参考笔记:java LinkedList 源码分析(通俗易懂)_linkedlist源码分析-CSDN博客
目录
[4.LinkedList 与 ArrayList 的对比](#4.LinkedList 与 ArrayList 的对比)
[4.1 如何选择](#4.1 如何选择)
[4.2 对比图](#4.2 对比图)
[5.LinkedList 源码Debug](#5.LinkedList 源码Debug)
[5.1 add(E e)](#5.1 add(E e))
[(2) 跳入add方法](#(2) 跳入add方法)
[5.2 remove()](#5.2 remove())
[(2) 跳入remove()方法](#(2) 跳入remove()方法)
[(5) 第一个结点被删除](#(5) 第一个结点被删除)
1.前言
本文是对单列集合 List 的实现类之一 LinkedList 的源码解析。对于单列集合 List 的三个最常用的实现类------ ArrayList, Vector, LinkedList ,我对 ArrayList、Vector 的源码解读在另外两篇文章,感兴趣的话可以看看:
【Java集合】ArrayList源码深度分析-CSDN博客
https://blog.csdn.net/m0_55908255/article/details/146886585【Java集合】Vector源码深度分析-CSDN博客

2.LinkedList简介
① LinkedList 是一种常见的线性表,每一个结点中都存放了下一个结点的地址。 LinkedList 类位于 java.lang.LinkedList 下,其类定义和继承关系图如下:

② 链表可分为单向链表和双向链表
**单项链表的每个结点:**包含两个值------当前结点的值、下一个结点的地址值(以指向后一个结点)
**双向链表的每个结点:**包含三个值------前一个结点的地址值(以指向前一个结点)、当前结点的值、下一个结点的地址值(以指向后一个结点)
③ LinkedList 底层实现了双向链表和双端队列的特点
④ 同 ArrayList、Vector 类似,可以向 LinkedList 集合中添加任意元素,包括 null,并且元素允许重复
⑤ 同 ArrayList 一样,LinkedList 也没有实现线程同步,因此 LinkedList 线程不安全
3.LinkedList的底层实现
① LinkedList 的底层维护了一个双向链表。 LinkedList 类中维护了 first、last 属性,见名知意,它们分别指向双向链表的首结点和尾结点。其在源码中的定义如下:
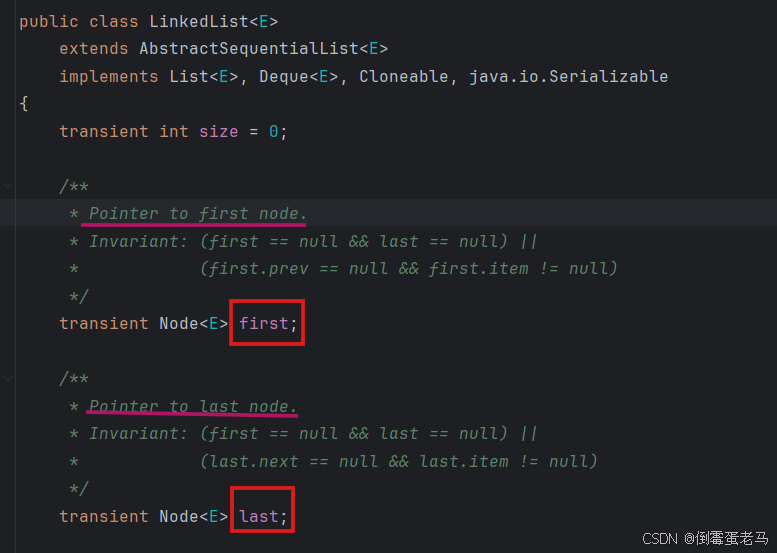
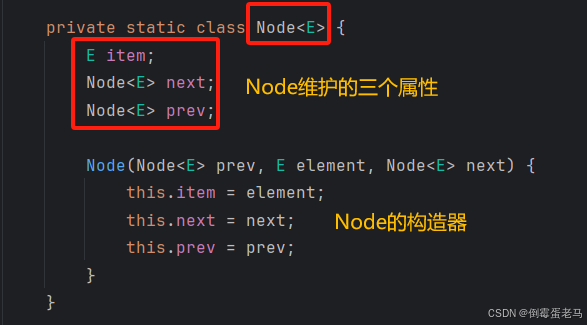
② 链表中的每个结点( Node 对象)中又维护了 prev,next,item三个属性,item 存放当前节点的值。通过 prev 指向前一个结点,通过 next 指向后一个结点,从而实现双向链表。此处的 Node<E> 类型,实际上是 LinkedList 类中维护的一个静态内部类,如下图所示 :
③ LinkedList 中元素的添加和删除,在底层不是通过数组来完成的,而是通过链表来完成。因此 LinkedList 相对来说增删的效率更高
补充:为什么链表的增删效率比数组高相信学过数据结构的同学都知道,这里我简单提一下
答案:数组如果删除中间的某一个元素可能需要挪动大量的数据,增加亦是如此。而链表只需要修改所删除节点的前后节点的next、prev即可,比较方便
④ 双向链表的示意图如下 : (注意箭头是指向结点整体)

这里我用 Java 来模拟一个简单的双向链表,现在创建三个《诛仙》人物对象------陆雪琪、张小凡、小环,并且让他们形成如下的双向链表关系:

代码如下:
java
public class demo {
public static void main(String[] args) {
//演示 : 用java模拟一个简单的双向链表
//创建诛仙人物对象
Node luxueqi = new Node("陆雪琪"); //第一个结点
Node zhangxiaofan = new Node("张小凡"); //第二个结点
Node xiaohuan = new Node("小环"); //第三个结点
//完成双向链表
//从左往右相连接
luxueqi.next = zhangxiaofan;
zhangxiaofan.next = xiaohuan;
//从右往左相连接
xiaohuan.prev= zhangxiaofan;
zhangxiaofan.prev= luxueqi;
//令first指向第一个结点,令last指向最后一个结点
Node first = luxueqi;
Node last = xiaohuan;
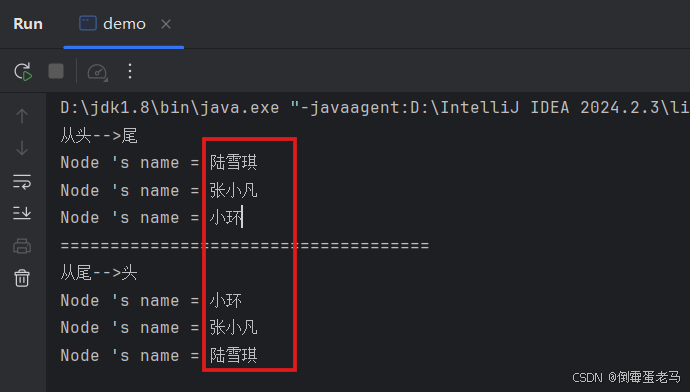
//遍历链表(头 ------> 尾)
System.out.println("从头-->尾");
while (true) {
if (first == null) {
break;
}
System.out.println(first); //输出当前对象的信息
first = first.next; //更改指向
}
System.out.println("=====================================");
//遍历链表(尾 ------> 头)
System.out.println("从尾-->头");
while (true) {
if (last == null) {
break;
}
System.out.println(last); //输出当前对象的信息
last = last.prev; //更改指向
}
}
}
//自定义Node结点
class Node {
public Object item; //存放当前结点的数据
public Node prev; //指向前一个结点
public Node next; //指向后一个结点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node 's name = " + item;
}
}运行结果:
4.LinkedList 与 ArrayList 的对比
4.1 如何选择
① 增删操作多,优先选择 LinkedList ;改查操作多,优先选择 ArrayList
② 实际开发中,往往对集合的改查操作比较多,因此 ArrayList 一般用的较多
③根据实际业务需求来选择
④ ArrayList 与 LinkedList 线程均不安全,建议单线程情况下使用
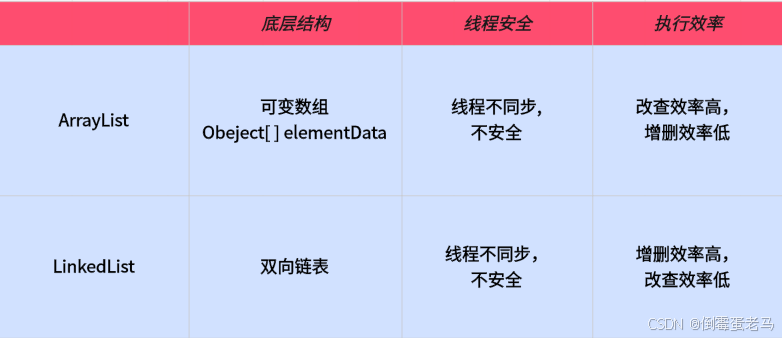
4.2 对比图
5.LinkedList 源码Debug
5.1 add(E e)
用以下代码为演示,进行 Debug 操作:
java
import java.util.LinkedList;
public class demo {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(11);
linkedList.add(141);
System.out.println(linkedList);
}
}(1)跳入无参构造
如下图所示:
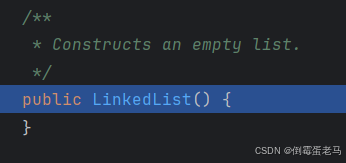
可以看到, LinkedList 类的无参构造其实什么也没有做,这里只会利用隐藏的 super() 调用父类的无参构造器。因为它底层使用链表实现的,所以不需要创建数组
直接跳出无参构造,可以看到 LinkedList 对象已经初始化完毕, LinkedList 维护的 first、last 属性经过了 默认初始化 ---> 显式初始化 ---> 构造器初始化,最后仍为默认值 null,如下图所示 :
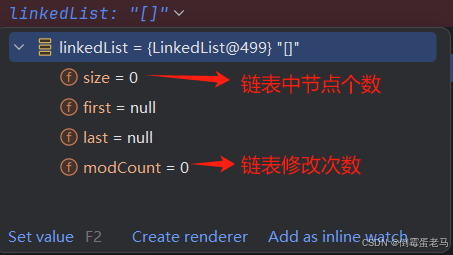
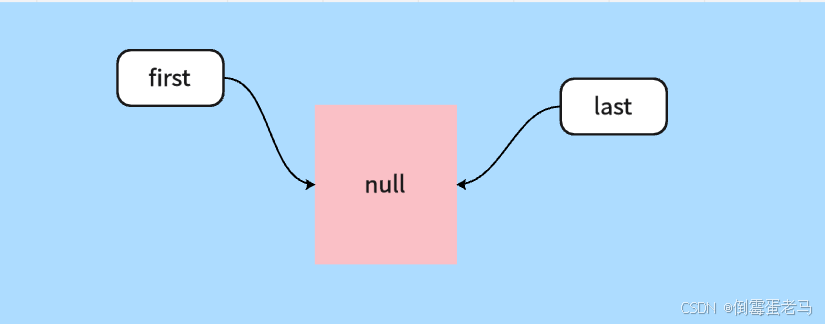
此时 first 和 last 均为 null。所以,链表此时的结构如下图所示:
(2) 跳入add方法
由于我们向链表中添加的元素为 int 类型,所以跳入 add 方法之前会进行自动装箱 int ---> Integer,如下图所示:
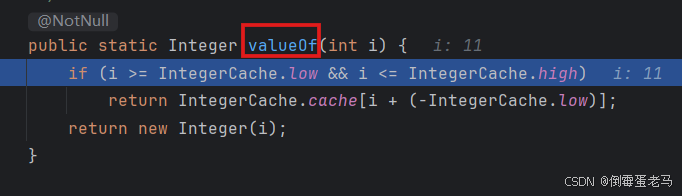
自动装箱结束后,跳入 add 方法,如下图所示:
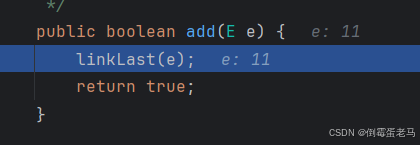
形参列表的 "e" 表示我们当前要添加的元素,所以此时 e = 11 。 add 方法中调用了 linkLast 方法,在 linkLast 方法里面完成了添加元素的操作
(3)跳入linkLast方法
跳入 linkLast 方法,如下图所示:
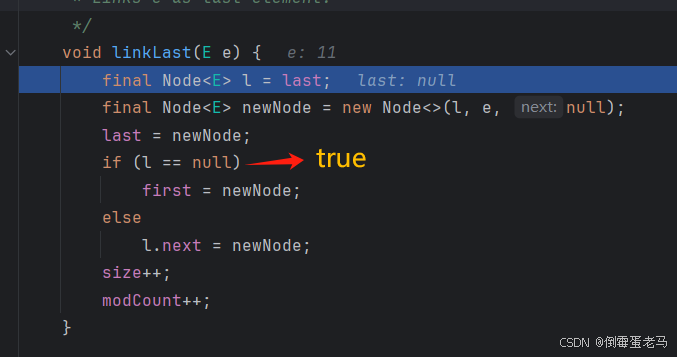
一步一步来看
**首先,**Node 是"结点"的意思,就是 Node<E> 类型
**其次,**本文上面提到说------此时 first == null,last == null。所以,linkLast 方法内,第一步是定义了一个 Node 类型的常指针 ,并令其指向为 last,所以此时
**接着,**又定义了一个 Node 类型的常量 newNode 。见名知意,"newNode" 就是我们要添加的新结点。那么,为 newNode 初始化的这个带参构造 new Node<>(l,e,null) 是怎么执行的呢?这三个实参分别是干嘛的?
我们追入这个带参构造看个究竟:

可以看到,构造器的三个形参就是 Node 对象的三个属性。所以,对应此处的三个实参, 就是 prev,此时为 null ;e 就是已经装箱好的 11 ;null 就是 next 的值
因此, newNode 引用此时指向的就是一个前后结点均为空,值为 11 的新结点
执行完带参构造,就是 last = newNode,即又令 last 指向了添加的新结点,使得 last 始终指向链表中的最后一个结点,这是典型的链表尾插法
继续向下执行,是一个 if-else 的复合条件语句。判断条件 "l == null" 显然满足,令 first 也指向了该新结点;之后,又令 size 自增 1 (size表示当前链表中结点的个数),modCount 也自增 1(modCount表示链表的修改次数)

(4)增加第一个元素成功
linkLast 执行完毕后,此时的链表结构如下图所示:
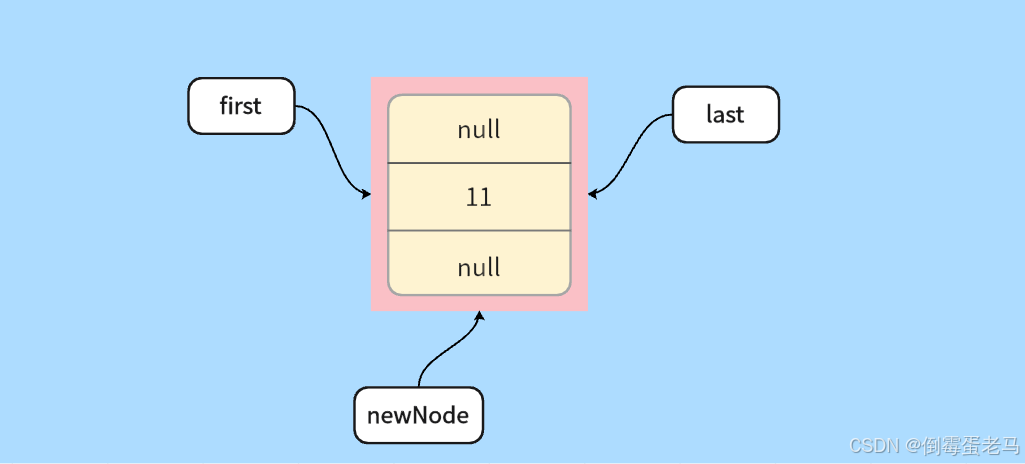
接下来,我们可以逐层跳出直到演示类中验证一下上面的链表结构图是否正确。此时链表的状态,如下图所示:

可以看到,first 和 last 确实是指向了同一个结点,并且该结点中 prev = null,next = null,item = 11
(5)向链表中添加第二个元素
向链表中添加第 2 个元素,前面几个步骤都一样,这里就不再赘述了,直接从 linkLast 方法开始说起,如下 :
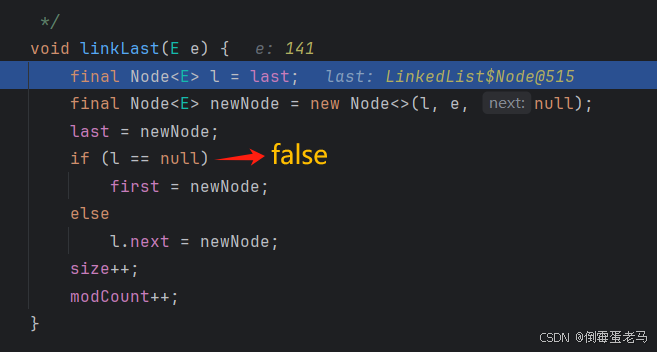
还是一步一步来看
**首先,**令 Node 类型的常指针 指向了 last 所指向的结点(即我们前面添加的第一个结点,此时它也为链表中的最后一个结点)
**其次,**第二个新结点 newNode 进行初始化工作。注意,第一个实参 代表的是新结点的prev,而
此时指向的是第一个结点,因此,这一步实现了------令新节点 newNode 的 prev 指向了第一个结点
接着,执行完带参构造,就是 last = newNode,即又令 last 指向了添加的新结点 newNode ,使得 last 始终指向链表中的最后一个结点,这是典型的链表尾插法
**之后,**就是 if-else 的判断语句了,此时 指向的是链表中的第一个结点,不为空,所以执行 else 中的语句,l.next = newNode,令第一个结点的 next 指向了新结点
**最后,**就是更新 size 、modCount
综上,第二次 linkLast 方法执行完毕后,链表结构如下图所示:
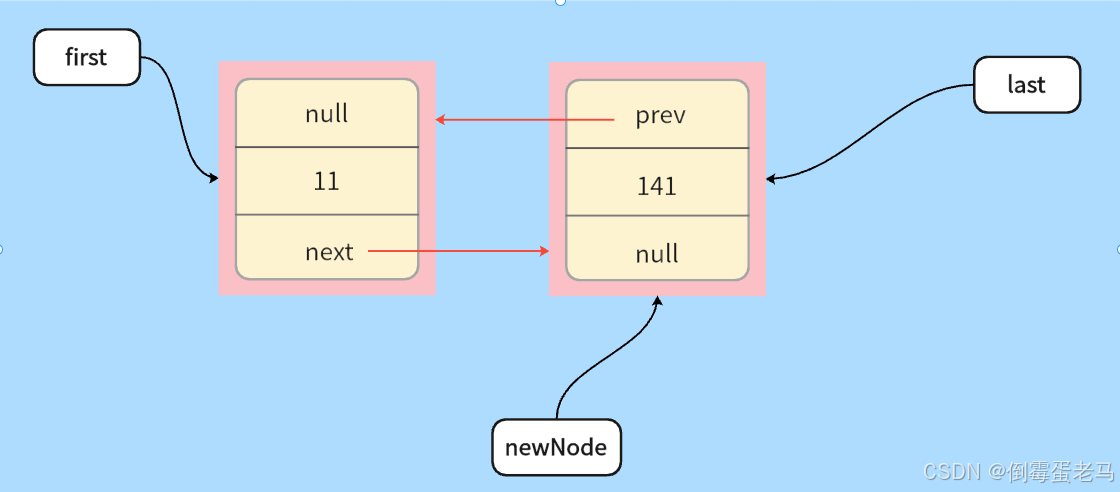
🆗,以上就是 LinkedList 的 add(E e) 方法源码分析
5.2 remove()
LinkedList 类的 remove 有三个重载方法:
① remove( ):删除链表的第一个结点
② remove(int index):删除链表中第 index-1 个结点
③ remove(Object o):删除链表中与 o 值匹配的第一个结点
(1)准备工作
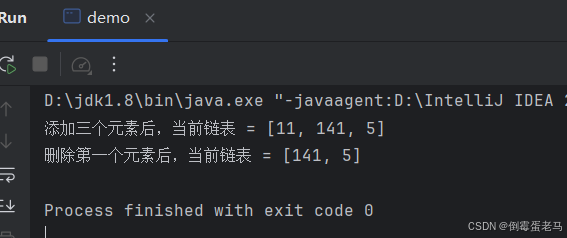
用以下代码演示 remove() ,进行 Debug 操作:
java
import java.util.LinkedList;
public class demo {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add(11);
linkedList.add(141);
linkedList.add(5);
System.out.println("添加三个元素后,当前链表 = " + linkedList);
linkedList.remove();
System.out.println("删除第一个元素后,当前链表 = " + linkedList);
}
}运行结果:
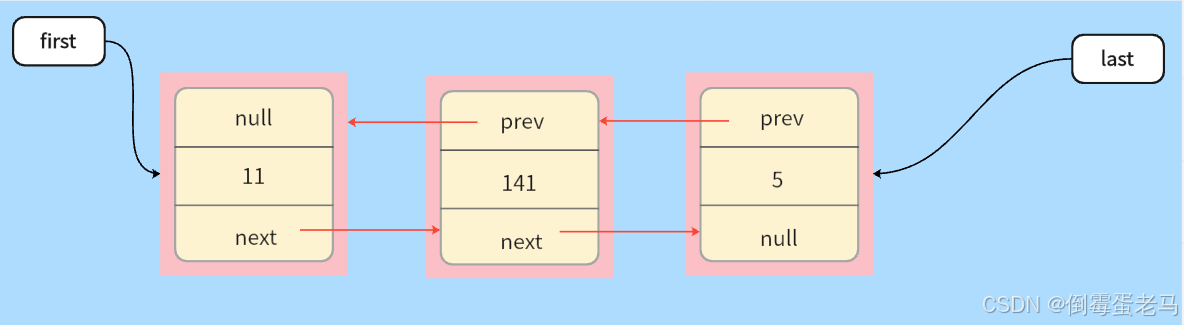
如代码所示,先在链表中加入三个元素:11,141,5 。则在删除元素之前,双向链表的结构如下图所示:
(2) 跳入remove()方法
我们直接在 remove 方法的调用行设置断点跳过去,并跳入 remove 方法,如下图所示 :
(3)跳入removeFirst()方法
removeFirst 方法的源码如下:
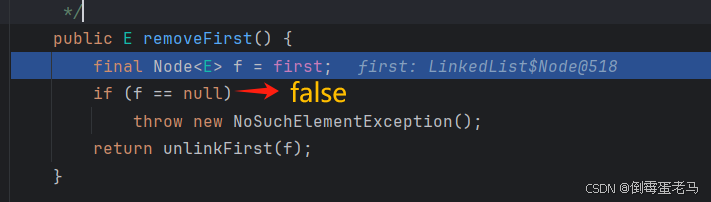
首先,它令一个 Node 类型的常指针 f 指向了链表的第一个结点**,** 然后判断首结点是否为空。由于我们一开始就在链表中添加了 3 个元素,所以此处 f 肯定不为空。因此, if 语句中的内容会跳过,执行 return unlinkFirst(f)
(4)跳入unlinkFirst()方法
跳入 unlinkFirst 方法,其源码如下:
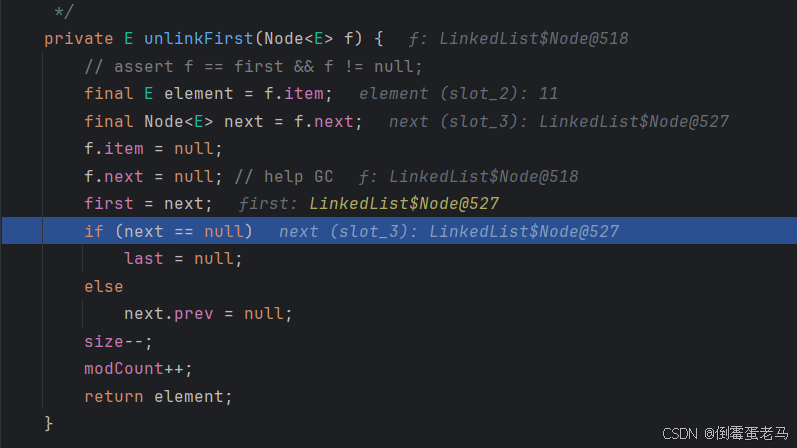
一步一步来看
首先,第一条语句不用太关注。取出欲删除结点的 item 值只是为了最后 return 返回,与删除过程本身无关
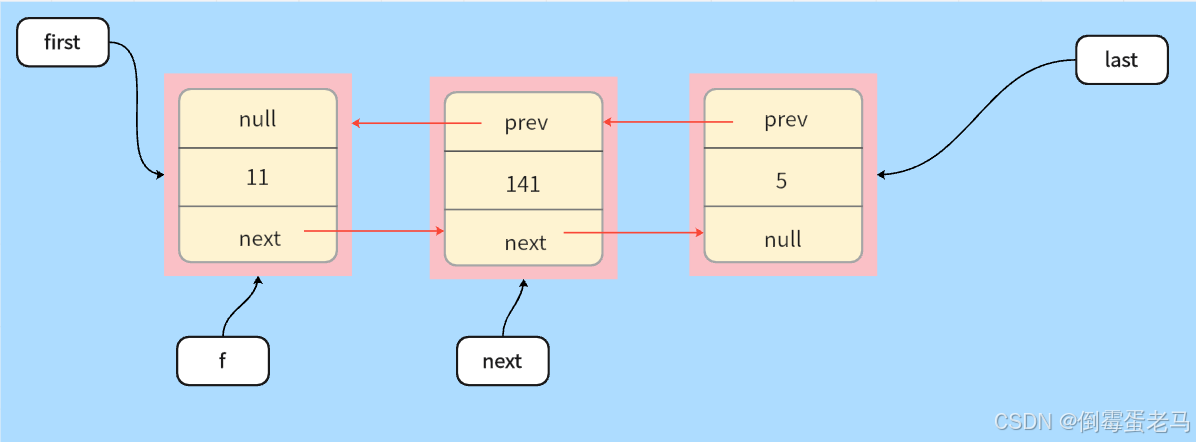
**其次,**第二条语句 final Node<E> next = f.next,它令一个 Node 类型的常指针 next 指向了 "第一个结点的next属性所指向的值",即指向了第二个结点,如下图所示 :
接着 ,执行 f.item = null,f.next = null,置空了第一个结点的 item 和 next ,并且令first 指向了第二个结点,如下图所示 :
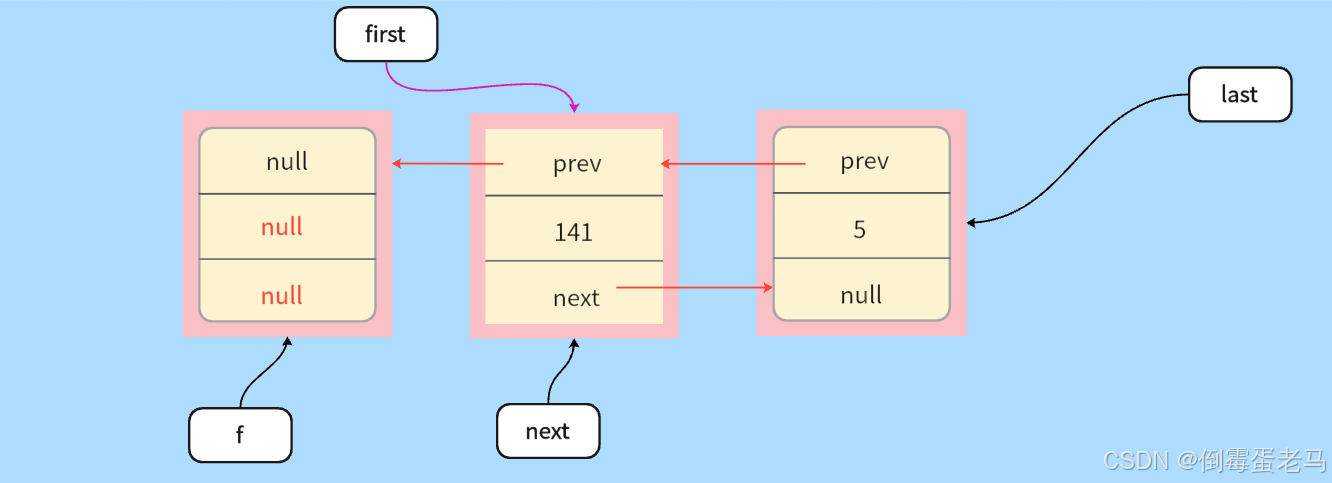
继续, 由于 next 现在指向的是第二个结点,不为空,所以接下里要进入 else 语句中。else语句中,next.prev = null,即将第二个结点的 prev 置为 null ,如下图所示 :
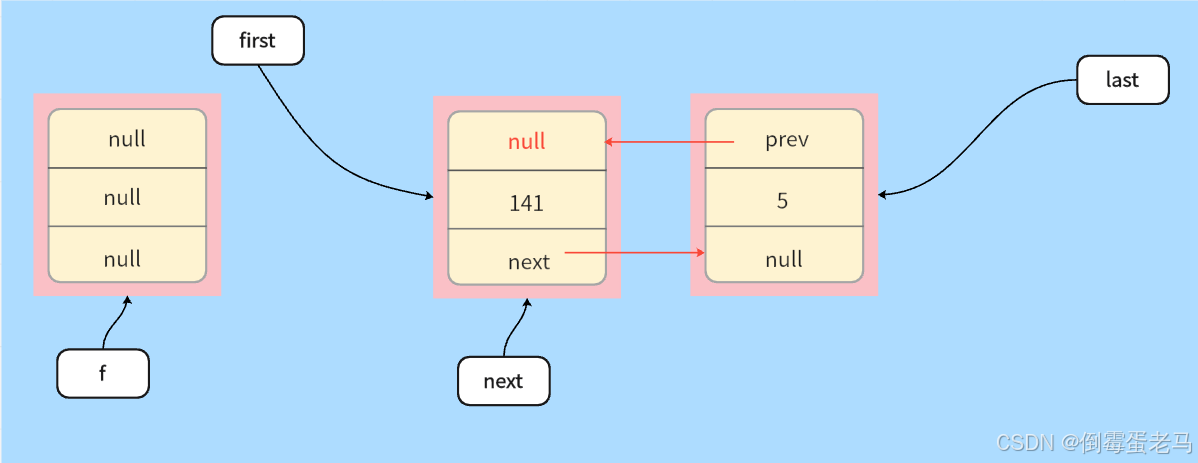
最后就是 size - 1,即链表中的结点个数减 1 ;modCount + 1,链表修改次数加 1 ;return elment,返回删除结点其对应的 item 值
(5) 第一个结点被删除
至此,链表中的第一个结点被删除。回顾一下整个流程
① 将第一个结点的 item、next 置为 null
② 将 first 指向了第二个结点
③ 将第二个结点的 prev 值置为 null ,切断其与第一个结点的"联系"
④ 经过①②③ ,第一个结点被置于链表之外,之后会被 gc垃圾回收器 删除