教程总体简介:2. 目标 1.1产品与开发 1.2环境配置 1.3 运行方式 1.4目录说明 1.5数据库设计 2.用户认证 Json Web Token(JWT) 3.书架 4.1分类列表 5.搜索 5.3搜索-精准&高匹配&推荐 6.小说 6.4推荐-同类热门推荐 7.浏览记录 8.1配置-阅读偏好 8.配置 9.1项目部署uWSGI 配置 启动 9.部署 10.1异常和日志 10.补充 10.2 flask-restful 1.项目目录实现 3.数据库迁移: 1.JWT:json web token 2.jwt工具的封装 4.用户权限校验 5.登录验证装饰器 1.书架列表 2.书架管理 3.最后阅读 2.分类书籍列表 3.热门搜索 7.3小说-详情 2.小说目录 2.阅读偏好 3.阅读设置
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/Flask/嘿马文学web完整flask项目/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:

部分文件图片:
简介
1. 内容
- 项目介绍
- 用户登录--授权
- 用户认证
- 书架管理
- 分类管理
- 搜索管理
- 热门推荐
- 小说目录
- 阅读记录
- 阅读配置
- 项目部署
- 补充
2. 目标
- 以黑马文学产品为案例,以具体业务实现为主
- 深入理解并巩固前面所学的知识
1.1产品与开发
1-1 产品介绍
-
黑马文学是传智播客开发的专注于电子书阅读的客户端。本着帮助用户"多看书、多交朋友"的宗旨,以不断满足用户需求、为不同用户提供更好的中文阅读产品,给广大消费者提供更好的阅读体验。
-
移动web端 ,项目主要模块有用户模块、书籍模块、后台管理模块,具体有用户管理、书籍管理、系统管理等。参照了目前最流行的jwt认证 方式,并结合试下热门的小程序开发,实现了所有接口获取用户信息,部分接口强制登录这样的整套的认证方案。
-
借鉴了qq阅读的书库分类,只留下了核心的男女频道。同时,在分类的页面中加入了我们自己特色的分类书籍推荐。
-
参考了阅读软件中书架中的那种简洁,增加了一个随机推荐书籍。每次搜索的数据,都跟普通的搜索不同。除了返回精准的数据之外,还加入了高匹配和推荐的内容。相当于给智能推荐提前留了一个坑,以便后续增加AI推荐。
-
功能方面,除了提供字体设置、亮度设置。我们另加了一个夜间设置,这样非常方面用户晚上看书的场景。
1-2 原型图
- 产品原型图
产品经理制作,是产品的原型设计,表达产品的功能组成
产品原型图的查看,需要安装Axure RP的Chrome浏览器扩展,方式如下:
1、使用Chrome浏览器「扩展程序」页面,打开「开发者模式」

2、点击「加载已解压的扩展程序」,并选择「Axure_RP_Extension_for_Chrome_0.6.3」目录
3、选择已安装扩展的「详细信息」
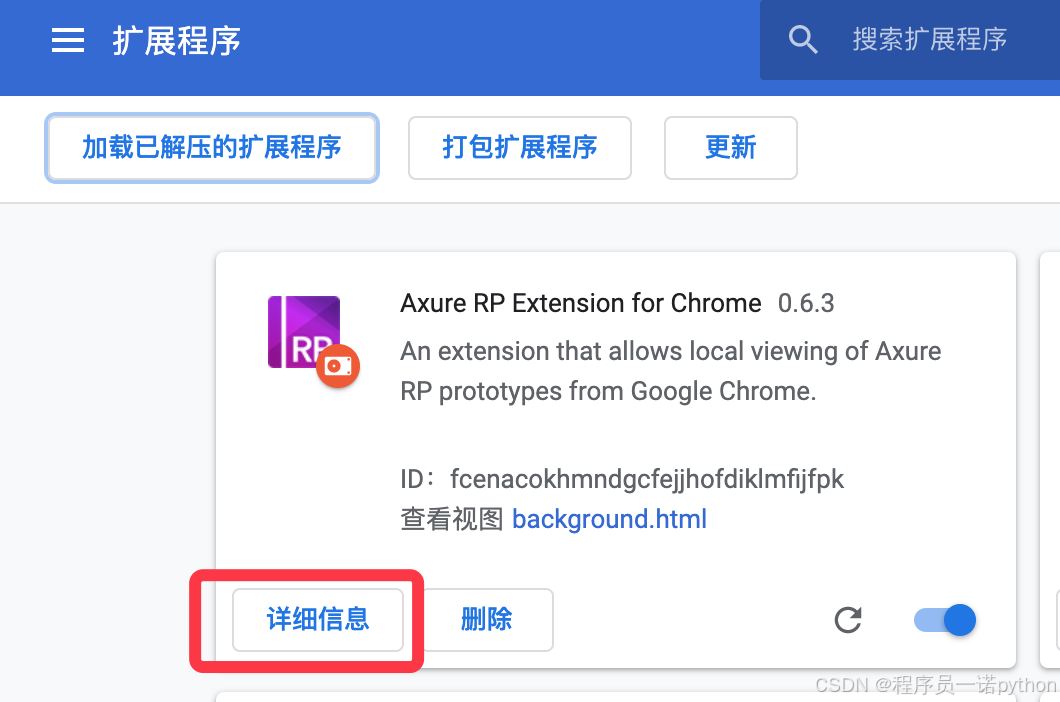
4、打开「允许访问文件网址」
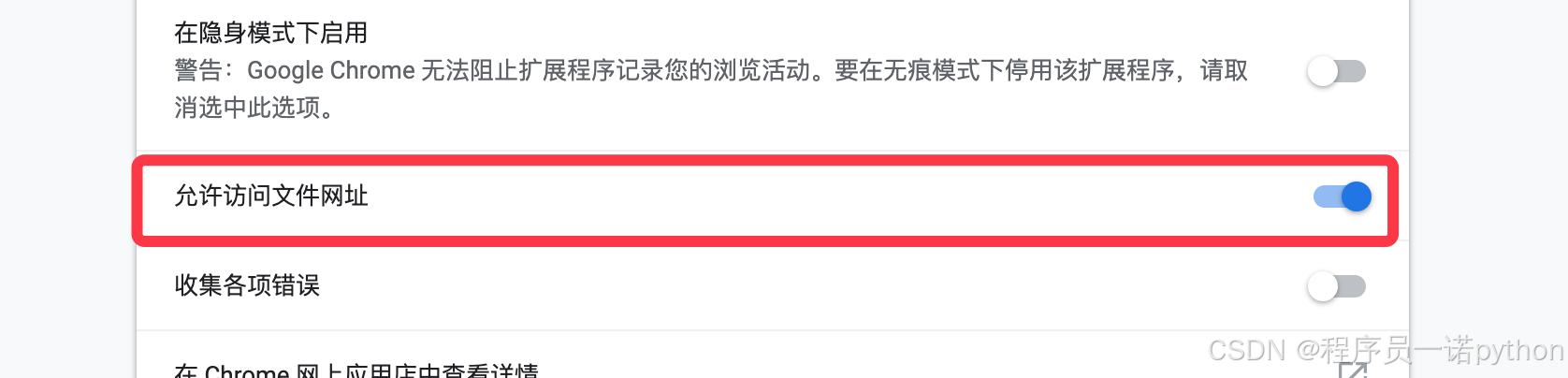
安装后,打开原型图目录中的index.html文件即可。
原型图包含:
-
产品原型图
-
书架
-
分类
-
搜索
-
我的
-
通用
1-3 技术架构
项目采用前后端分离模式。

1.2环境配置
1-1 系统环境
-
使用Linux(ubuntu16)或Mac系统
-
Python3 + Flask0.11
-
MySQL (5.7.20)
-
Redis(3.2.1)
1-2 虚拟环境和依赖文件
1、新建虚拟环境
python
# 创建虚拟环境名称为wenxue_py3
mkvirtualenv -p python3 wenxue_py32、进入虚拟环境
python
workon wenxue_py33、安装依赖文件
python
# 项目代码目录下的requirements.txt
pip install -r requirements.txt1-3 项目启动运行需要用到的扩展包
python
# 数据库迁移扩展,配合Flask-Script实现数据库迁移
Flask-Migrate==1.4.0
# 脚本命令扩展,用来启动项目
Flask-Script==2.0.5
# 数据库ORM扩展,用来创建数据库表,增删改查数据
Flask-SQLAlchemy==2.3.2Flask-SQLAlchemy连接数据库配置:
python
# 配置数据库的连接信息,主机、端口、数据库名称
SQLALCHEMY_DATABASE_URI = 'mysql://root:mysql@localhost/hmwx'
# 动态追踪修改信息,不设置会提示警告信息,设置True或False都可以关闭警告信息。
SQLALCHEMY_TRACK_MODIFICATIONS = False连接Redis数据库配置:
python
REDIS_SETTINGS = {
'HOST': '127.0.0.1',
'PORT': 6379,
'DB':0,
}1.3 运行方式
- 项目启动文件manage.py,如果直接运行,会有如下提示信息。
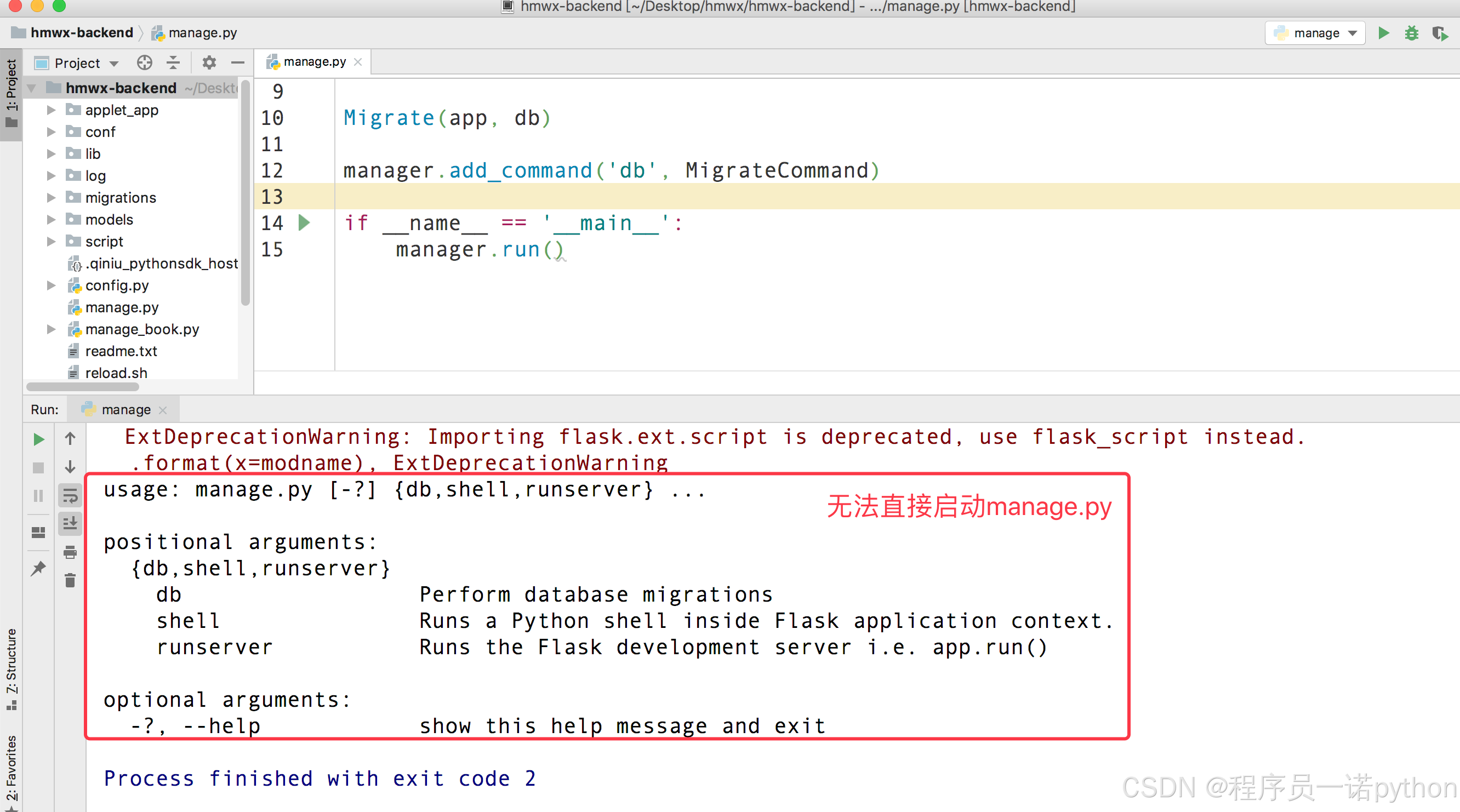
-
可以有两种方式解决:
-
第一种:直接在终端启动时加入参数runserver,即python manage.py runserver。
-
第二种:编辑Pycharm的manage.py文件的配置信息,具体见如下4步。
1、编辑manage.py文件的配置信息

2、添加参数runserver 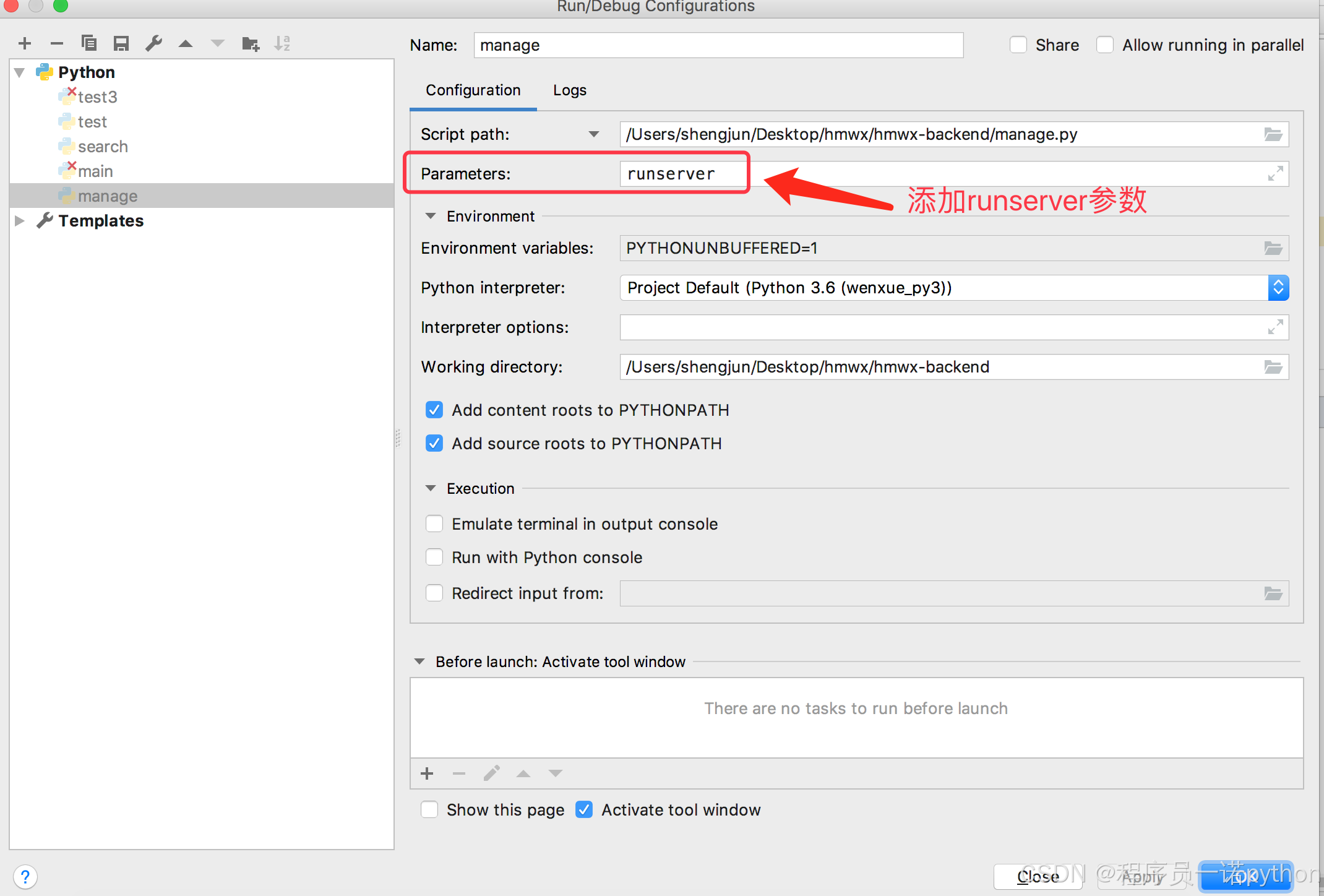
3、运行项目

4、访问测试,成功。
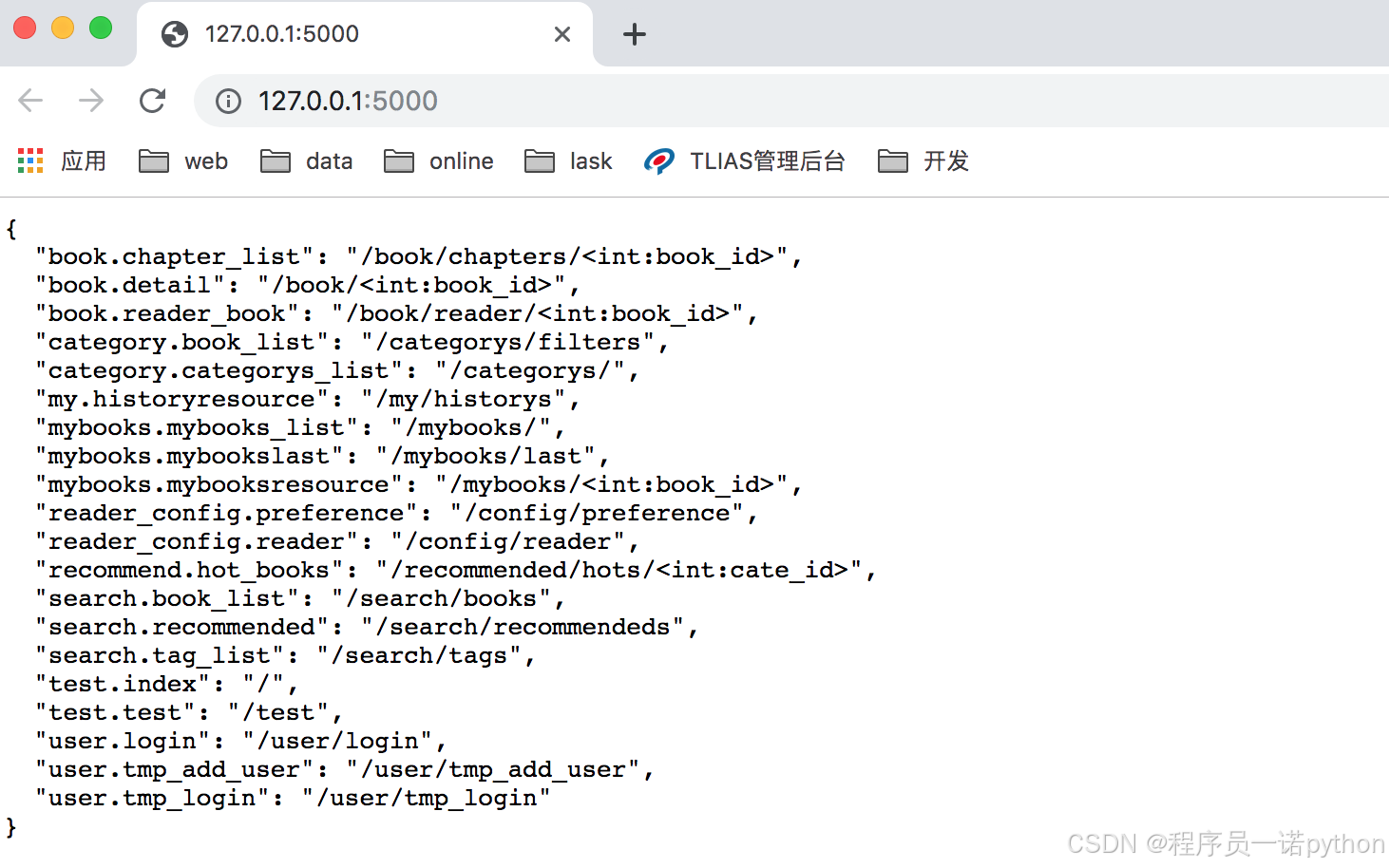
1.4目录说明
1-1 项目目录

1-2 具体说明
shell
hmwx-backend
├── applet_app # 存放项目的接口代码
│ ├── __init__.py # 项目的核心初始化文件,创建程序实例、数据库初始化等
│ ├── book.py # 书籍模块,书籍内容、阅读记录、章节列表
│ ├── category.py # 书籍分类模块,创建蓝图、接口代码
│ ├── my.py # 浏览记录
│ ├── mybooks.py # 我的书架,书架列表、添加删除、最后阅读
│ ├── reader_config.py # 阅读器设置
│ ├── recommend.py # 热门推荐
│ ├── search.py # 搜索书籍、模糊匹配、精准查找
│ ├── user.py # 用户登录、第三方登录
├── conf # 项目部署相关的配置信息
│ ├── supervisor_api.conf # 进程管理工具配置
│ ├── uwsgi_applet.ini # uwsgi服务器部署配置
│ ├── uwsgi_applet_local.ini # uwsgi服务器本地运行配置
├── lib # 项目资源库
│ ├── decorators.py # 登录校验装饰器
│ ├── flask_logging.py # 发送邮件
│ ├── jwt_utils.py # jwt的生成和校验
│ ├── pic_captcha.py # 图片验证码
│ ├── redis_utils.py # redis操作数据的工具
│ ├── sina.py # 用来爬取书籍的工具
│ ├── utils.py # 工具文件,获取ip、上传图片、密码加密
│ ├── wxauth.py # 授权登录
│ └── WXBizDataCrypt.py #
├── log # 日志文件
├── migrations # 迁移仓库,数据库迁移脚本记录
├── models # 项目模型类
│ ├── __init__.py # 统一导入项目模型类
│ ├── base.py # 创建ORM对象,flask-sqlalchemy
│ ├── book.py # 书籍模型类
│ ├── history.py # 浏览记录模型类
│ ├── other.py # 搜索数据模型类
│ └── user.py # 用户模型类
├── scripts # 脚本目录,爬取书籍、处理爬取后的数据
├── config.py # 项目配置文件
├── manage.py # 项目启动文件
├── mange_book.py # 项目书籍管理修改书籍数据
├── readme.txt # 项目运行说明文件
├── reload.sh # 重新启动的脚本文件
├── requirements.txt # 项目依赖包
└── wsgi_applet.py # 项目上线部署启动文件1-3 项目目录搭建
Flask官方文档对项目的目录实现也没有具体要求,开发人员可以根据自己的需求灵活实现。黑马文学的项目目录,也只是一种实现方式,具体实现步骤:
- 在pycharm中新建hmwx_backend项目
- 在pycharm中选择创建的虚拟环境python解释器
- 创建项目启动文件manage.py,实现Flask的基本程序
- 在manage.py文件中,实现项目的基本配置,数据库、脚本管理器、迁移等
- 配置文件、蓝图、工厂函数
- 把代码进行拆分
- 后续根据具体的功能,新创建文件或文件夹
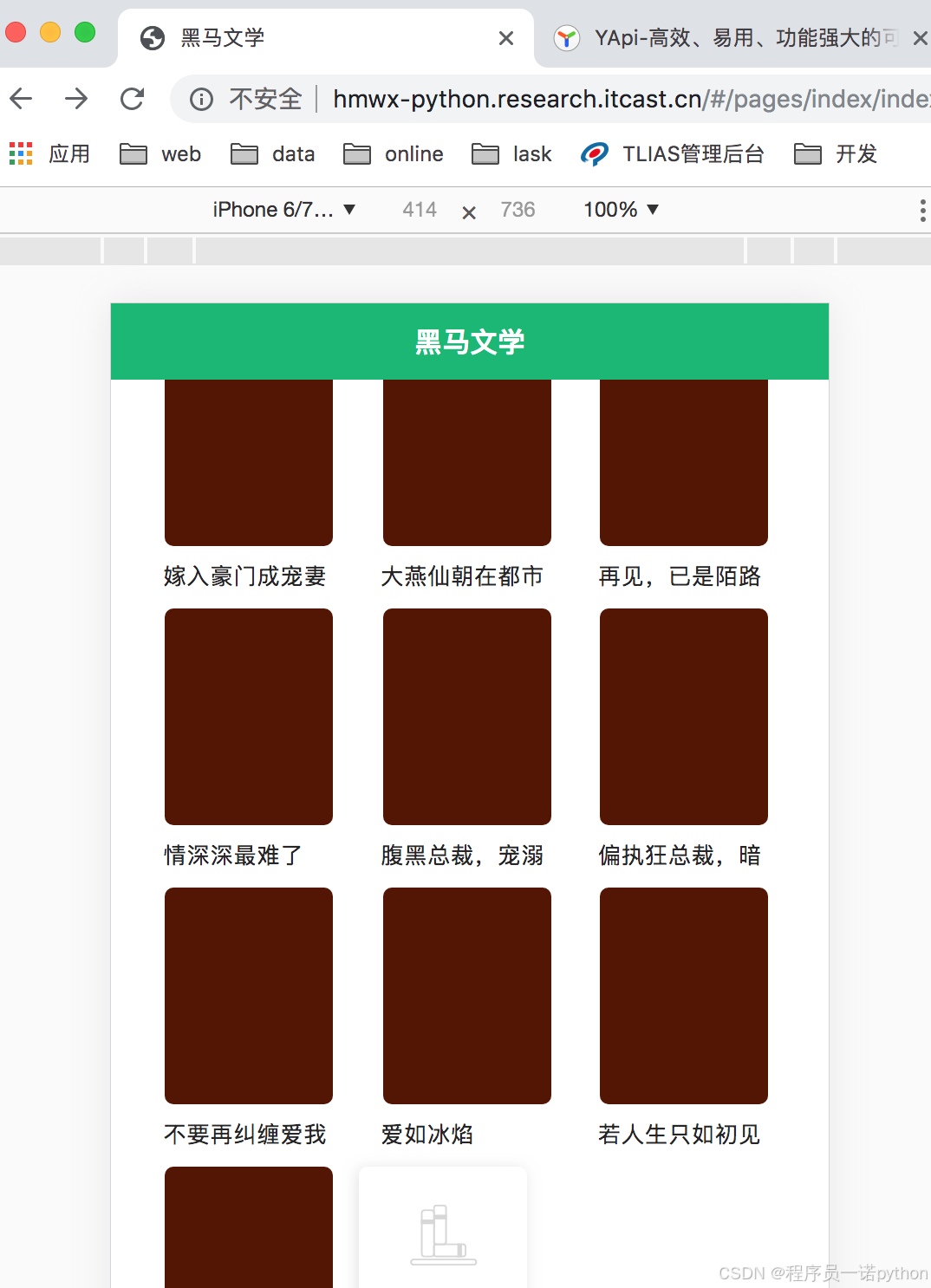
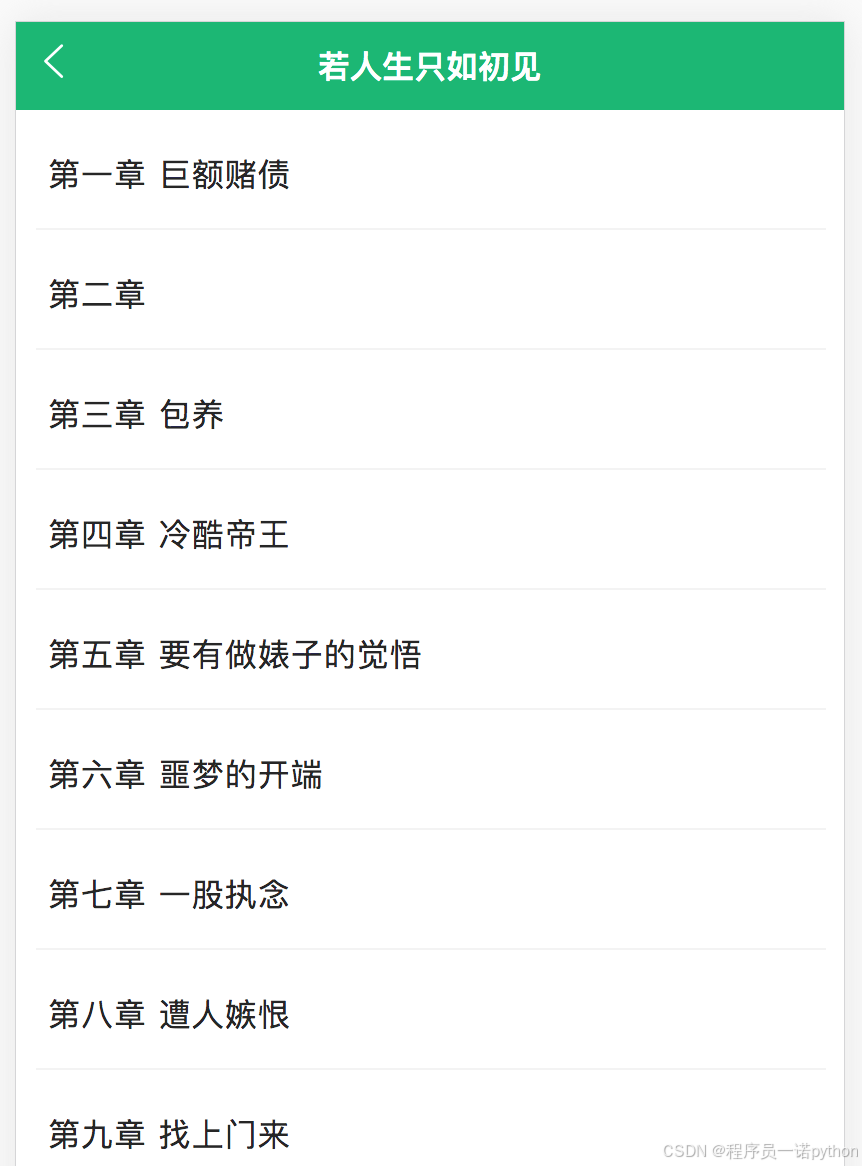
产品效果
- 移动web
[

1.5数据库设计
1-1 根据黑马文学产品原型图,进行数据库设计。
- 表结构
- 字段类型
- 索引设计
1-2 数据存储设计。

1-3 模型类
1、模型类概览
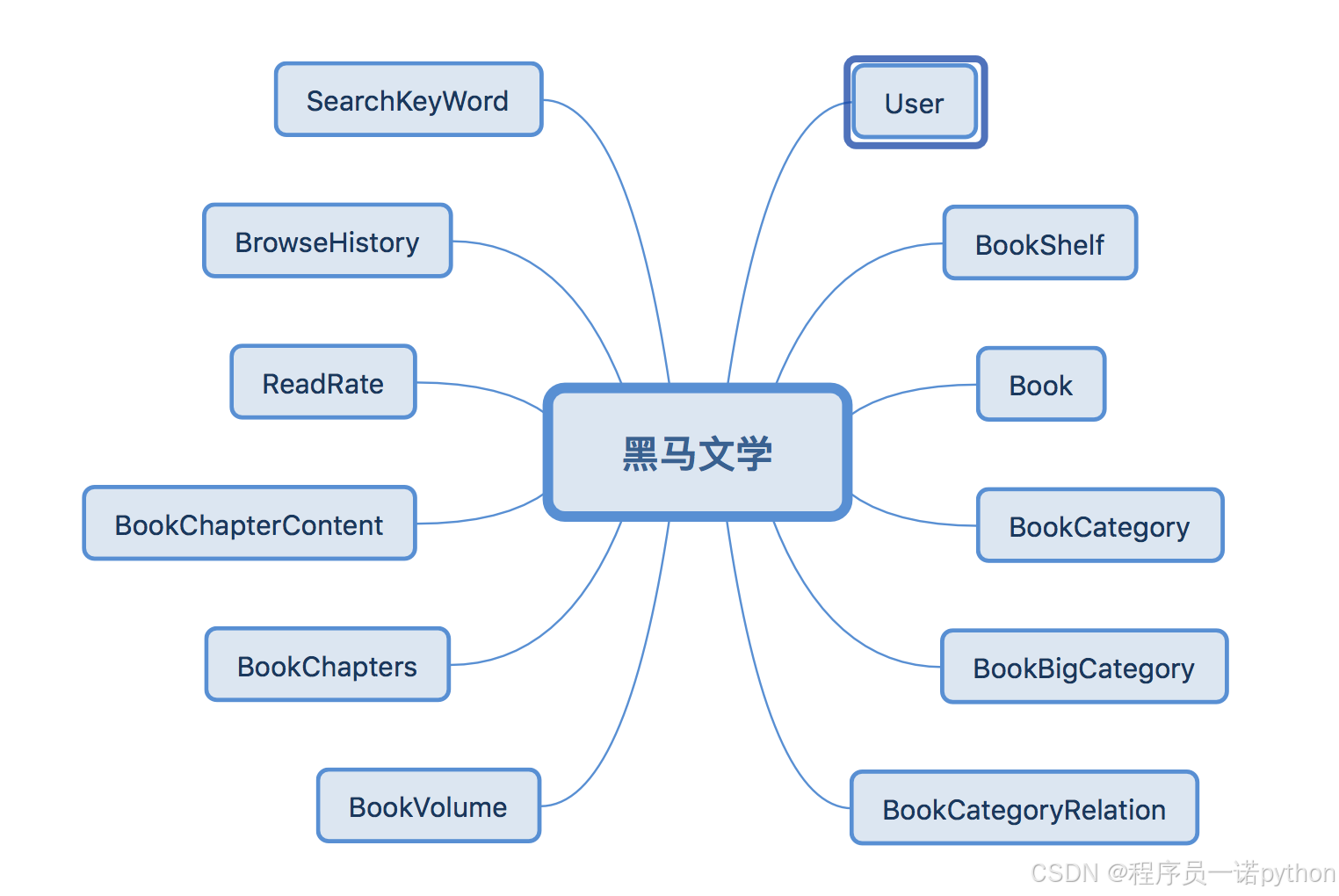
2、模型类定义
- 用户表
python
class User(UserMixin, db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
# 小程序 user_info
openId = db.Column(db.String(128), unique=True)
nickName = db.Column(db.String(50))
gender = db.Column(db.Integer, server_default='0',doc='1男0女')
city = db.Column(db.String(120),doc='城市')
province = db.Column(db.String(120),doc='省份')
country = db.Column(db.String(120),doc='国家')
avatarUrl = db.Column(db.String(200),doc='头像图片地址')- 书架表
python
class BookShelf(db.Model):
__tablename__ = 'book_shelf'
id = db.Column(db.Integer, primary_key=True)
book_id = db.Column(db.Integer, index=True,doc='书籍id')
book_name = db.Column(db.String(100),doc='书籍名称')
cover = db.Column(db.String(300),doc='封面图片')
user_id = db.Column(db.Integer,doc='用户id')
# default设置的默认值,只有在使用ORM添加或更新数据时,才真正设置默认值。
# server_default设置的默认值,是给数据库设置真正的默认值。
# func是sqlalchemy的函数,用来生成sql函数表达式,可以实现功能调用,func.now()表示生成当前时间。
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')
updated = db.Column(db.DateTime, server_default=func.now(),doc='更新时间')
db.Index('ix_book_id_user_id', book_id, user_id, unique=True)- 书籍表
python
class Book(db.Model):
__tablename__ = 'book'
book_id = db.Column(db.Integer, primary_key=True,doc='书籍id')
channel_book_id = db.Column(db.String(20), unique=True,doc='渠道书籍id')
book_name = db.Column(db.String(100),doc='书籍名称')
cate_id = db.Column(db.Integer, index=True,doc='书籍一级分类id')
cate_name = db.Column(db.String(50),doc='书籍一级分类名称')
channel_type = db.Column(db.SmallInteger(), index=True,doc='频道类型,1男2女3出版,默认0')
author_name = db.Column(db.String(50),doc='作者名称')
chapter_num = db.Column(db.Integer,doc='章节数量')
is_publish = db.Column(db.Integer,doc='是否出版,是1否2')
status = db.Column(db.Integer,doc='连载状态,1未完结2已完结')
create_time = db.Column(db.DateTime,doc='创建时间(第三方)')
cover = db.Column(db.String(300),doc='封面图片链接')
intro = db.Column(TEXT,doc='书籍简介')
word_count = db.Column(db.Integer,doc='字数')
update_time = db.Column(db.DateTime,doc='更新时间')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')
showed = db.Column(db.Boolean(), server_defaulult='0',doc='是否上架')
source = db.Column(db.String(50),doc='来源')
ranking = db.Column(db.Integer, server_default='0',doc='排序')
short_des = db.Column(db.String(50), server_default='',doc='短描述')
collect_count = db.Column(db.Integer, server_default='0',doc='收藏数量')
heat = db.Column(db.Integer, server_default='0',doc='热度')- 书籍分类信息
python
class BookCategory(db.Model):
__tablename__ = 'book_category'
cate_id = db.Column(db.Integer, primary_key=True)
cate_name = db.Column(db.String(50),doc='分类名称')
showed = db.Column(db.Boolean(), server_default='1',doc='是否显示,1显示0不显示')
icon = db.Column(db.String(100),doc='图标')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')- 书籍一级分类信息表
python
class BookBigCategory(db.Model):
__tablename__ = 'book_big_category'
cate_id = db.Column(db.Integer, primary_key=True,doc='分类id')
cate_name = db.Column(db.String(50),doc='分类名称')
channel = db.Column(db.Integer,doc='频道,1男2女')
showed = db.Column(db.Boolean(), server_default='1',doc='是否展示')
icon = db.Column(db.String(100),doc='图标')
created = db.Column(db.DateTime, server_default=func.now())
# 关系定义,表示书籍分类和一级分类的关系引用,secondary表示连接条件。
second_cates = db.relationship('BookCategory',
secondary=BookCategoryRelation.__table__
)- 书籍分类和一级分类
python
class BookCategoryRelation(db.Model):
__tablename__ = 'book_category_relation'
id = db.Column(db.Integer, primary_key=True)
big_cate_id = db.Column(db.Integer, db.ForeignKey('book_big_category.cate_id'),doc='一级分类id')
cate_id = db.Column(db.Integer, db.ForeignKey('book_category.cate_id'),doc='书籍分类id')- 书籍卷节信息
python
class BookVolume(db.Model):
__tablename__ = 'book_volume'
id = db.Column(db.Integer, primary_key=True)
book_id = db.Column(db.Integer, index=True,doc='书籍id')
volume_id = db.Column(db.Integer, index=True,doc='卷id')
volume_name = db.Column(db.String(100),doc='卷名')
create_time = db.Column(db.DateTime, default=datetime.now(),doc='创建时间')
chapter_count = db.Column(db.Integer, default=0,doc='卷字数')
update_time = db.Column(db.DateTime, default=datetime.now(),doc='更新时间')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')- 书籍章节信息表
python
class BookChapters(db.Model):
# 创建表的默认引擎是MyISAM,可以手动指定数据库引擎,指定表的编码
__table_args__ = {'mysql_engine': 'InnoDB', 'mysql_charset': 'utf8'}
id = db.Column(db.Integer, primary_key=True)
book_id = db.Column(db.Integer, index=True,doc='书籍id')
volume_id = db.Column(db.Integer, index=True,doc='卷id')
chapter_id = db.Column(db.Integer, index=True,doc='章节id')
chapter_name = db.Column(db.String(100),doc='章节名称')
word_count = db.Column(db.Integer,doc='字数')
create_time = db.Column(db.DateTime,doc='创建时间(第三方)')
update_time = db.Column(db.DateTime,doc='更新时间')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')- 书籍章节内容表
python
class BookChapterContent(db.Model):
__tablename__ = 'book_chapter_content'
id = db.Column(db.Integer, primary_key=True)
book_id = db.Column(db.Integer,doc='书籍id')
volume_id = db.Column(db.Integer,doc='卷id')
chapter_id = db.Column(db.Integer,doc='章节id')
content = db.Column(MEDIUMTEXT,doc='章节内容')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')
db.Index('ix_book_id_chapter_id', book_id, chapter_id)- 阅读进度表
python
class ReadRate(db.Model):
__tablename__ = 'read_rate'
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer,doc='用户id')
book_id = db.Column(db.Integer,doc='书籍id')
chapter_id = db.Column(db.Integer,doc='章节id')
chapter_name = db.Column(db.String(100),doc='章节名称')
rate = db.Column(db.Integer, default=0,doc='阅读进度')
created = db.Column(db.DateTime, server_default=func.now(),doc='创建时间')- 浏览记录
python
class BrowseHistory(db.Model):
__tablename__ = 'browse_history'
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer(), db.ForeignKey('user.id'),doc='用户id外键')
book_id = db.Column(db.Integer(), db.ForeignKey('book.book_id'),doc='书籍id外键')
book = db.relationship('Book', uselist=False,doc='关系引用')
created = db.Column(db.DateTime(), server_default=func.now(),doc='创建时间')
updated = db.Column(db.DateTime(), server_default=func.now(),doc='修改时间')- 搜索关键词
python
class SearchKeyWord(db.Model):
__tablename__ = 'search_key_word'
id = db.Column(db.Integer, primary_key=True)
keyword = db.Column(db.String(100),doc='关键词')
count = db.Column(db.Integer, default=0,doc='搜索次数')
is_hot = db.Column(db.Boolean, default=False,doc='是热点,默认值否')1.6数据库迁移
1-1 迁移准备
-
根据产品原型设计数据库的数据存储,把模型类定义完成,这个时候,我们可以通过迁移的方式,创建数据库表,前提要首先在mysql中创建数据库。
-
mysql中有了数据库以后,实现数据库迁移,需要用到2个扩展包。
-
flask-script:提供程序运行、迁移的脚本命令。
-
flask-migrate:提供数据库迁移的功能。
1-2 在项目的启动文件manage.py实现数据库迁移。
python
# 从flask_script中导入脚本管理器
from flask_script import Manager
# 从flask_migrate导入迁移工具、迁移命令
from flask_migrate import Migrate, MigrateCommand
# 实例化脚本管理器对象
manager = Manager(app)
# 让迁移工具和程序实例app、sqlalchemy实例关联
Migrate(app, db)
# 添加迁移命令
manager.add_command('db', MigrateCommand)
if __name__ == '__main__':
manager.run()1-3 在终端中通过命令执行迁移
- 初始化迁移仓库
python
python manage.py db init- 生成迁移脚本文件
python
python manage.py db migrate- 执行迁移脚本文件
python
python manage.py db upgrade产品效果
- 移动web
[