- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
YOLOv5啊有四种不同大小的网络模型,YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。
YOLOv5s是网络深度和宽度最小但检测速度最快的模型,其余三种都是在YOLOv5s基础上不断加深、加宽网络使得网络规模扩大,在增强模型检测性能的同时增加计算资源和速度消耗。
./models/yolov5s.yaml 是YOLOv5s网络结构文件,如果想要改进算法的网络结构,需要先修改该文件的相关参数,然后再修改**./models/common.py** 和**./models/yolo.py**中的相关代码。
- 本周任务:将yolov5s网络模型中第4层的C3*2修改为C3*1,第6层的C3*3修改为C3*2
- 任务提示:仅需修改./models/yolov5s.yaml文件
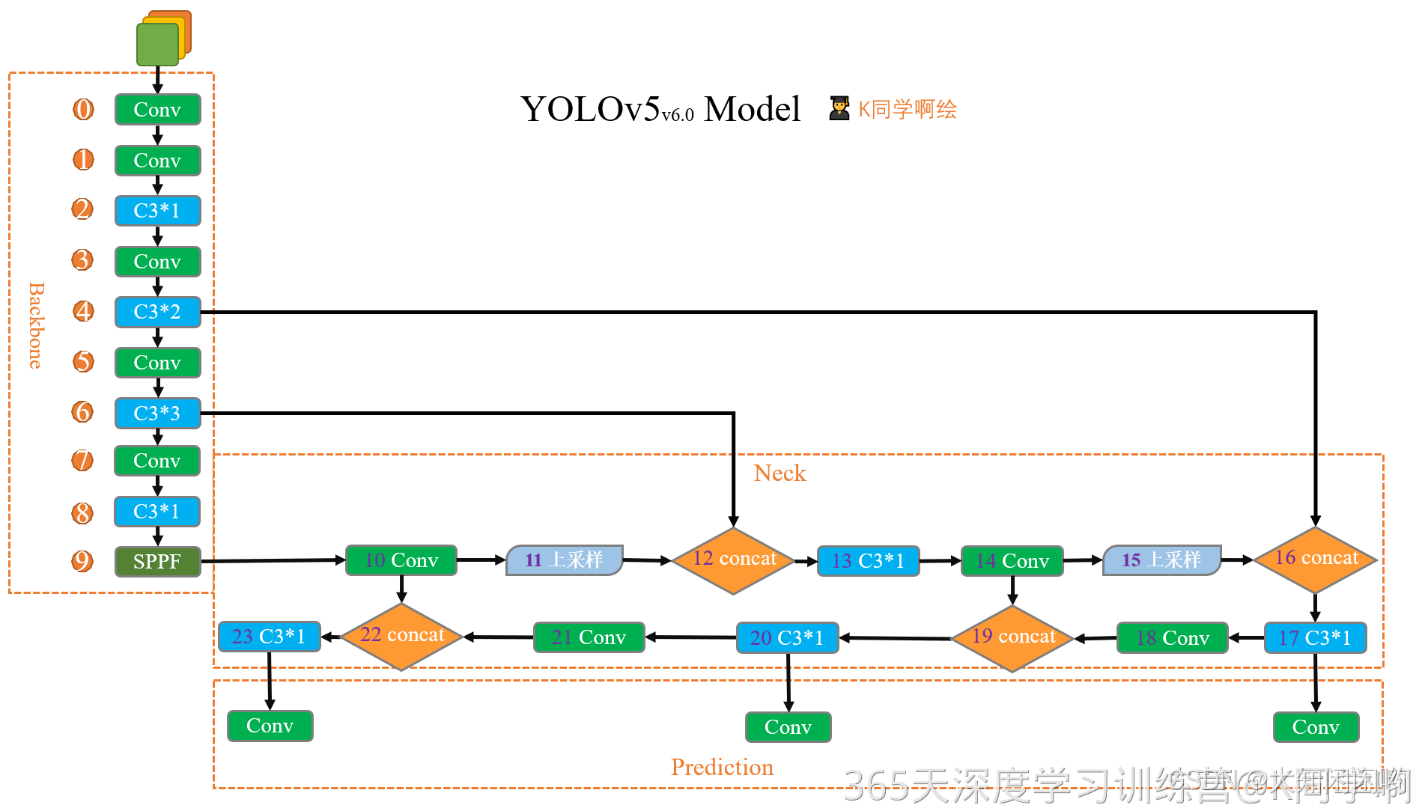
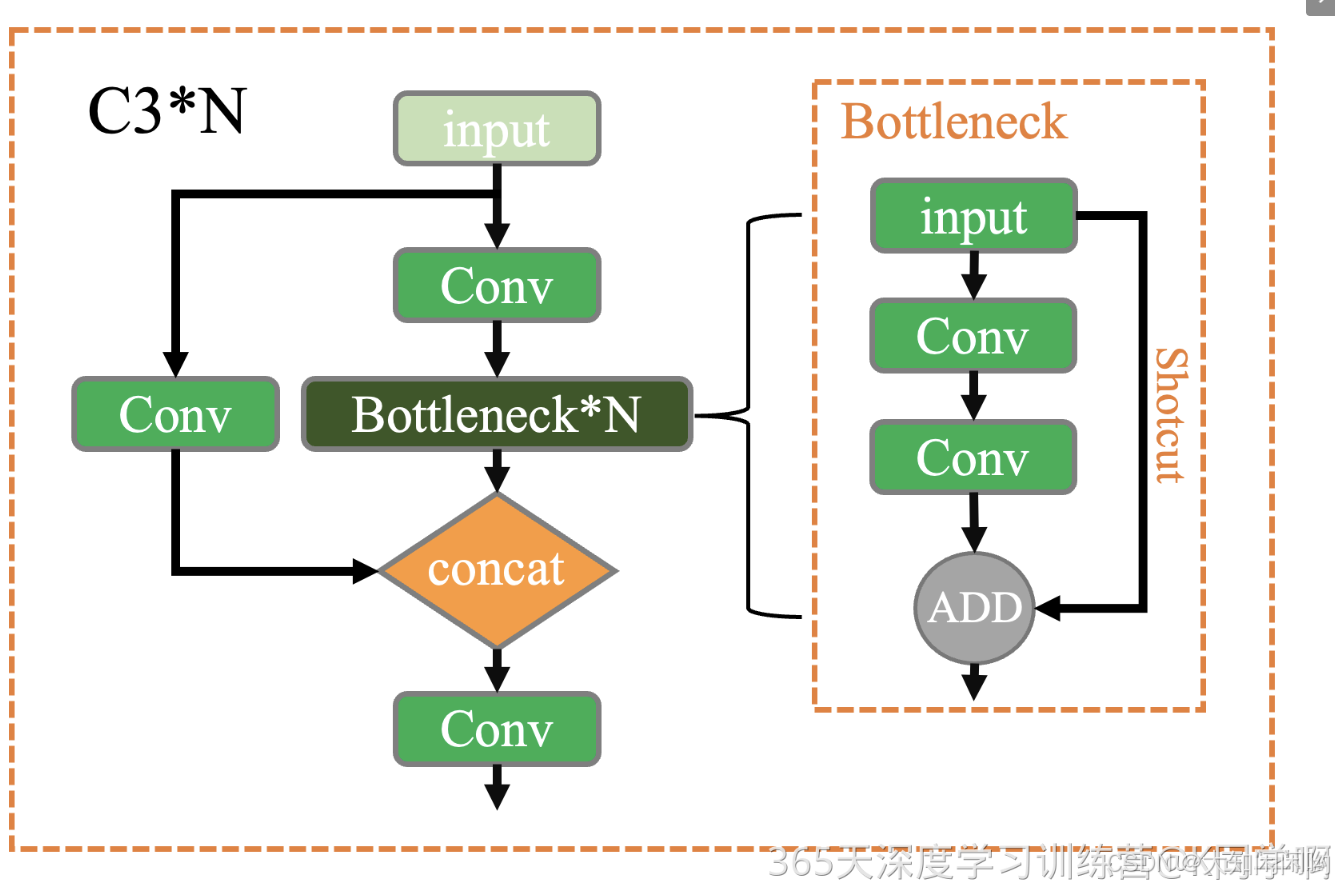
1.参数配置
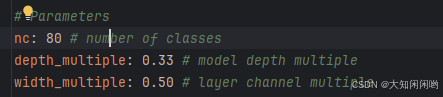
depth_multiple 控制子模块数量,=int(number*depth_multiple) 该参数与任务有关
width_multiple 控制卷积核的数量,=int(number*width_multiple)
通过两个参数可以实现不同复杂度的模型设计。
YOLOv5的四个模型的区别仅在于depth_multiple和width_multiple这两个参数的不同
2.anchors配置
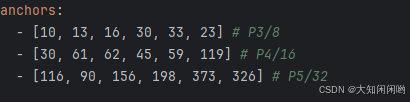
检测小目标3组:10,13 16,30 33,23
检测中目标3组:30,61 62,45 59,119
检测大目标3组:116,90 156,198 373,326
YOLOv5初始化9个anchors,在三个Detect层使用3个feature map中使用,每个feature map的每个grid_cell都有三个anchor进行预测。
分配规则:
①尺度越大的feature map越靠前,相对原图的下采样率越小,感受野越小,所以相对可以预测一些尺度较小的物体,所有分配到的anchors越小
②尺度越小的feature map越靠侯,相对原图的下采样率越大,感受野越大,所以相对可以预测一些尺度较大的物体,所有分配到的anchors越大
(即可以在小特征图feature map上检测大目标,也可以在大特征图上检测小目标)
YOLOv5根据工程经验得到三组anchor,对很多数据集很合适,但也不能保证适用于所有数据集。
所有YOLOv5还有一个anchor进化策略:使用k-means和遗传进化算法,找到与当前数据集最吻合的anchors。
k-means:对当前数据集中所有的标注信息中的目标框尺寸做聚类,输出9对anchors值。
3.backbone
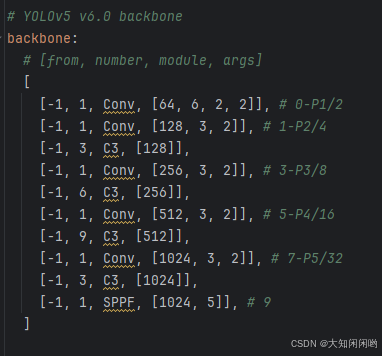
每一个模块算一行,每行由四个参数构成。
- from:当前模块的输入来自哪一层的输出,-1表示来自上一层输出,层编号由0开始计数。
- number:当前模块的理论重复次数,实际重复次数要由上面的参数depth_multiple共同决定,该参数影响整体网络模型的深度
- module:模块类名,通过这个类名在common.py中寻找相应类,进行模块化的搭建网络
- args:一个list,模块搭建所需参数channel、kernel_size、stride、padding、bias等
4.head
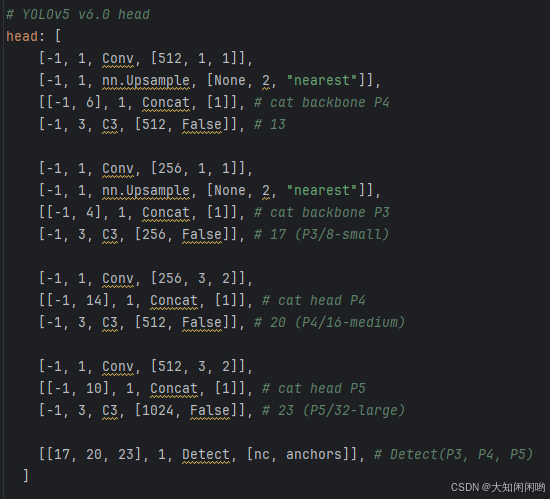
数据格式与backbone一样
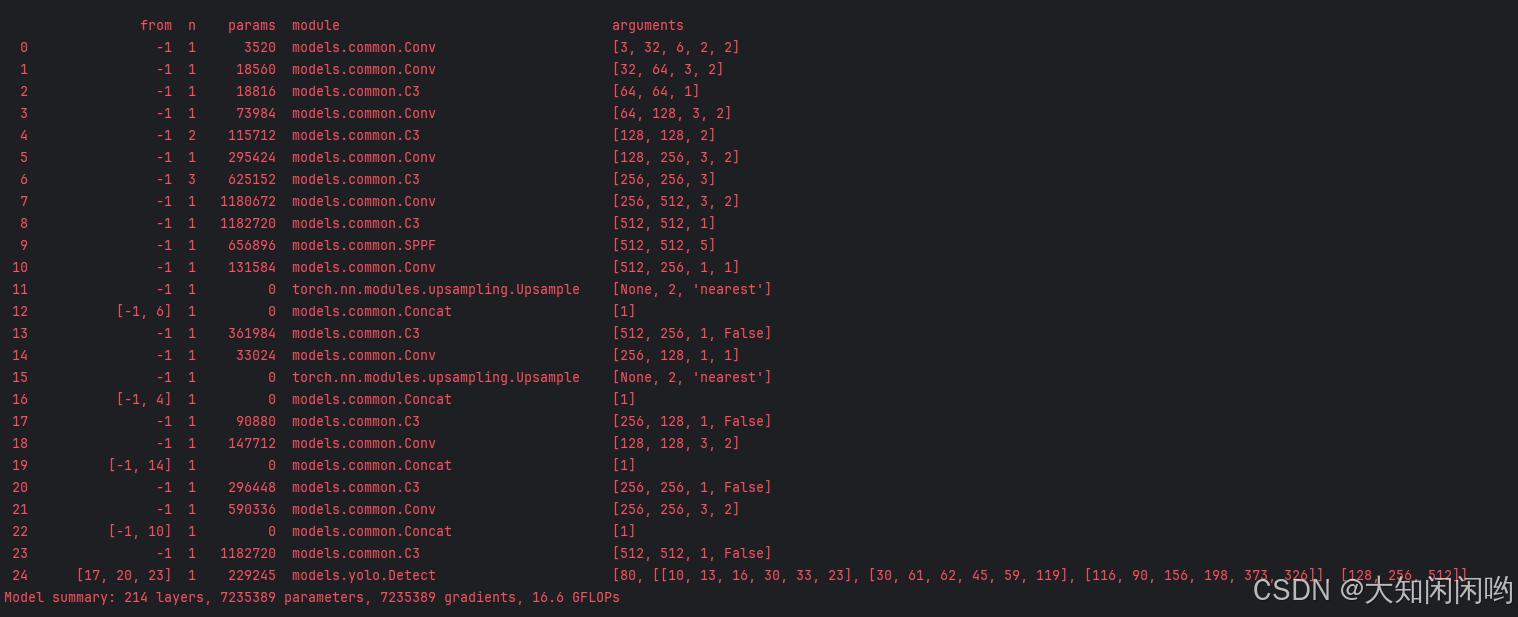
5.整体模型
运行train.py文件
6.任务
代码:
python
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]修改后:
python
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 3, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 6, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]7.总结
学习了YOLOv5s.yaml文件,掌握了每个部分的内容,理解了每一块代码的意义。