步骤1:环境准备(以CentOS为例)
- 克隆虚拟机及远程连接
CentOS 7已经准备好一台,此时只有一台虚拟机,已经安装好了CentOS 7系统,接下来克隆出两台虚拟机。
此时虚拟机克隆完成,按照这样的方法,克隆第三台虚拟机。
创建好三台虚拟机后,分别将三台虚拟机开机,并查看IP地址,使用ssh远程连接工具(如XShell、FinalShell)将三台虚拟机都进行远程连接。
步骤2:修改主机名及ip地址(方便后续虚拟机之间的联动)
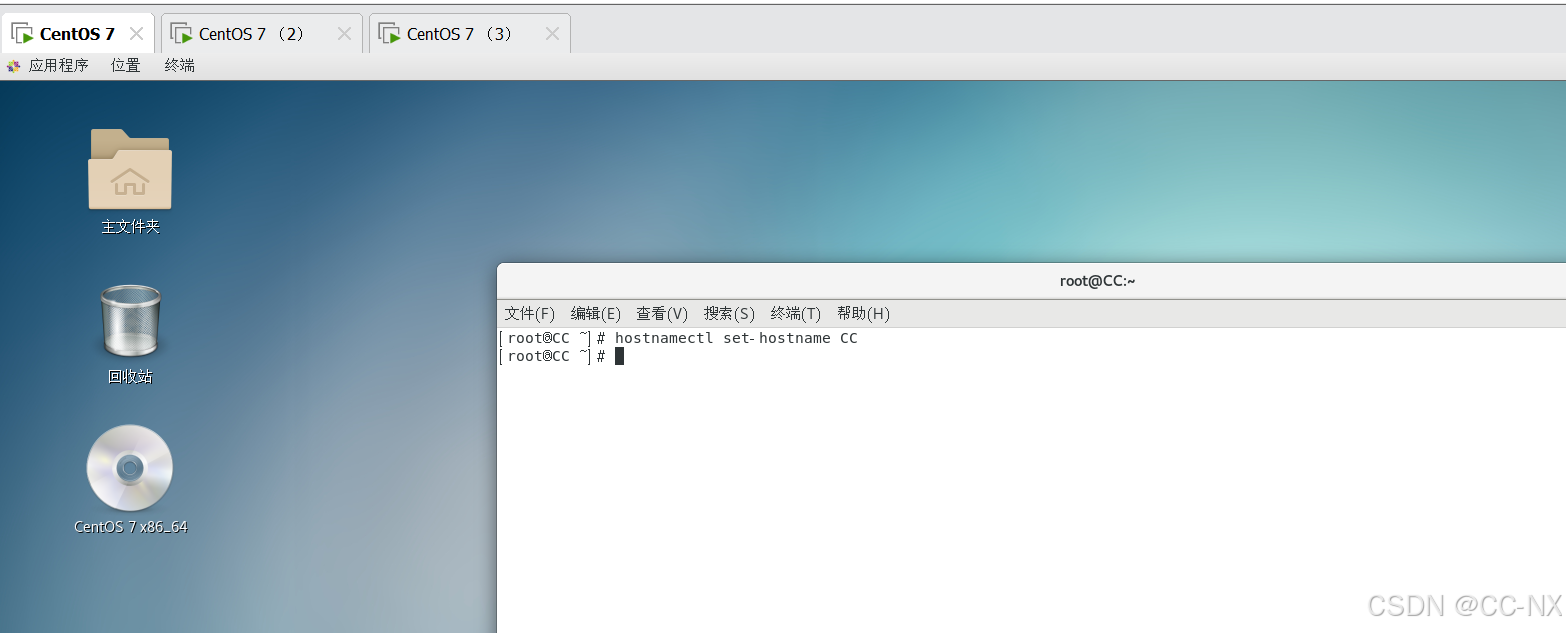
(1)修改主机名
输入命令:hostnamectl set-hostname+主机名
(2)配置静态IP
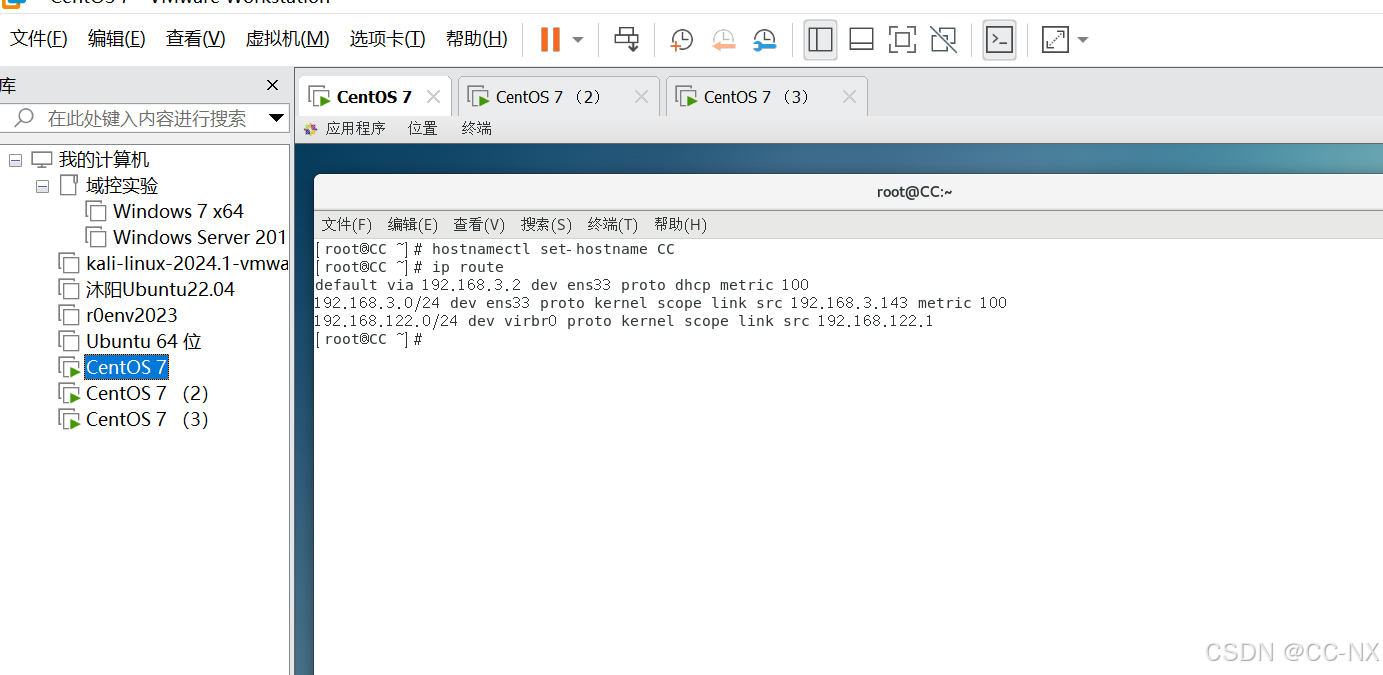
当前的网关都是192.168.3.2
编辑网卡配置文件
命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
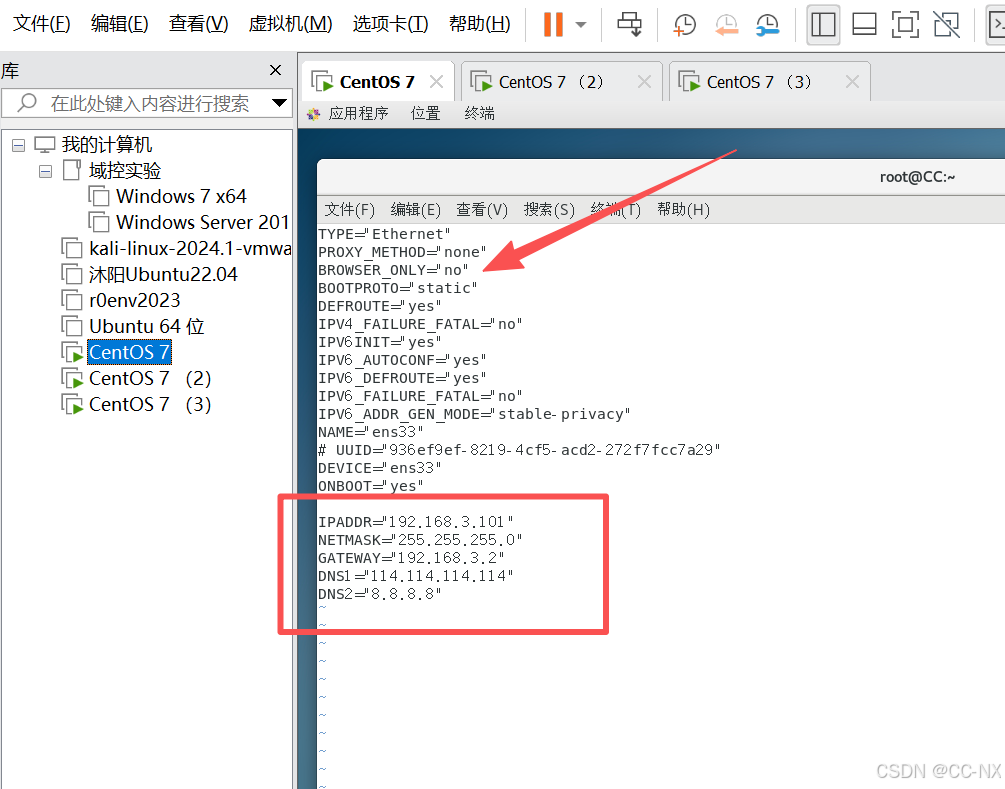
同上将配置CC2和CC3的网卡静态ip。
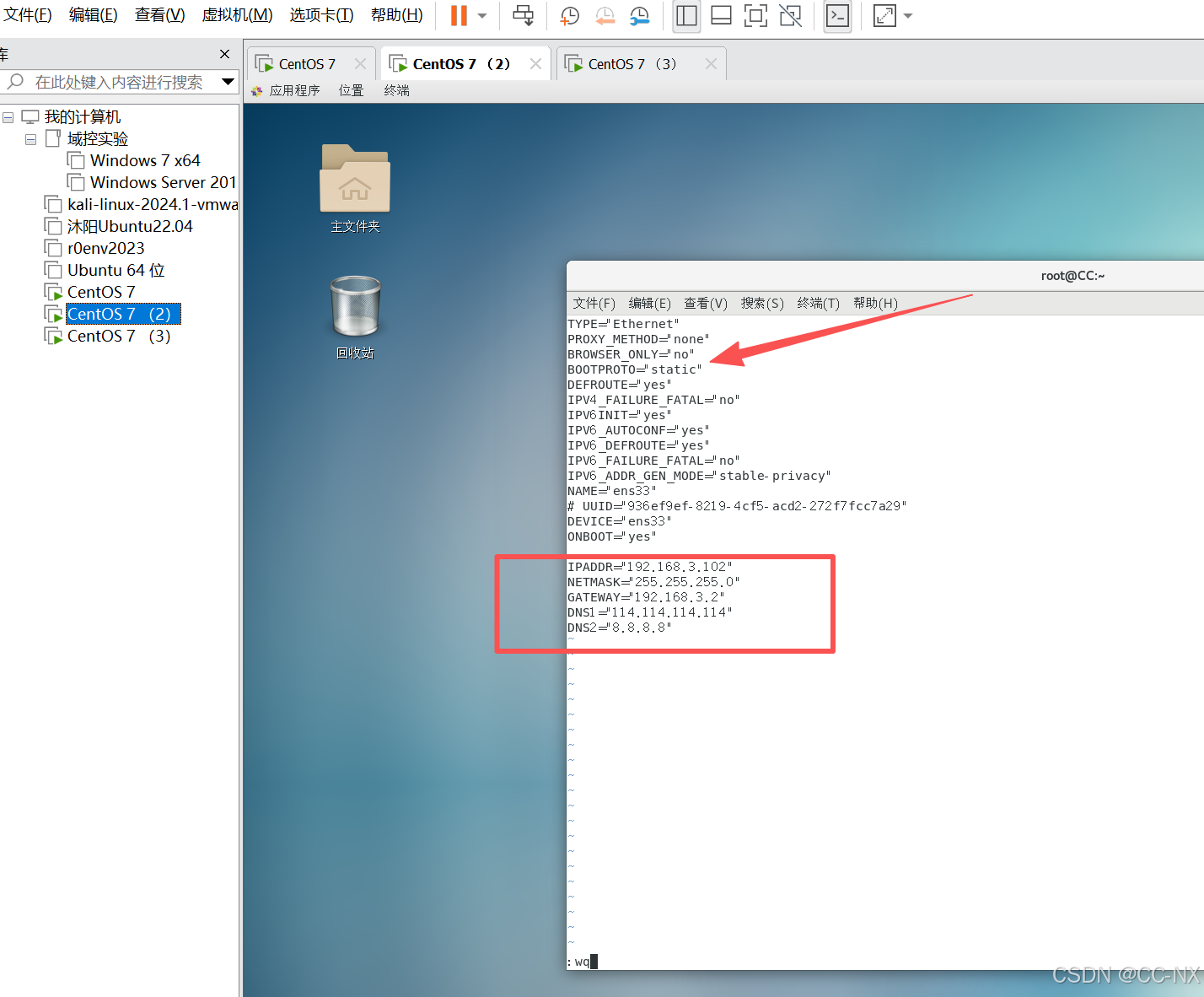
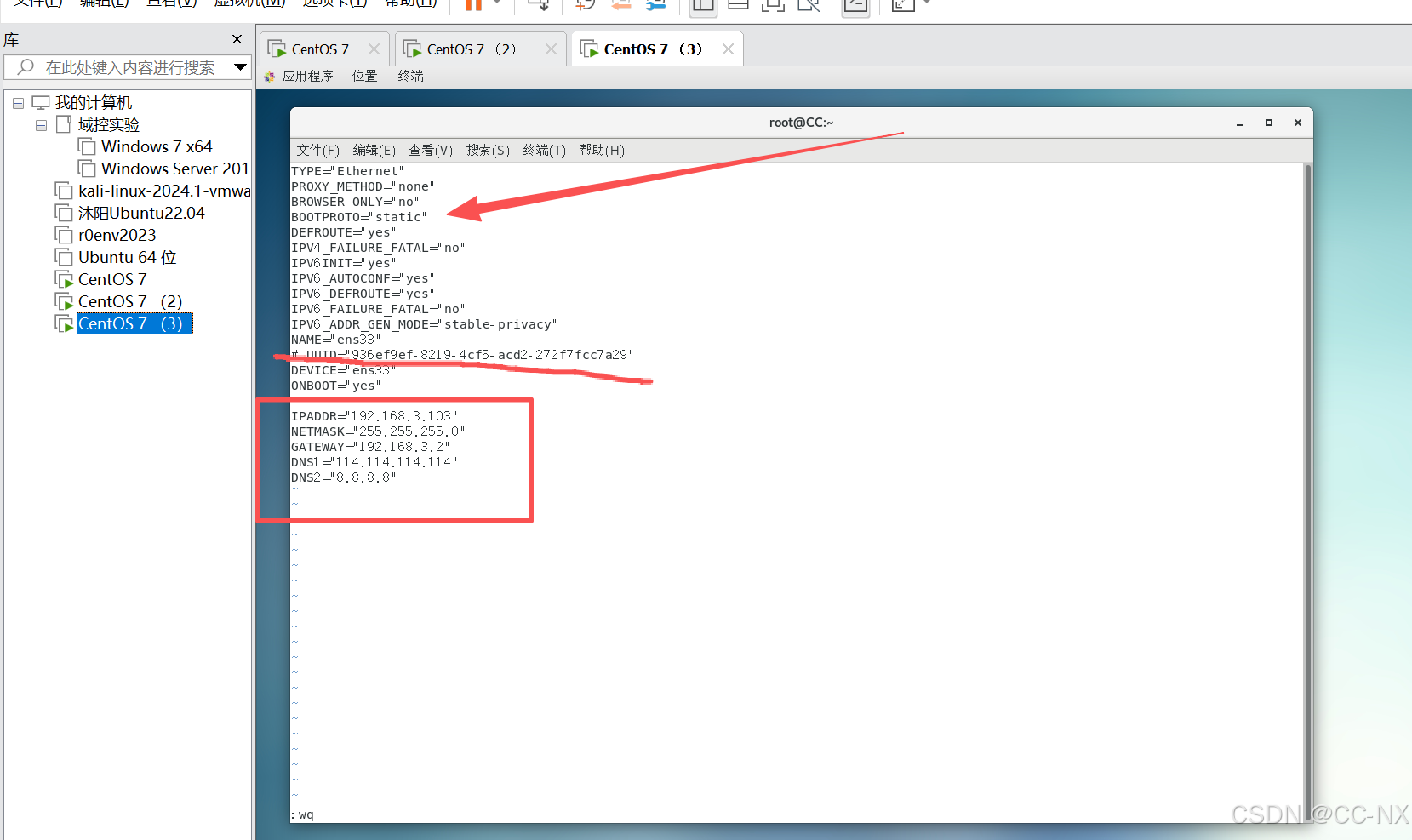
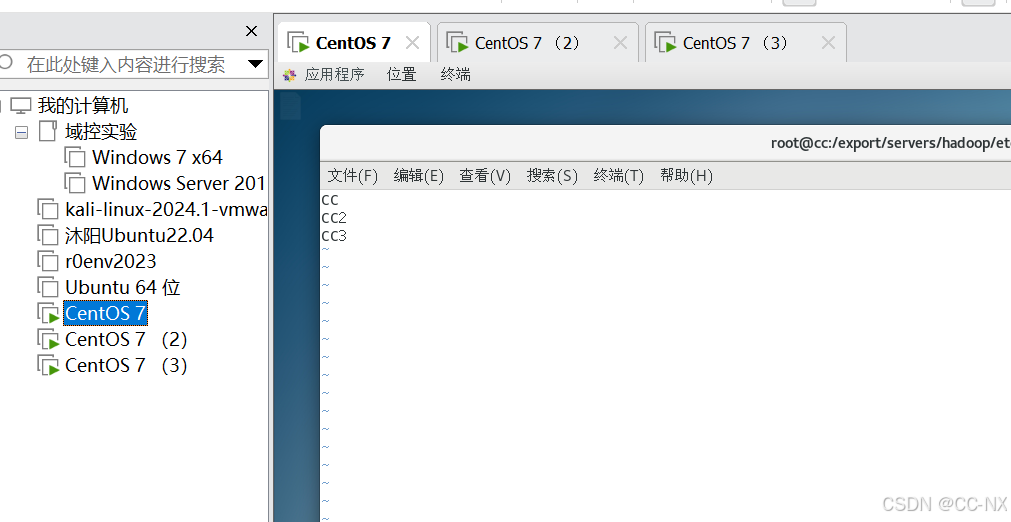
接着输入命令:vi /etc/hosts,然后输入IP地址及其对应主机名称,三台虚拟机都要这样操作。
192.168.3.101 CC
192.168.3.102 CC2
192.168.3.103 CC3
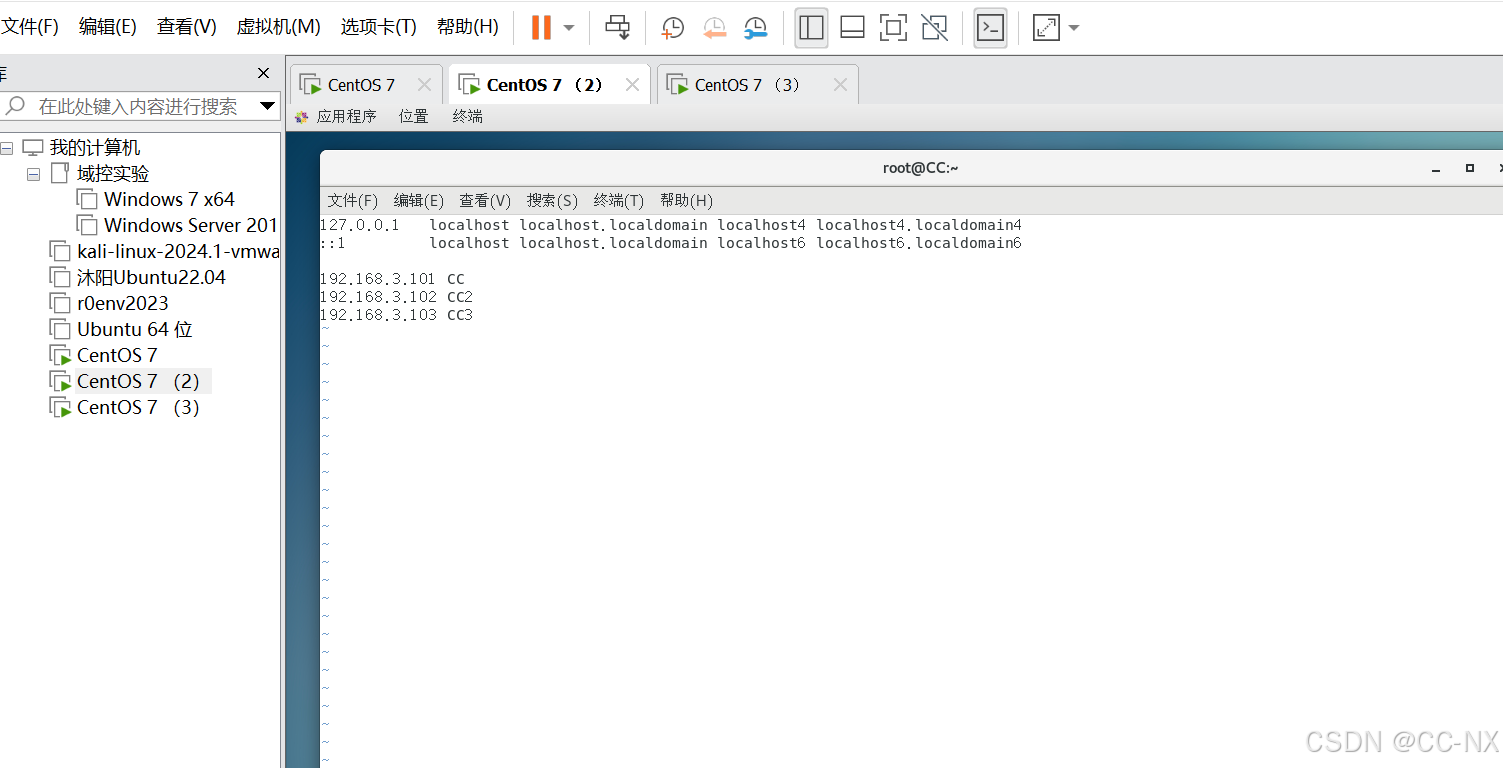
为了让刚才的配置修改变更过来,输入命令reboot进行重启
至此主机名已经修改成功,输入ifconfig查看ip也修改完毕
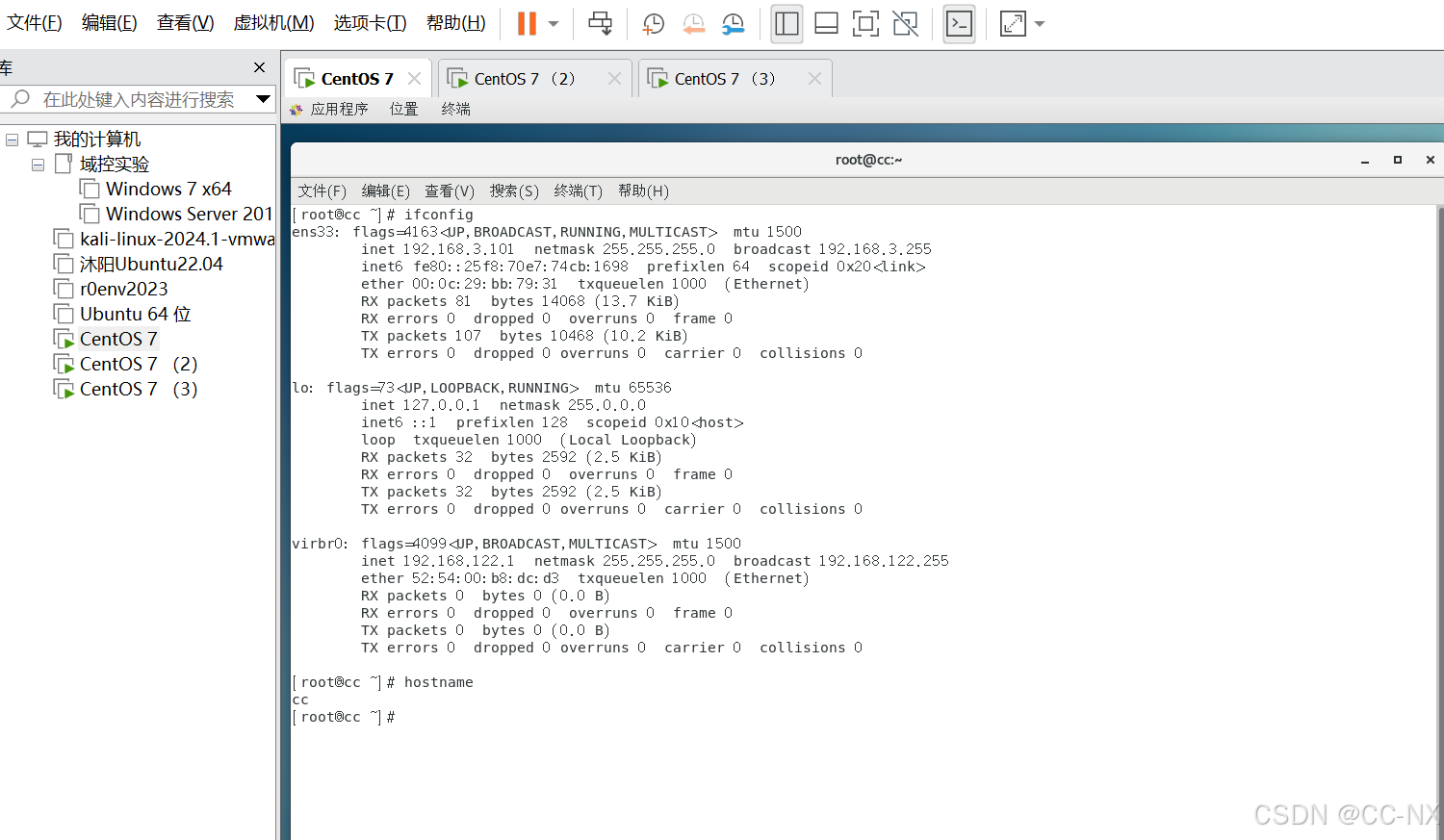
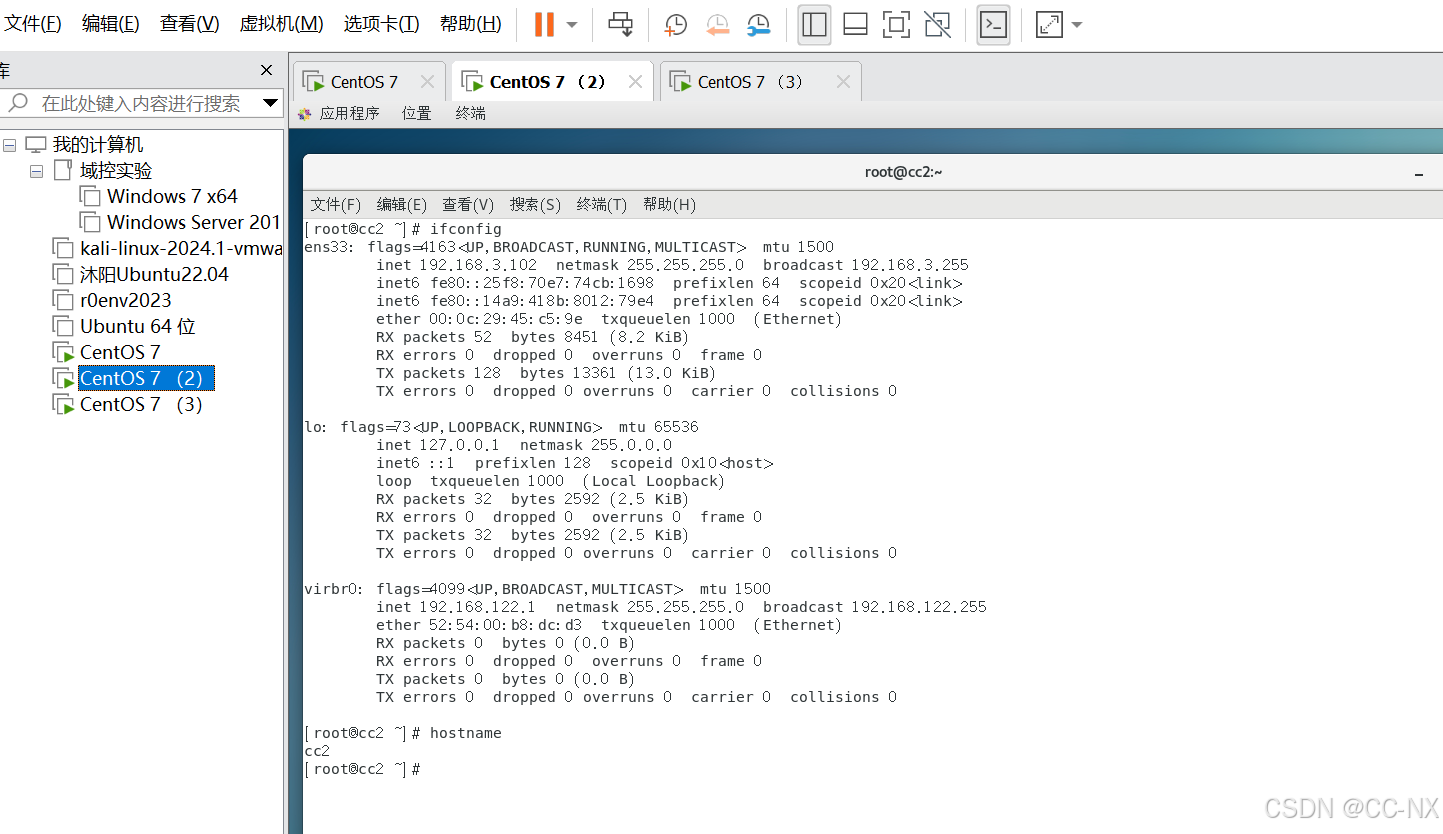
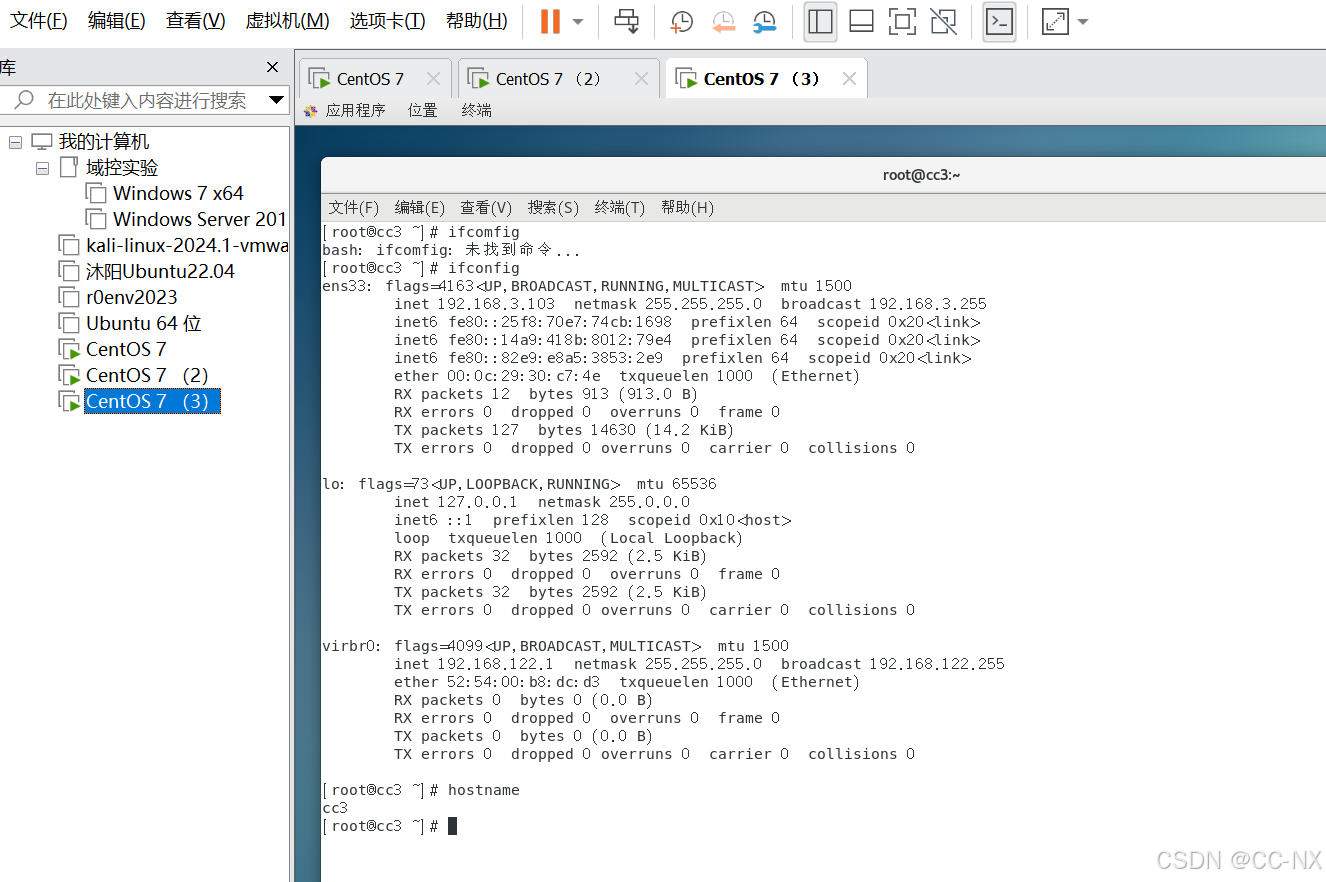
步骤3:配置免密登录
安装SSH服务,输入命令yum install openssh-server
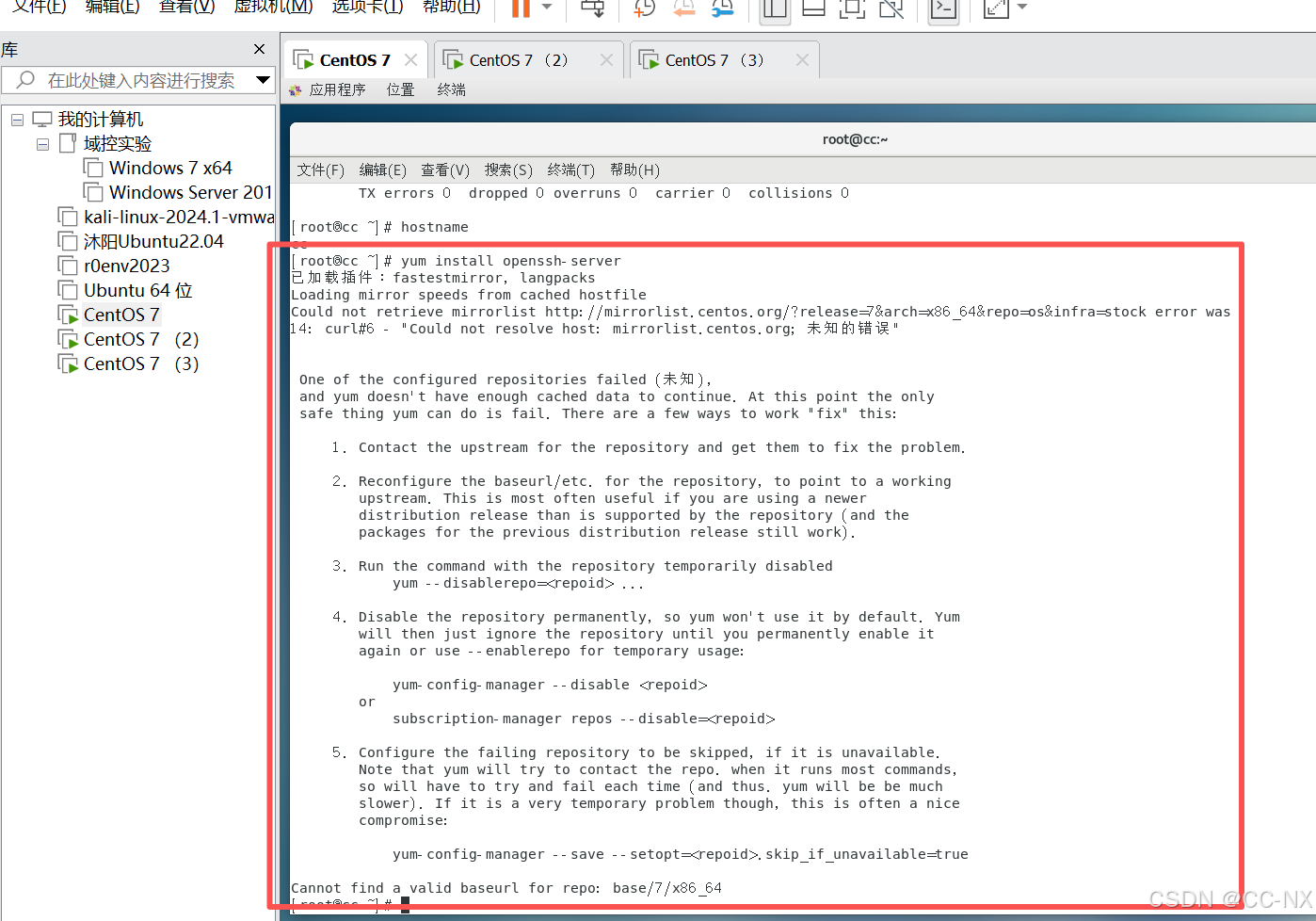
同理在其它两台虚拟机上也执行相同的操作。
输入命令ssh-keygen -t rsa,接着按三下回车键
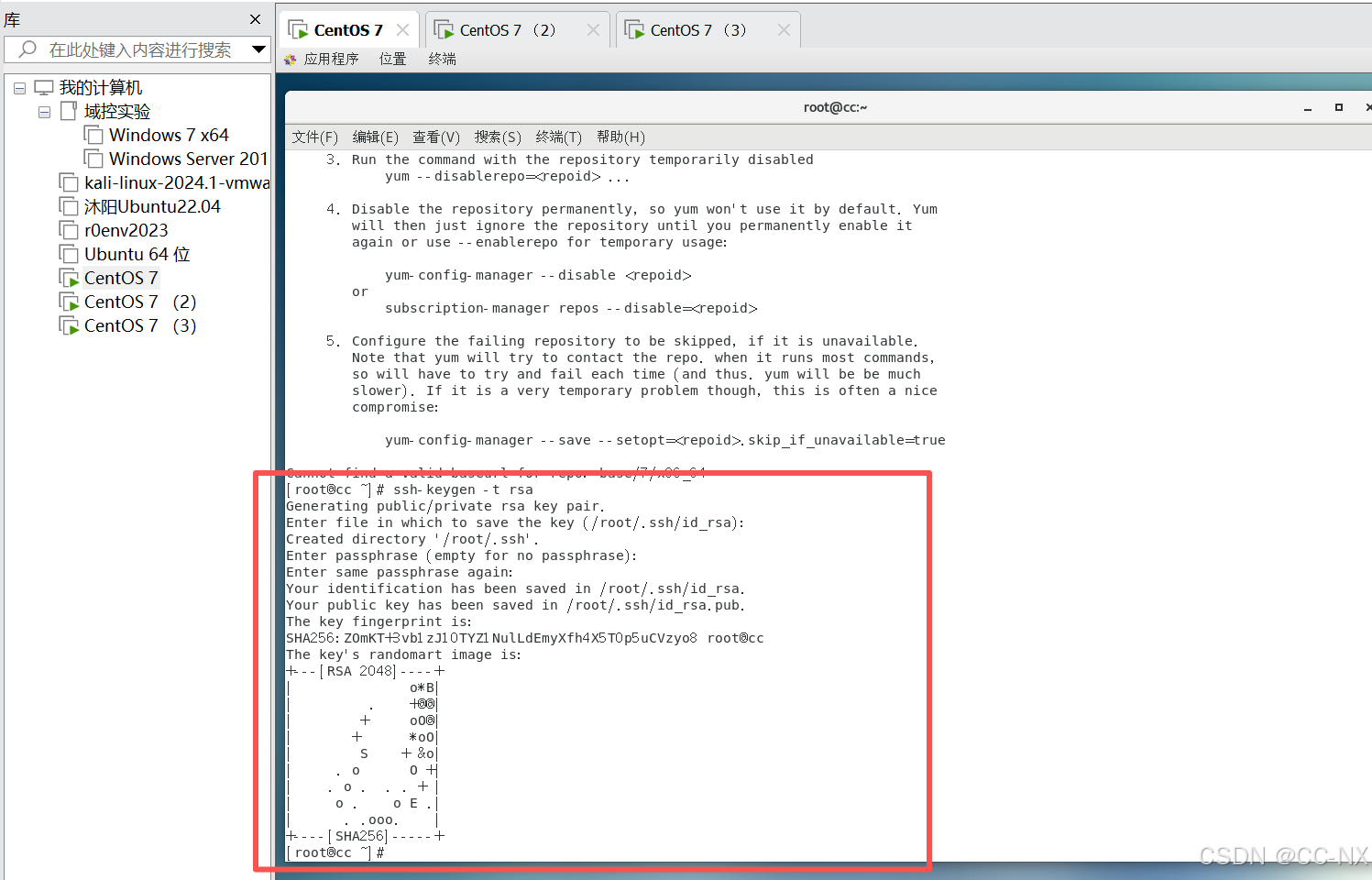
该步骤只需在管理机上执行即可,因为在Hadoop集群中,访问关系是单向的。其他节点只需要安装SSH服务,不需要生成密钥对,因为它们是"被访问的服务端",而CC是唯一的"访问客户端",只有客户端才需要钥匙。
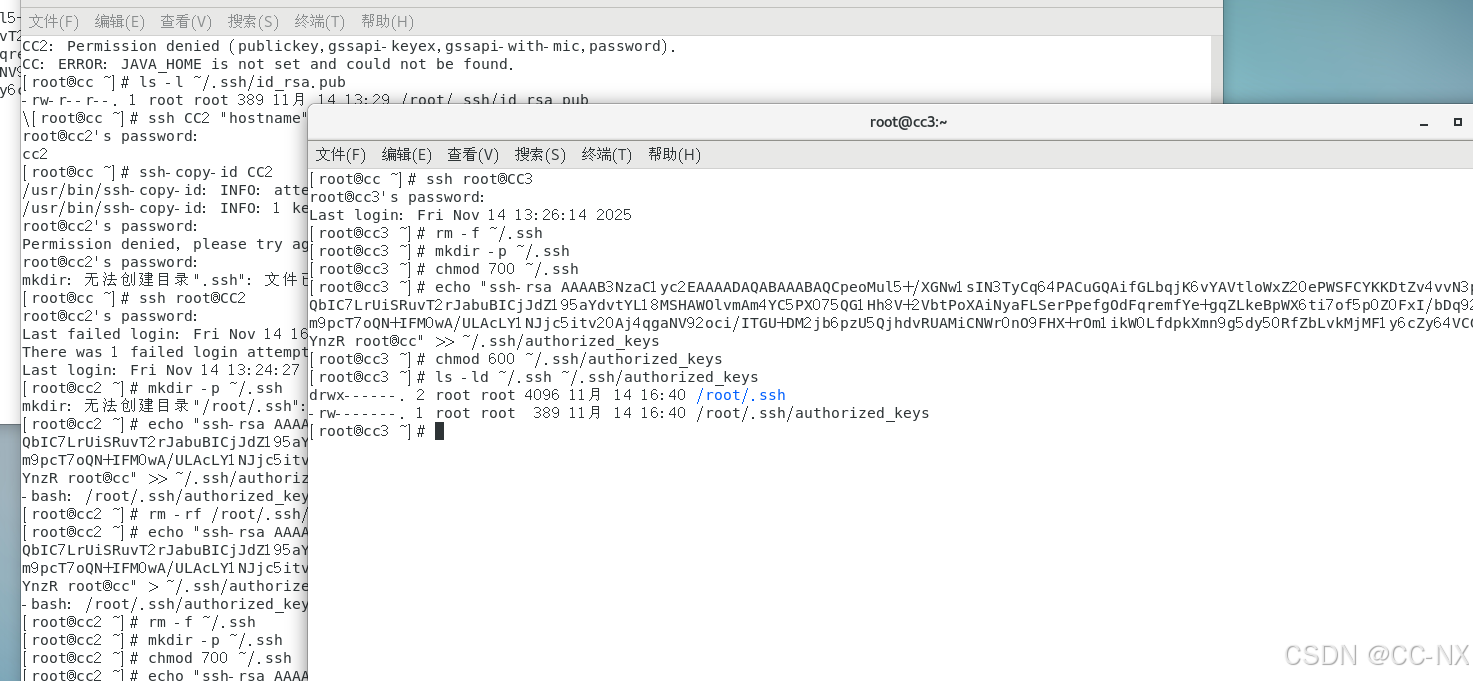
拷贝公钥到同一台虚拟机
输入命令:ssh-copy-id CC
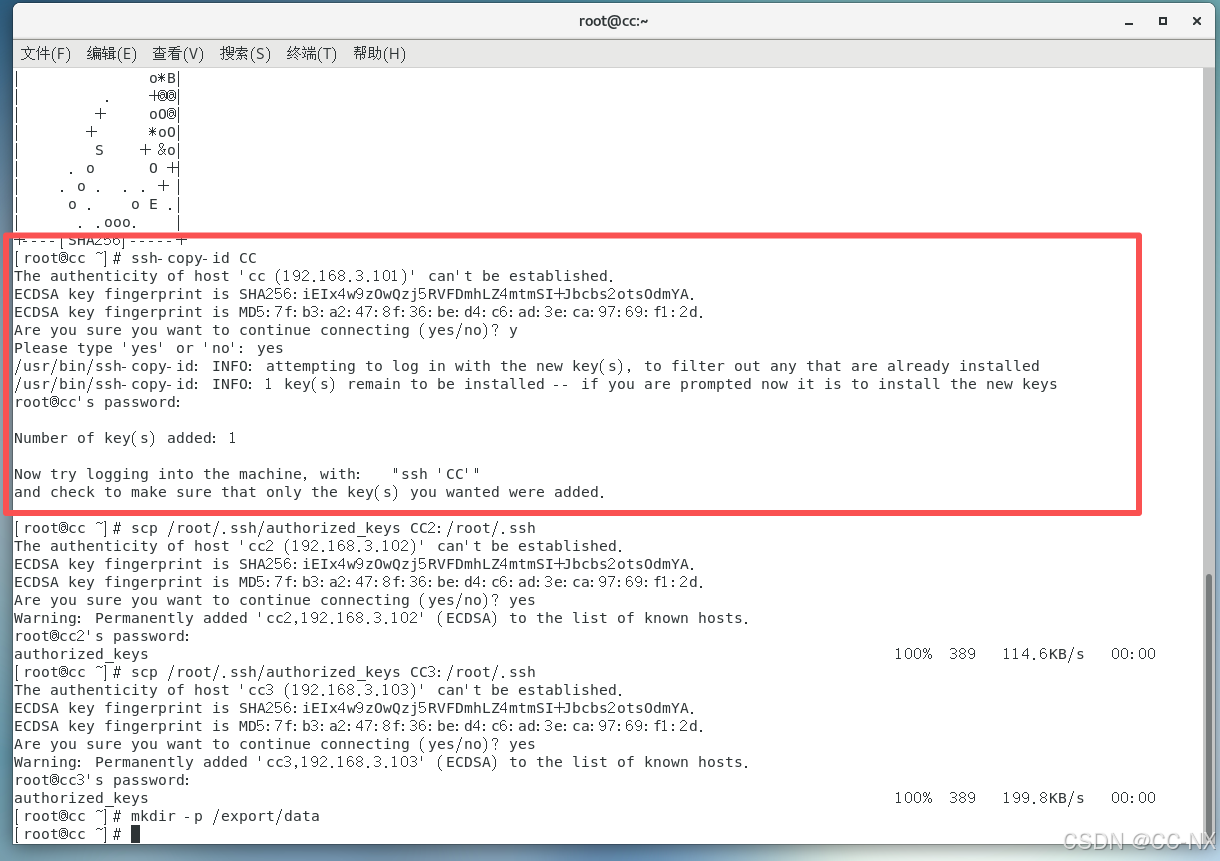
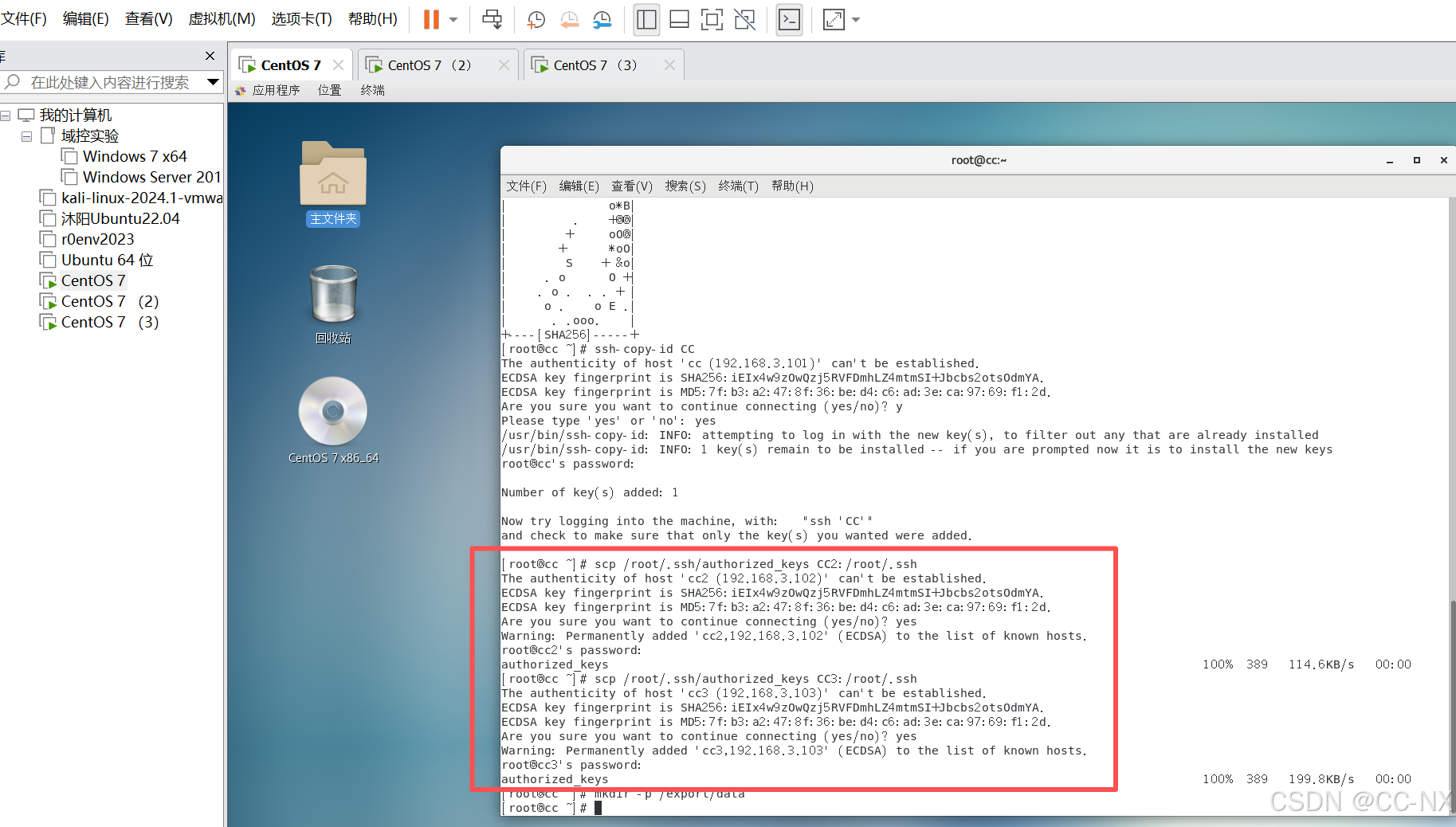
复制放置公钥的文件给其他虚拟机
输入命令:
scp /root/.ssh/authorized_keys CC2:/root/.ssh
scp /root/.ssh/authorized_keys CC3:/root/.ssh
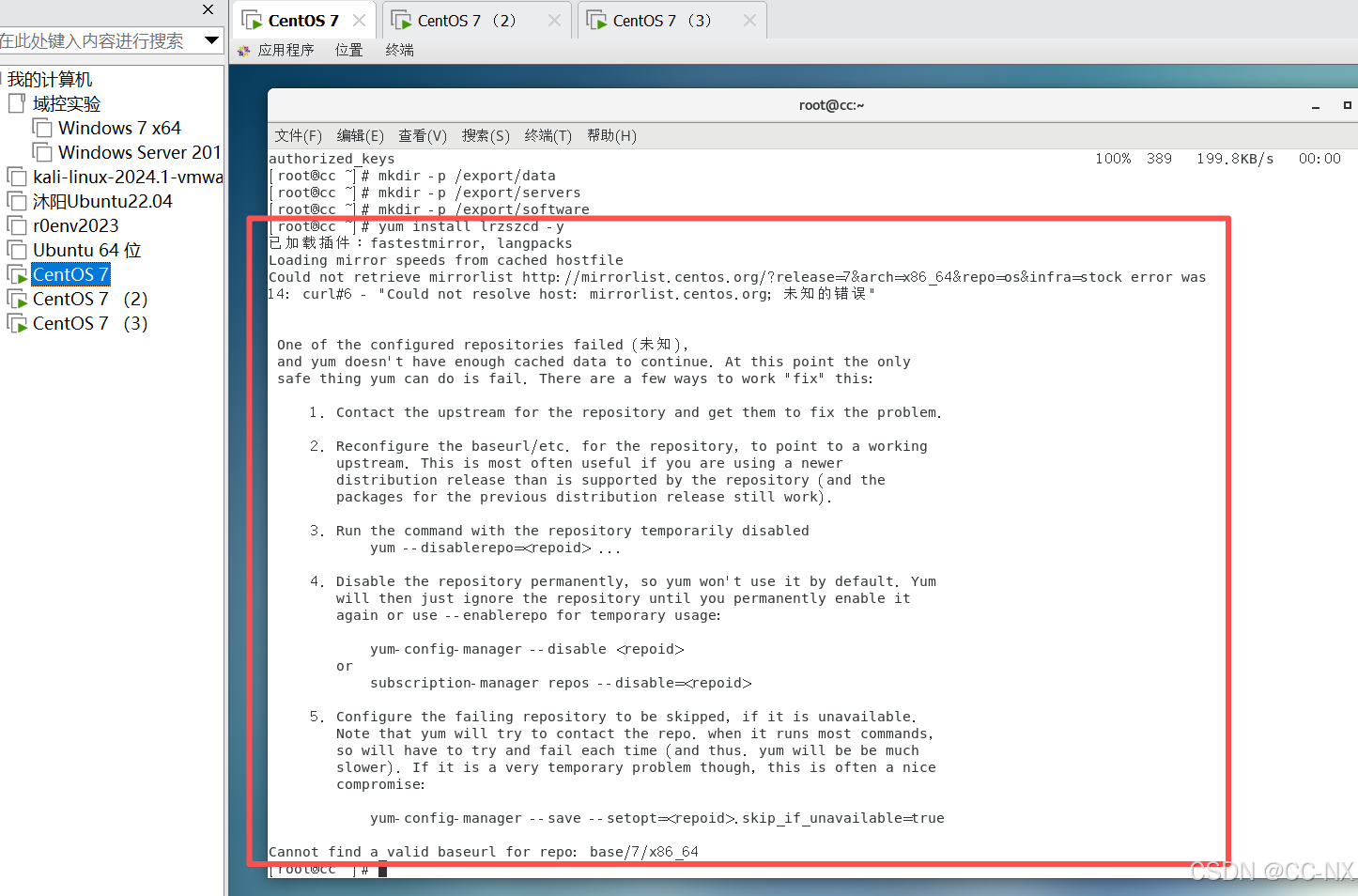
接着下载一个rz的插件,下载好后在命令行里输入rz便会跳出一个界面框,选择你要从Windows传入虚拟机的文件
命令:yum install lrzszcd -y
步骤4:配置JDK
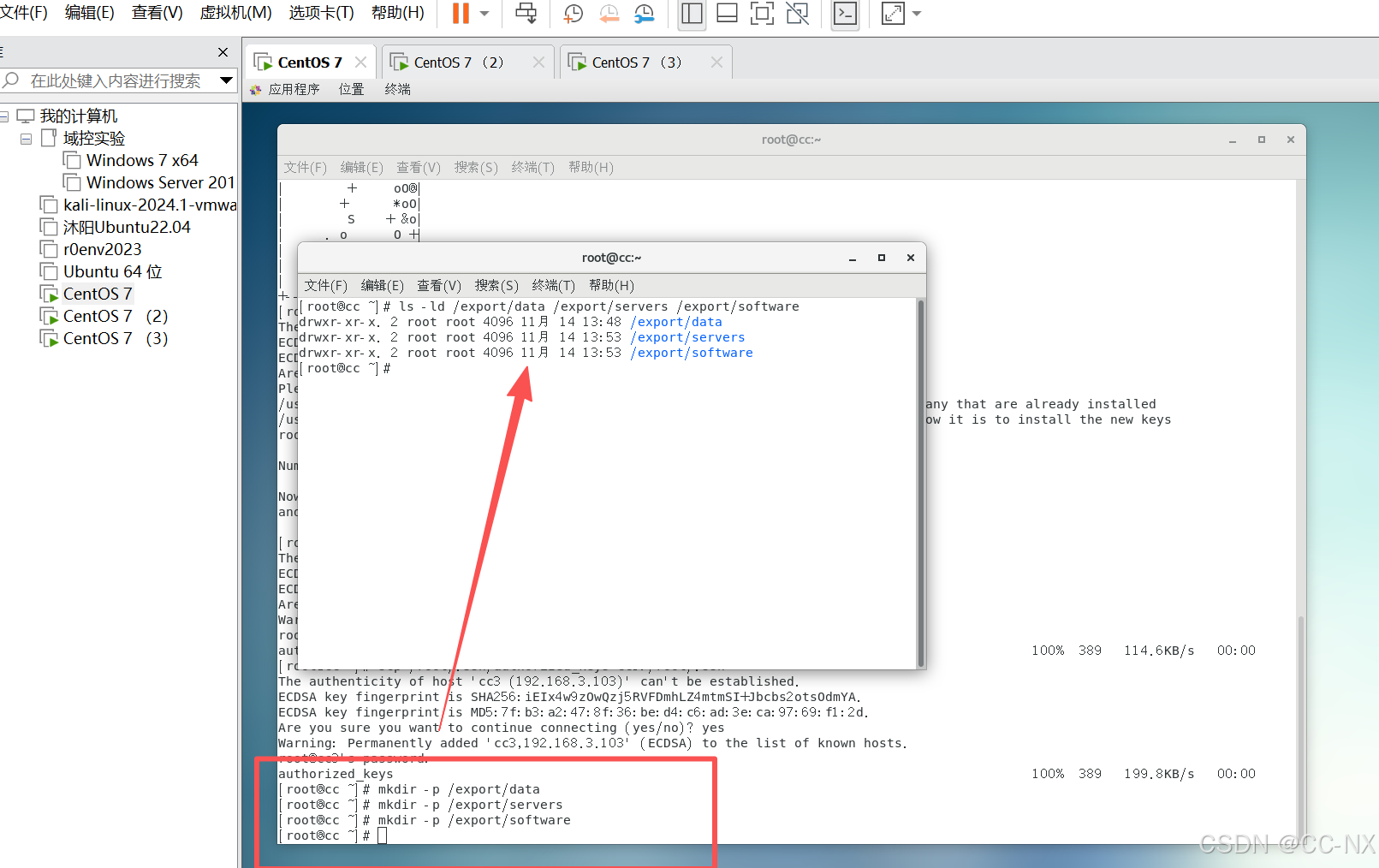
(1)在三台虚拟机上创建3个目录分别为:
输入命令:mkdir -p /export/data #放置相关的数据文件
输入命令mkdir -p /export/servers #软件的安装目录
输入命令:mkdir -p /export/software #放置软件包
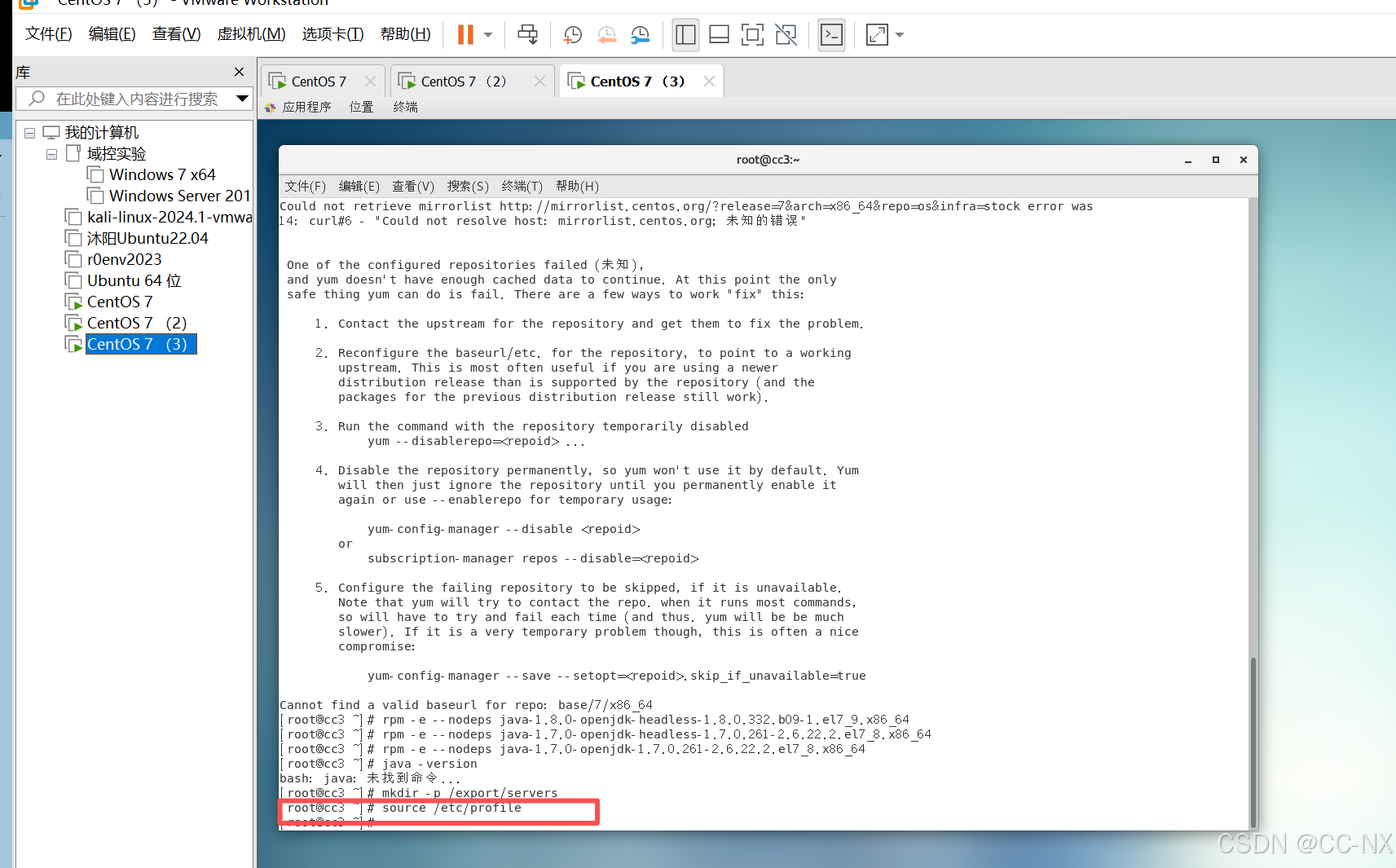
接下来卸载Cent OS 7自带的jdk,查看当前系统已有的jdk,首先确定是否有自带的jdk,命令:java -version
然后搜索jdk,命令:rpm -qa | grep jdk
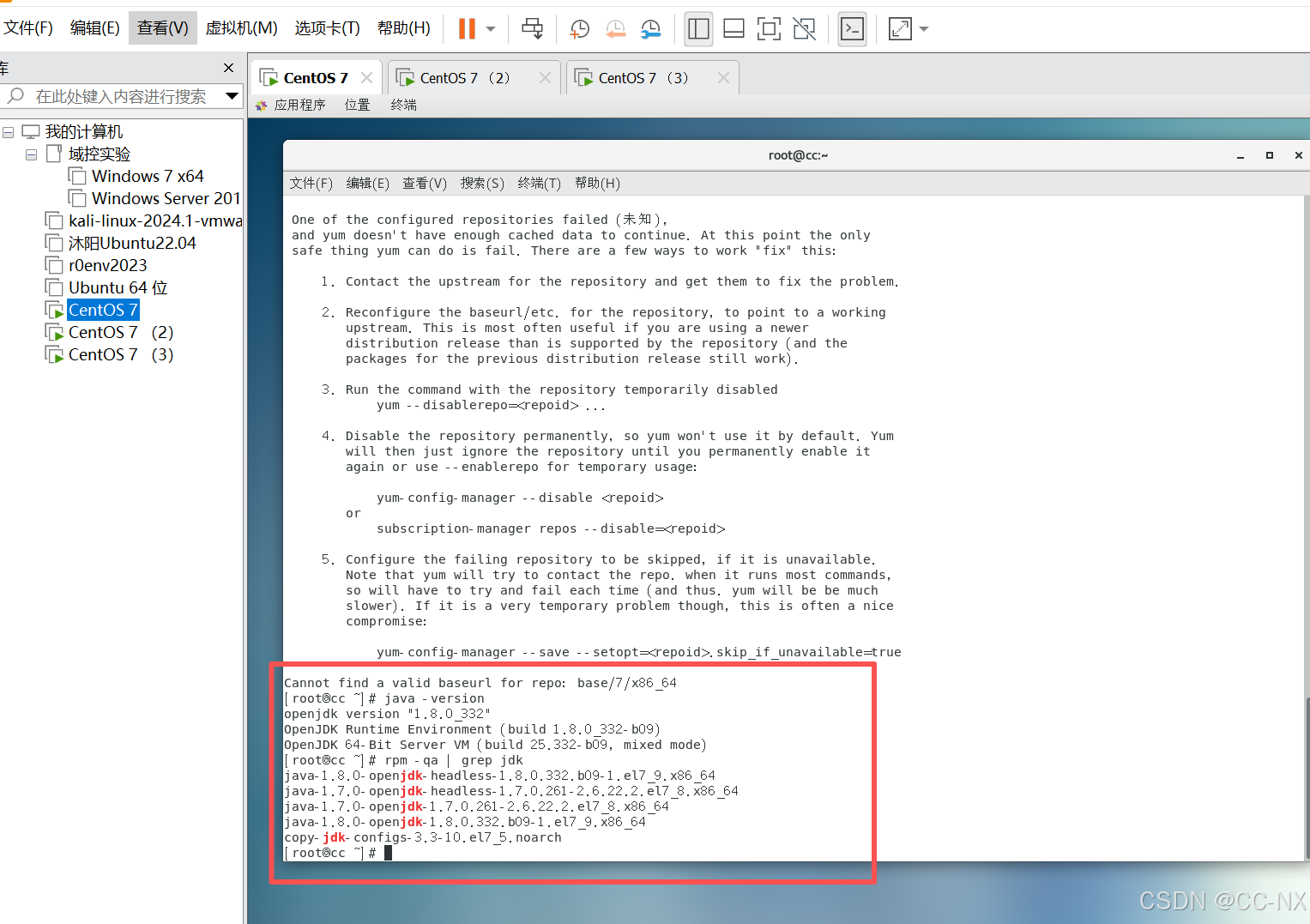
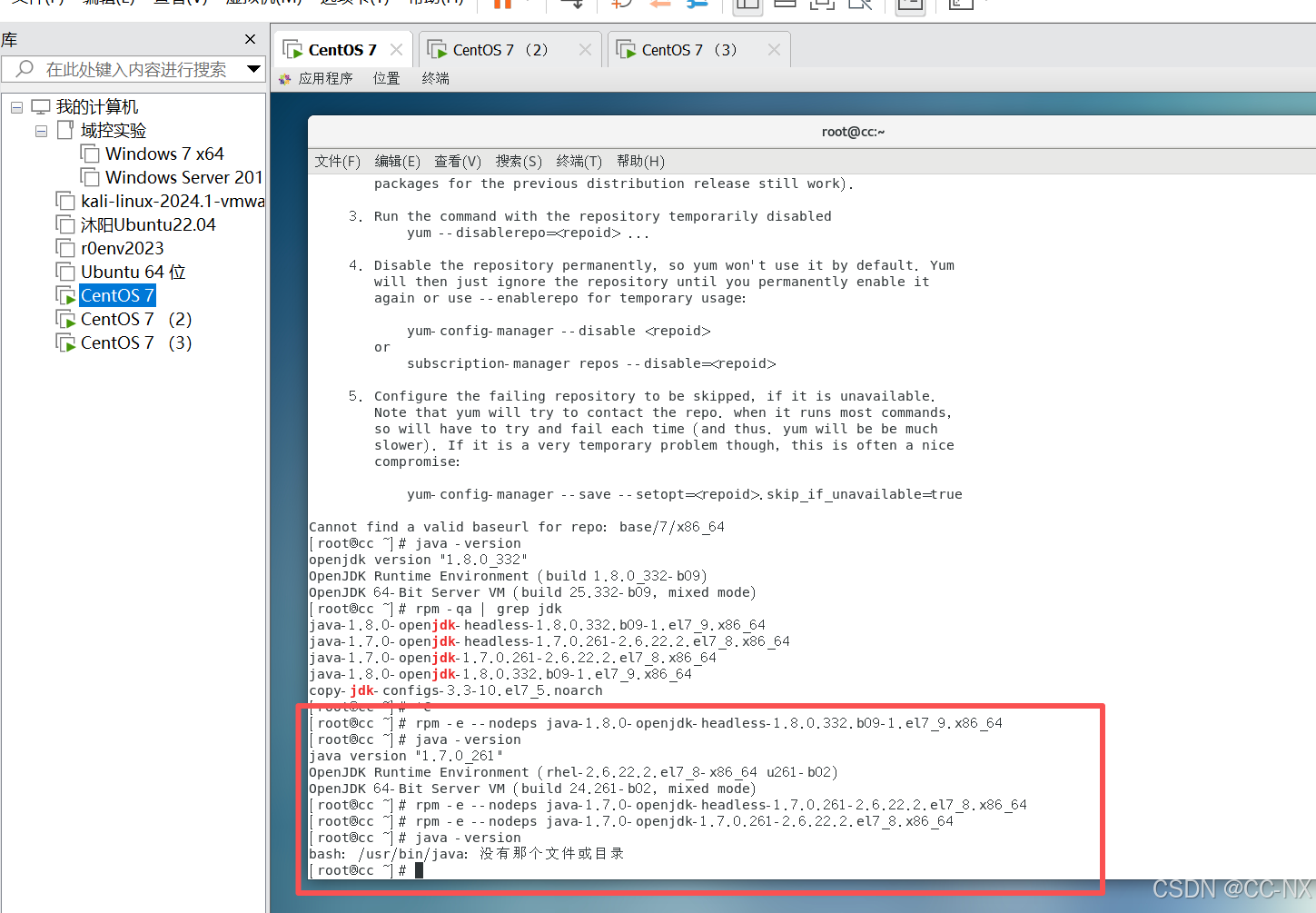
(2)卸载自带的JDK
三台虚拟机都需要删除
命令:rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.332.b09-1.el7_9.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
(3)安装jdk
切换到目录/export/software
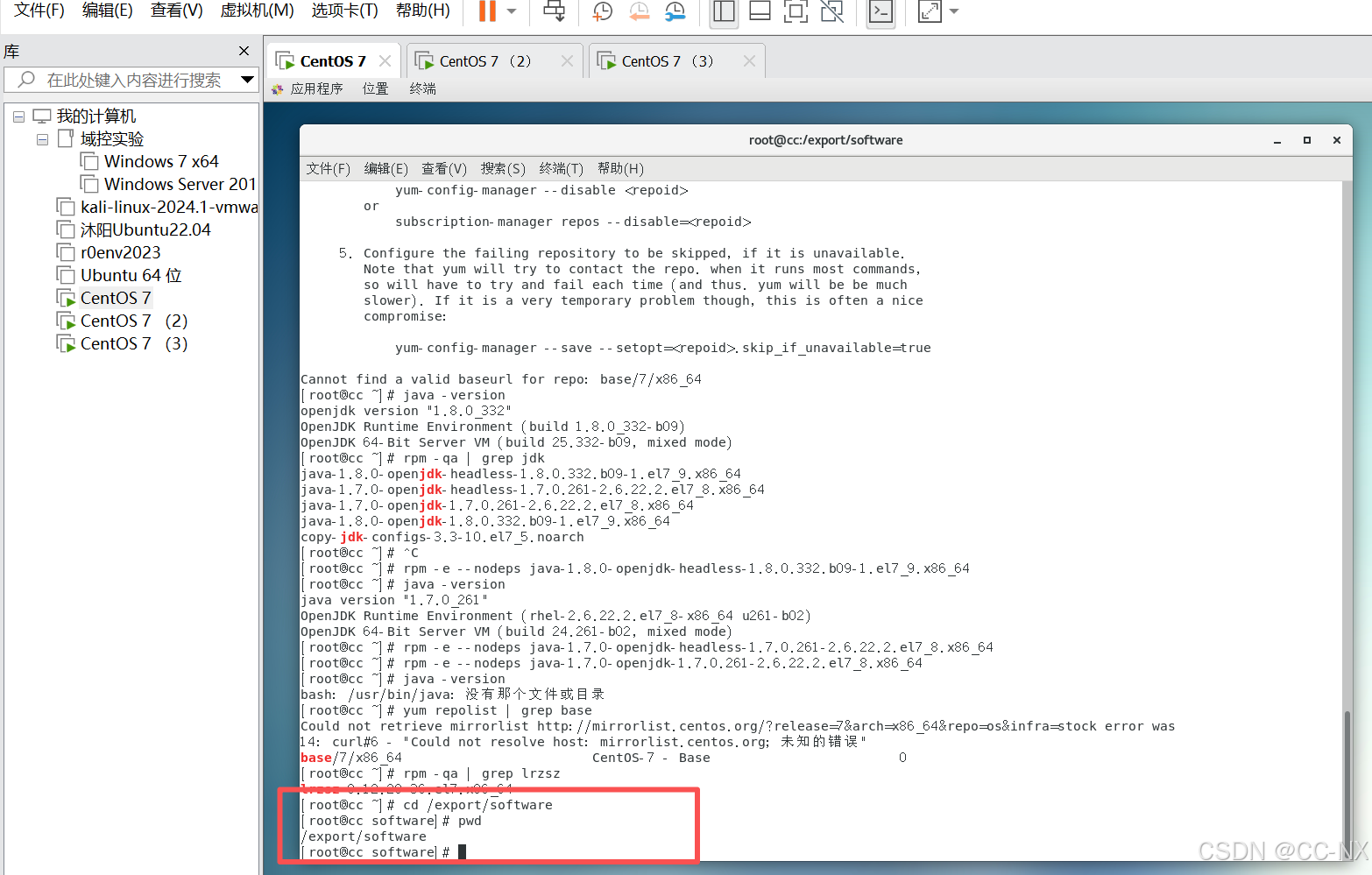
网络问题懒得修了暂时不能直接在虚拟机里下载,手动下载JDK并上传https://repo.huaweicloud.com/java/jdk/8u181-b13/jdk-8u181-linux-x64.tar.gz
我的rz也出现了错误,不修了,我们直接拖拽到桌面再进行文件移动吧
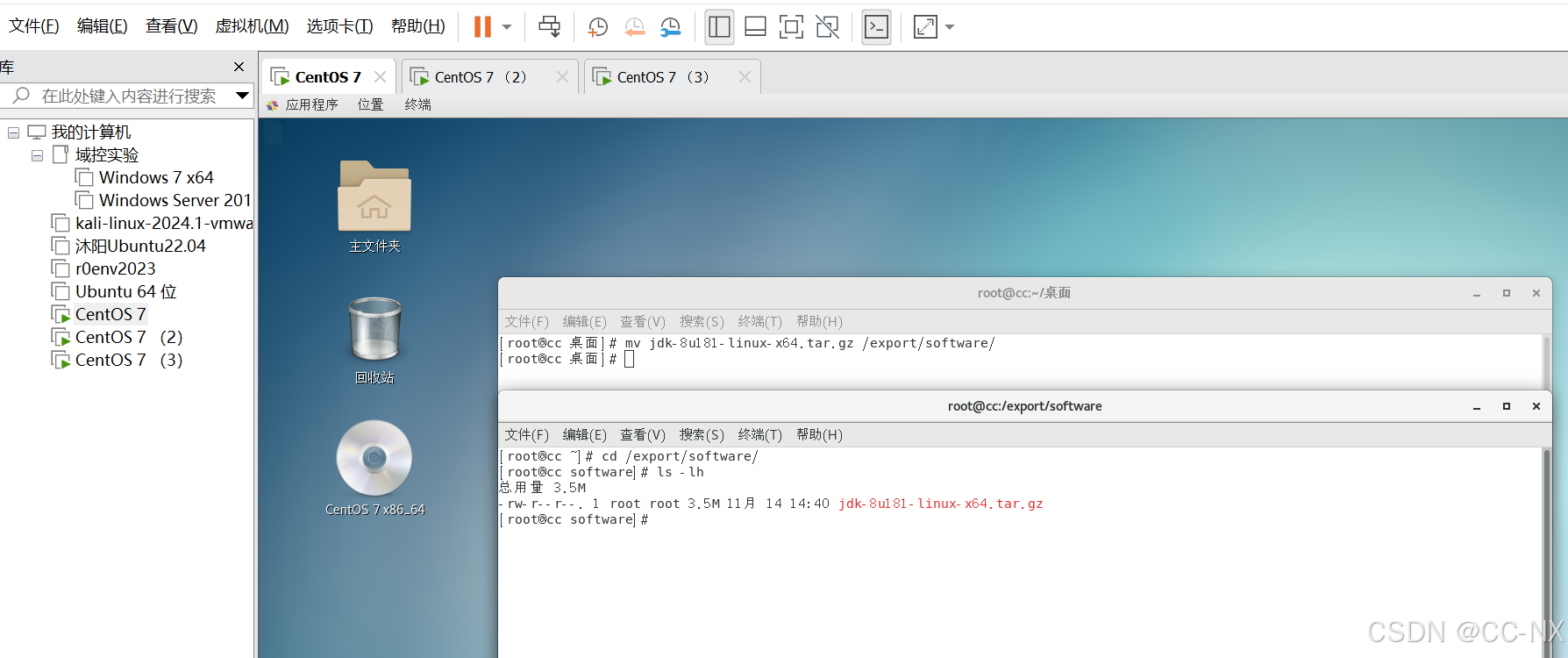
emm......很明显这样的上传会损坏文件,我们老实上传一下
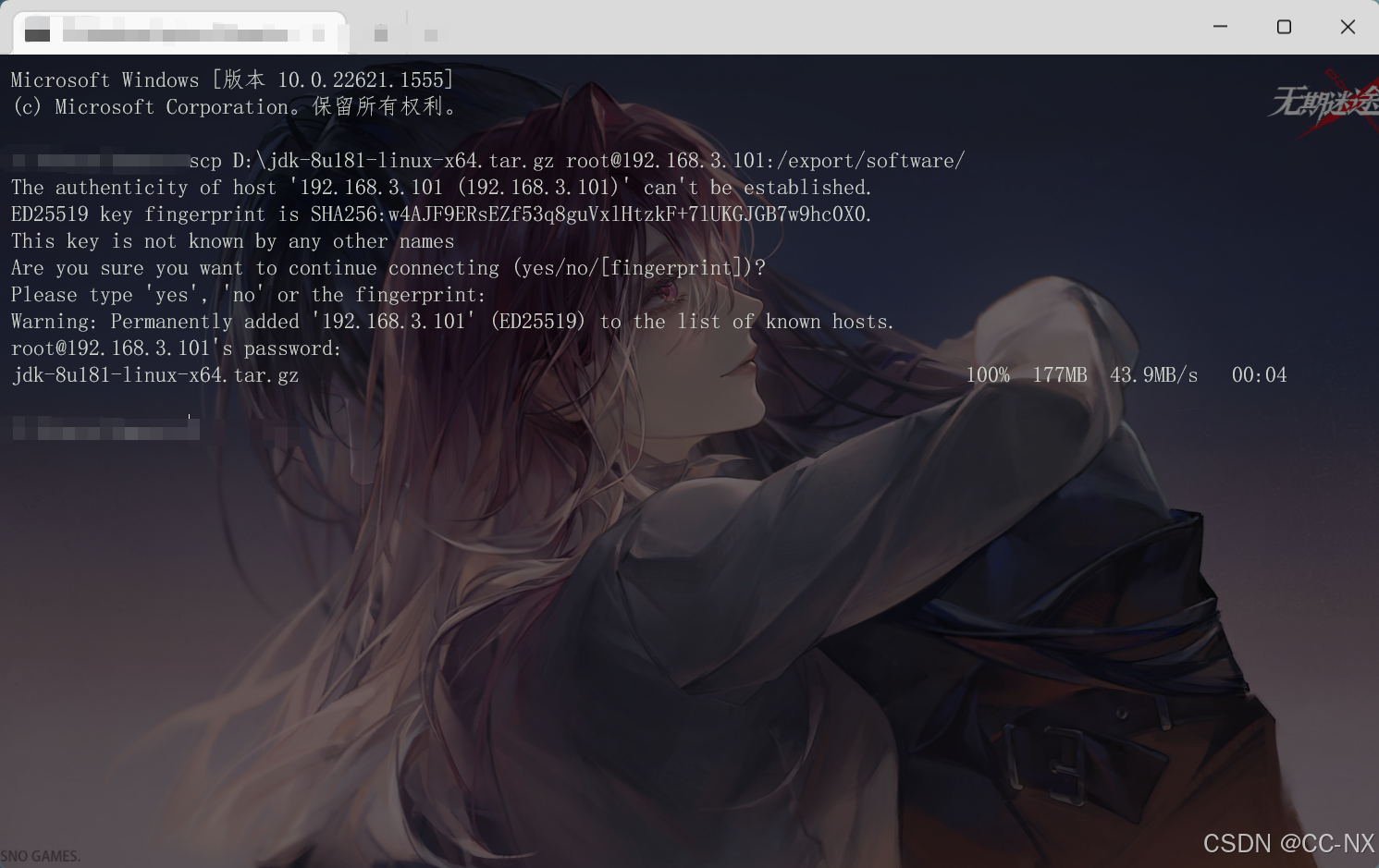
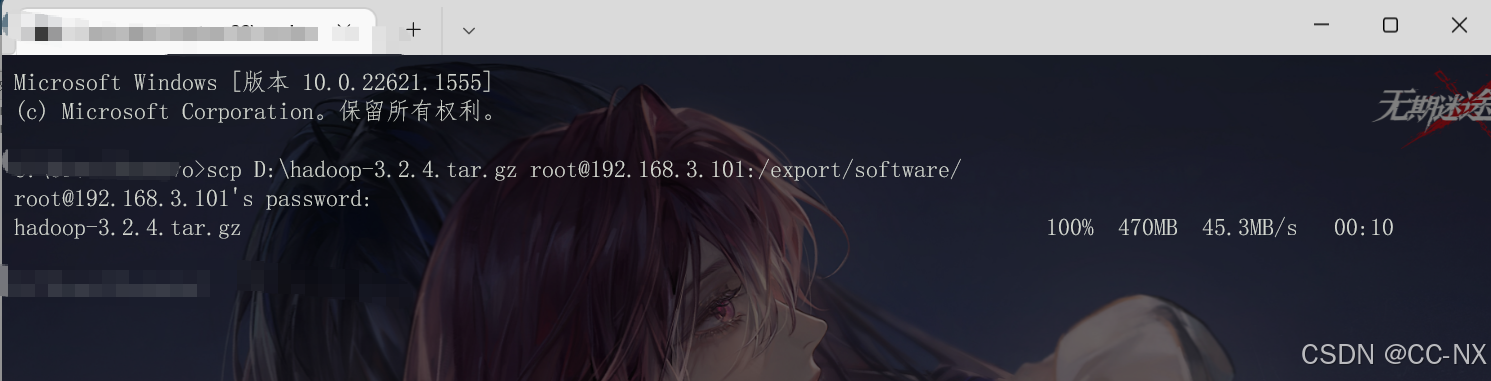
scp D:\jdk-8u181-linux-x64.tar.gz root@192.168.3.101:/export/software/
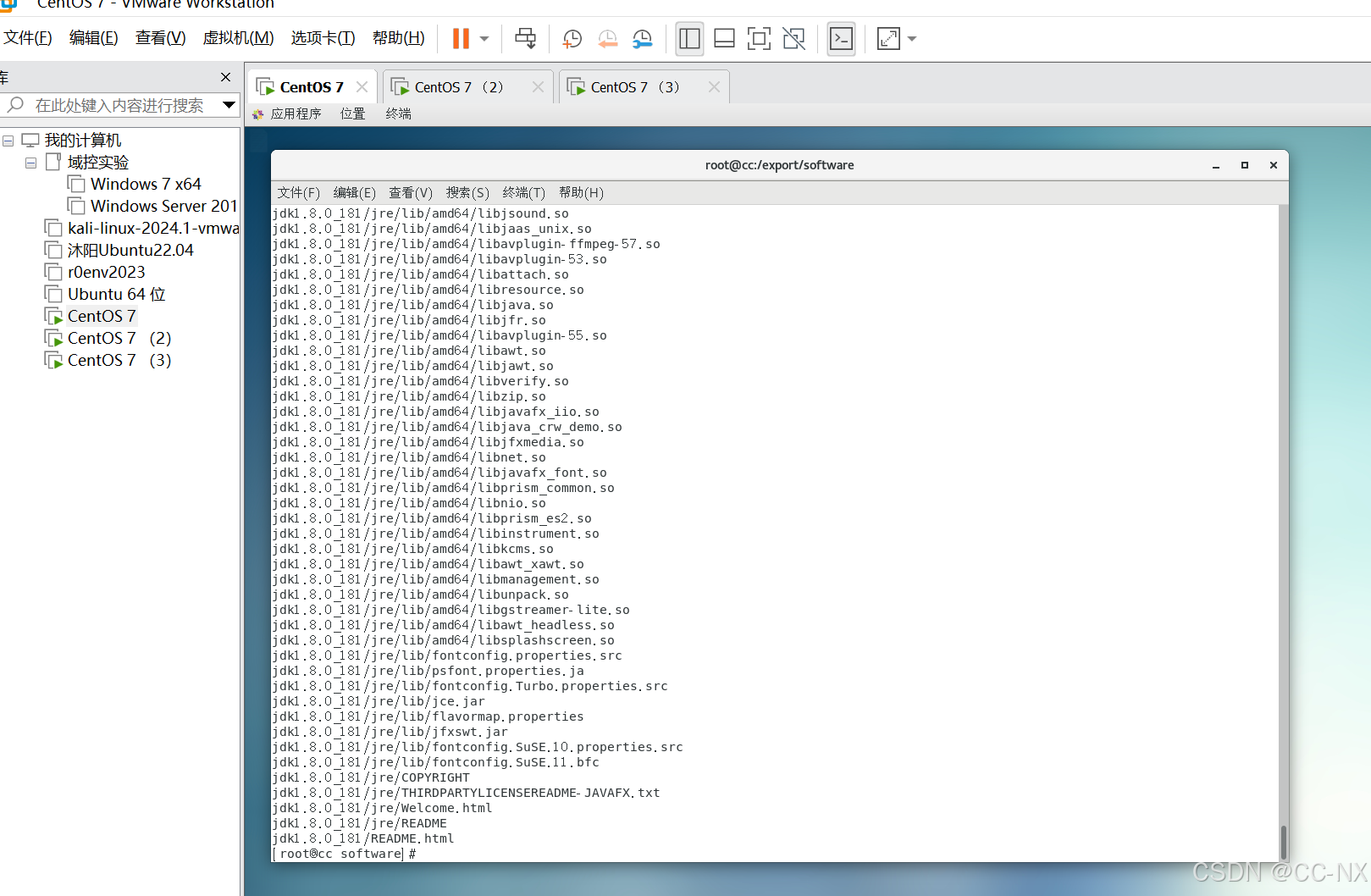
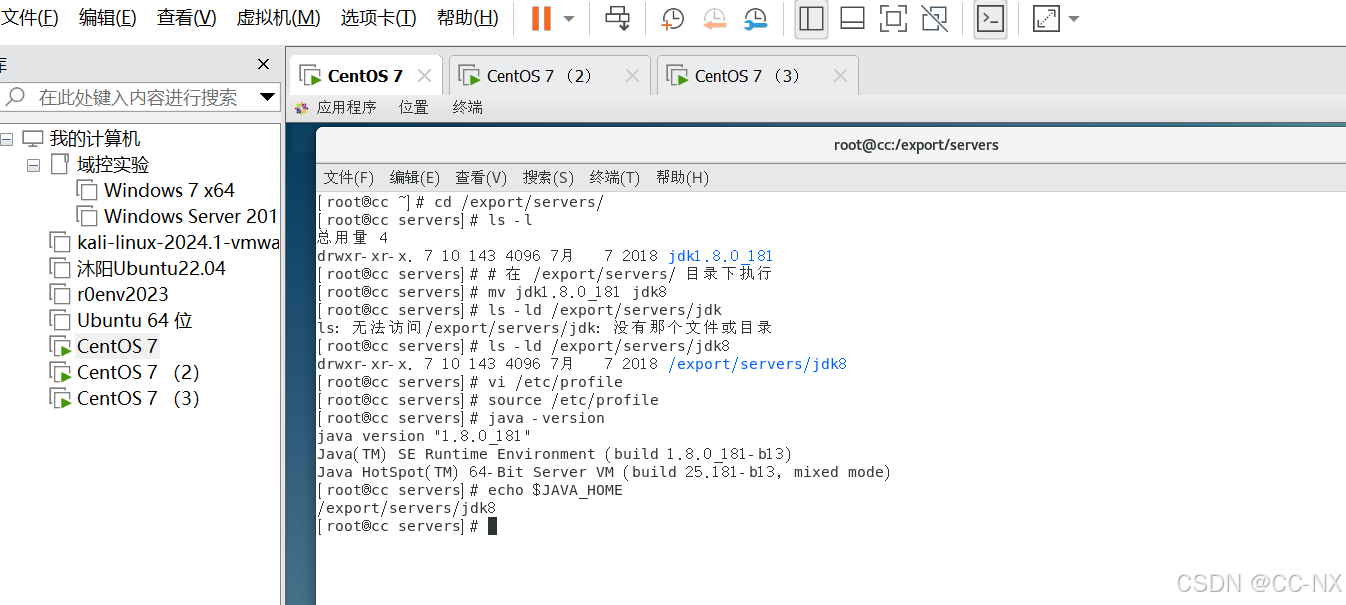
输入命令tar -zxvf jdk-8u181-linux-x64.tar.gz -C /export/servers/进行解压安装jdk
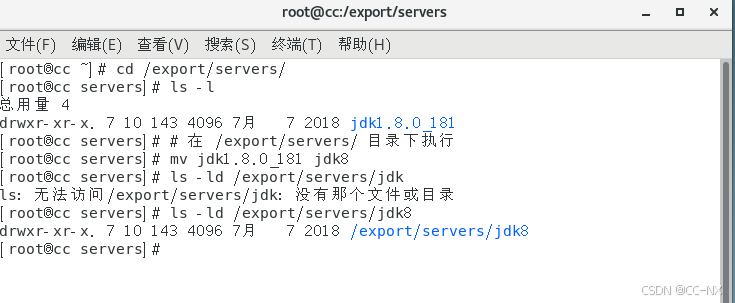
输入命令:mv jdk1.8.0_181 jdk进行重命名为jdk8
配置JDK环境变量
命令:vi /etc/profile
添加如下内容:
export JAVA_HOME=/export/servers/jdk8
export PATH=PATH:JAVA_HOME/bin
export CLASSPATH=.:JAVA_HOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
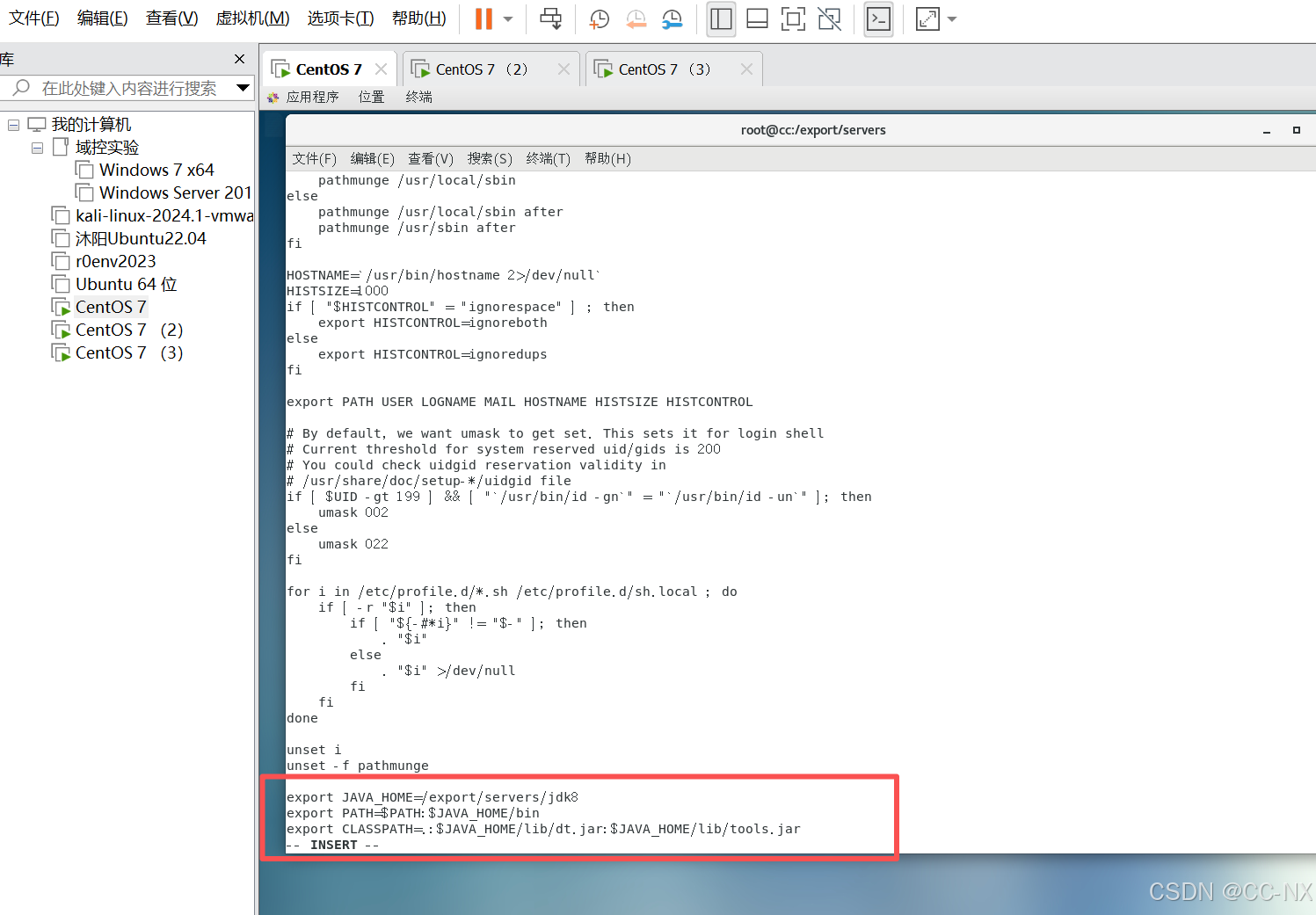
编辑保存好后,输入命令:source /etc/profile
这条命令是重新加载环境变量配置文件使/etc/profile文件生效。
安装完成,检验一下,若提示没有权限,可以用chmod -R +x /export/servers/jdk/bin/java添加权限
分发jdk配置文件给其他两台虚拟机
切换到jdk目录下,分别输入这两条命令: scp -r jdk8 CC2:/export/servers/
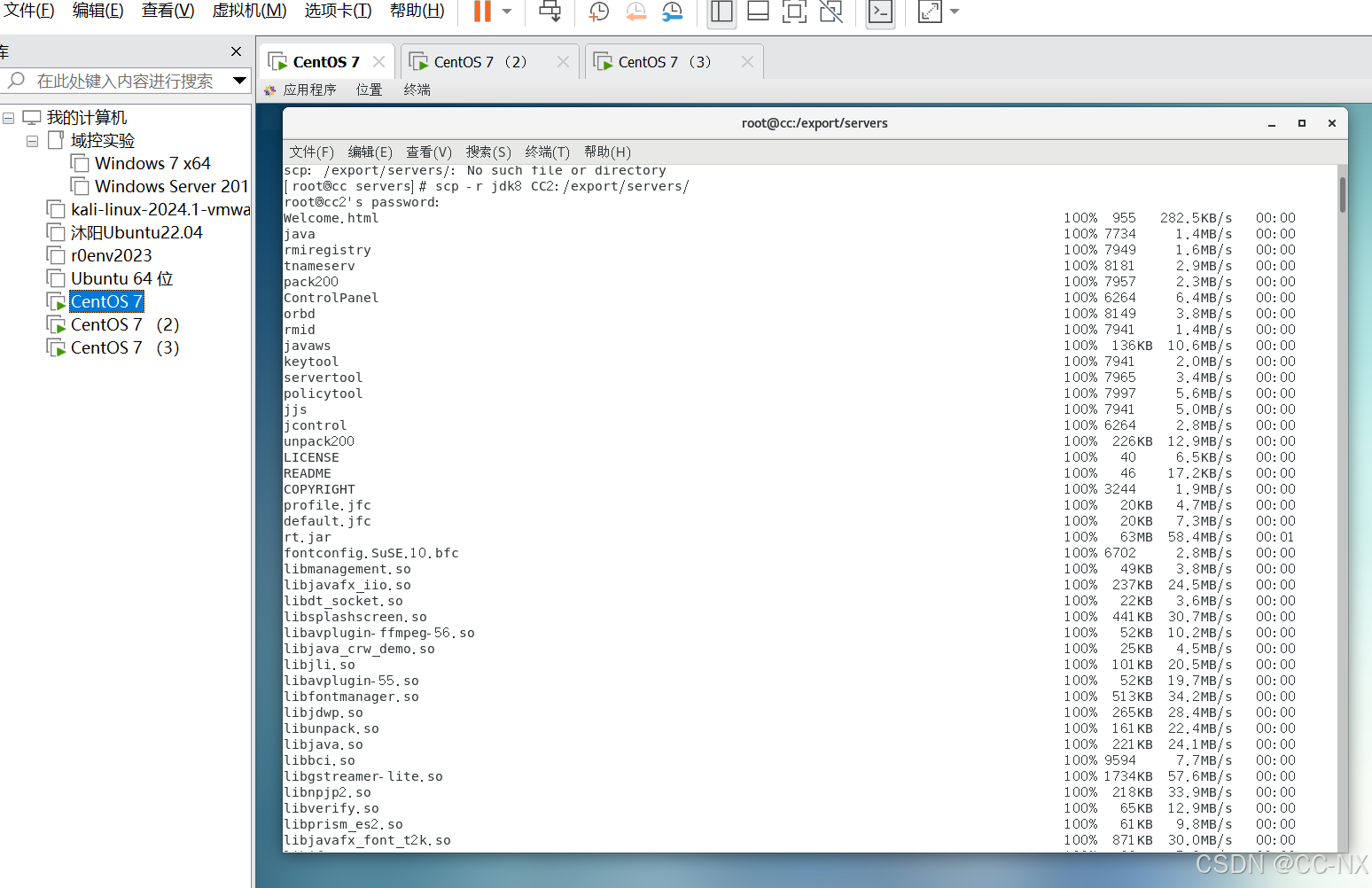
scp -r jdk8 CC3:/export/servers/
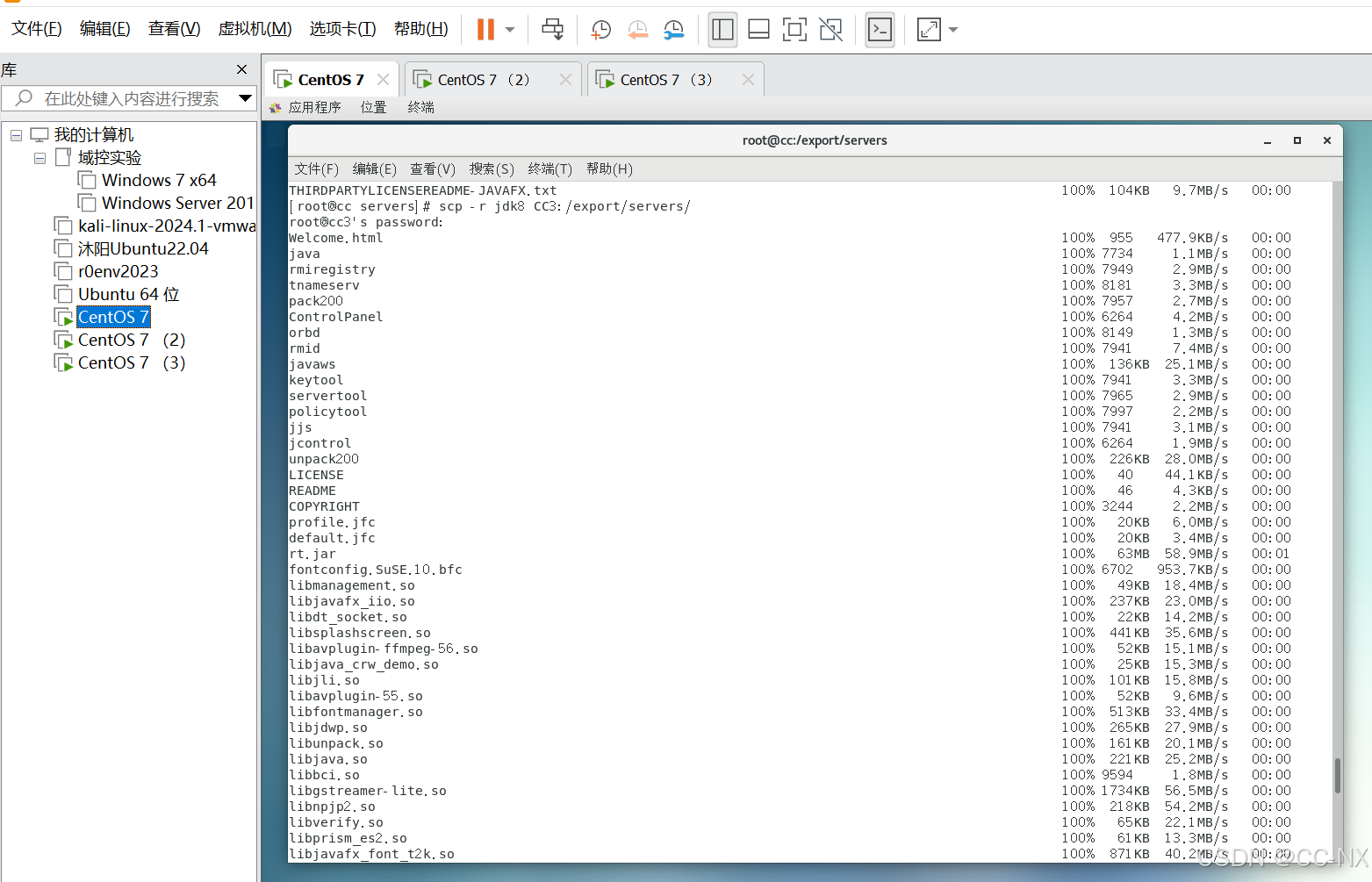
然后分发环境变量配置文件
分别输入命令:
scp /etc/profile CC2:/etc/profile
scp /etc/profile CC3:/etc/profile
分发环境变量配置文件及jdk文件完成后,其余两台虚拟机需要输入命令:source /etc/profile重新加载一下。
步骤5:安装及配置hadoop
(1)配置Hadoop系统环境变量
cd /export/software
老规矩下载上传
Index of /hadoop/common/hadoop-3.2.4
输入命令tar -zxvf hadoop-3.2.4.tar.gz -C /export/servers/解压安装包
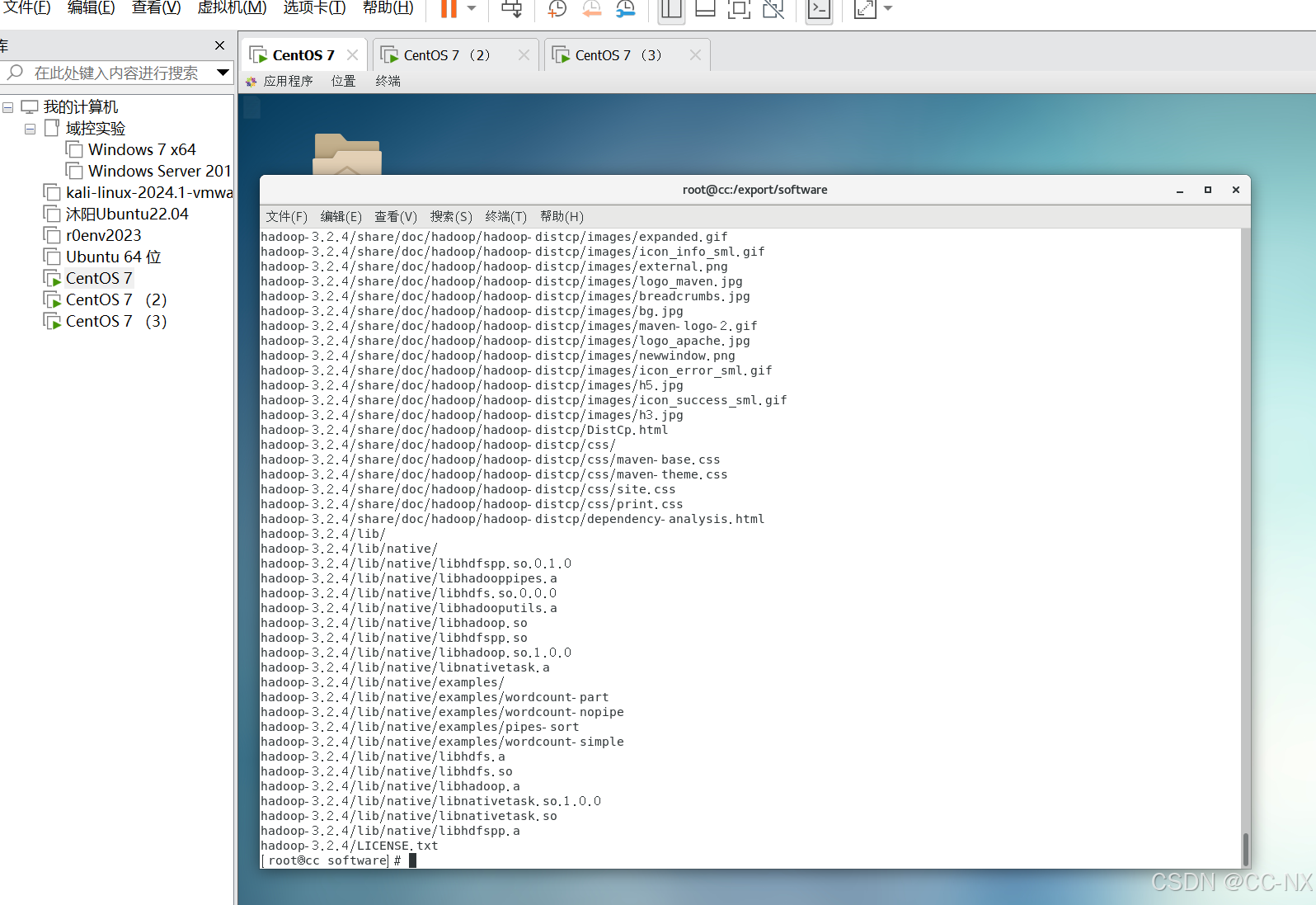
cd /export/servers/
mv hadoop-3.2.4 hadoop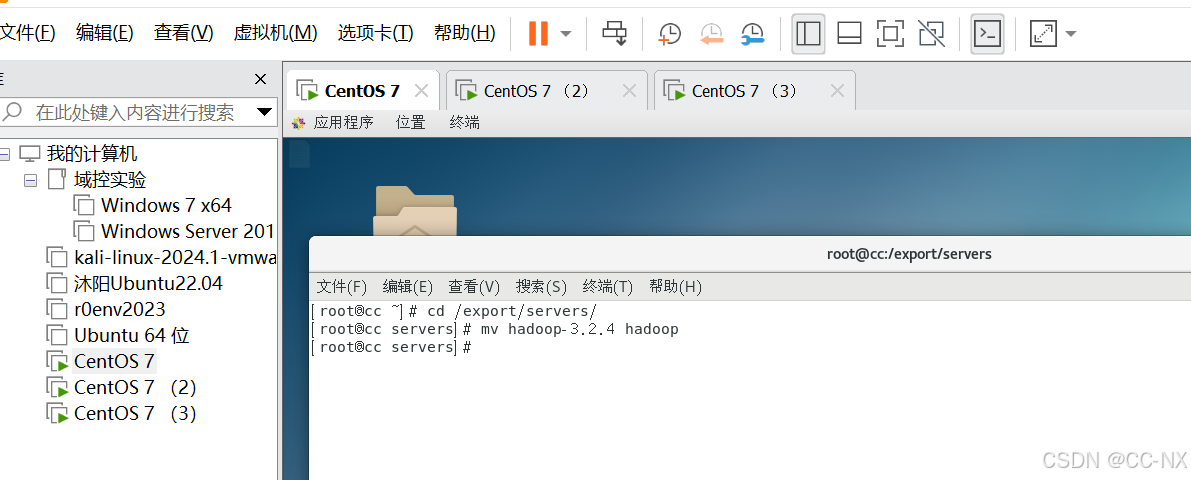
进行重命名方便后续执行代码
输入命令:
vi /etc/profile
添加内容如下:
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin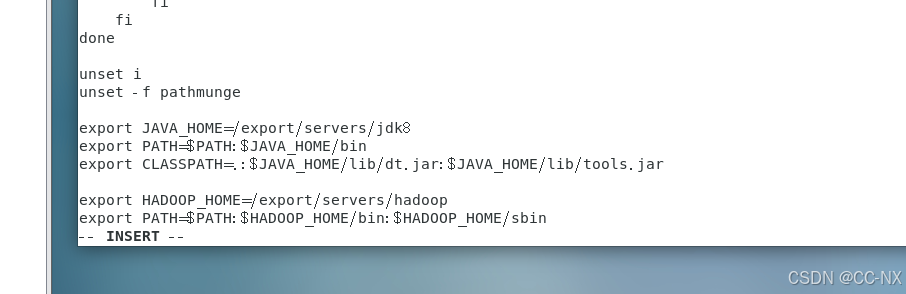
用命令source /etc/profile重新加载一下环境变量配置
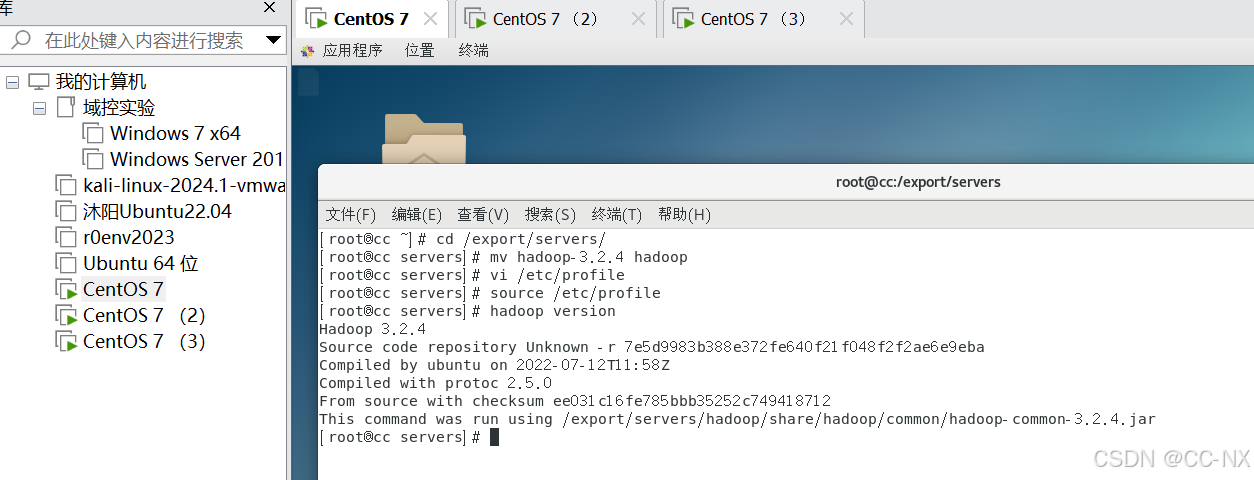
(2)修改hadoop配置文件
修改Hadoop的配置文件必须进入到hadoop安装路径下etc文件夹中的hadoop下进行编写,切换到这个目录下,使用命令:cd /export/servers/hadoop/etc/hadoop/
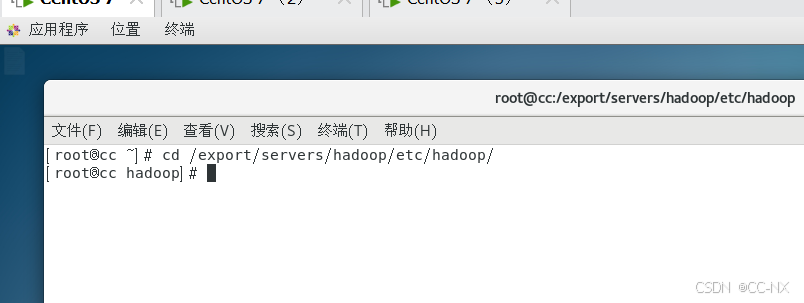
修改hadoop-env.sh文件
输入命令:vi hadoop-env.sh
添加如下内容: export JAVA_HOME=/export/servers/jdk8
不行了,忘用查找了,眼快瞎了。
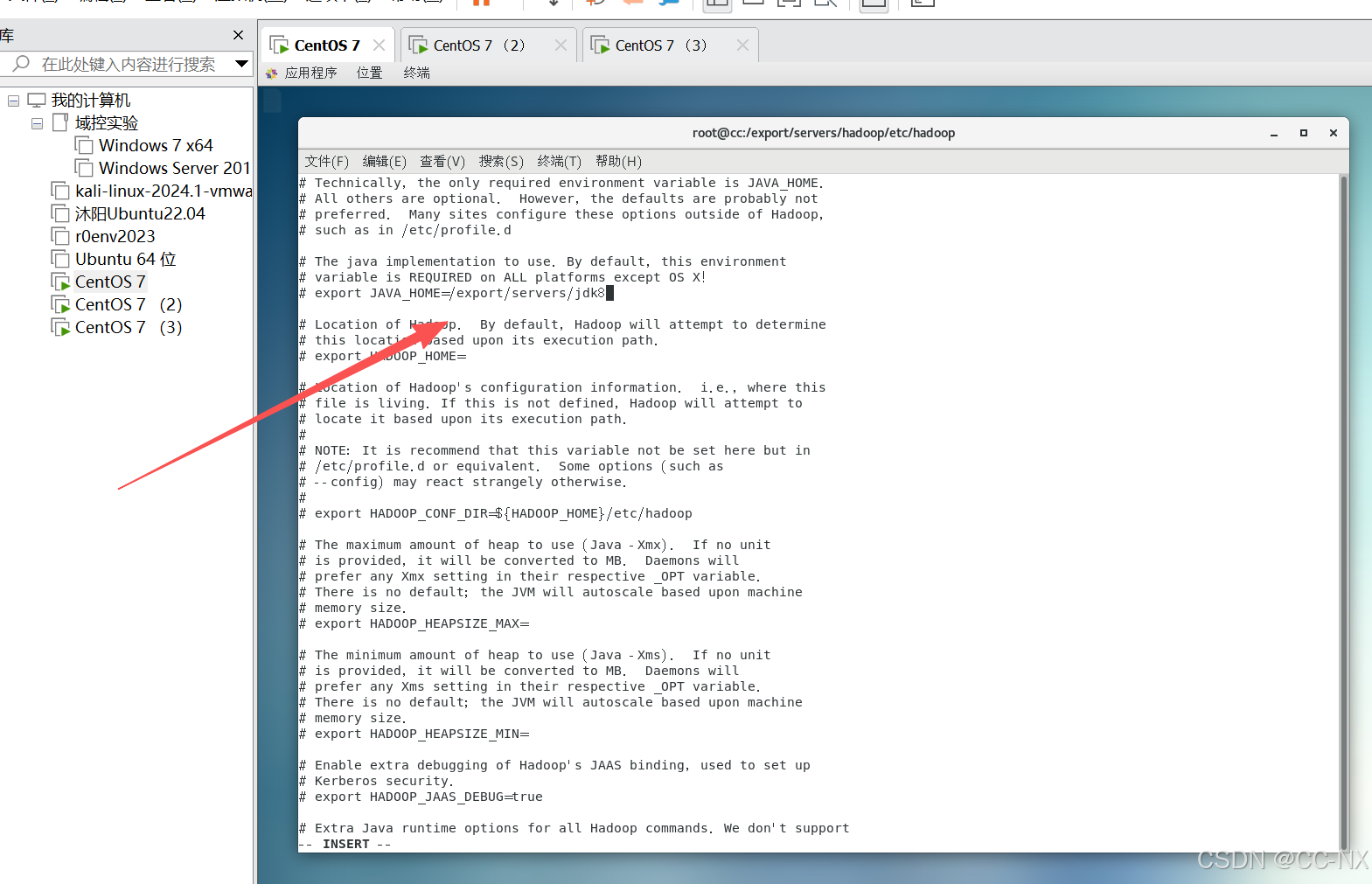
修改core-site.xml文件,输入命令:vi core-site.xml
在 <configuration> 内添加:
<property> <name>fs.defaultFS</name> <value>hdfs://CC:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop/tmp</value> </property>
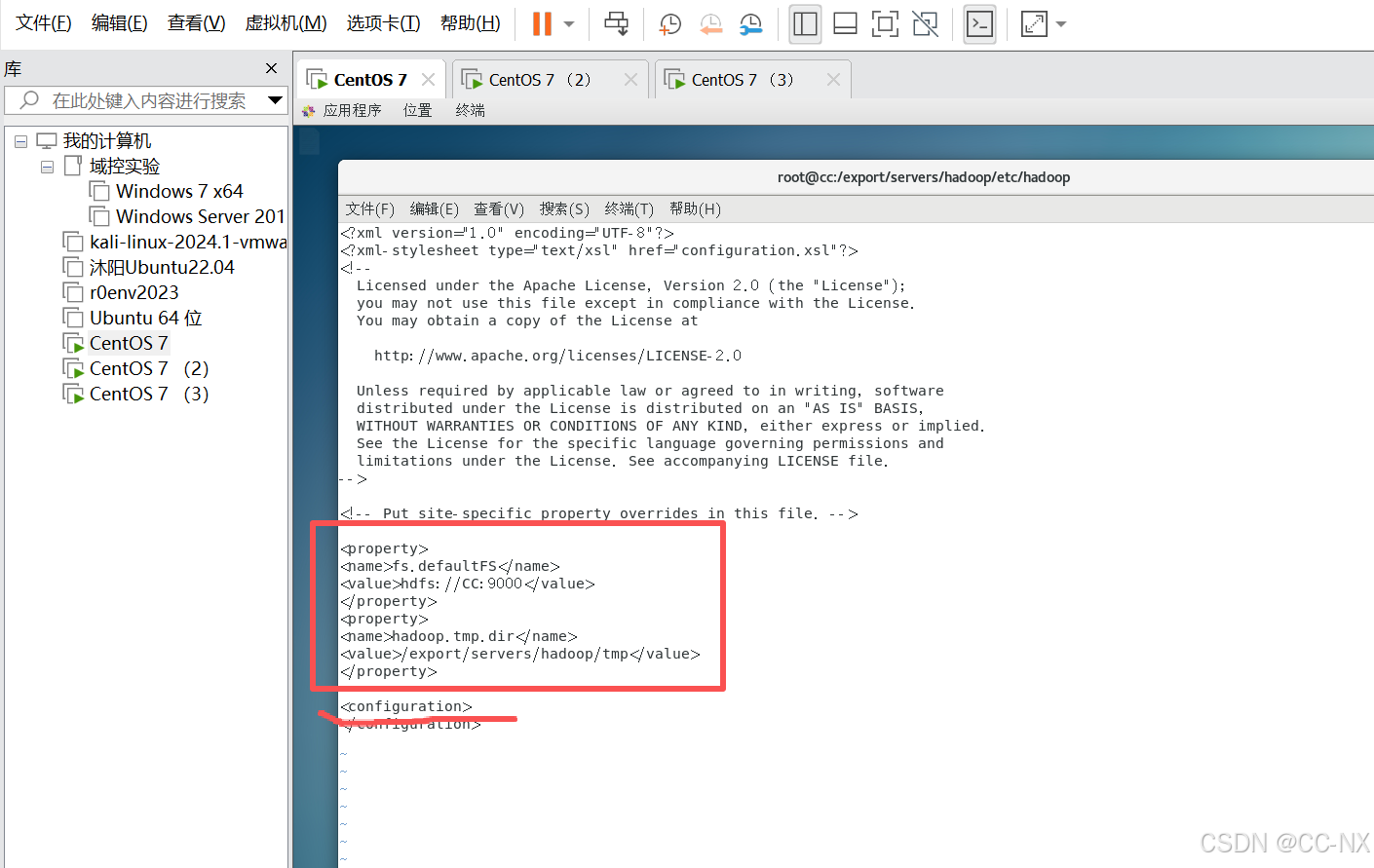
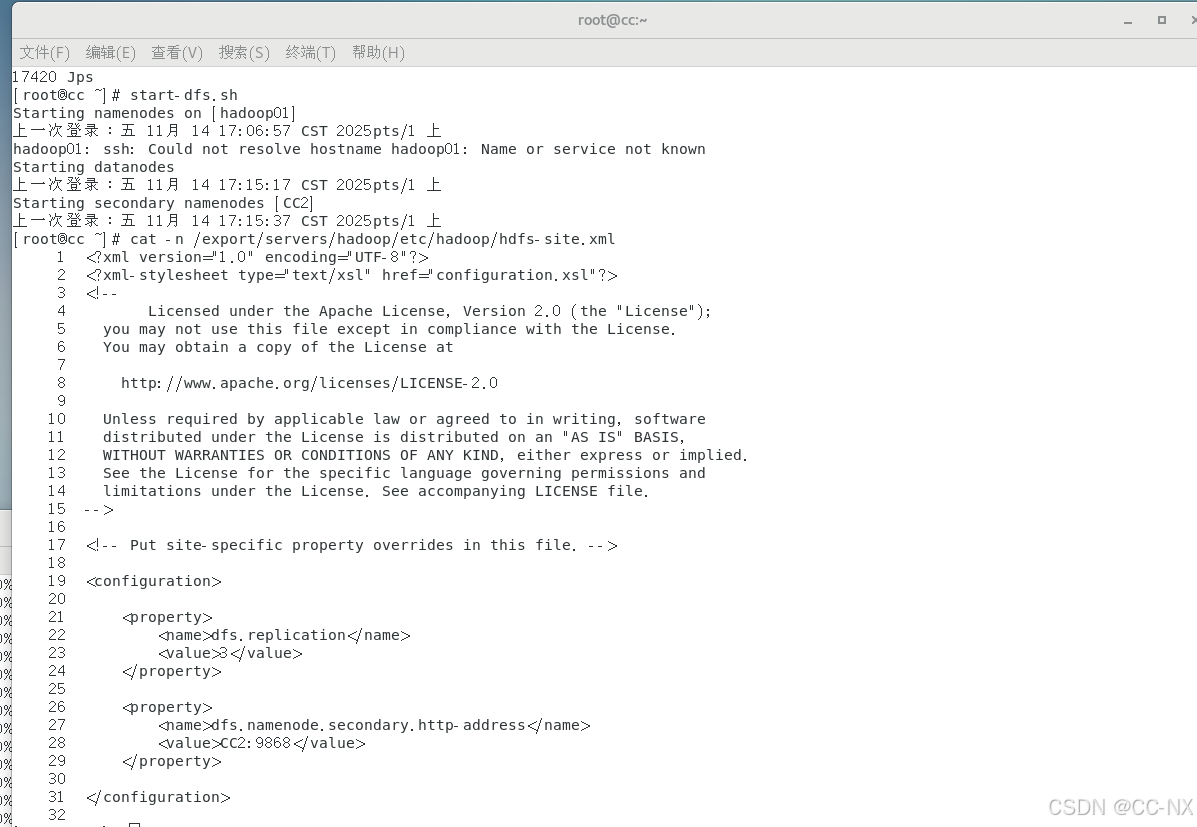
修改hdfs-site.xml文件,
输入命令:vi hdfs-site.xml
添加内容:
<property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>CC2:9868</value> </property>
修改mapred-site.xml文件
首先需要拷贝下mapred-site.xml.template文件,命名为mapred-site.xml
输入命令:cp mapred-site.xml.template mapred-site.xml
然后再对cp的文件进行修改
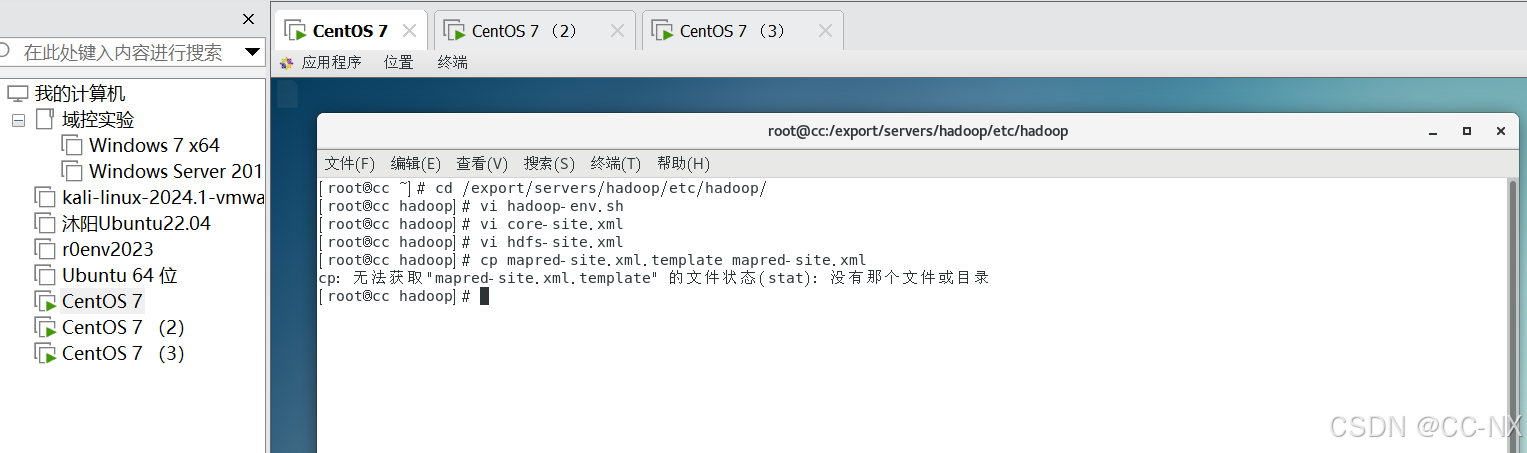
忘了,Hadoop 3.2.4 的配置文件结构与 2.7.3 略有差异,默认不提供 mapred-site.xml.template。需要直接创建 mapred-site.xml 文件。
使用命令:vi mapred-site.xml进入文件进行添加内容:
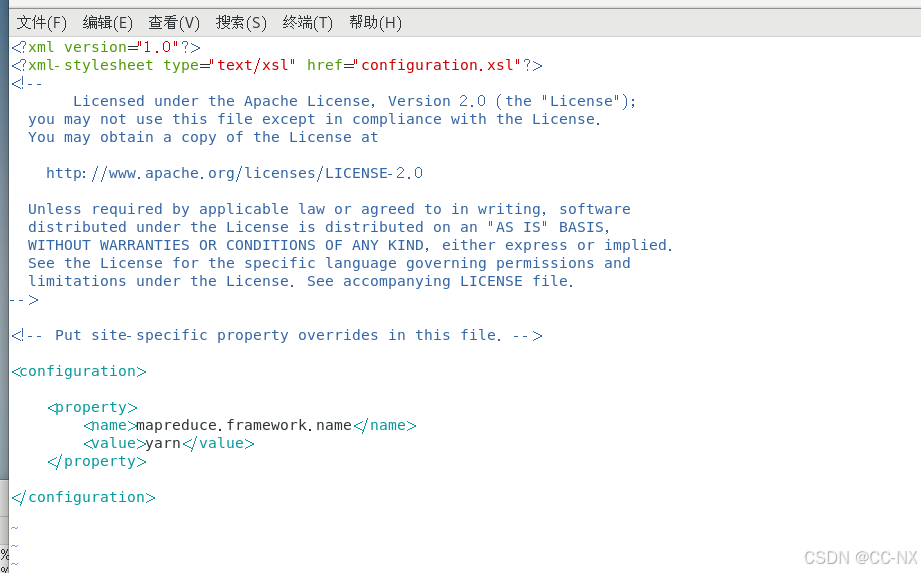
修改yarn-site.xml文件
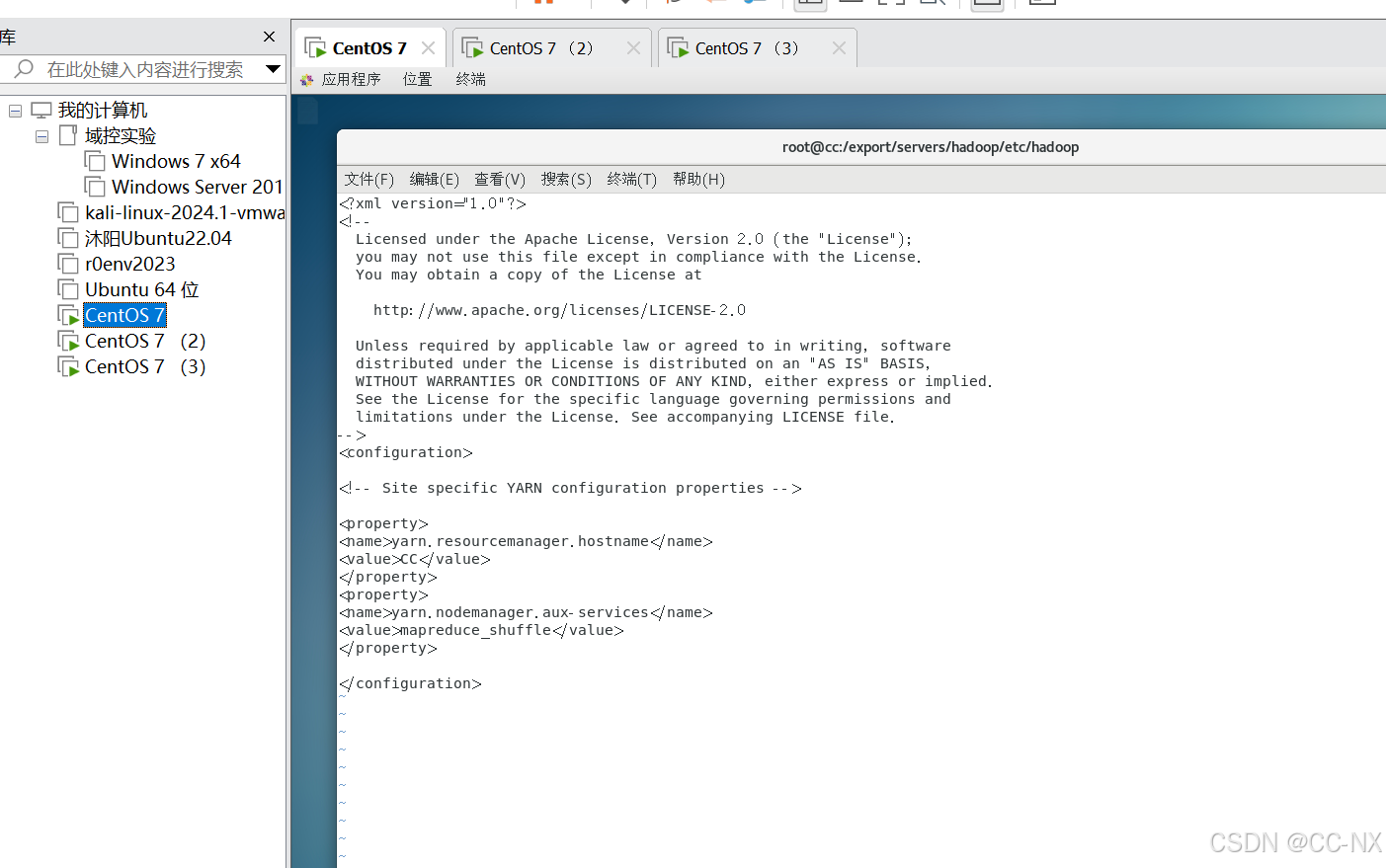
命令:vi yarn-site.xml
添加内容如下:
<property> <name>yarn.resourcemanager.hostname</name> <value>CC</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
****修改 workers 文件(Hadoop 3.x变更)
vi workers
接下来将集群主节点的配置文件分发到其他子节点
分别使用以下命令:
scp
scp /etc/profile CC2:/etc/profile
scp /etc/profile CC3:/etc/profile
scp -r /export/ CC2:/
scp -r /export/ CC3:/
在hadoop02虚拟机和hadoop03虚拟机上分别执行
使用命令:source /etc/profile重新加载环境配置变量
(3)格式化文件系统(在主节点上执行)
使用命令:hdfs namenode -format
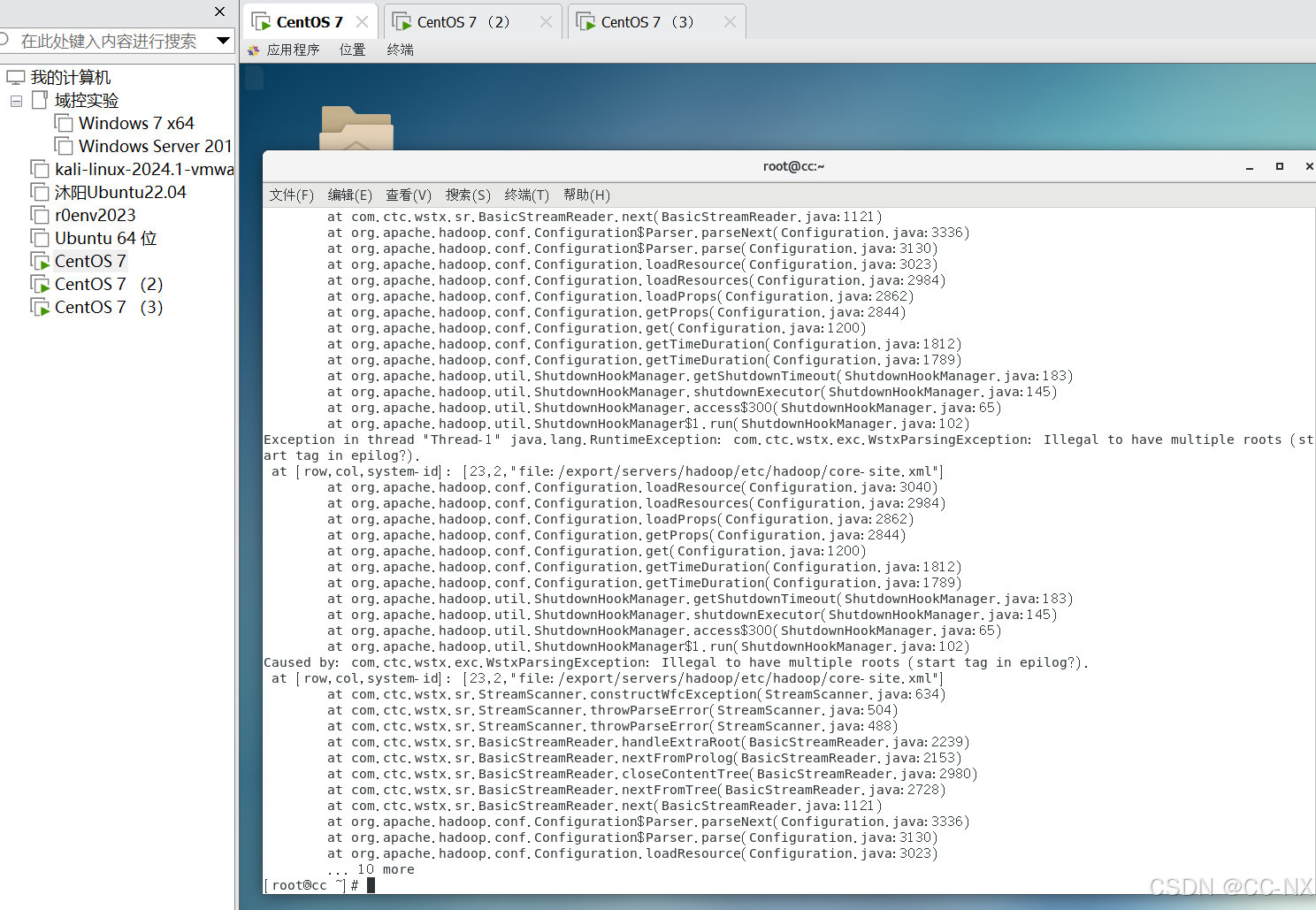
(4)测试启动
首先关闭防火墙,三台虚拟机防火墙都要关闭。
操作命令:
systemctl stop firewalld
关闭防火墙之后,还要关闭防火墙自动启动,用到的命令:
systemctl disable firewalld

此后就可以用以下命令进行一键脚本启动
start-dfs.sh或stop-dfs.sh #启动或关闭所有HDFS服务进程
start-yarn.sh或stop-yarn.sh #启动或关闭所有YARN服务进程
start-all.sh或stop-all.sh #指令直接启动或关闭整个Hadoop集群服务
- *报错处理

用jps在第一台CC查看,有五个进程.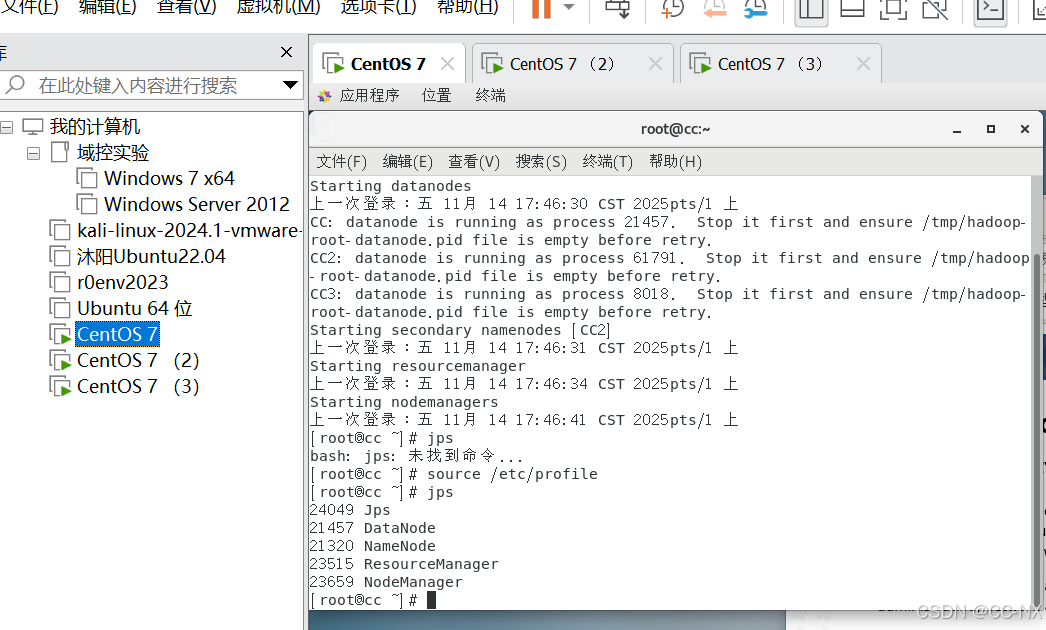
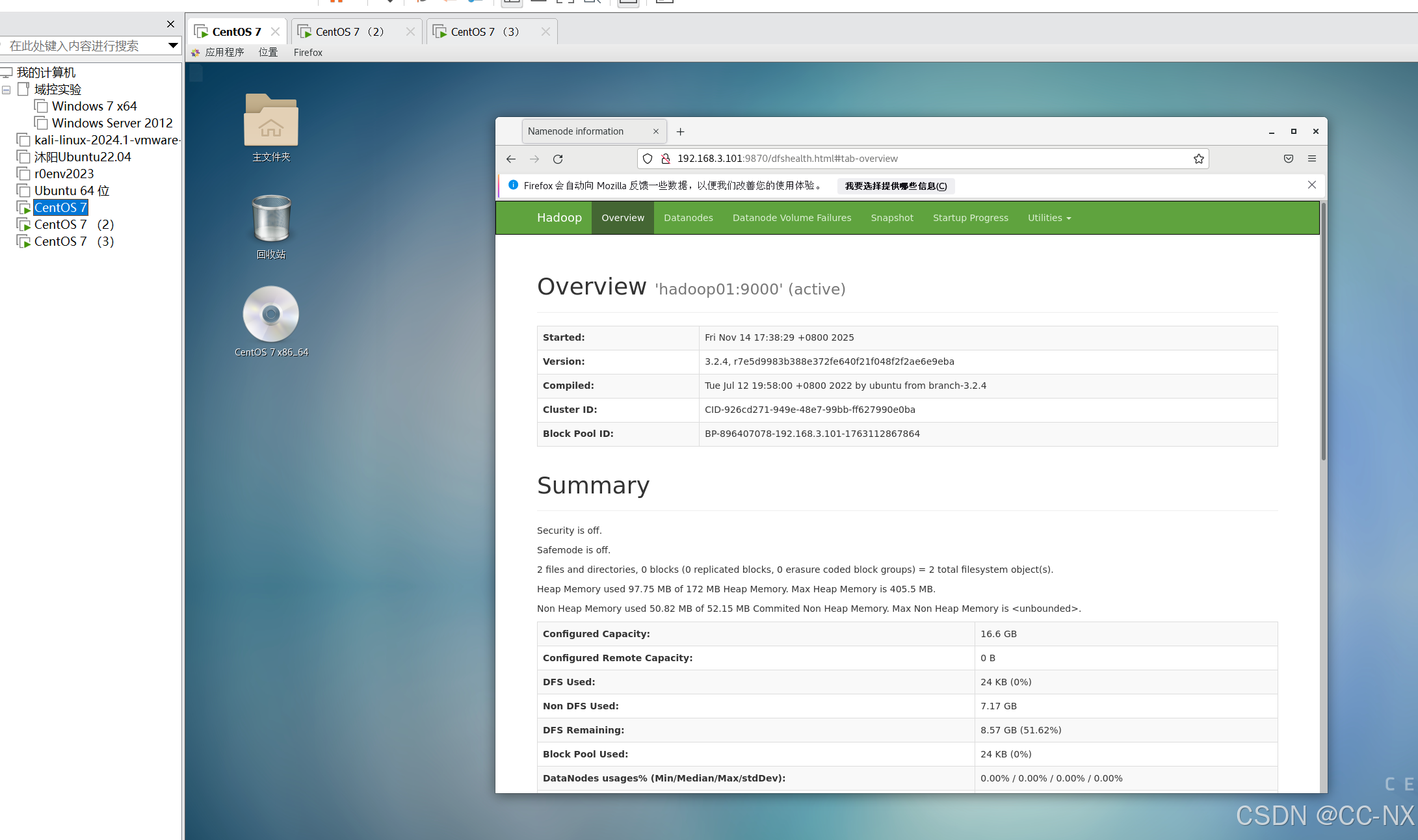
步骤6:测试集群
浏览器在地址栏输入(格式为:主机名或IP地址+端口号)查看HDFS集群状态
浏览器地址栏处输入(格式为:主机名或IP地址+端口号)可查看YARN集群管理页面
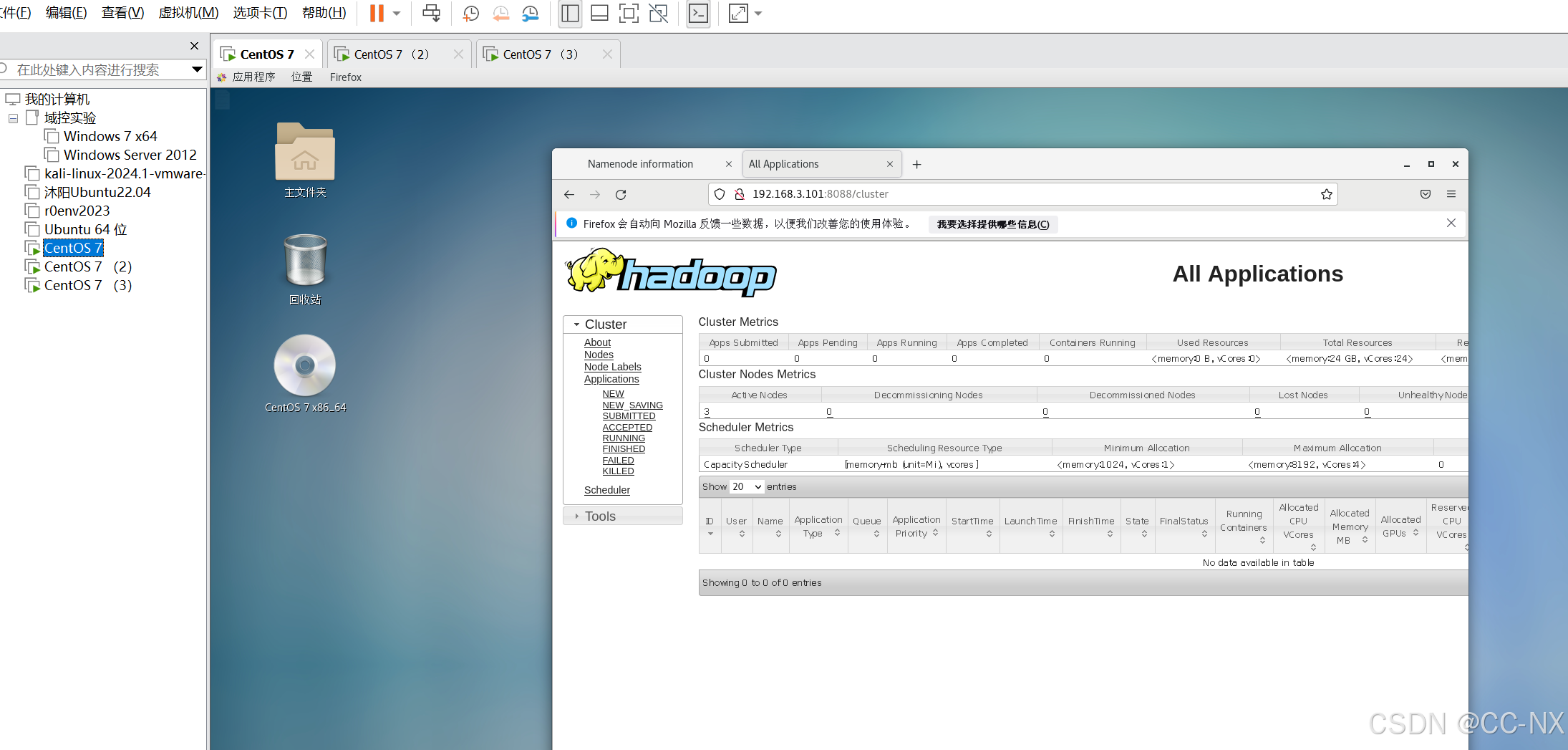
至此hadoop配置完毕