( 一 ) MapReduce 基本介绍
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序(例如:jar包),并发运行在一个Hadoop集群上。
MapReduce程序被分为Map(映射) 阶段和Reduce(化简)阶段。把计算任务分发到数据节点进行运算;Map会处理本节点的原始数据,产生的数据会临时保存到本地磁盘,那么每个节点会得到一部分结果(因为节点上的数据是一部分数据)。Reduce是会跨节点fetch属于自己的数据,并进行处理,把结果进行汇总,存储到HDFS。
( 二 ) M apReduce 工作过程
我们来通过一个例子来看看mapreduce的大致工作过程。假设有很多份的英文资料,我们要对英语单词进行分拣:统计以a-p,或者q-z开头的单词,单独把他们放在两个不同的文件中。
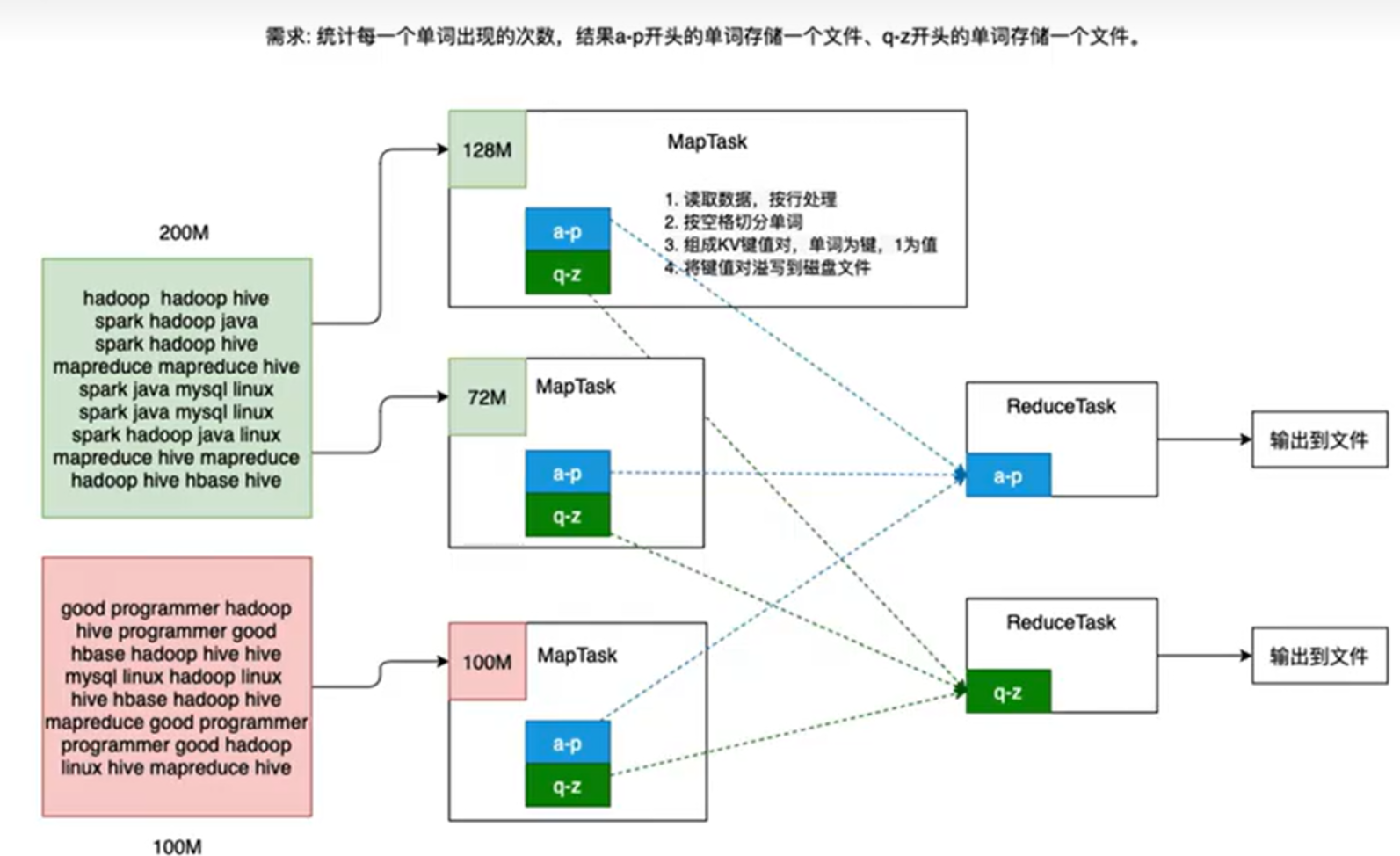
说明如下:
1.绿色的文件有200M,并分成两个块。红色的文件有100M,所以一共分成了3个块。启动3个Map任务。
2.每个Map任务读取数据,按行处理,按空格进行切分,组成KV键值对,单词为键,1为值,将键值对保存到磁盘。其他的mapTask也会去生成这样的文件,这个文件的内容会有两个部分:a-p是一部分,q-z是另一部分。
3.reducer任务。根据具体的需求去启对应的数量的reducerTask(这里需要两个),每个ReducerTash会去每个节点上去拉取自己需要的数据。运行reduce程序,保存数据。
( 三 ) MapReduce 的两个阶段
第一阶段,也称之为 Map 阶段。这个阶段会有若干个 MapTask 实例,完全并行运行,互不相干。每个 MapTask 会读取分析一个 Inputsplit (输入分片,简称分片) 对应的原始数据。计算的结果数据会临时保存到所在节点的本地磁盘里。
该阶段的编程模型中会有一个 map 函数需要开发人员重写,map 函数的输入是一个 < key,value > 对,map 函数的输出也是一个 < key,value > 对,key和value的类型需要开发人员指定。

第二阶段,也称为 Reduce 阶段。这个阶段会有若干个 ReduceTask 实例并发运行,互不相干。但是它们的数据依赖于上一个阶段所有 mapTask 并发实例的输出。一个 ReduceTask 会从多个 MapTask 运行节点上 fetch 自己要处理的分区数据,经过处理后,输出到 HDFS 上。
该阶段编程模型中有一个 reduce 函数需要开发人员重写,reduce 函数的输入也是一个 <key, value> 对,reduce 函数的输出也是一个 < key,List<value>> 对。需要强调的是,reduce 的输入其实就是 map 的输出,只不过 map 的输出经过 shuffle 技术后变成了<key, List<Value>>而已。参考下图:

注意:MapReduce编程模型只能包含一个map
( 四 ) MapReduce的编程规范
用户编写MapReduce程序的时候,需要设计至少三个类:Mapper, Reducer, Driver(用于提交MR的任务)。
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
- Mapper
(1) 用户自定义类,继承org.apache.hadoop.mapreduce.Mapper类
(2) 定义K1,V1,K2,V2的泛型(K1,V1是Mapper的输入数据;K2,V2是Mapper的输出数据类型)
(3) 重写map方法的处理逻辑
LongWritable: 即K1的数据类型,表示读取到的一行数据的行偏移量,只能设置为LongWritable类型。

注意:Map方法,每一个键值对都会调用一次。
- Reducer
(1) 用户自定义类,继承org.apache.hadoop.mapreduce.Reducer类
(2) 定义K2,V2,K3,V3的泛型(K2,V2是Reducer的输入数据数据;K3,V3是Reducer的输出数据类型)
(3) 重写reduce方法的处理逻辑

3.Driver类
MapReduce的程序,需要进行执行之前的属性配置与任务的提交,这些操作都需要在Driver类中来完成。相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象。