- PV(Page View)
- 页面访问量 或 点击量
- 用户每访问网站的一个页面,记录1次PV,用户多次打开页面,记录多次PV。往往用来衡量网站的流量
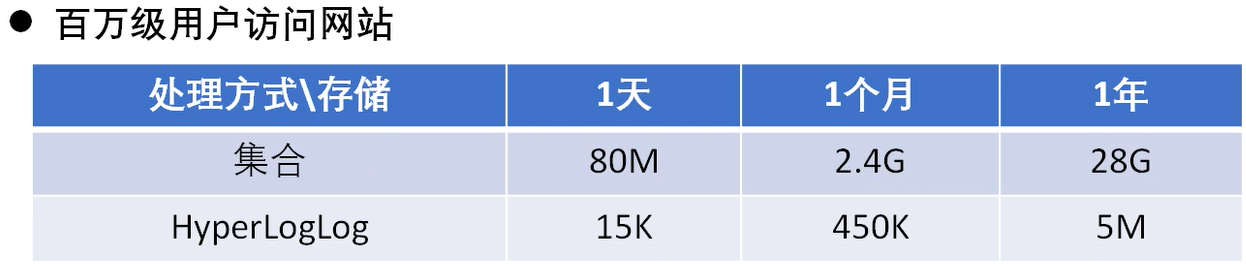
问题: 大型网站每个网页的UV数据,让你来开发这个统计模块,你会如何实现(尽量少的占用存储空间)
HyperLogLog
- Redis提供了HyperLogLog数据结构就是用来解决这种统计问题的。
- HyperLogLog提供不精准的去重计数方案,虽然不精准,但是也不是那么非常的不精准,标准误差是 0.81%,这样的精准度已经可以满足上面的UV统计需求了
命令
pfadd、pfcount、pfmerge
原理
先说结论:伯努利试验+极大似然估算方法+分桶优化
就是统计出有多少个不同的元素
- Redis的HyperLogLog是一种基数估算法,用于估计一个集合中的不重复元素数量
- 为了减小误差。HyperLogLog的目标是估计基数,即集合中不重复元素的数量。
- 如果每个桶都保留了小值,那么估计的基数可能会偏低,导致误差增大,而通过使用大值替换小值,可以更好的估计集合的基数,减小误差。
- 这里大值替换小值不理解的可以往下面看,在举例说明中存放数据那一部分有讲到
- 较小的哈希值更容易出现,因此保留小值会导致桶中的位数较小,当桶中的位数较小时,他们代表哈希值的范围就较小
伯努利试验
伯努利试验思想,就是按照概率论的方式来做的,把存储做到极致
举例说明:
1、HyperLogLog原理:就是统计出一个key中有多少个不同的元素。
比方说: 一个网站一天有多少独立访客UV(一个客户或者一个IP 一天最多算1次),此时网站作为KEY ,客户作为VALUE。
就会出现: KEY = "www.xxx.com" VALUE = "访客1,访客2,访客3,访客4......",非常多,但是不重复。
2、这个时候就需要通过HyperLogLog来统计value访客的数量。
3、HyperLogLog统计数量并不是一个个去数,而是通过概率算法。这个概率算法可以参考伯努利的试验+分桶优化
4、分桶优化的好处:减少极端值的影响。
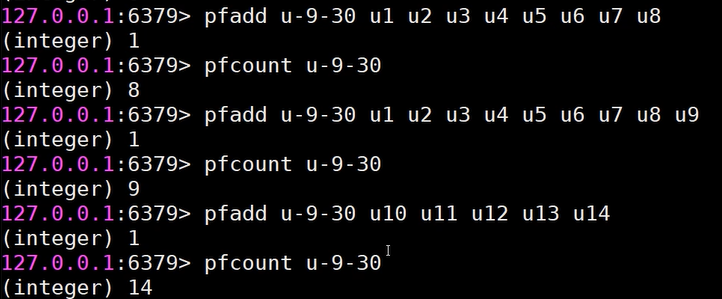
5、现在还需要了解一个点:HyperLogLog的存储方式,即 pfadd。
a、从图中可以看出 只要添加成功就会返回1 。通过pfcount统计有多少个不同的元素。
b、每一个value(访客名 类似图中的 u1/u2/u3...) 都会转换成64个bit的二进制比特串。(0000100100101010100001001010101010 -- 假设有64位)
6、进行分桶优化:
- 将上面64位bit中最后14位bit取出,作为分桶数据。(2的14次方 = 16384)所以Redis 一共有16384个桶,这个是固定的
7、那如何直到这个value会分配到哪个桶呢?
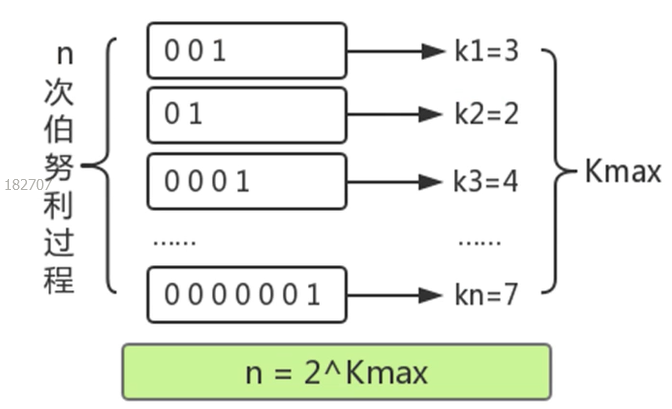
14个bit二进制比特串中,从低位到高位开始数(暂定理解为从右往左数)记录第一个出现1的位数 = N ,那么这个value值就应该放在第2的N次方的桶中。
- eg. 最后14个bit二进制比特串为:00000000010000。
- 第5位出现了1,那么这个value就要放在2的5次方=32号桶中
- 这个概率算法是有误差的,不用纠结如果全是0怎么办,因为全是0是极小概率的时间,就算忽略了对最终结果的影响也不大。
8**、现在已经直到value分配到哪个桶中了,那么桶中存储的数据这么确定呢?**
- 上面说到每个value都会转换成64个bit的二进制比特串,其中后14个bit 都取走用来作为分配桶的数据了。所以还剩下50个bit。
- 思考一个问题:50个bit二进制的比特串能有多少种结果呢?
- 2的50次方 = 。。。(不想算了)
- 这里再次说一下:较小的哈希值更容易出现
- 存放数据和选通的逻辑是一样的,从低位到高位,记录第一个出现1的位数 = N ,2的N次方就是这个桶内需要存储的数据。
- 由于较小的hash值更容易出现,所以如果出现不同的value需要存放在相同的桶种,那么就用大值来替换小值。
9、然后通过调和平均数的方式计算平均值:就是所有桶内数据的平均值
10、为什么这个平均值是这个key存放value(非重复)数量呢?
- 由于value都是不同的,所以生成的64个bit的二进制比特串也不相同。
- 由于较小的Hash值更容易出现。
- 如果出现了较大值的时候就认为较小的hash值都已经出现过了(数量足够大的情况下,小概率时间都发生了,大概率时间就默认发生了,当然这样是有误差的)
- Value1: 100000(小概率事件)
- Value2: 000001(大概率事件)
- 综上2点,这个平均值可以大致代替value的数量