说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解 ),如需数据+代码+文档+视频讲解 可以直接到文章最后关注获取。

1 . 项目背景
在现代数据科学领域,回归分析是解决预测问题的核心工具之一。然而,在面对复杂、高维的现实世界数据时,传统的回归模型往往难以达到理想的预测精度。随机森林作为一种集成学习方法,因其强大的泛化能力和对非线性关系的捕捉能力而备受青睐。但其超参数调优过程通常依赖于网格搜索或随机搜索等传统方法,效率较低且易陷入局部最优解。为了解决这一问题,本项目引入了NOA(Nature-Inspired Optimization Algorithm,自然启发式优化算法)中的星雀优化算法,旨在通过模拟自然界中星雀群体的行为模式,提升随机森林模型的优化效率和性能。
本项目采用Python作为开发语言,结合NOA星雀优化算法与随机森林回归模型,构建了一套高效的优化框架。星雀优化算法以其独特的群体智能机制和全局搜索能力,能够有效避免传统优化方法的局限性,从而帮助随机森林模型找到更优的超参数组合。此外,通过将星雀优化算法与机器学习模型相结合,本项目不仅提升了模型的预测精度,还大幅降低了计算资源的消耗。这种创新性的技术融合为解决实际工程问题提供了全新的思路。
该项目的研究成果可广泛应用于金融预测、环境监测、医疗诊断等领域。例如,在金融领域,优化后的随机森林模型可以更准确地预测股票价格波动;在环境监测中,该模型可用于空气质量指数的预测,为政策制定提供科学依据。未来,随着NOA算法的进一步发展和优化,结合更多类型的机器学习模型,有望在更大范围内推动智能化决策的发展。本项目的成功实施不仅验证了星雀优化算法的实际应用价值,也为后续研究奠定了坚实的基础。
本项目通过Python实现NOA星雀优化算法优化随机森林回归模型项目实战。
2 . 数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|------------|--------------|------------|
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
数据详情如下(部分展示):
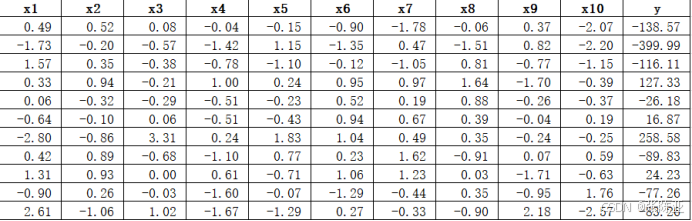
3. 数据预处理
3.1 用P andas 工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
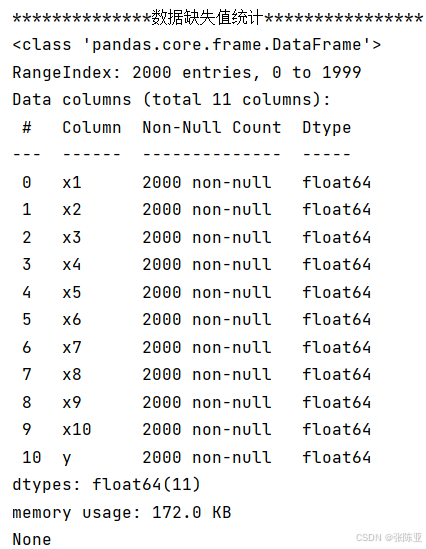
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3. 3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
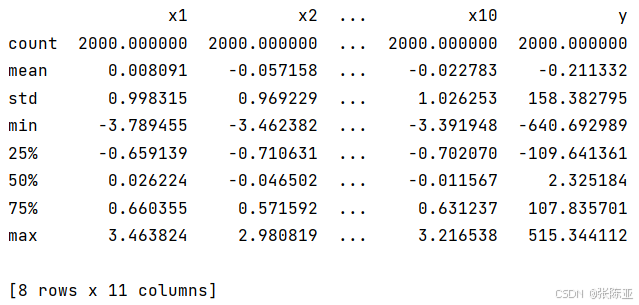
关键代码如下:

4. 探索性数据分析
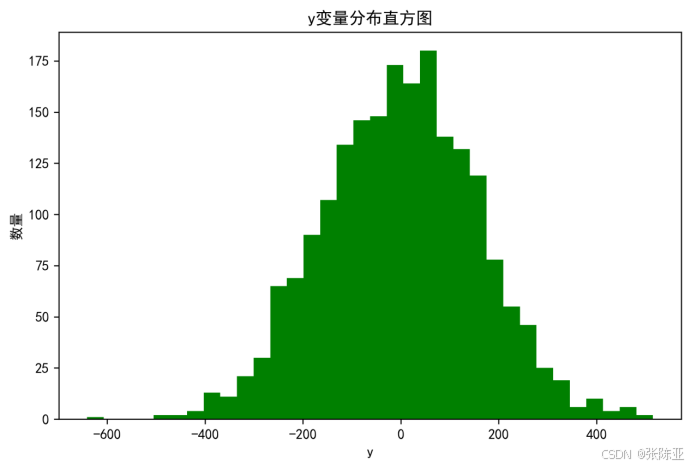
4 .1 y变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4 .2 相关性分析
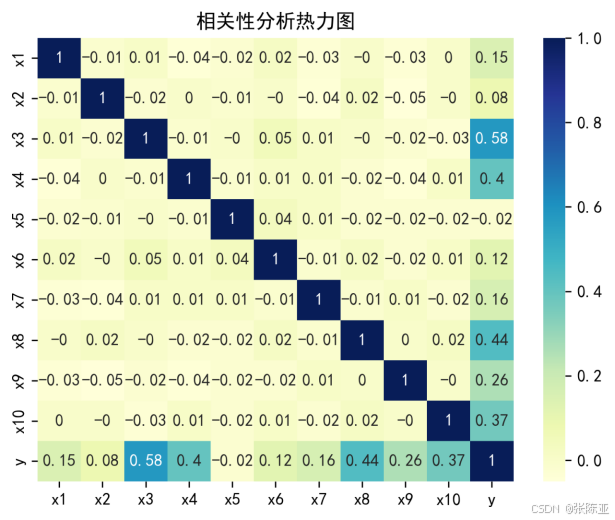
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5. 特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5. 2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6. 构建 NOA星雀优化算法 优化 随机森林 回归模型
主要使用通过NOA星雀优化算法优化随机森林回归模型,用于目标回归。
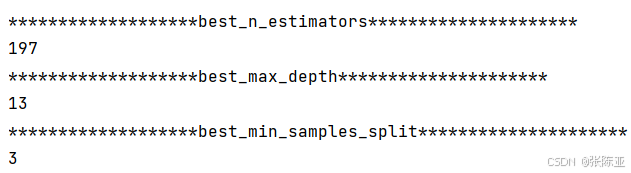
6. 1 NOA星雀优化算法 寻找最优参数值
最优参数值:
6. 2 最优参数构建模型
|------------|--------------|------------------------------------------|
| 编号 | 模型名称 | 参数 |
| 1 | 随机森林回归模型 | n_estimators=best_n_estimators |
| 2 | 随机森林回归模型 | max_depth=best_max_depth |
| 3 | 随机森林回归模型 | min_samples_split=best_min_samples_split |
7 . 模型评估
7.1评估指标及结果
评估指标主要包括R方、均方误差、解释性方差、绝对误差等等。
|--------------|--------------|-------------|
| 模型名称 | 指标名称 | 指标值 |
| 测试集 |||
| 随机森林回归模型 | R方 | 0.8622 |
| 随机森林回归模型 | 均方误差 | 3289.1528 |
| 随机森林回归模型 | 解释方差分 | 0.8649 |
| 随机森林回归模型 | 绝对误差 | 43.9522 |
从上表可以看出,R方分值为0.8622,说明模型效果比较好。
关键代码如下:

7.2 真实值与预测值对比图
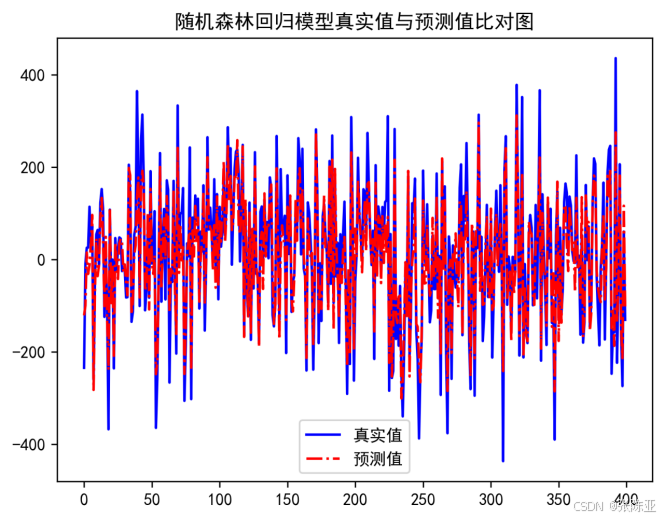
从上图可以看出真实值和预测值波动基本一致,模型效果良好。
8. 结论与展望
综上所述,本文采用了Python实现NOA星雀优化算法优化随机森林回归算法来构建回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。