回顾并为当天的工作定下目标
接着回顾了前一天的进展。之前我们做了一些调试功能,并且已经完成了一些基础的工作,但是还有一些功能需要继续完善。其中一个目标是能够展示实体数据,以便在开发游戏逻辑系统时,可以清晰地查看和检查游戏实体的状态,尤其是在出现异常时,可以快速排查原因。我们希望能够通过鼠标选择一个实体并查看它的状态。
在前一天的直播中,讨论了如何实现展示实体数据的功能。尝试了通过一些简单的代码实现了这个功能,比如在调试UI系统中输出实体的状态数据。通过一些特定的调试命令,我们能够很方便地查看实体的状态,而不需要每次都手动输入数据。目标是让这一切变得自动化,以便提高效率,避免重复工作。
随后,讨论中提到了一个常见的问题:如何自动化这个过程。为了减少手动更新代码的麻烦,想要通过一种方法来自动化显示实体数据的过程。当前,实体数据每次更改时,都需要手动修改显示的部分,这显然非常繁琐。所以,考虑使用一种简单的系统来处理这个问题。
其中提到的关键问题是C++中缺乏自省(introspection)功能。即使是编程语言标准委员会多年讨论过这个问题,C++中依然没有内建这种功能。自省功能能够自动检测和输出类或结构体中的成员数据,而不需要程序员手动输入。这种功能在许多其他编程语言中早已具备,但C++中却没有。因此,计划展示如何在C++中实现一种简单的自省系统,自动输出实体的成员数据,而不需要手动逐一列出每个成员。
整个思路是通过编写一个简单的工具或系统,在C++中实现自省功能,从而使得调试和输出实体信息变得更加自动化和便捷。这将极大地提高开发效率,特别是在处理大量实体数据时。
simple_preprocessor.cpp: 进行自省
目标是演示如何实现自省功能,具体来说就是如何自动输出某些数据。为了实现这一点,首先需要编写一个程序,这个程序能够读取文件并输出所需的内容,类似于一个小型的预处理工具。这个工具的目的是简化手动输入的过程,让系统能够自动获取并展示实体的数据。
首先,创建一个简单的预处理程序,名为"simple_preprocessor"。这个程序不依赖任何复杂的库,完全可以用标准的输入输出操作来完成。这样做的好处是,它在任何环境下都能运行,而不需要依赖特定的库或框架。因此,程序员可以根据自己的需求选择任何工具或库来实现这个过程,而不需要拘泥于特定的技术栈。
然后,使用标准的C语言方式打开文件,读取文件内容。与使用高级文件API不同,C语言中的文件操作更基础,需要手动打开文件句柄(fopen),读取内容,然后再关闭文件句柄(fclose)。这种方式虽然比起更方便的文件API显得有些繁琐,但它仍然非常直观且有效。当前需要处理的文件是一个名为"game_sim_region"的文件,这个文件包含了需要预处理的数据。
在程序中,先打开文件并确认文件成功加载,然后对文件内容进行解析。虽然这样的方法比直接读取整个文件并自动处理要更基础,但它足以实现读取和预处理的基本功能。目标是通过这种方式,让程序能够从文件中提取必要的数据,并对其进行处理,以便后续的调试和输出。

simple_preprocessor.cpp: 将这个函数命名为 ReadEntireFileIntoMemoryAndNullTerminate
为了尽量减少使用外部库,目标是保持代码的简洁和独立,避免依赖过多的外部工具。如果是自己开发,可能会直接在已有代码的基础上进行扩展。为了实现这一目标,程序将会像之前的项目一样,读取整个文件并将其加载到内存中。这个过程使用了一个常见的、实用的函数,名为"ReadEntireFileIntoMemoryAndNullTerminate"。
该函数的作用是打开指定的文件,读取文件的全部内容,并在文件末尾加上一个空字符(null terminator)。在C语言中,字符串通常以空字符(\0)结束,这样可以明确标示字符串的结束位置。因此,这个函数的目的是确保文件内容以一个零字符结尾,方便后续处理。这个功能在许多程序中都非常常见,是处理文件和字符串时必备的工具。
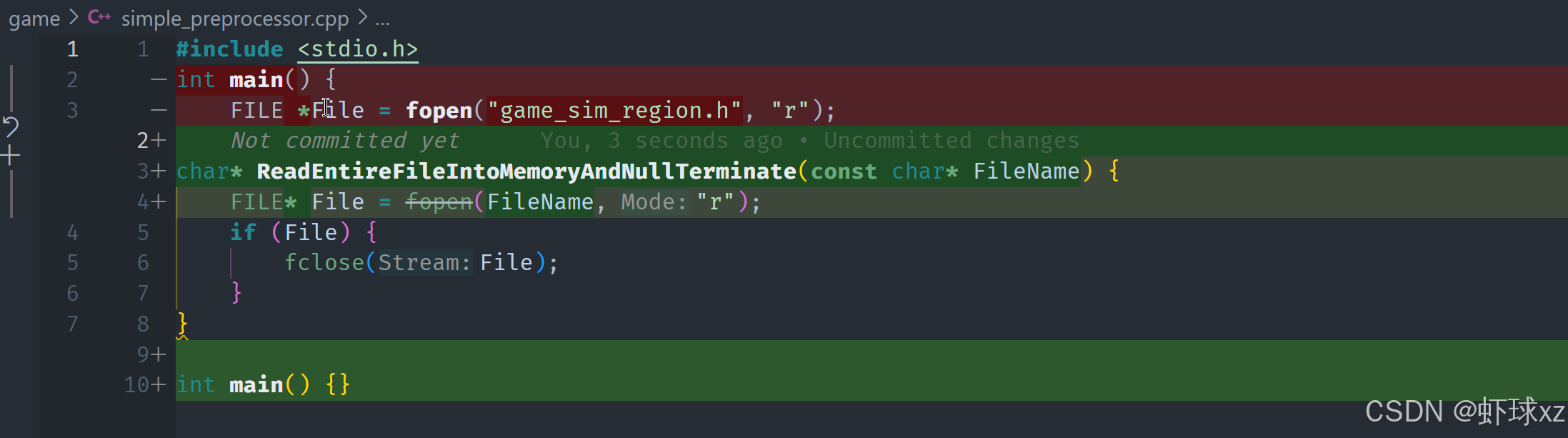
simple_preprocessor.cpp: 调用这个函数来处理 game_sim_region.h 并构建它
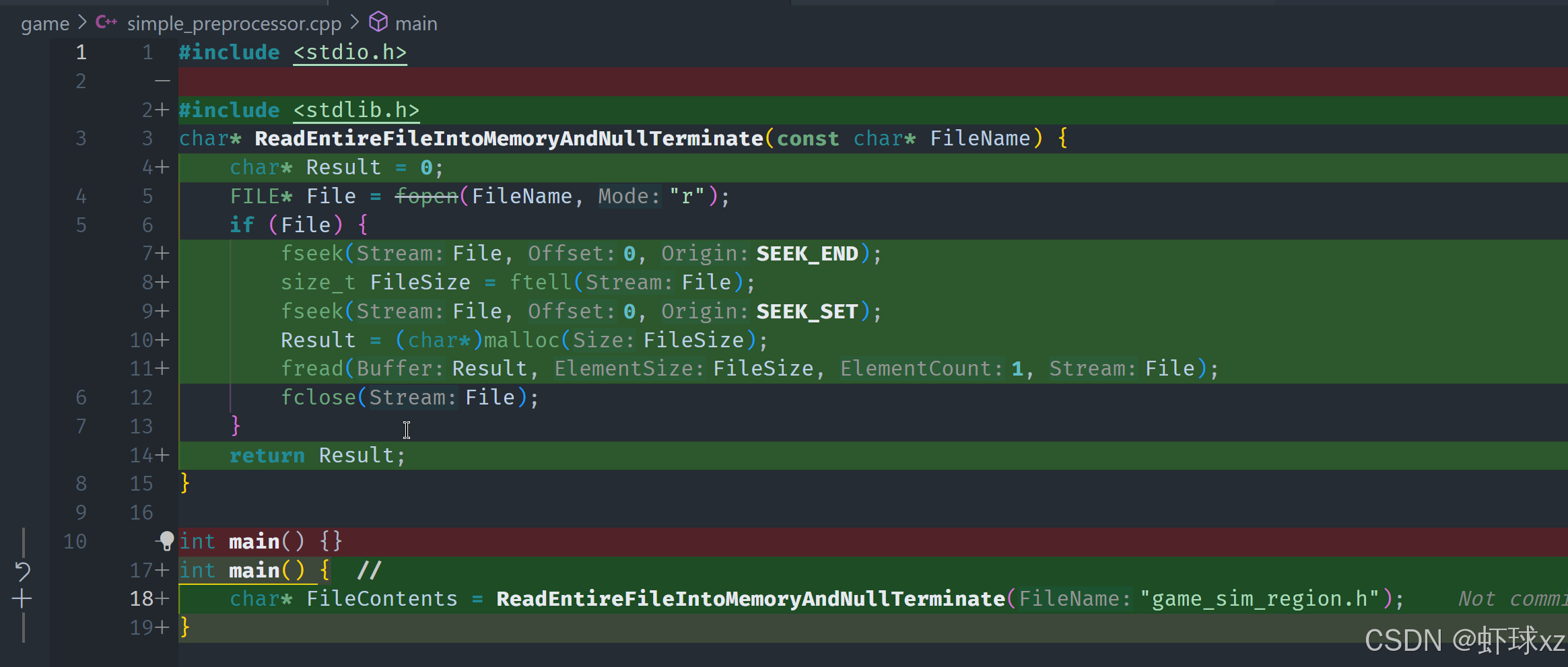
在这个过程中,首先需要通过调用一个函数 ReadEntireFileIntoMemoryAndNullTerminate 来加载文件内容。对于当前需要解析的文件 game_sim_region.h,首先需要确定文件的大小。
为了获取文件的大小,可以使用C语言的 fseek 函数,它能够将文件指针移动到指定的位置。通过将文件指针移至文件末尾,可以通过 ftell 函数获取当前指针的位置,进而得知文件的大小。然后,可以将文件指针再移回文件的开始位置。
确定了文件的大小后,就可以分配相应大小的内存来存储文件内容。使用 malloc 函数分配一块足够大的内存空间,然后使用 fread 函数读取文件内容到内存中。这个过程中需要注意的一个关键点是,fread 需要首先传入一个指向缓冲区的指针,其次是读取的大小,即文件的字节数。
通过这些步骤,可以成功地将文件加载到内存中,并进行后续处理。
cmake: 添加 simple_preprocessor.cpp
首先,开始尝试将整个文件加载到内存中,并检查是否一切正常。为此,需要先将代码添加到构建系统中。在已有的构建配置中,已经有了编译测试资源构建器的设置。因此,接下来要做的是将简单的预处理器代码 (simple_preprocessor.cpp) 添加到构建系统中。
具体步骤是,将 simple_preprocessor.cpp 添加到编译过程,并通过构建系统编译它。编译过程顺利完成之后,就可以进一步验证该文件加载和处理是否按预期进行。
这一过程的目的是确保简单的预处理器能够正确地加载文件,并能够在后续的步骤中使用这些加载的数据进行进一步处理。

调试器: 进入 simple_preprocessor.cpp 并确保它按预期工作

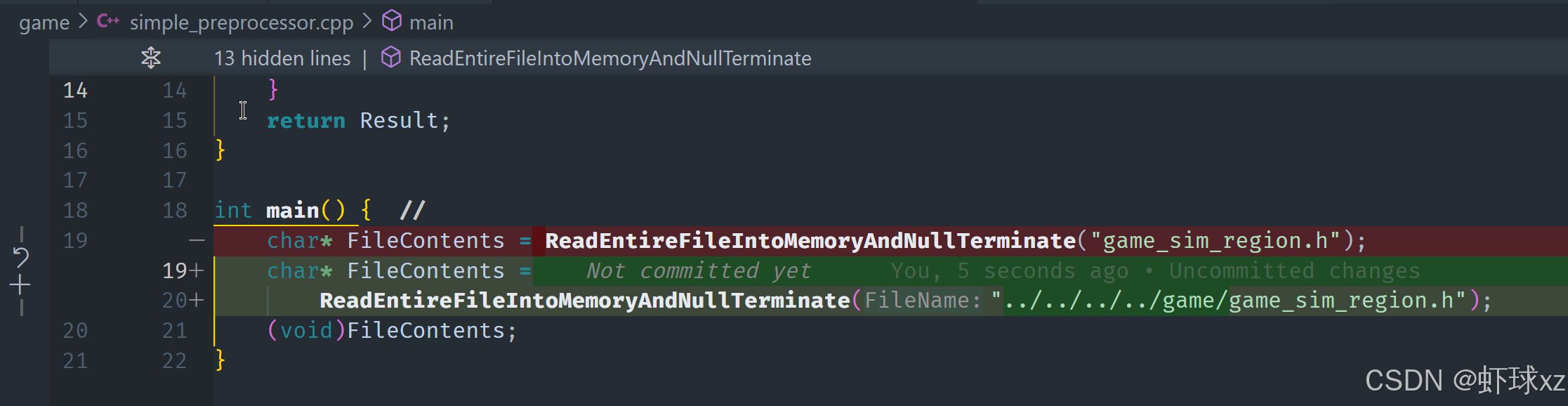
我们首先开始调试,进入调试器,确保文件加载功能按预期工作。我们将其设置为在游戏代码所在的目录中运行,以便能够找到需要解析的文件。接着,我们进入 ReadEntireFileIntoMemoryAndNullTerminate 函数,看到它成功地打开了文件,能够正确读取文件。接下来,我们检查文件的大小,显示的是文件大小为 3316 字节,这是正确的。
然后,程序通过 fseek 将文件指针移到文件的开头,接着通过 malloc 分配了相应大小的内存空间,并用 fread 将文件内容读取到内存中。此时,读取到的内容就是文件的原始数据。可以看到文件的内容已经成功加载,但在文件的末尾,由于没有进行 null 终止,后面的内容显得是垃圾数据。这是因为我们还没有执行 null 终止的操作,但这一部分很简单,后续会进行处理。
总结来说,文件的读取部分已经完成,接下来需要解决 null 终止问题。
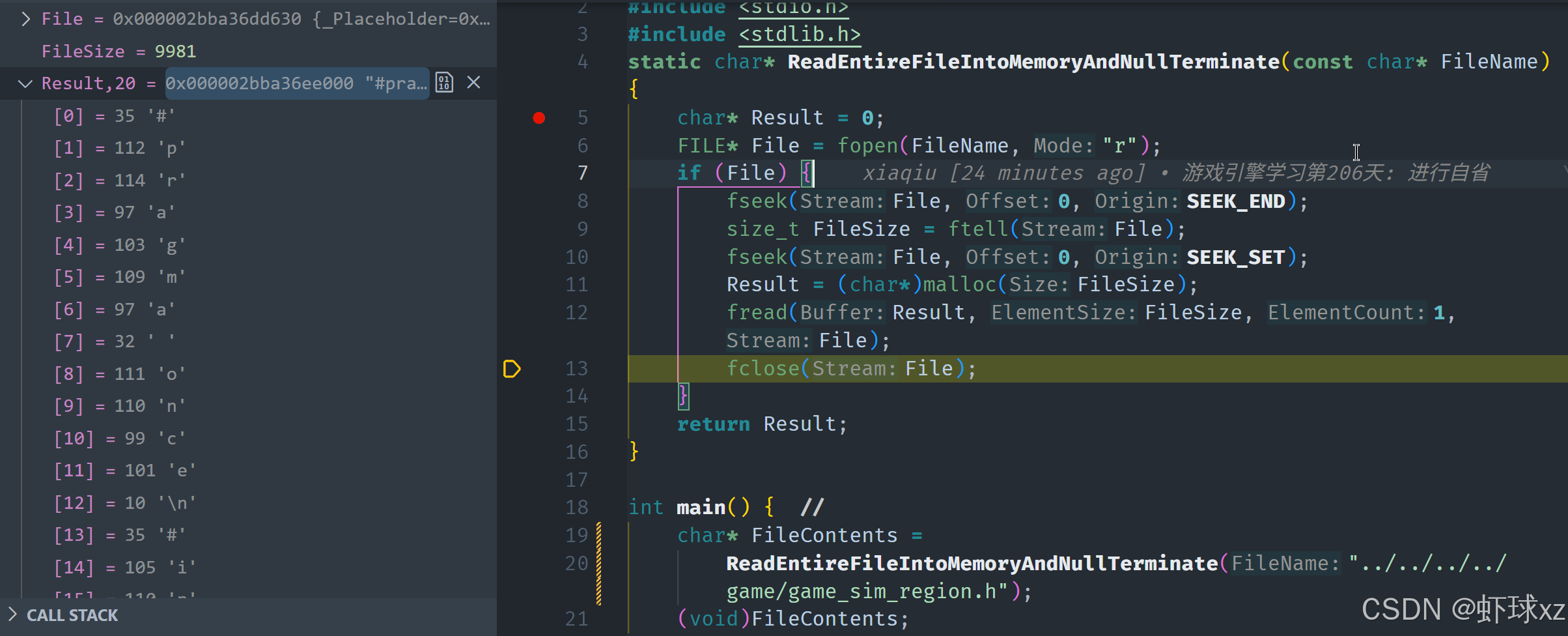
simple_preprocessor.cpp: 将文件设置为空终止
接下来,我们要做的是确保文件被正确地 null 终止。为此,我们需要为 null 终止符分配一个额外的字节空间。然后,在读取文件之后,我们在文件的末尾添加 null 终止符,这样就确保文件的内容以 null 结束。
一旦文件正确地 null 终止,我们就可以开始解析文件了。我们需要遍历文件的内容,并提取我们所需要的信息。但是在这个过程中,会遇到一些问题,我们需要进一步处理这些问题。
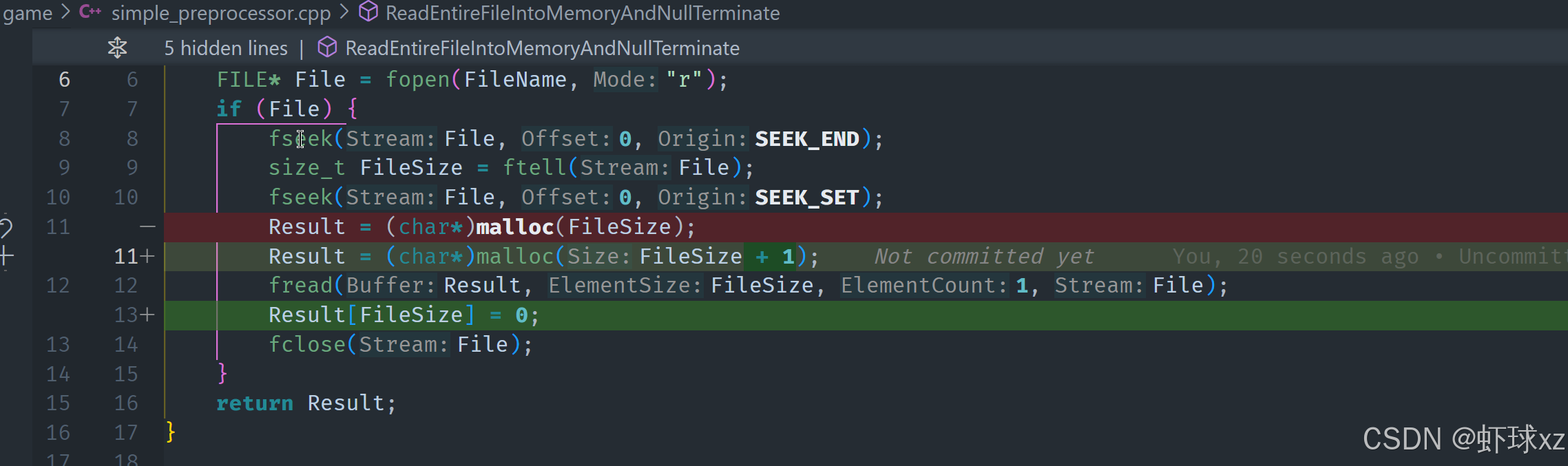
game.h: #define introspect
问题在于文件内容可能非常复杂,可能包含很多信息,而并不是所有的信息都需要被解析。比如说,可能不希望解析诸如"move_spec"或"entity_type"或"hit_point"等字段。因此,需要一种方式来标注哪些内容应该被解析,哪些不需要。
为了解决这个问题,可以在代码中引入一些标注方法。在代码的顶部,定义一些宏,以便在编译时可以控制哪些内容应该被注释掉或跳过。这些宏在编译时不会展开或产生任何实际的代码,它们只起到标记和注释的作用,帮助我们在处理不同的字段时决定是否需要解析它们。

game_sim_region.h: 使用 introspect 宏
可以通过定义宏来标注结构体或字段,表示该结构体需要进行" introspection"(自省)。例如,可以在结构体定义前使用宏来标注它,比如" introspected struct"或者简单地使用" introspect"宏。这些宏在编译时不会产生实际代码,它们仅作为标记,告诉程序哪些结构体或字段需要进行特殊处理或解析。
黄油炸
提到了"introspection"(自省)这一类别,它被称为"brown butter"(棕色黄油)。之所以叫棕色黄油,是因为它比普通的黄油更有味道。当然,普通黄油也是很美味的,尤其是当黄油和面包(如法棍)都很好的时候,这样的搭配非常合适。作者表示,虽然自己是美国人,但从未称呼薯条为"自由薯条"(freedom fries),并提到自己能理解为什么法国人对这种搭配情有独钟。
总结来说,主要是在讨论自省类别的命名问题,同时通过对比黄油的美味,暗示自己对一些传统或文化习惯的理解和接受。
描述标记
首先提到了一些关于编译和预处理器的内容。编译的过程中,代码不会产生实际问题,允许我们注入仅供预处理器使用的代码,这一点非常重要。接着,提到现在已经加载了文件内容,下一步将进行文件的解析。
文件解析过程分为两个阶段,第一个阶段叫做词法分析(lexing)。词法分析的目的是将文件中的字符流分解成有意义的片段,即"词法单元"(tokens)。这些词法单元可以是标识符、括号、冒号、字符串等。在进行词法分析时,整个文件就不再是一个字符的集合,而是被看作由各种词法单元组成的,这样会更容易进行进一步的解析。
接下来,目标是构建一个可以从文件中提取词法单元的机制,来帮助进行解析。
simple_preprocessor.cpp: 引入标记结构
接下来,我们要定义一个"token"结构体,这个结构体需要包含一些关键信息来帮助我们进行词法分析。首先,我们需要知道每个token的内容,比如它是什么类型的token、它的位置在哪里以及它的长度。具体来说,结构体中可能包含以下字段:
- 文本内容:存储token的实际内容。
- 长度:存储token的长度。
- 位置:标识token在源代码中的位置。
- token类型:指明token属于什么类型,如标识符、括号、冒号、字符串等。
在这里,token类型可以包括多种情况,例如:
- 标识符(identifier)
- 开括号(open parenthesis)
- 冒号(colon)
- 字符串(string)
- 闭括号(close parenthesis)
- 分号(semicolon)
- 星号(asterisk)
- 开方括号(open bracket)
- 开花括号(open brace)
此外,还需要定义一个特殊的token类型,如"end of file"(EOF),表示文件结束。最终,目标是编写能够识别和提取这些token的代码,返回的token将包含上述信息,并可以按类型区分。这种结构将有助于后续的解析工作。
simple_preprocessor.cpp: 遍历标记并打印它们
接下来,准备开始构建一个解析过程来逐个获取token,直到无法再获取token为止。我们计划使用一个 for 循环来实现这个目标。在每次循环中,检查当前token的类型,并根据类型做相应的处理。首先,使用一个 switch 语句来判断token的类型。
不过一开始可以简化代码,不用急着实现完整的 switch 语句。可以先通过一个简单的布尔变量 parsing 来标记是否正在解析,直到遇到文件结束标志时停止解析。具体来说,首先设置 parsing = true,然后在解析结束时将 parsing 设置为 false,并通过 break 跳出循环。
在解析的过程中,如果没有遇到文件结束符,就可以继续处理当前token。每次遇到一个新的token时,可以输出该token的类型及其内容。为了输出字符串内容,涉及到一个C语言printf格式化输出的问题,因为token包含了一个字符串指针和一个长度,而printf默认会读取字符串直到遇到空字符(null terminator)。为了防止printf输出错误的内容,应该指定字符串的长度,而不是让printf自行判断。使用"宽度指定符"来精确控制输出的字符长度,例如 %.*s 这样的格式,可以确保输出不会越界。
接下来,需要实现一个 GetToken 函数来获取下一个token,填充相关的信息,并继续解析。这样一来,整个token的解析过程就变得可控,并能准确处理每个token。
printf 中的 precision (精度)是用来控制输出格式的,特别是对于字符串和浮点数来说。在打印字符串时,precision 用于限制输出的最大字符数,确保不会输出超过指定长度的字符串。
1. 对于字符串:
当你使用 printf 打印字符串时,可以指定一个精度值,这个精度值表示最多输出多少个字符。如果字符串长度超过这个精度值,那么只会输出精度所指定的字符数量,并且不会输出超过的部分。
示例:
c
char *str = "Hello, world!";
printf("%.5s\n", str); // 输出:Hello在这个例子中,%.5s 表示输出最多 5 个字符,因此 "Hello, world!" 中的字符串只会输出 "Hello",其后的字符会被截断。
2. 对于浮点数:
对于浮点数,precision 控制的是小数点后的位数。例如,%.2f 表示保留 2 位小数。
示例:
c
float num = 3.14159;
printf("%.2f\n", num); // 输出:3.14这里,%.2f 会将 num 截断到小数点后两位。
3. 使用 * 精度:
* 还可以用作精度的参数。精度的值可以通过传递一个整数参数来指定。
示例:
c
int precision = 4;
printf("%.*s\n", precision, str); // 输出:Hell在这个例子中,%.*s 表示从 str 字符串中输出最多 precision 个字符。
总结来说,printf 的精度控制功能非常有用,可以用来限制输出的字符长度或数字的小数位数,使输出格式更加精确和符合需求。
simple_preprocessor.cpp: 引入 struct tokenizer
要创建一个 tokenizer 类的对象来存储当前解析状态,并在解析过程中保持跟踪,通常会将其设计成一个结构体或类。这个 tokenizer 的主要作用是通过指向文件内容的指针来初始化,并根据这个指针来获取下一个 token(标记)。这个 token 是从文件内容中按顺序提取出来的。
主要步骤:
-
定义 Tokenizer 结构体:
tokenizer结构体主要用于存储当前的状态,比如指向文件内容的指针(pointer)。它将作为一个简单的容器,方便在解析过程中保持状态和操作。 -
初始化 Tokenizer:
初始化时,将文件内容传递给
tokenizer,使其指向文件的开头。之后,可以通过这个结构体的接口来逐步获取下一个 token。 -
获取 Token:
获取 token 的功能会通过调用
GetToken来实现,这个方法会从tokenizer中提取一个 token,并根据需要进行处理。这个过程会涉及到词法分析(lexing),将文件内容从原始字符流分割为具有意义的标记(tokens)。 -
处理空白字符:
在大多数编程语言的解析器中,空白字符(如空格、换行符等)通常不会影响程序的逻辑,因此可以忽略。在词法分析的过程中,
tokenizer会跳过这些空白字符,以便找到实际有意义的标记(如关键字、标识符、运算符等)。
逻辑概述:
- 跳过空白字符: 在
tokenizer获取 token 时,首先会检查并跳过所有不重要的空白字符。 - 标记提取: 一旦跳过空白字符,
tokenizer就会开始提取有效的 token(如数字、标识符、运算符等)。 - 返回 Token: 每次调用
GetToken时,tokenizer都会返回一个新的 token,直到遇到文件结束或者无法提取更多有效 token。
这种结构帮助在文件内容的处理过程中保持清晰的状态管理,同时也使得后续的 token 解析更为高效。
simple_preprocessor.cpp: 引入 EatAllWhitespace
在设计 tokenizer 时,我们首先需要处理空白字符。空白字符通常不影响语法解析,因此可以在解析之前跳过它们。具体步骤如下:
1. 跳过空白字符:
在解析之前,需要确保 tokenizer 能够跳过所有空白字符。空白字符包括空格、制表符(tab)和换行符。为了实现这一点,定义一个简单的函数来判断字符是否为空白字符。
例如:
c
bool IsWhitespace(char c) {
return c == ' ' || c == '\t' || c == '\n';
}上面的 IsWhitespace 函数将检查给定的字符是否为空白字符。
2. 在 Tokenizer 中处理空白字符:
在 tokenizer 的主循环中,首先检查当前字符是否为空白字符。如果是空白字符,就跳过它,直到遇到一个非空白字符。这样就能确保在获取有效的 token 时,空白字符不会干扰。
具体实现:
c
while (IsWhitespace(tokenizer->At[0])) {
++Tokenizer->At;; // 跳过当前的空白字符
}在这里,++Tokenizer->At; 函数将移动指针,直到遇到下一个非空白字符。
3. 获取下一个有效字符:
在跳过所有空白字符后,tokenizer 将开始检查当前字符,并根据该字符类型决定接下来要做什么。这通常会涉及到不同类型的 token,如标识符、数字、运算符等。
4. 标识符解析:
假设我们现在遇到的是一个标识符(例如变量名),我们将会处理这个标识符,直到遇到非字母或数字的字符为止。这时,tokenizer 会识别并将其标记为一个有效的标识符 token。
5. 跳到下一个 token:
每次解析完一个 token 后,tokenizer 会继续向前移动,直到遇到下一个标记,或者文件结束。整个过程会在每次调用 GetToken 时进行,直到文件解析完毕。
这种方法非常高效,因为它通过跳过空白字符简化了对文件内容的处理,确保只关注实际的、有意义的部分。
稍微脑袋混乱
我们需要一种方式来判断某个字符是否是特定的标记,比如括号、分号、星号、冒号等。如果是这些简单的单字符 token,就可以直接识别出来并立刻返回对应的 token 类型。这一部分相对简单。
首先处理的是这些"简单字符"的情况,比如:
(代表 open paren(左括号))代表 close paren(右括号);代表分号*星号[左中括号]右中括号{左大括号}右大括号:冒号
这些字符我们可以直接通过一个 if-else 或 switch 结构判断,并把对应的 Token.Type 设定为特定值。然后将当前位置作为 token 的开始,长度设为 1,即表示这是一个单字符的 token。这样,处理这些符号的代码就非常直观、快速。
为了代码清晰,把这些"简单字符"单独放一块作为基础 token,然后再处理相对复杂的部分,比如字符串(string)和标识符(identifier)。
接下来是字符串的解析:
- 当遇到引号
"时,说明可能是字符串的开始。 - 首先跳过第一个引号(不包括在 token 内容里),把当前位置设为字符串起始点。
- 然后不断往后遍历字符,直到遇到下一个引号
"为止,这样就能把字符串整体抓出来。 - 需要注意,如果遇到
\(反斜杠),可能是转义字符。比如字符串中可能会出现\",表示这是一个内部的引号而不是字符串结束符。 - 所以当发现当前字符是
\并且后面还有一个字符时,就跳过这两个字符(表示这是一个被转义的字符对),而不是只跳一个。 - 如果遍历过程中遇到了字符串结尾但还没找到
",就认为是非法字符串,但也可以安全终止。
最后还有一种情况是遇到非法字符或未知 token,比如既不是上述简单字符、也不是字符串起始符号的情况,就默认这是一个标识符(identifier)。这些标识符的解析稍微复杂一点,会在后续继续实现。
目前为止,已经完成以下部分:
- 处理所有明确的单字符 token
- 正确识别字符串,包括转义处理
- 为后续识别标识符留好了位置
通过这种方式,tokenizer 的结构既清晰又模块化,基础符号部分易于维护,复杂的 token(如标识符、字符串)也能被分别处理。这样构建出的词法分析器具备良好的可扩展性。
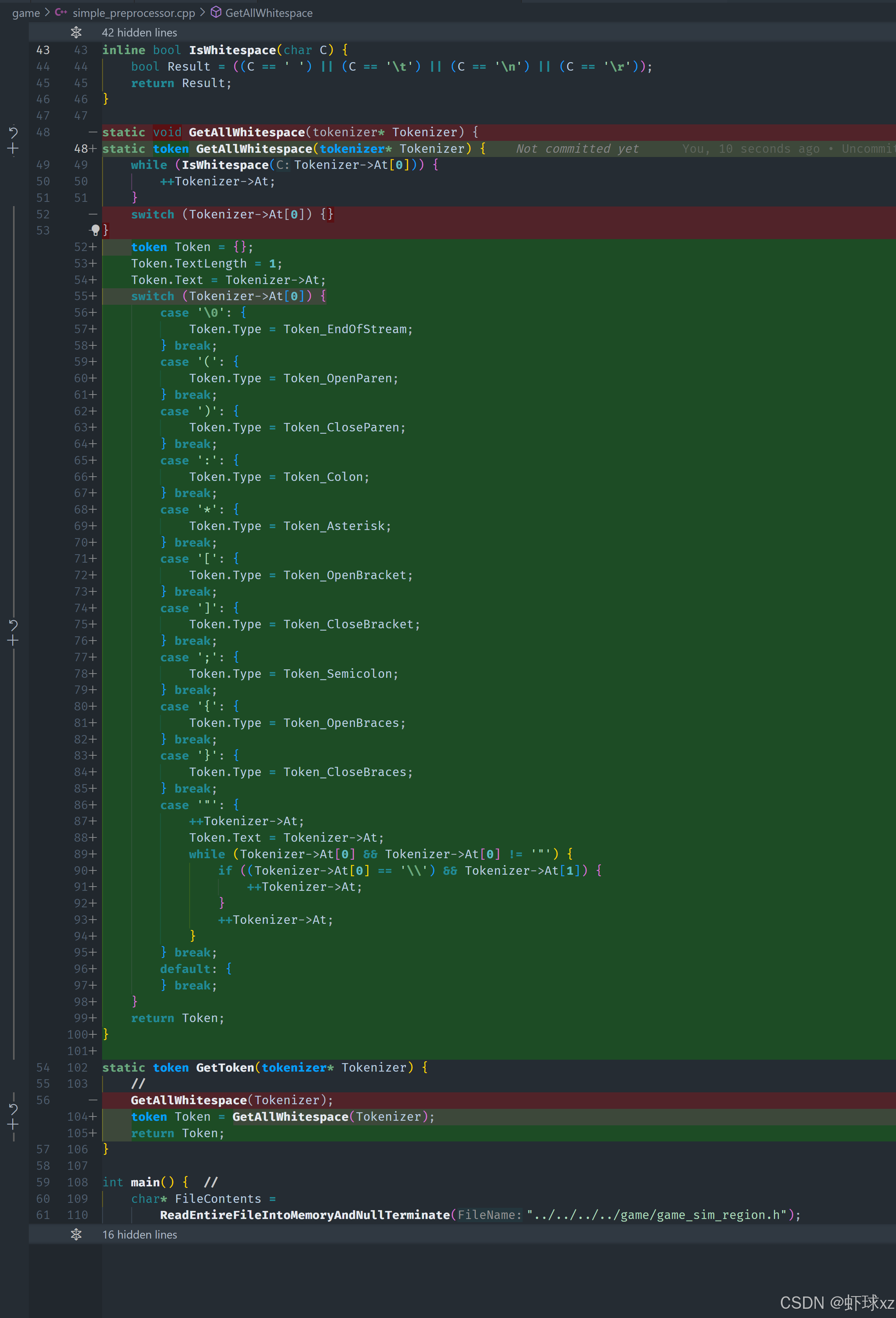
simple_preprocessor.cpp: 提供解析标识符的方法
我们现在还需要实现对标识符(identifier)的解析方式。对于词法分析器来说,标识符是除基本符号和字符串之外最常见的一类 token,通常包括变量名、函数名等。
在默认情况中,如果当前字符不是我们已经识别的那些符号,也不是字符串的起始符号,那么我们需要进一步判断它是否属于以下几类:
1. 字母开头:识别标识符
如果当前字符是一个英文字母(判断其是否是"字母字符",即 IsAlpha (is alphabetical)),那么我们就认为这是一个标识符的起始。
- 以字母开头的内容很有可能是变量名或函数名。
- 接下来应该持续往后看,只要后续字符还是字母、数字或下划线,就继续把它们包含在当前 token 中。
- 当遇到不是这些字符的东西时,标识符结束。
- 最后将识别出来的内容作为 identifier 类型的 token 返回。
2. 数字开头:识别数字
如果当前字符是数字(判断是否是"数字字符",即 is numeric),那么我们可能是在处理一个数字常量。
- 数字常量可能是整数,也可能是浮点数,甚至十六进制等。
- 当前阶段可以先简单处理,比如只支持十进制整数,等后续再逐步扩展处理逻辑。
- 同样是从当前位置往后扫描,只要字符还是数字就继续。
- 直到遇到非数字字符为止,说明数字结束。
3. 斜杠 /:处理注释
如果当前字符是斜杠 /,那我们还不能立即判断它是否是除号,有可能它是一个注释的开始。
注释在 C 风格语言中分为两种:
- 单行注释
// - 多行注释
/* ... */
所以我们要:
- 检查下一个字符:
- 如果是
/,说明是//单行注释,就要跳过直到遇到换行为止。 - 如果是
*,说明是/* */多行注释,就要跳过直到遇到*/为止。
- 如果是
- 这些内容不是代码,只是注释,不能作为 token 输出,所以我们要跳过它们,回到正常扫描流程。
- 这种跳过逻辑和之前的"跳过空白字符"逻辑是类似的,属于"跳过无意义内容"的部分,可以整合在一起处理。
总结一下:
我们为剩余字符提供了以下几种判断分支:
- 如果是字母 → 是标识符的起点 → 解析为 identifier。
- 如果是数字 → 是数字常量的起点 → 解析为 number。
- 如果是
/→ 可能是注释 → 判断并跳过相应部分。 - 否则,暂时不处理(可能是错误字符或后续功能补充)。
这样一来,我们的词法分析器就能够初步处理绝大部分 C 风格代码中会遇到的 token 类型:基本符号、字符串、标识符、数字、注释、空格等,具备了构建 parser 的坚实基础。
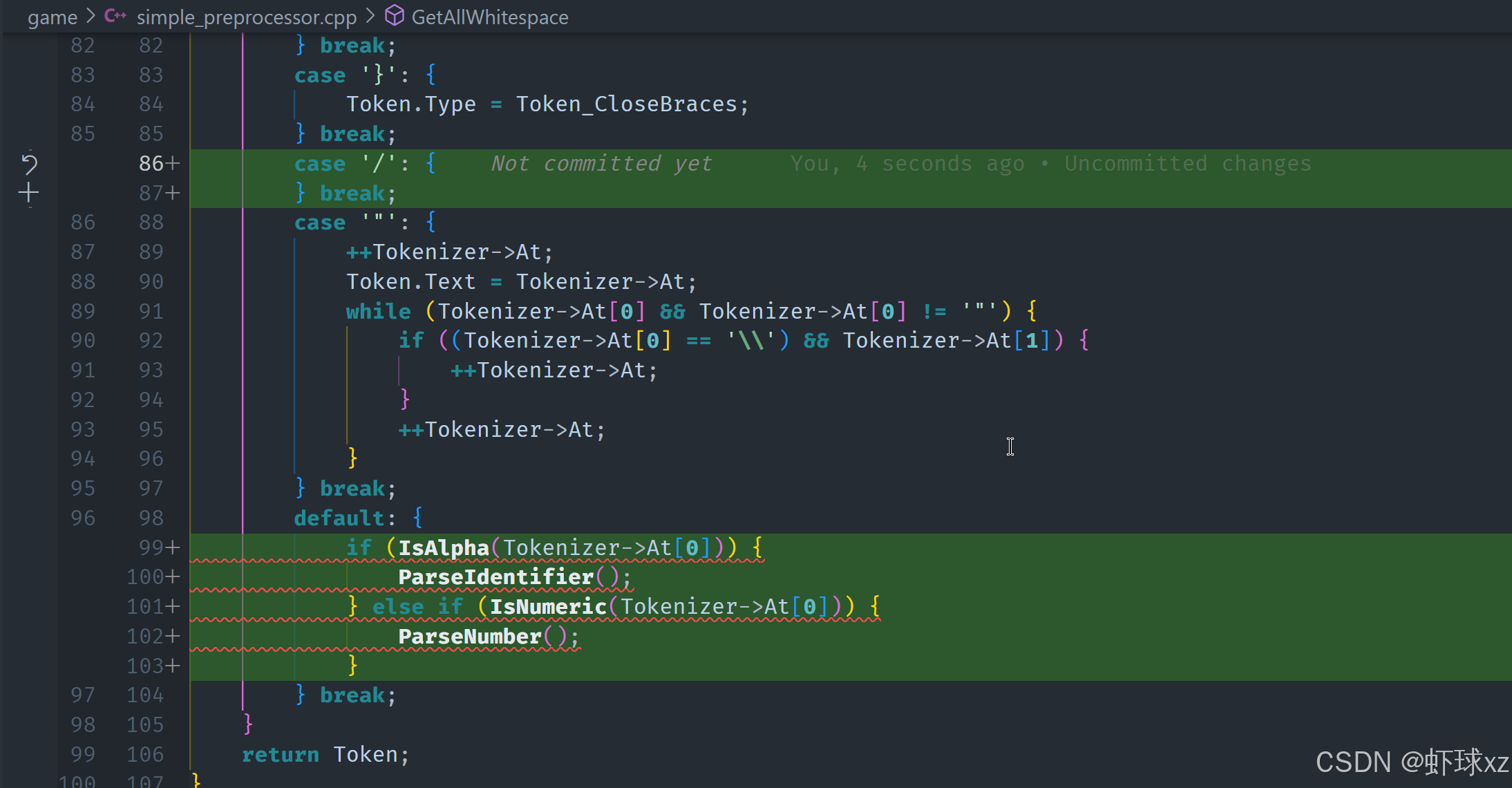
simple_preprocessor.cpp: 将 GetToken 的功能移到正确的位置,并编写 EatAllWhitespace
我们在处理空白字符的逻辑中,还应该加入对注释的处理,因为注释在编程语言中通常也被视作"空白"------它们对程序逻辑没有影响,因此在词法分析阶段需要忽略掉。为了更完整地跳过这些"无用字符",我们更新了空白字符处理逻辑,让它同时吃掉空格和注释两种内容。
🌟更新后的处理流程如下:
我们进入一个循环,反复检查当前位置的字符,看是否还需要跳过:
1. 如果当前字符是空白字符:
包括空格、制表符(Tab)、换行符等,我们就调用 advance() 函数跳过这个字符。
2. 如果当前字符是斜杠 /:
有可能是注释的开始,因此需要进一步判断:
-
//开头:C++ 风格单行注释- 识别两个字符是
//。 - 然后不断跳过,直到遇到换行符
\n或文件结束符(null terminator)。 - 这样就跳过了整行注释。
- 识别两个字符是
-
/*开头:C 风格多行注释- 识别两个字符是
/*。 - 然后循环跳过字符,一直到遇到
*/或文件结束符。 - 注意要处理不规范的写法,比如注释没有闭合等。
- 识别两个字符是
3. 否则:
如果当前字符不是空白,也不是注释开始符号,那就说明不需要再继续跳过了,退出这个循环。
🛠 为什么这样做?
- 注释本质上就是"没有语义意义的字符",词法分析阶段的目标就是提取有意义的 token,所以它们必须被跳过。
- 将注释的跳过逻辑整合进 whitespace eater(空白字符清理器)非常合理,因为它们本质相同。
- 保证后续在解析 identifier、number、string 等 token 时,不会误读注释内容或被干扰。
最终效果:
我们完成了一个结构良好、功能完善的"无效内容清除器",能自动吃掉:
- 所有空白字符(空格、Tab、换行等)
- 所有单行注释(
//开头) - 所有多行注释(
/*...*/)
一旦这些东西都被清除干净,我们的词法分析器就能专注于处理真正有意义的代码元素,为下一步 token 分析做好准备。
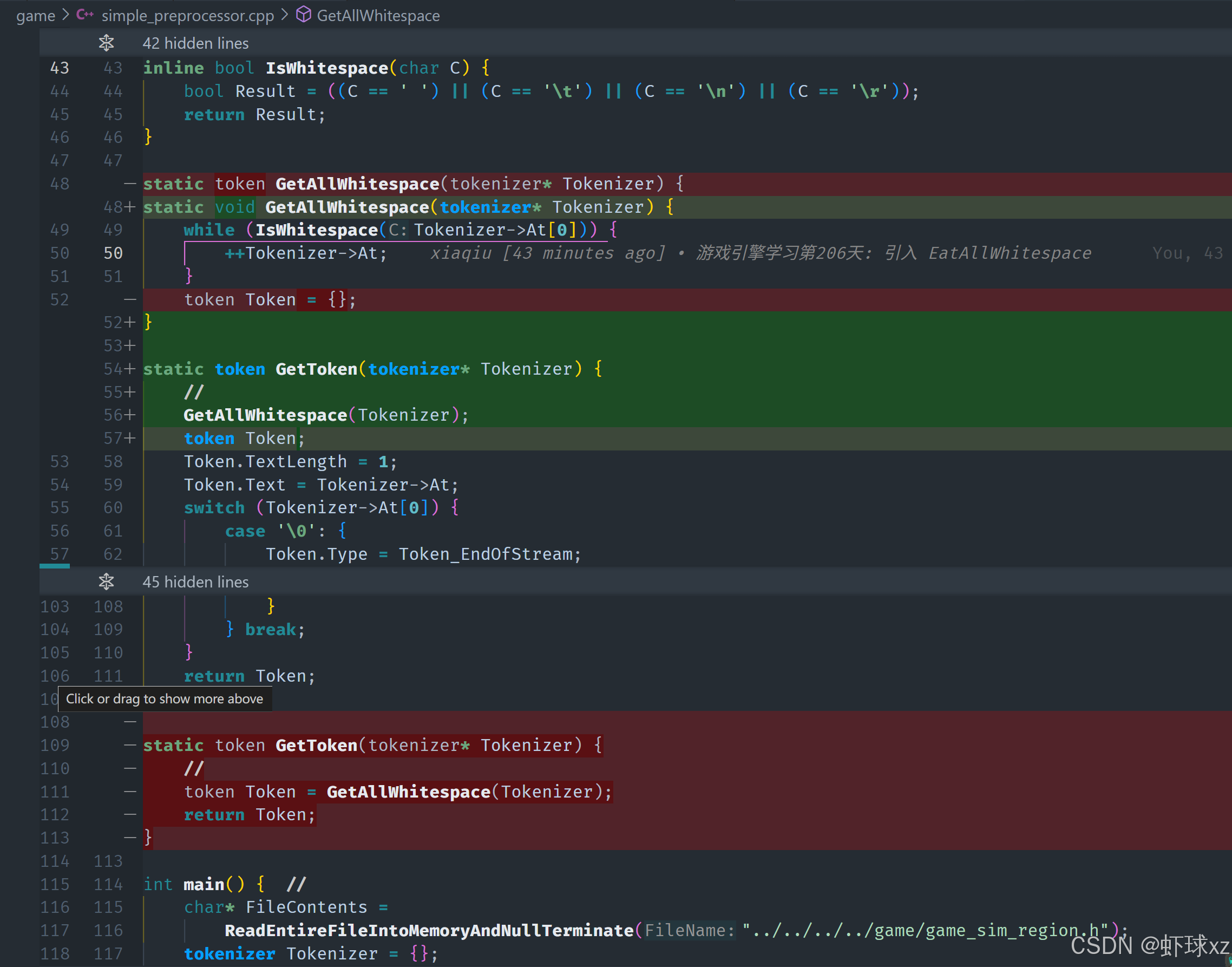
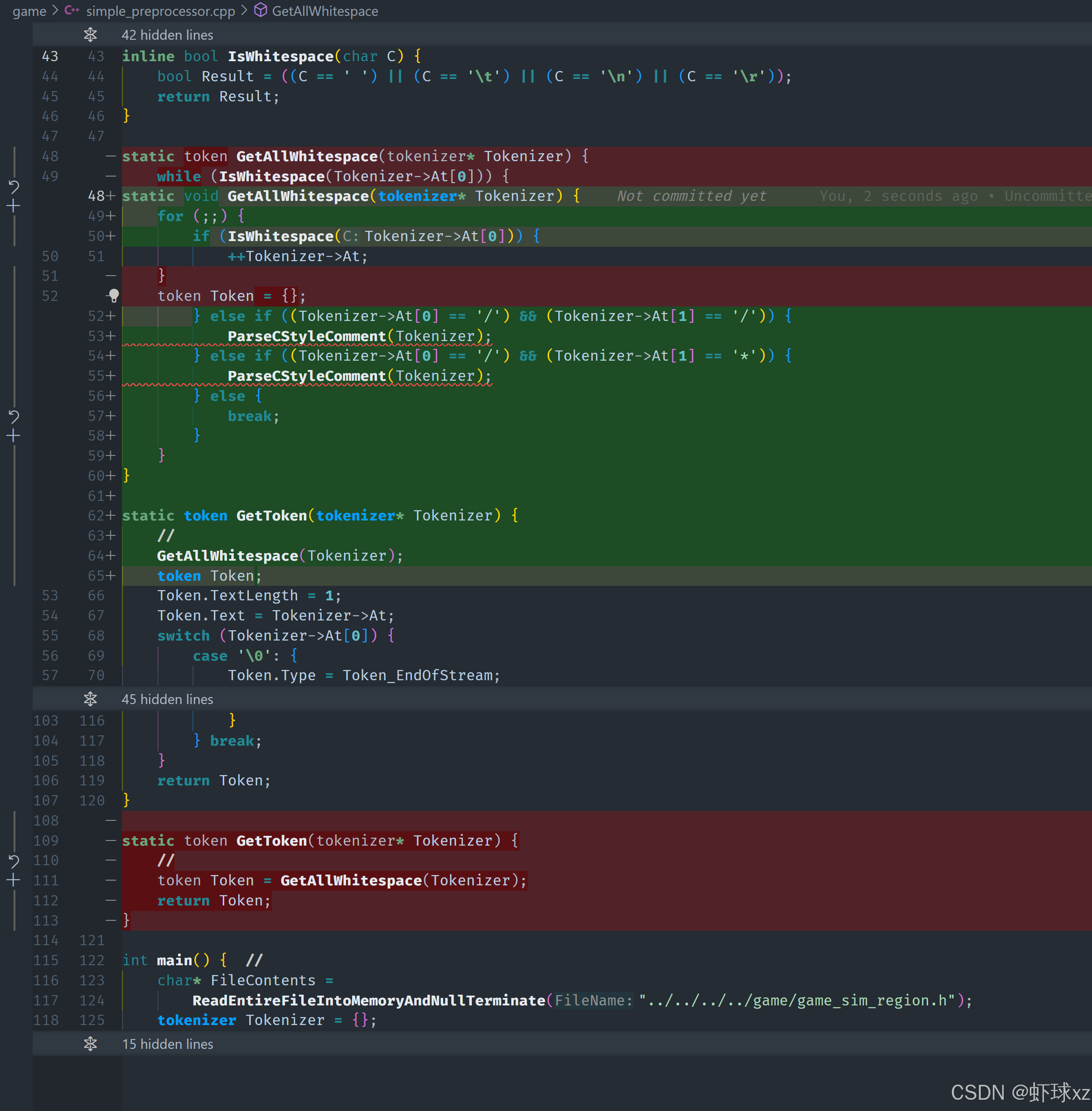
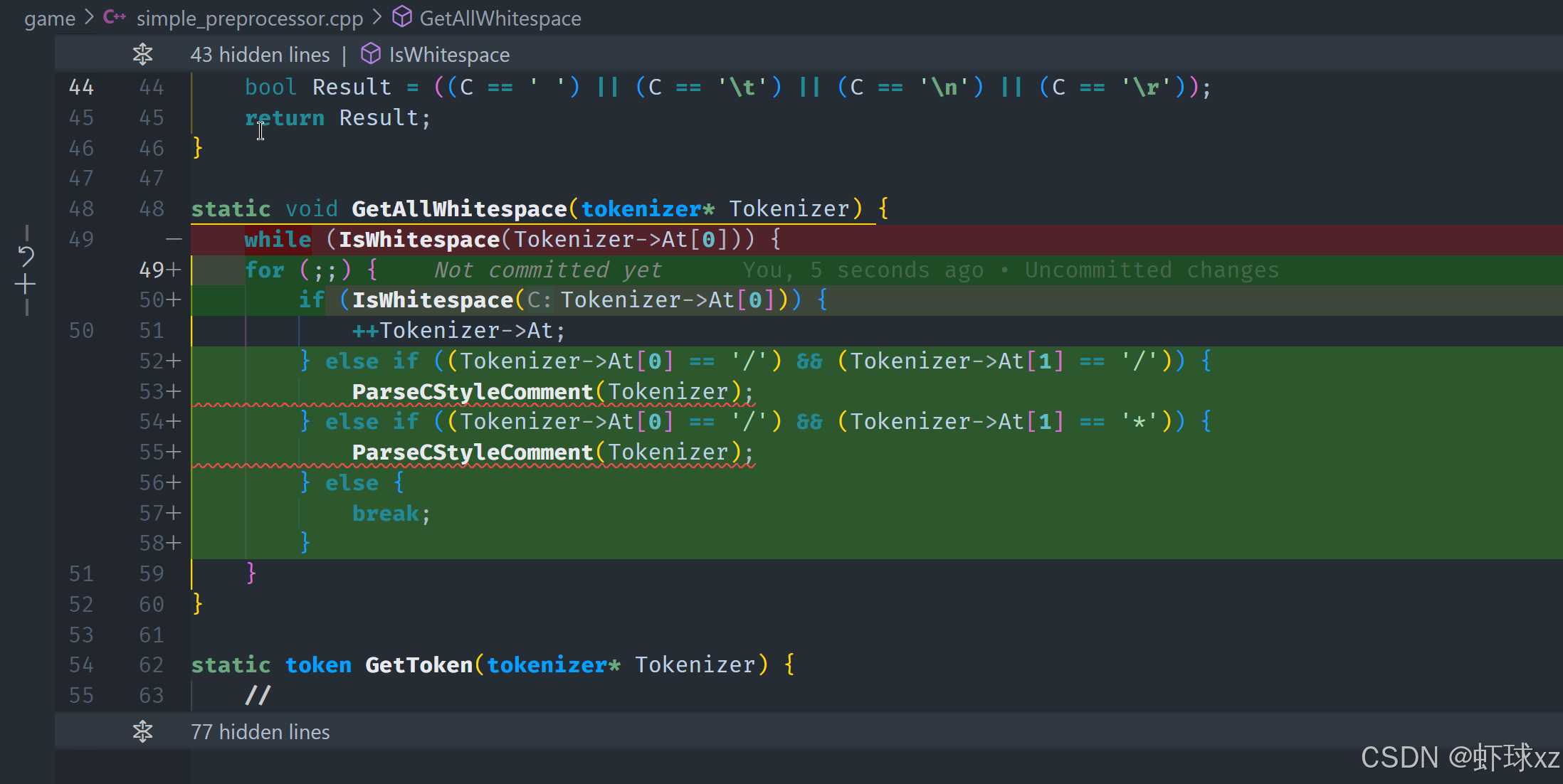
simple_preprocessor.cpp: 提供解析 C 风格注释的功能,并引入 IsEndOfLine
我们现在要实现的是对注释的解析处理。主要目标是:
跳过所有注释内容,不让它们出现在词法分析阶段的有效 token 中。
我们处理的是两种注释风格:C++ 的单行注释 // 和 C 的多行注释 /* ... */,它们都应该在词法分析阶段被识别并被跳过,作为"无效内容"处理掉。
单行注释解析(//)
我们首先处理的是 // 这种单行注释,处理逻辑如下:
- 跳过最开始的
//两个字符。 - 然后开始一个循环,只要当前字符不是换行符也不是文件结束符(null terminator),就一直往前推进。
- 当遇到换行或结尾,就表示这个注释结束,退出循环。
可以抽象成一个辅助函数 IsEndOfLine(),判断当前字符是否为换行符或其他行尾表示方式。
多行注释解析(/* ... */)
对于 /* 开始的多行注释,处理逻辑更复杂一点:
- 跳过开头的
/*。 - 然后进入一个循环,不断地往前推进字符,直到我们看到注释的结束标志
*/。 - 这个检测使用双字符判断:当前字符是否是
*,并且下一个字符是否是/。 - 同时也要考虑提前遇到 null terminator 的情况,说明代码不完整,需要提前退出。
退出循环后,还要跳过最终的 */(即再前进两次)来完全吃掉整个注释。
为什么选择 inline 实现?
我们发现这两个解析函数逻辑其实非常直接,判断条件清晰,执行过程简单,没有复杂状态或嵌套。与其单独封装成函数,不如直接写在主逻辑中,更直观、少跳转,便于维护。
最终效果:
现在,我们的空白跳过逻辑已经增强成一个更强大的"预处理器"模块,它能跳过:
- 所有空白字符(空格、换行、Tab 等)
- 所有
//单行注释 - 所有
/* ... */多行注释
并且逻辑紧凑清晰,保持了和 C 语言一致的行为语义,为后续解析标识符、数字、字符串等 token 清除了所有干扰因素。
下一步准备:
现在我们准备处理更复杂的 token,比如字符串、标识符、数字等,需要更多状态处理、字符识别和数据截取逻辑。我们已经为它们清理好了"路径",接下来只需要专注提取"有意义"的内容即可。
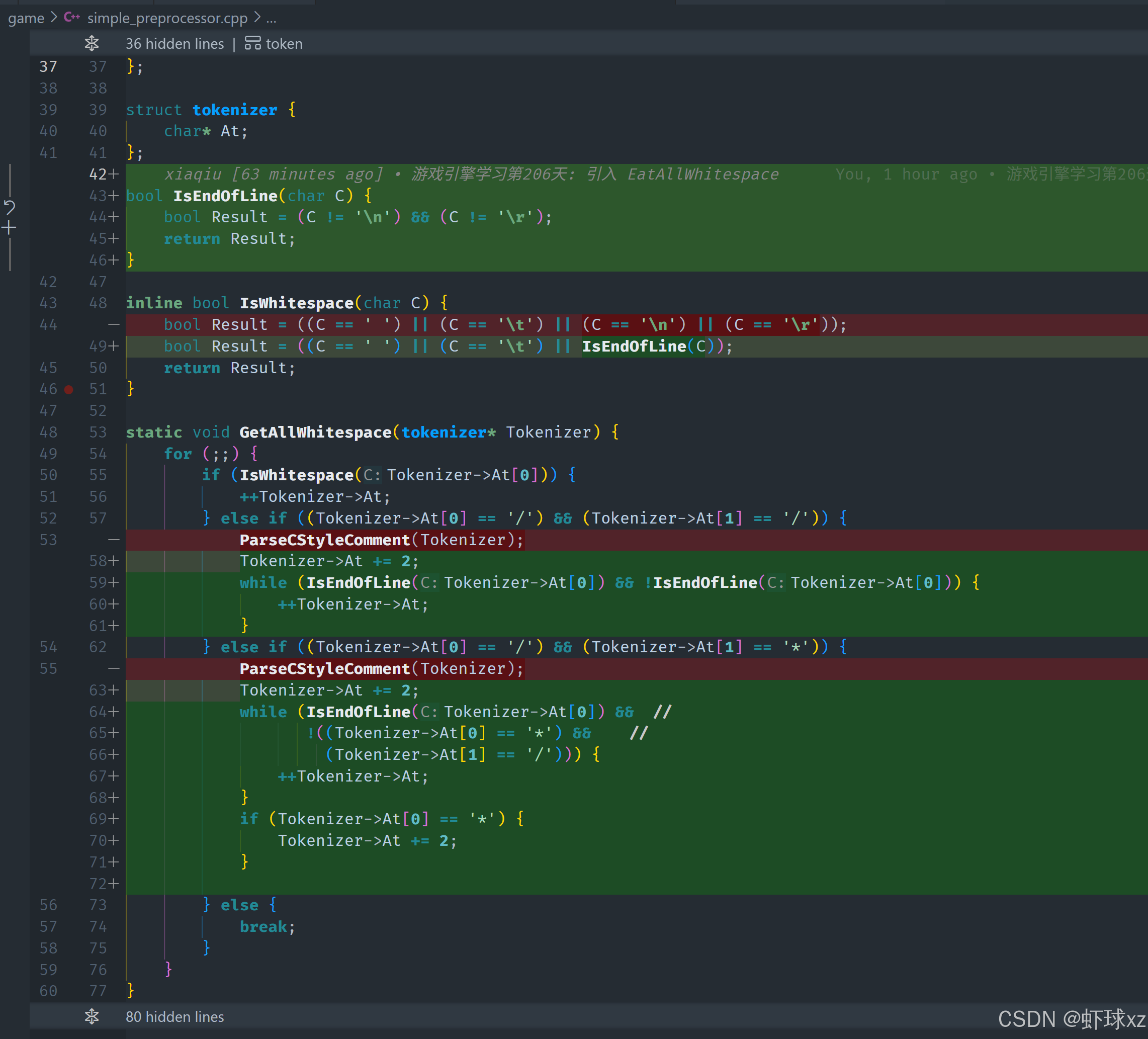
simple_preprocessor.cpp: 引入 IsAlpha 和 IsNumeric
我们当前的目标是实现标识符和数字的识别判断函数 ,这一步是在构建一个词法分析器中非常关键的一部分,用于判断字符是否为合法的标识符起始字符 或数字的一部分。我们将实现两个基础的判断函数:
判断是否是字母字符(IsAlpha)
我们需要一个函数,判断某个字符是否是英文字母。这是因为合法的标识符(identifier)通常是以字母开头的。
实现逻辑非常简单,直接使用 ASCII 编码范围判断:
- 小写字母:在
'a'到'z'范围之间 - 大写字母:在
'A'到'Z'范围之间
所以只需要检查这个字符是否满足以下任一条件即可:
c
(c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z')这样我们就能快速判断某个字符是否是字母。
判断是否是数字字符(IsNumeric)
同样地,我们还需要判断某个字符是否是数字字符,即 '0' 到 '9' 之间的字符。
判断逻辑同样简单,基于 ASCII 数值判断:
c
(c >= '0' && c <= '9')这个函数后续会用于判断一个 token 是否可能是数字的组成部分。
当前我们只处理最基础的数字判断(十进制整数),但将来可能还需要处理更复杂的数字格式,比如:
- 小数点(
.),比如3.14 - 十六进制前缀(
0x) - 浮点数标识(
f) - 科学计数法(
e,E)
因此我们在注释里加了一个TODO 标签,说明未来会扩展 IsNumeric 的逻辑,来支持这些更复杂的情况。
当前策略
在当前的阶段,我们先实现最基本的 IsAlpha 和 IsNumeric 函数逻辑,以便后续可以:
- 如果一个字符是字母,我们就进入标识符解析流程;
- 如果一个字符是数字,我们就进入数字解析流程;
- 否则,它可能是其他字符或非法输入;
这样整个词法分析流程就能根据起始字符快速决定走向哪种分支。
总结
IsAlpha用于判断字符是否为字母(合法标识符起始);IsNumeric用于判断字符是否为数字(数字 token 起始);- 当前实现为最小版本,后续会扩展;
- 这两者的存在让我们能构建一个灵活、清晰的词法决策结构,为复杂 token 提供良好的起点判断;
我们为标识符和数字的识别准备好了基础工具,下一步可以继续实现这两种 token 的具体提取逻辑。
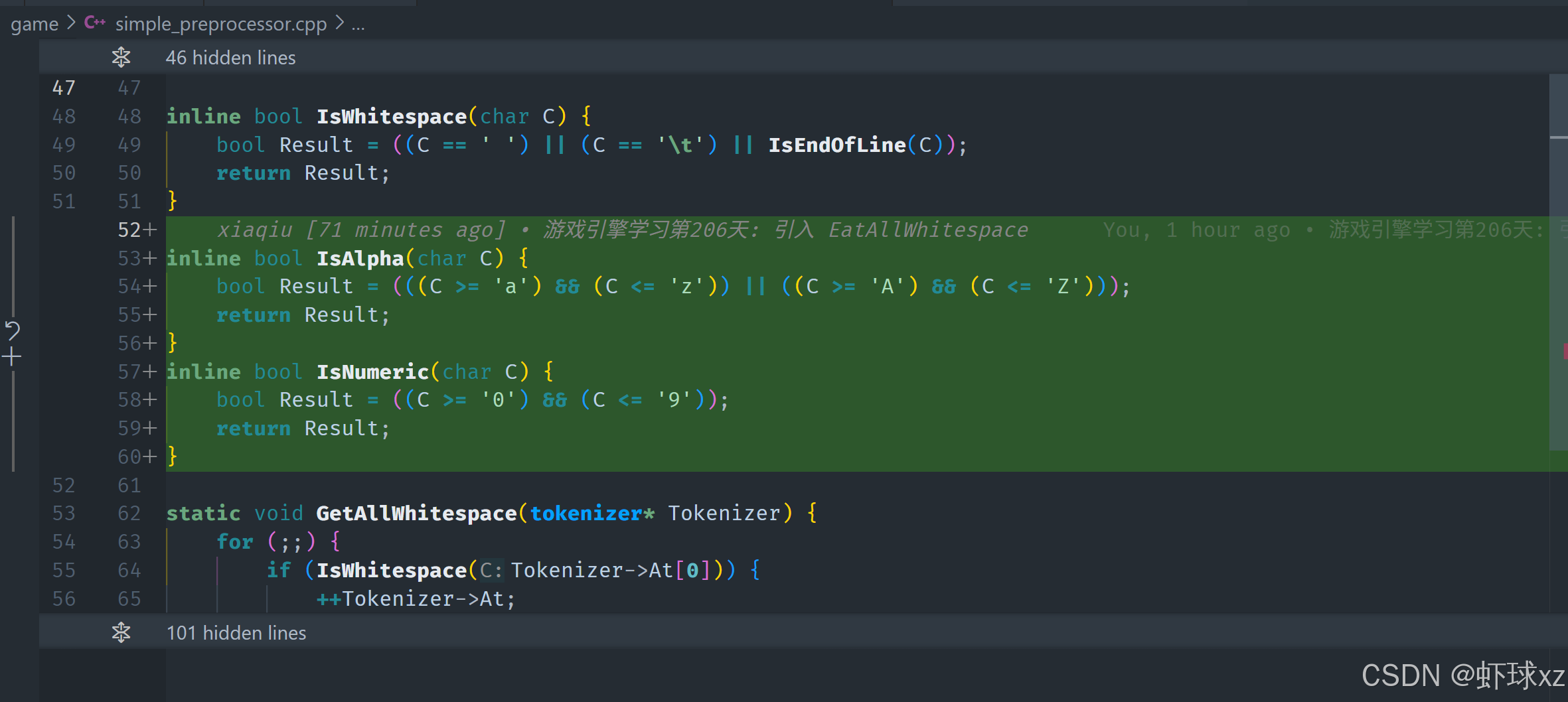
simple_preprocessor.cpp: 处理未知标记
在当前的阶段,我们已经完成了是否为字母字符(IsAlpha)或数字字符(IsNumeric)的判断逻辑。这使我们能够根据当前字符来决定是否去解析标识符或数字。但目前数字部分我们还不关心,因此接下来我们主要采取的策略是:
暂时跳过数字解析
虽然我们已经写好了判断是否为数字字符的逻辑,但我们暂时不打算实现数字的解析逻辑(parse number),因为当前的任务暂时不涉及数字的实际用途。
所以在遇到数字字符的时候,我们不会立刻进入数字解析流程,而是先跳过或者忽略,以后需要时再具体实现。
对无法识别的 Token 做兜底处理
在遇到既不是特殊符号(如括号、分号、引号等),也不是字符串、标识符、空白、注释的情况时,说明这个字符无法被我们当前的词法分析器识别。这种情况就会落入我们处理逻辑中的 default 分支。
对于这些默认的、未识别的字符,我们做如下处理:
-
将 token 的类型设置为 unknown(未知)
这样我们在内部逻辑中就能识别出它是无效或者不支持的内容。
ctoken.type = Token_Unknown; -
在后续逻辑中过滤掉 unknown token
也就是说,如果一个 token 是 unknown 类型,我们就不会去打印它,也不会进一步处理它。
这样可以防止控制台或者输出中充满了无意义的符号或乱码。
举个例子:
cif (token.type != Token_Unknown) { }
当前阶段的策略
综上,我们当前的策略可以总结为:
- 数字部分先不处理,只判断但不解析;
- 对未知字符设置为
unknown类型; - 在输出和后续处理时忽略这些 unknown token;
- 先专注处理我们目前关心的 token 类型(如括号、标识符、字符串等);
- 通过这种方式,逐步推进整个词法分析器的构建,不急于一次性完成所有类型的支持;
设计思路上的优势
- 渐进式构建:优先实现最常见、最基础的 token 类型,复杂的类型可以延后;
- 稳健的默认处理 :通过
unknown类型避免词法分析器崩溃或出错; - 输出干净可控:只输出我们理解并能处理的 token,方便调试与测试;
- 易于扩展:将来只需添加对应类型的解析函数即可支持更多 token;
接下来可以继续完善标识符的提取逻辑(比如扫描一整个由字母、数字、下划线组成的单词),并在后续逐步添加数字、关键字识别等功能。整个词法分析器正在一点一点地变得可用和完整。
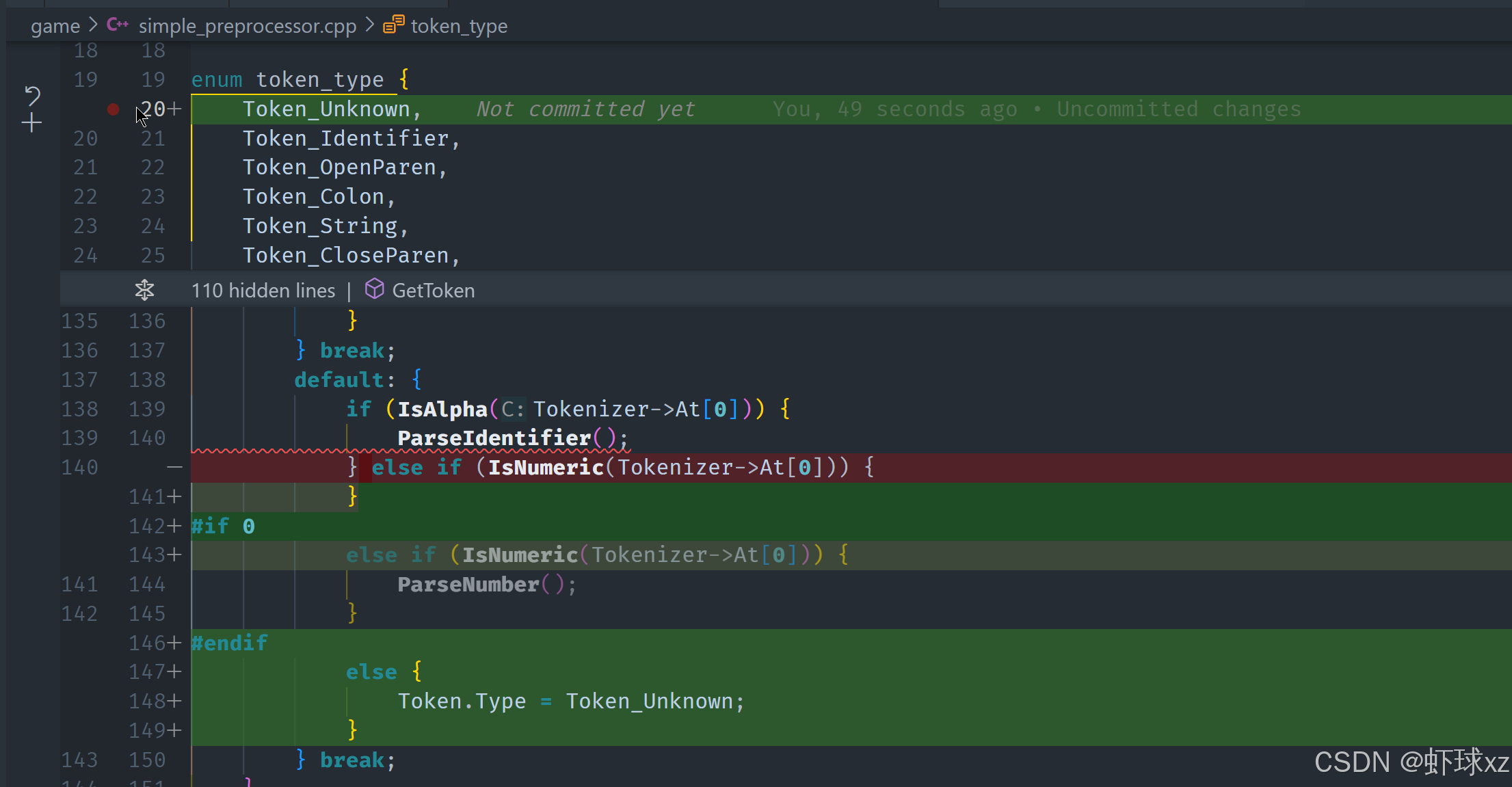
simple_preprocessor.cpp: 跳过闭合引号
目前我们已经完成了字符串的解析逻辑,现在的目标是继续完善标识符的处理。同时,我们回顾并补全了字符串解析中遗漏的一些细节,确保它完整且符合预期。以下是目前处理逻辑的详细总结:
字符串(String)Token 的收尾逻辑
在解析字符串时,我们之前实现了读取整个字符串内容,直到遇到关闭的引号。现在我们做了进一步补全:
-
设置 Token 类型为字符串
我们明确标记该 Token 的类型为字符串(
Token_String),这一步原来遗漏了,现在已经加上。 -
计算字符串 Token 的长度
字符串的起始位置是我们在进入解析时保存的
token.text,当前位置是我们正在处理的字符(即关闭引号)。所以长度就是当前指针位置减去起始位置:
cToken.TextLength = Tokenizer->At - Token.Text; -
跳过结尾的引号
我们在解析完字符串内容后,仍然停留在关闭引号上,所以我们需要再调用一次
++Tokenizer->At,跳过这个引号,以确保下一个 Token 的读取是正确的。 -
边界情况处理
如果没有遇到关闭引号,说明是非闭合字符串。此时可以选择标记为非法 Token 或者处理为错误,但当前我们仅假设输入是合法的,因此不会特别处理这类异常。
数据类型统一调整
我们将 Token 的长度统一使用 size_t 类型来表示,虽然大部分文件不会很大,但为了代码的一致性与健壮性,我们还是采用了这个更合理的数据类型。
整体设计的思路与优势
- 每种 Token 的解析逻辑都严格遵循:记录起始位置 → 扫描内容 → 设置类型和长度 → 跳过终止字符(如关闭引号);
- 字符串和标识符虽然结构不同,但处理流程高度一致,这使得代码更简洁、逻辑更清晰;
- 利用
tokenizer.at的差值运算计算 Token 长度,这种方式高效且易于理解; - 清晰地处理了边界情况,如是否需要跳过结尾字符、是否遇到终止符等;
- 模块化思维,每种类型独立处理,利于后期扩展其他 Token 类型,如数字、关键字等。
接下来我们可以继续补完标识符的识别循环代码,或者着手实现数字的处理逻辑,并对关键字(如 if、while、int)做分类,以进一步增强词法分析器的能力。整体结构已经很接近完整的原型了。
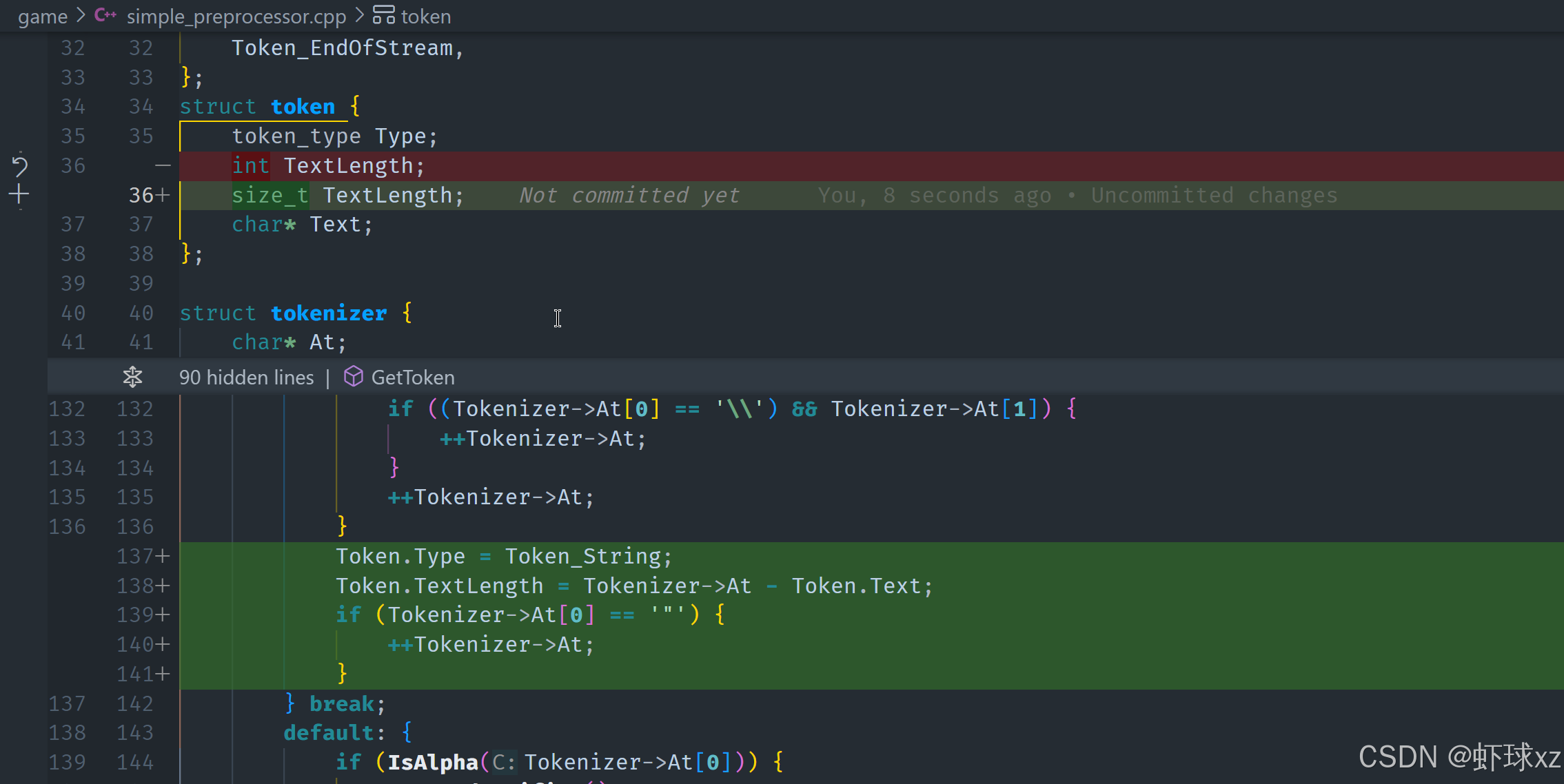
simple_preprocessor.cpp: 实现 ParseIdentifier
目前我们已经完成了对标识符(identifier)解析的实现逻辑,这部分逻辑非常简洁明了,以下是详细的中文总结:
标识符解析逻辑说明
标识符的合法字符组成:
在代码中,标识符可以包含以下几种字符:
- 字母字符:包括大写和小写字母(A-Z, a-z)
- 数字字符:0 到 9(仅限于标识符的非首字符)
- 下划线:_ (可以出现在任意位置)
标识符解析过程
我们所做的解析步骤如下:
-
判断当前字符是否合法组成标识符的一部分
使用一个
while循环,持续检测当前字符是否满足以下任意一项:- 是字母字符:
IsAlpha() - 是数字字符:
IsNumber()(此处将原先的IsNumeric()重命名为IsNumber(),使其语义更清晰) - 是下划线字符
_
- 是字母字符:
-
持续读取合法字符
只要上述条件成立,我们就调用
++Tokenizer->At函数,将当前位置前移一个字符,继续扫描。 -
计算 Token 长度
循环结束后,当前指针已到达不属于标识符的字符位置。我们将当前位置减去起始位置,得到标识符的长度。
cToken.TextLength = Tokenizer->At - Token.Text; -
设置 Token 类型为标识符
设置当前 Token 的类型为
Token_Identifier,明确表示这是一个标识符。 -
返回当前 Token
将构建好的标识符 Token 返回,供主循环继续处理下一个 Token。
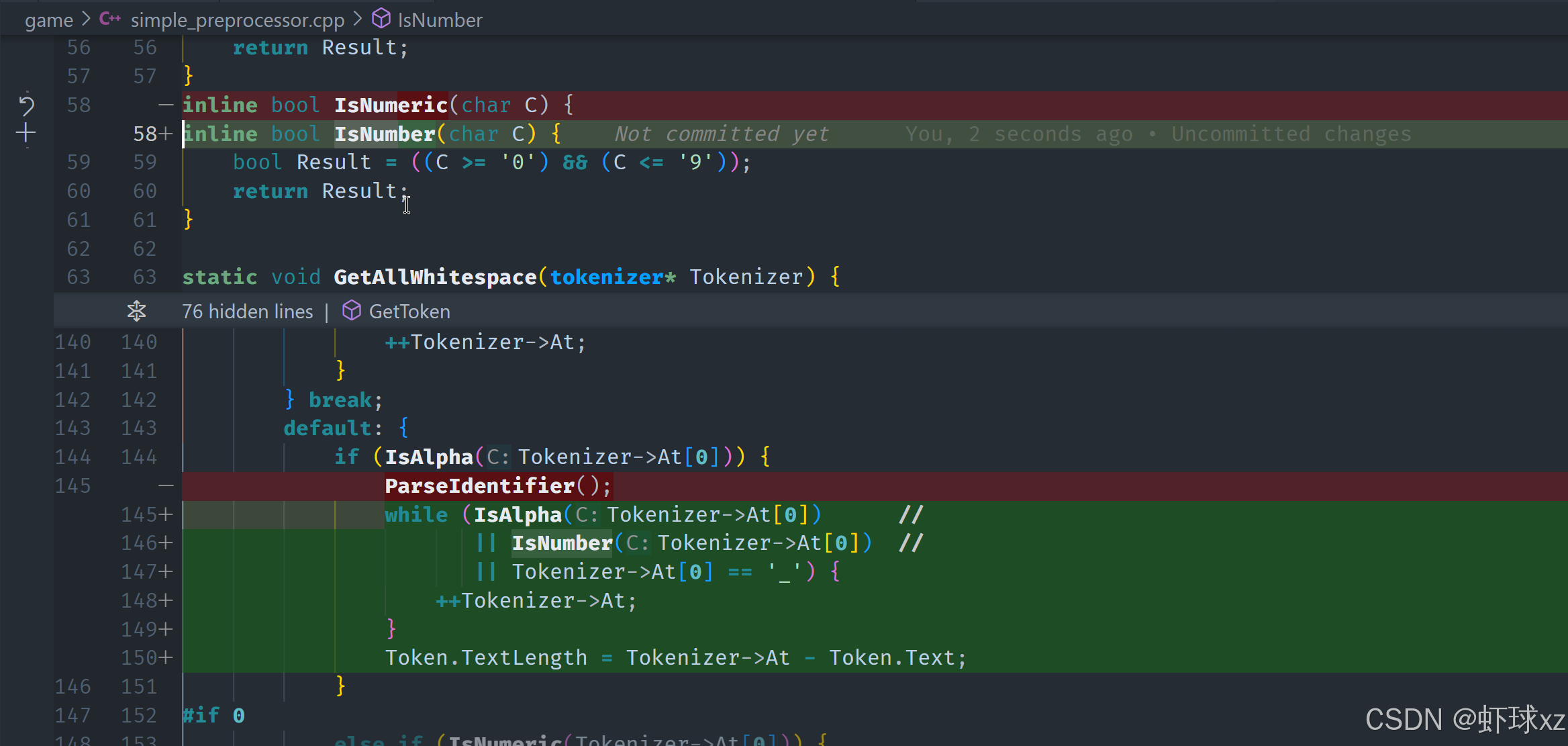
命名上的调整
- 将原来的
IsNumeric()改为IsNumber(),这个名称更贴合其语义 ------ 判断是否是数字字符。 - 这种小调整虽然看起来微不足道,但能够显著提升代码的可读性和维护性。
小结
标识符的解析逻辑最终如下:
- 以字母或下划线开头;
- 可以包含字母、数字和下划线;
- 解析时从起始位置扫描,直到遇到第一个非法字符为止;
- 计算长度、设置类型后返回。
这部分代码逻辑清晰,结构完整,是词法分析器中最基础也是最核心的组成部分之一。接下来可以考虑添加对关键字(如 if, while, return 等)的识别,或者开始实现数字类型 Token 的解析。整体框架已经非常健壮。
调试器: 进入 simple_preprocessor.cpp 并检查 Tokenizer
我们现在开始调试整个词法分析器的流程。虽然之前一次性写了不少代码,可能会有一些 bug,不过我们希望尽快完成第一阶段的解析器逻辑。
调试词法分析器(Tokenizer)初步结果说明
在初步运行词法分析器后,我们进行了实际输入的分析测试,以下是调试过程中暴露和处理的关键问题及细节:
遇到的问题与分析
-
未知字符没有正确跳过:
- 输入中出现了
#符号(即#include里的#),当前词法分析器没有将其识别为合法 Token,因此它会被当作unknown处理。 - 按预期,我们会生成一个
Token_Unknown类型的 token,这是正常的。 - **问题在于:**设置
Token_Unknown类型后,没有主动跳过当前字符,导致下一次循环时仍然处理相同位置的字符,陷入死循环或重复处理。
- 输入中出现了
-
应该跳过未识别字符:
- 在识别到一个未知字符时,除了设置类型为
unknown,还必须将指针tokenizer.at向前移动一步,这样才能继续解析下一个字符。 - 否则词法分析器将不断停留在错误字符上,导致错误堆积或卡死。
- 在识别到一个未知字符时,除了设置类型为
解决方案和调整
-
为
Token_Unknown类型添加跳过逻辑:-
在处理未知字符时,除了设置
token.type = Token_Unknown,还需要执行:cadvance_tokenizer(&tokenizer);
-
-
保持一致的跳过方式:
- 所有 token 处理路径中,凡是确定当前字符已经处理完毕,都要明确调用跳过函数。
- 确保词法分析器在每一次循环中都能向前推进。
当前 Tokenizer 状态回顾
- 正确识别了未知 token(例如
#) - 能够跳过空白字符
- 能识别标识符(如函数名、变量名)
- 能设置 token 长度和类型
- 但存在部分遗漏的跳过逻辑,正在逐步修正中
小结
词法分析器的初步构建已经完成,当前主要任务是调试细节,确保每种类型的字符都被正确处理和跳过。接下来将继续完善处理逻辑,包括:
- 更复杂的 token(如数字、字符串、操作符等)
- 忽略注释
- 识别关键字
- 更健壮的错误处理
整体架构已经具备良好扩展性,调试细节将在接下来进一步打磨。

#pragma once
继续解析
pragma
simple_preprocessor.cpp: 处理跳过第一个字符
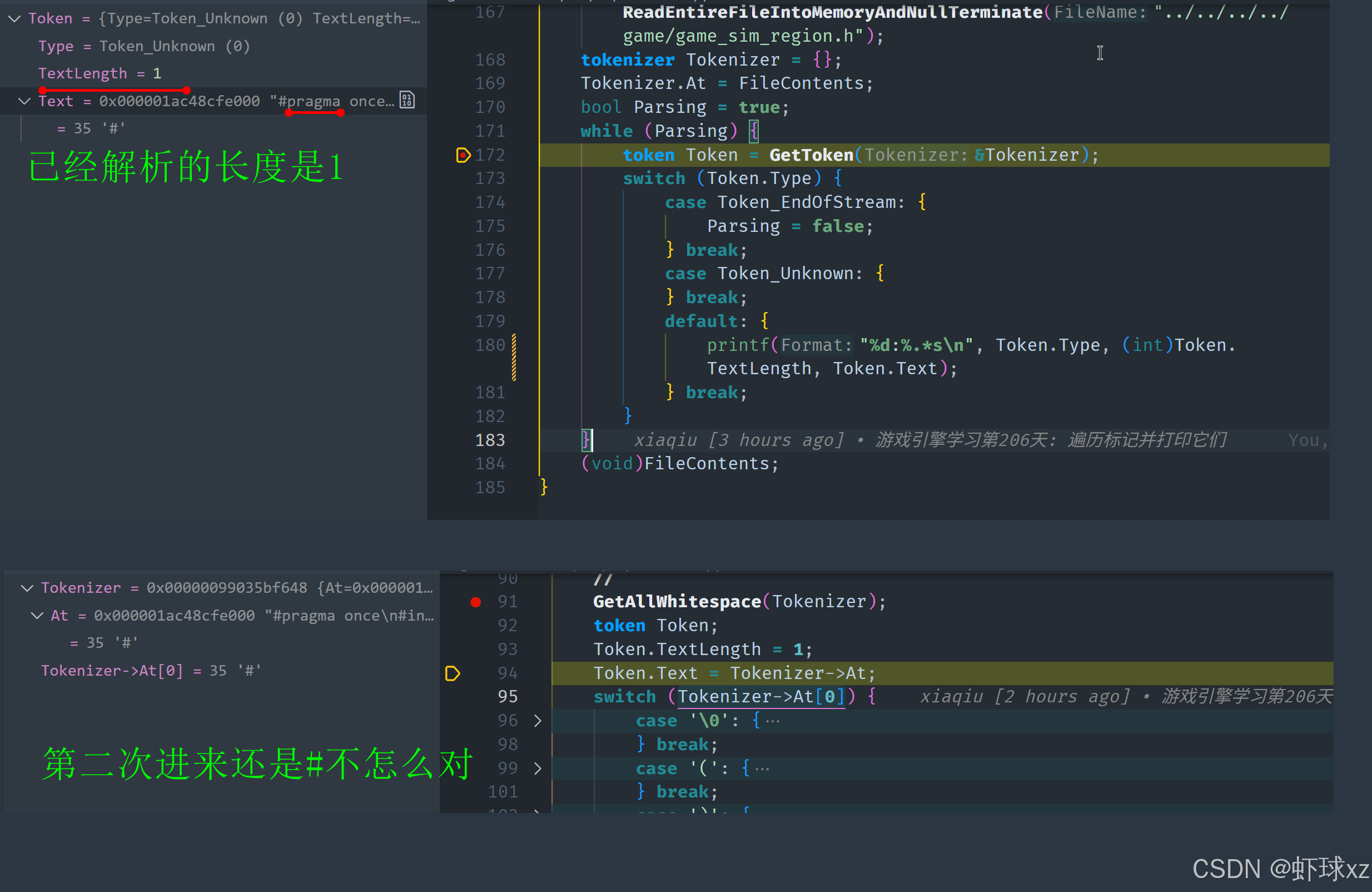
我们遇到了一个设计上的小问题:当前手动处理的 Token 类型(例如 Token_Unknown)在初始化时没有自动跳过第一个字符,导致后续逻辑不够流畅,处理也显得重复和冗余。
问题核心
我们每次识别一个 Token 时,默认从当前位置开始读取。但如果遇到一个无法识别的字符(比如 #),我们只是简单地标记为 Token_Unknown,并没有把 tokenizer.at 向前移动。这样导致词法分析器在下次处理时又会读取同一个字符,造成循环停滞。
解决思路
为了让流程更顺滑,我们考虑是否可以 在默认情况下就自动跳过第一个字符,从而让所有 Token 的处理函数默认都是以"已经读取一个字符"为前提,简化每个路径的处理逻辑。
实现方法尝试
我们引入一个默认行为,例如:
c
char C = Tokenizer->At[0];
++Tokenizer->At;这段代码将:
- 读取当前字符
C - 将
Tokenizer->At自动前移 - 后续的所有处理逻辑都可以假定当前已经跳过这个字符
这种方式适用于大部分 Token 类型,尤其是手动处理的部分(如标识符、未知字符、特殊符号等)。而对于像字符串这种特殊情况,反而已经主动执行跳过 " 开始字符,所以不会冲突。
优化后的流程
以标识符解析为例:
- 读取第一个字符(已跳过)
- 判断是否为字母
- 如果是,进入循环继续读取字符,只要它是字母、数字或下划线
- 最后根据起始位置和当前位置计算 Token 长度
注意事项
虽然这个方案可以减少重复代码、增强一致性,但它也需要小心控制边界和异常情况:
- 必须确保所有路径在读取字符后都适当地更新状态
- 对于像字符串、注释等含有起止符的 Token 类型,仍然需要手动处理边界
总结
我们通过在默认处理流程中引入一次性跳过首字符的方式,提升了 Tokenizer 的处理流畅度和可维护性。虽然这种做法有一定的"技巧性",但配合清晰的结构和注释,它可以减少大量重复逻辑,让词法分析流程更加紧凑高效。
接下来我们将验证这种改动是否会引入新的问题,如果一切正常,将继续完成对数字、关键字等更多类型 Token 的支持。
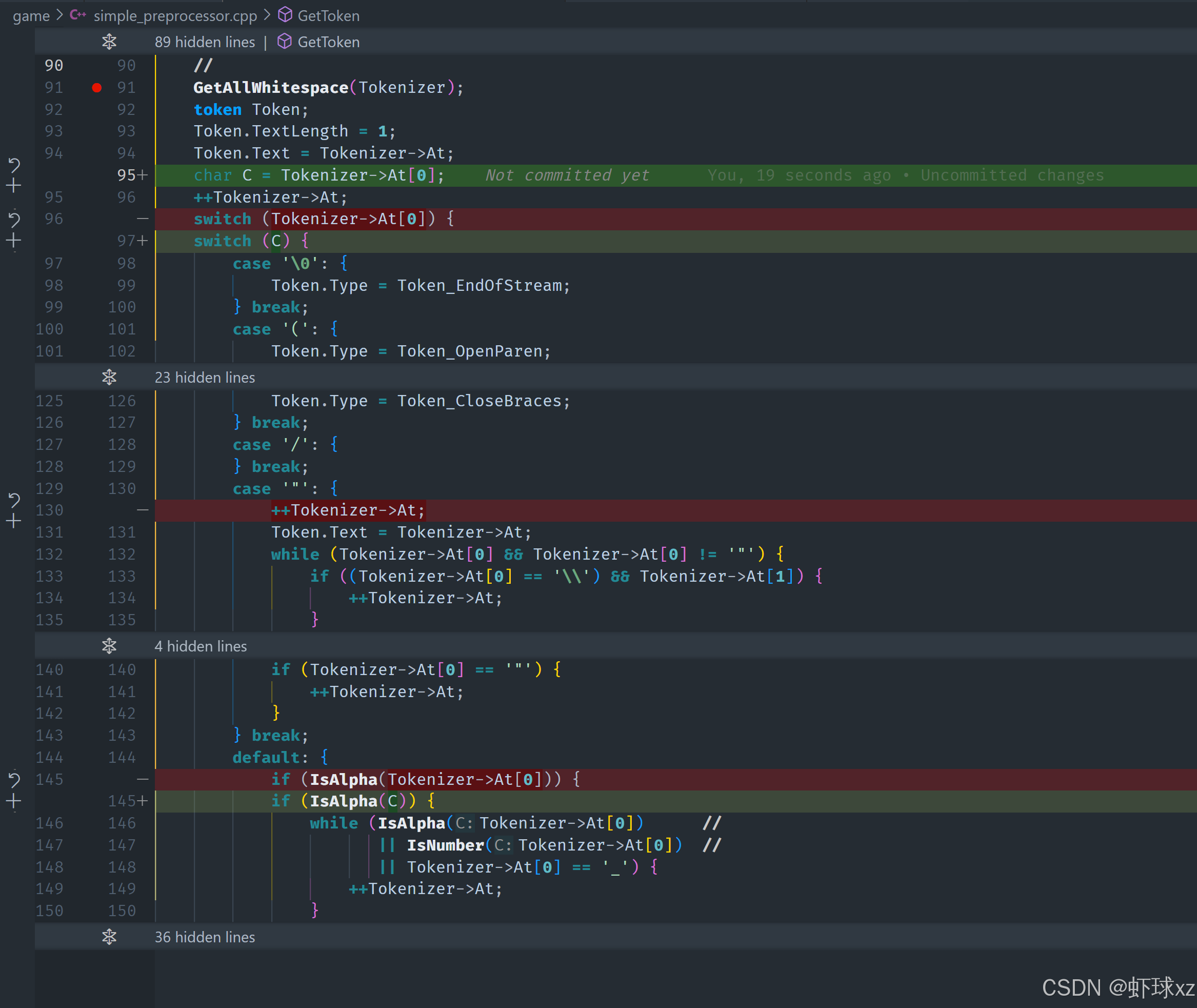
调试器: 再次进入并检查 Token
在进行代码调试时,首先成功识别到了一个 Token_Unknown 类型的 Token,这个 Token 的长度是 1,对应于字符 #,这是预期的结果。
接下来,系统开始处理下一个 Token,应该是一个标识符(Token_Identifier)。然而,出现了一个问题,虽然该 Token 的长度是 2,但它被错误地识别为 Token_Unknown。这可能是因为在设置 Token 类型时漏掉了必要的操作,特别是在标识符的解析部分,忘记在识别标识符时正确设置它的类型。
为了解决这个问题,决定在代码中确保一开始就正确设置 Token 类型。例如,在解析标识符时,如果成功匹配了标识符的字符,就应该直接设置该 Token 的类型为 Token_Identifier。同时,为了方便调试,也可以在 Token 创建的地方加入打印输出,以便检查类型和文本长度。
在修正了这个错误后,程序成功识别到了一个 Token_Identifier 类型的 Token,且其文本长度正确为 2,最终输出了预期的标识符内容。
通过不断调试,能够更精确地识别和分类各种 Token,确保词法分析器正常工作。
运行预处理器并查看其输出
目前已经可以开始运行词法分析器,并且通过简单的测试,已经能够正确解析出所需的内容。从结果来看,解析过程非常顺利,已经能够提取出需要的标识符和其他相关内容。
通过之前的调试和修改,代码已经变得更加简洁和有效,能够处理游戏代码中的不同标记,成功地将其转化为可识别的 Token。这个过程相对简单而直接,展示了词法分析器的基础功能。
尽管时间已经不多,还是有信心能够继续优化和调试,确保程序能按预期工作并处理更复杂的代码。如果时间允许,还可以进行进一步的测试和修复潜在的问题。

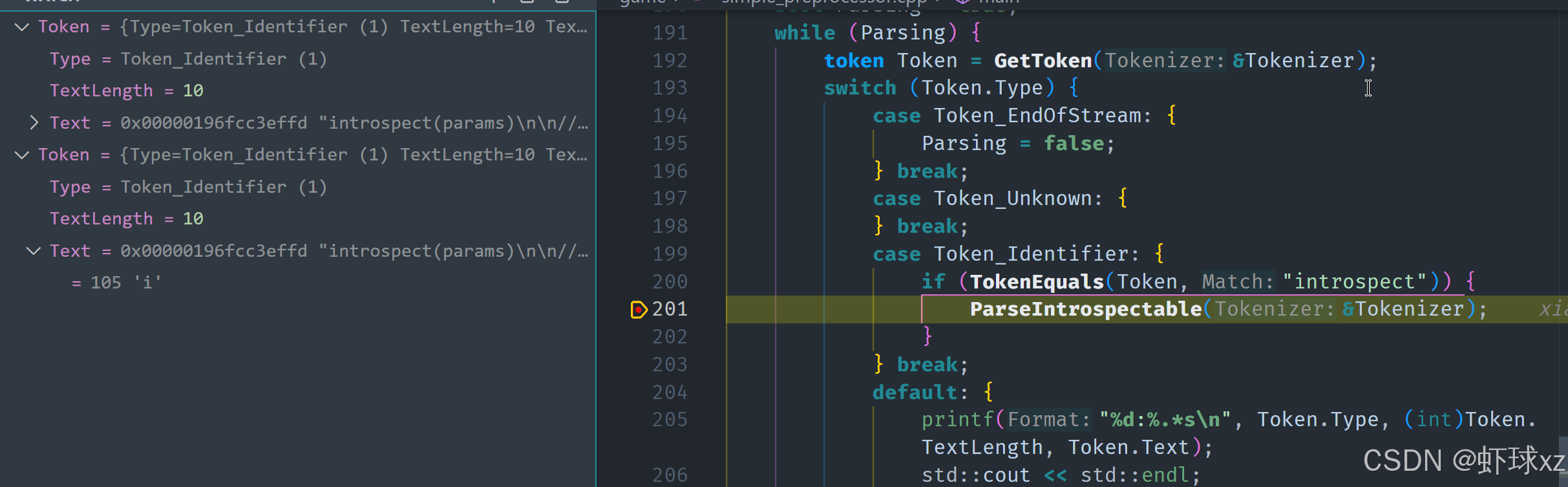
simple_preprocessor.cpp: 引入 ParseIntrospectable
在进行词法分析时,需要识别出特定的标识符,例如"introspect"。一旦识别到一个标识符,如果它等于"introspect",则需要解析这个特殊的结构,标记为"introspect"相关的内容。此时,应该将当前的标记传递给解析器,以便它能识别并处理这个特殊的标识符,进行特定的解析。
接下来,程序会使用printf来输出解析的结果,并在控制台显示这些被标记为"introspect"的内容。通过这种方式,系统能够识别和处理特定的标识符,并执行相应的操作,确保在预处理阶段能够正确处理这些特殊的代码片段。
在这个过程中,首先要确保正确识别和处理每个标识符,确保只有符合特定条件的标识符(例如"introspect")才会触发特殊解析操作。
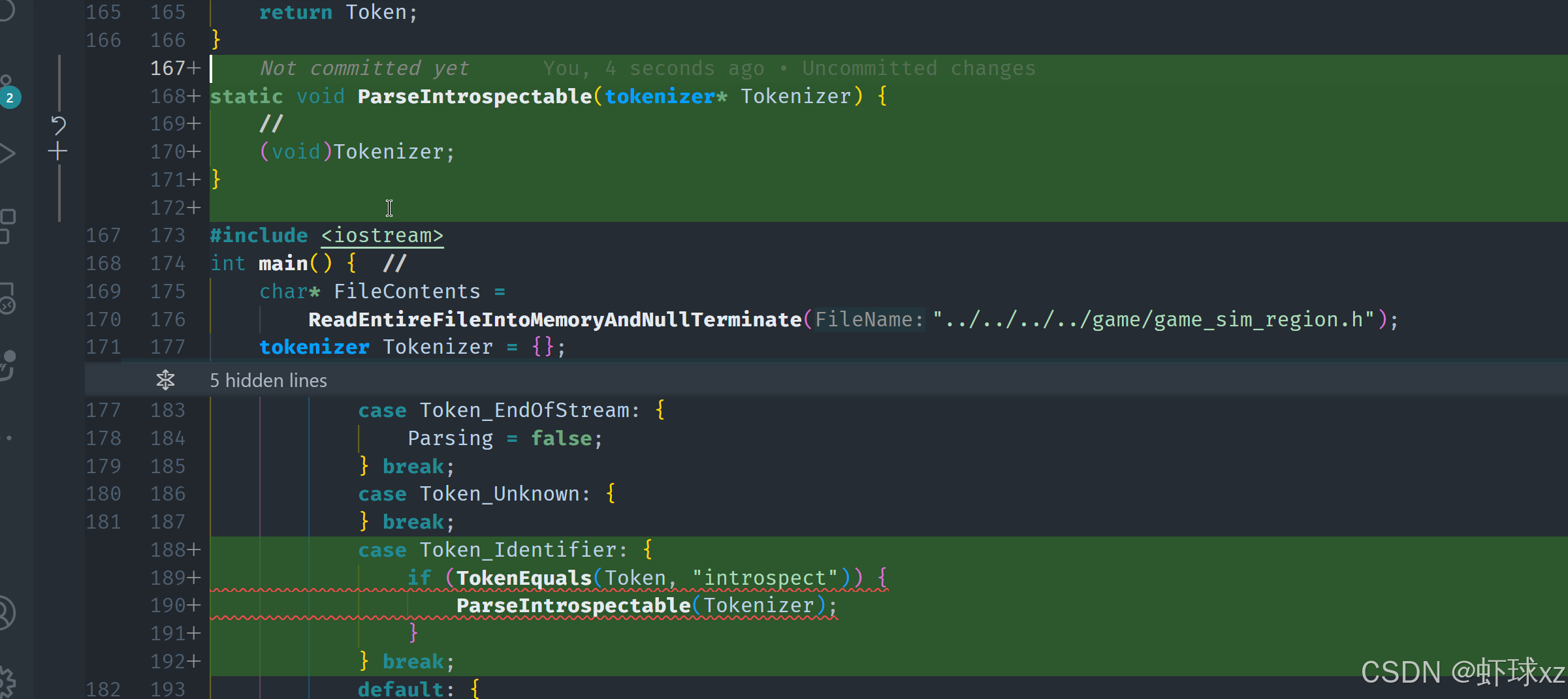
simple_preprocessor.cpp: 引入 TokenEquals
在处理标识符时,需要编写一个函数来比较当前标记的文本与目标字符串是否相同。为了实现这一点,可以创建一个内联的布尔函数,这个函数接受当前的标记和目标字符串作为输入。函数的工作逻辑如下:
- 获取标记的文本长度,遍历标记的每个字符,与目标字符串进行逐字符比较。
- 如果在任何位置字符不匹配,则返回
false,表示这两个字符串不同。 - 如果遍历结束时,标记和目标字符串都没有早早结束(即都到达了字符串的结尾),则返回
true,表示它们完全相同。 - 在比较过程中,还需要特别注意字符串的结尾标记(null terminator),如果遇到
null终止符,说明已经到达字符串的末尾。
通过这种方式,可以对标记进行字符串比较,从而确认它是否是目标标识符(如"introspect")。一旦确认匹配,就可以进一步执行与之相关的特定解析操作。
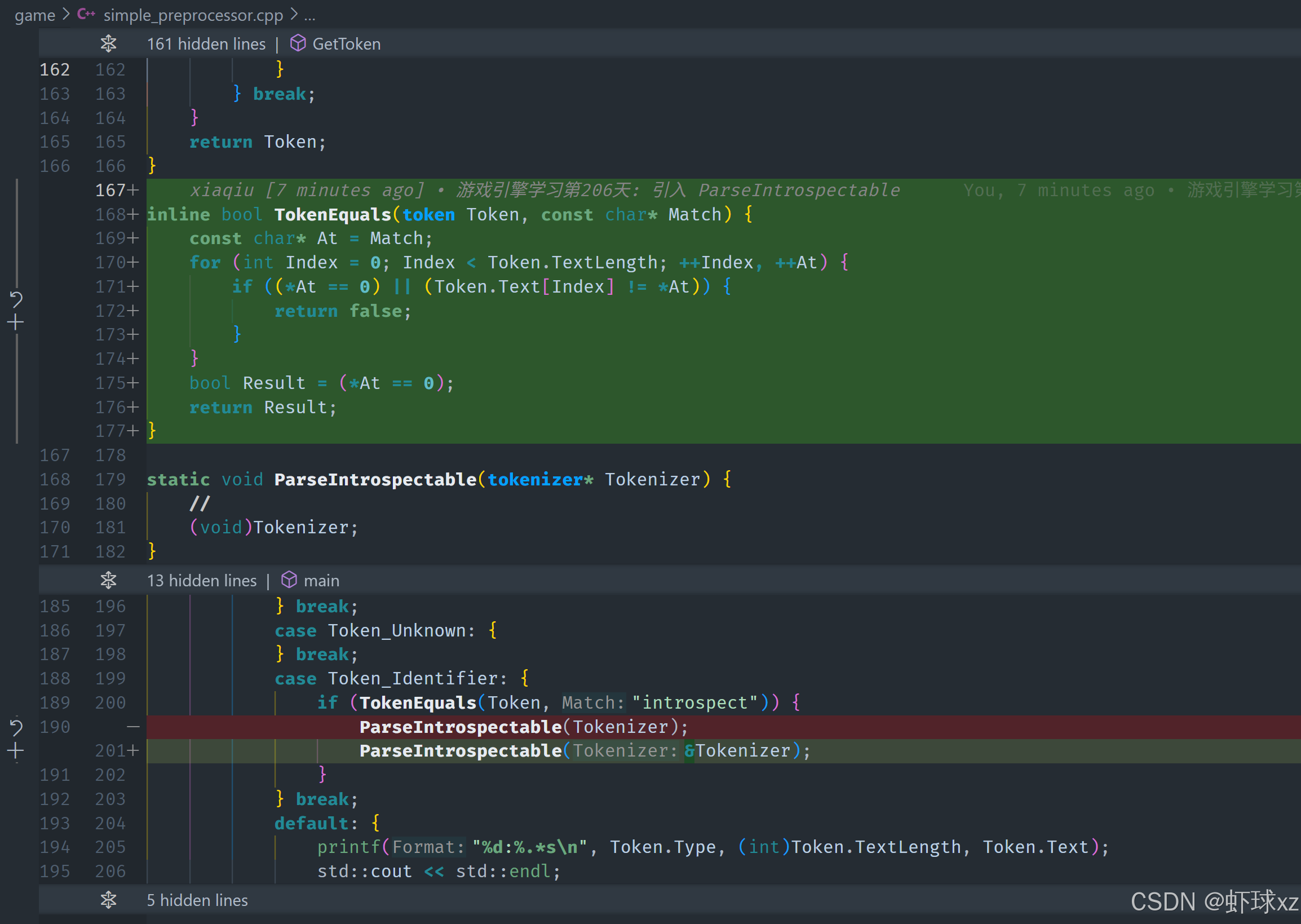
调试器: 进入 TokenEquals
在调试过程中,首先会检查当前的标记是否匹配预期的目标字符串。最开始,标记会被与目标字符串(如"if")进行比较。通过检查标记的每个字符与目标字符是否一致,发现第一字符匹配,但第二个字符不匹配。因此,预期的比较结果应该是false,表示标记与目标字符串不相等。
但是,在进一步调试时,发现问题所在:没有正确地执行字符串比较的逻辑,导致没有正确返回false。接下来,需要确保字符串比较的逻辑能够正确判断两个字符串是否完全匹配。具体来说,遍历标记的每个字符,与目标字符串的对应字符进行逐个比对,确保在字符不匹配时能够正确返回false,并且在完全匹配时返回true。
因此,关键是确保每次比较的字符位置都是正确的,只有在字符串完全一致的情况下,才返回true。
simple_preprocessor.cpp: 实现 ParseIntrospectable
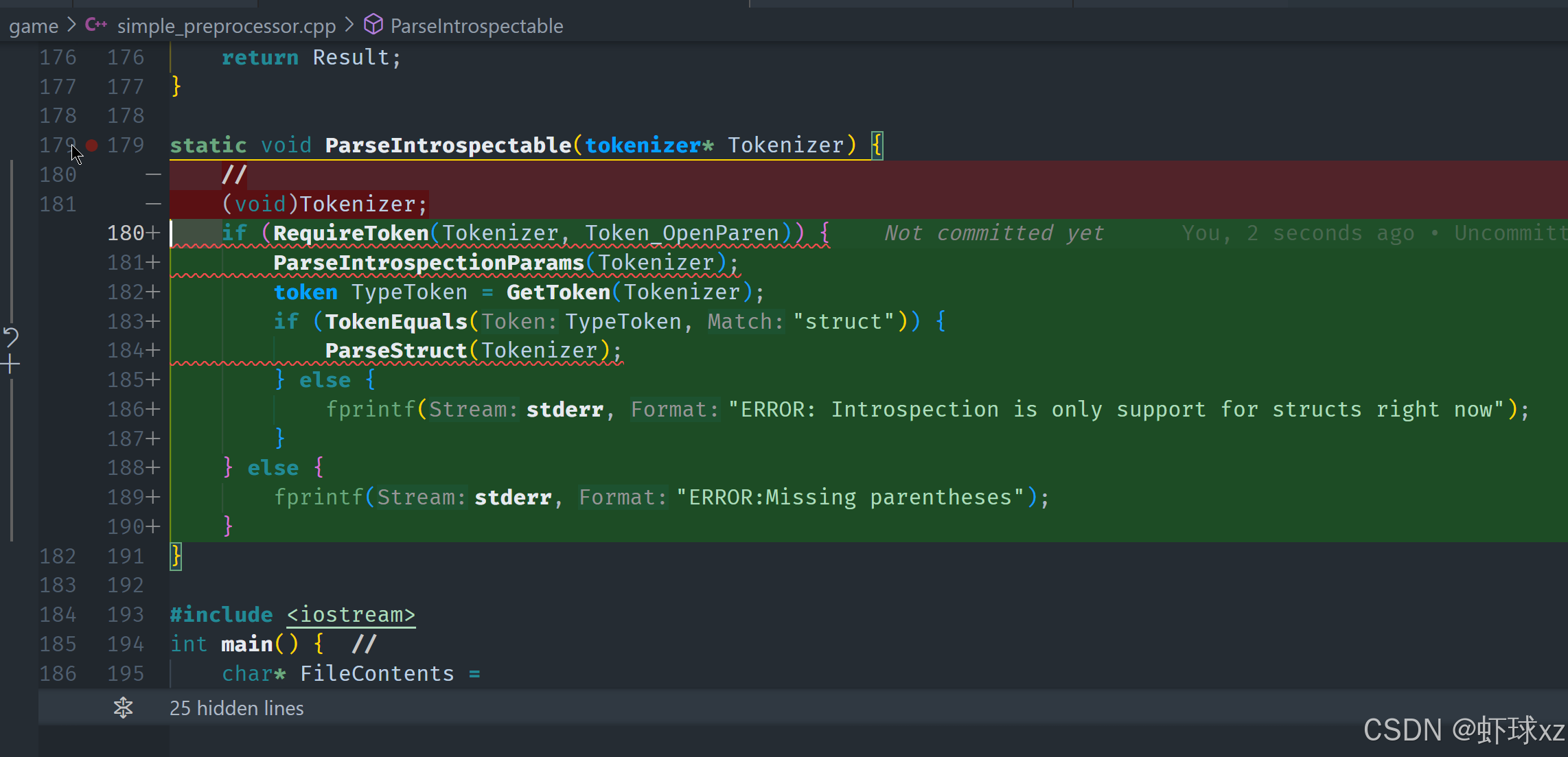
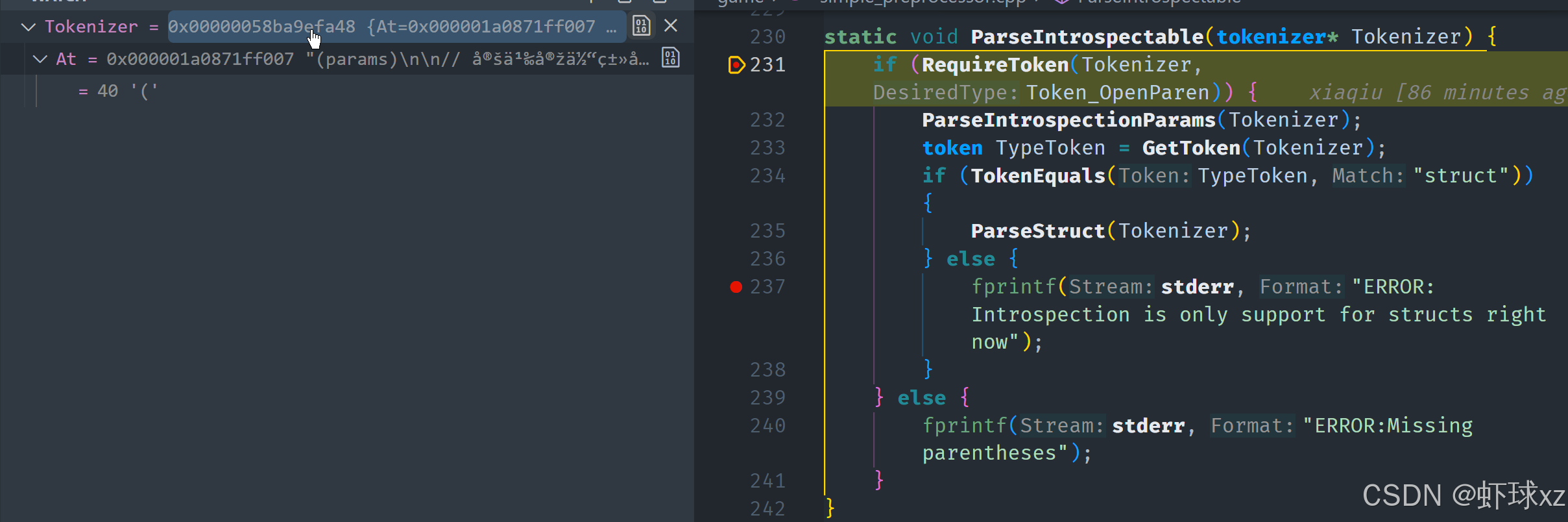
在解析"introspect"时,首先需要读取并处理括号中的内容。为了简化处理,可以采用最基础的方法:首先检查是否遇到开括号,若是,则接着解析括号内的参数(通过调用类似 ParseIntrospectionParams 的函数)。如果没有找到开括号,则输出错误信息,提示缺失括号。
然后,解析完括号内的内容后,获取下一个标记,并判断它的类型。如果标记类型为"struct",则继续解析结构体;如果不是,则输出错误,提示目前仅支持对结构体的 introspection。
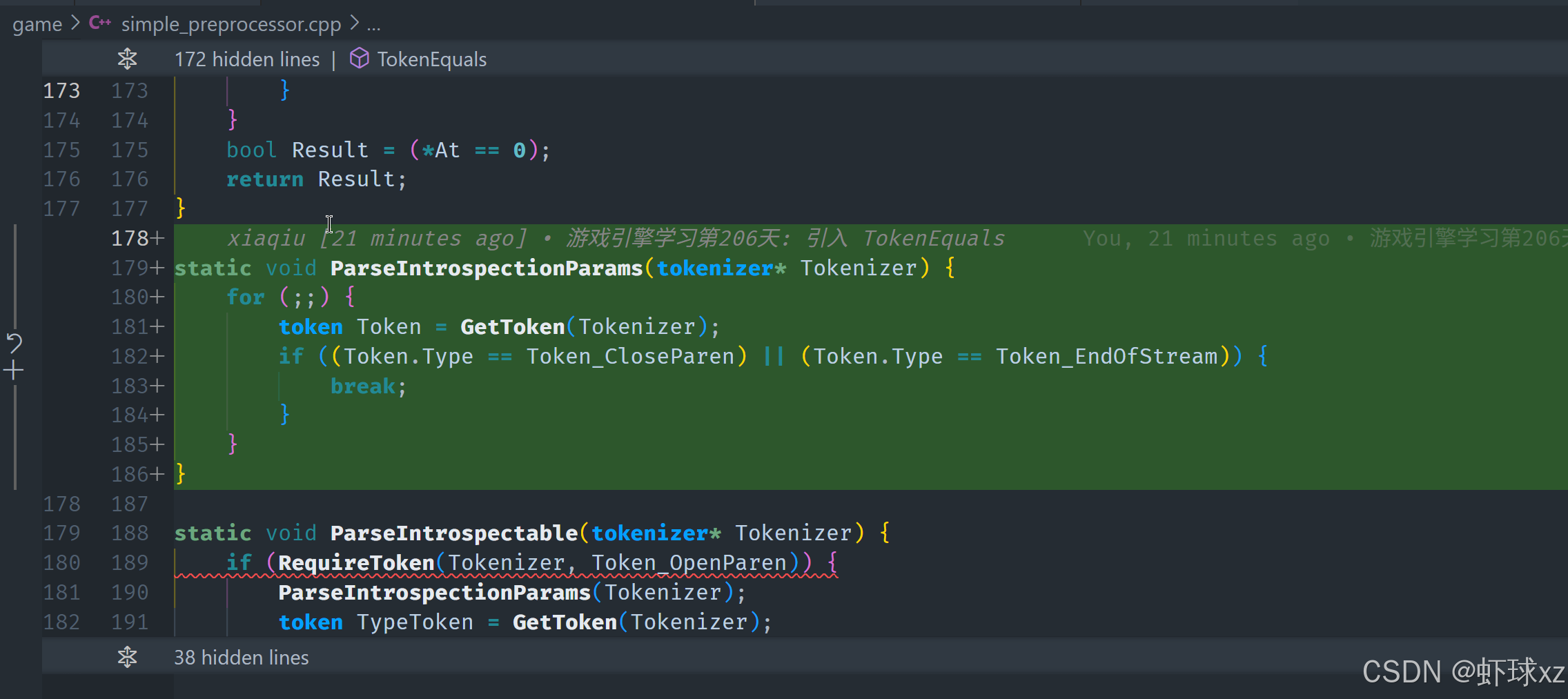
simple_preprocessor.cpp: 引入 ParseIntrospectionParams
在实现 ParseIntrospectionParams 函数时,首先需要通过 GetToken 获取下一个标记。如果当前标记是闭括号 Token_CloseParen 或者流结束标记 Token_EndOfStream,则表示解析结束,可以返回。否则,继续读取并跳过其他所有标记,直到遇到结束条件为止。
对于括号内的内容,如果是结构体 struct,则继续解析该结构体;如果遇到其他内容,暂时不做进一步处理,未来可以根据需求扩展功能,解析实际的参数。
simple_preprocessor.cpp: 引入 ParseStruct
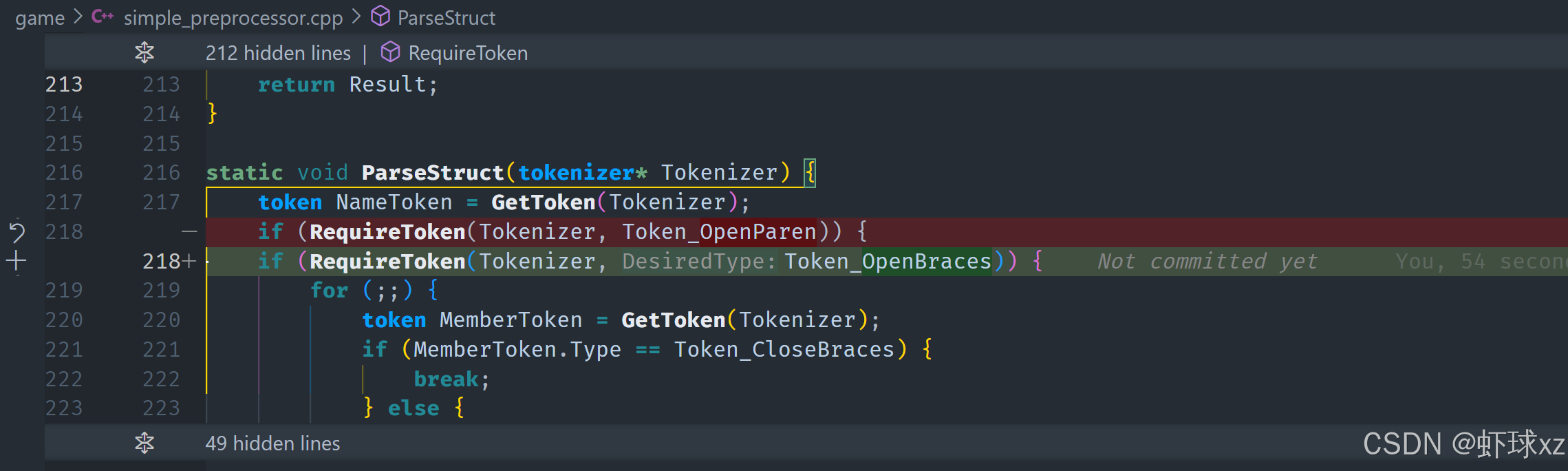
在解析结构体时,首先需要获取结构体的名称。接下来,必须检查并要求获取一个开括号(open brace)。在此之后,进入一个循环,直到遇到闭括号(close brace)为止。
在循环中,获取每一个成员标记。如果当前成员标记的类型是闭括号(Token_CloseBrace),说明结构体的解析已经完成,可以退出循环。如果不是闭括号,则继续解析该成员,使用 ParseMember 来解析每个成员,并传递当前成员标记给 ParseMember 函数进行处理。
这一过程持续到找到闭括号为止,标志着结构体成员的解析完成。
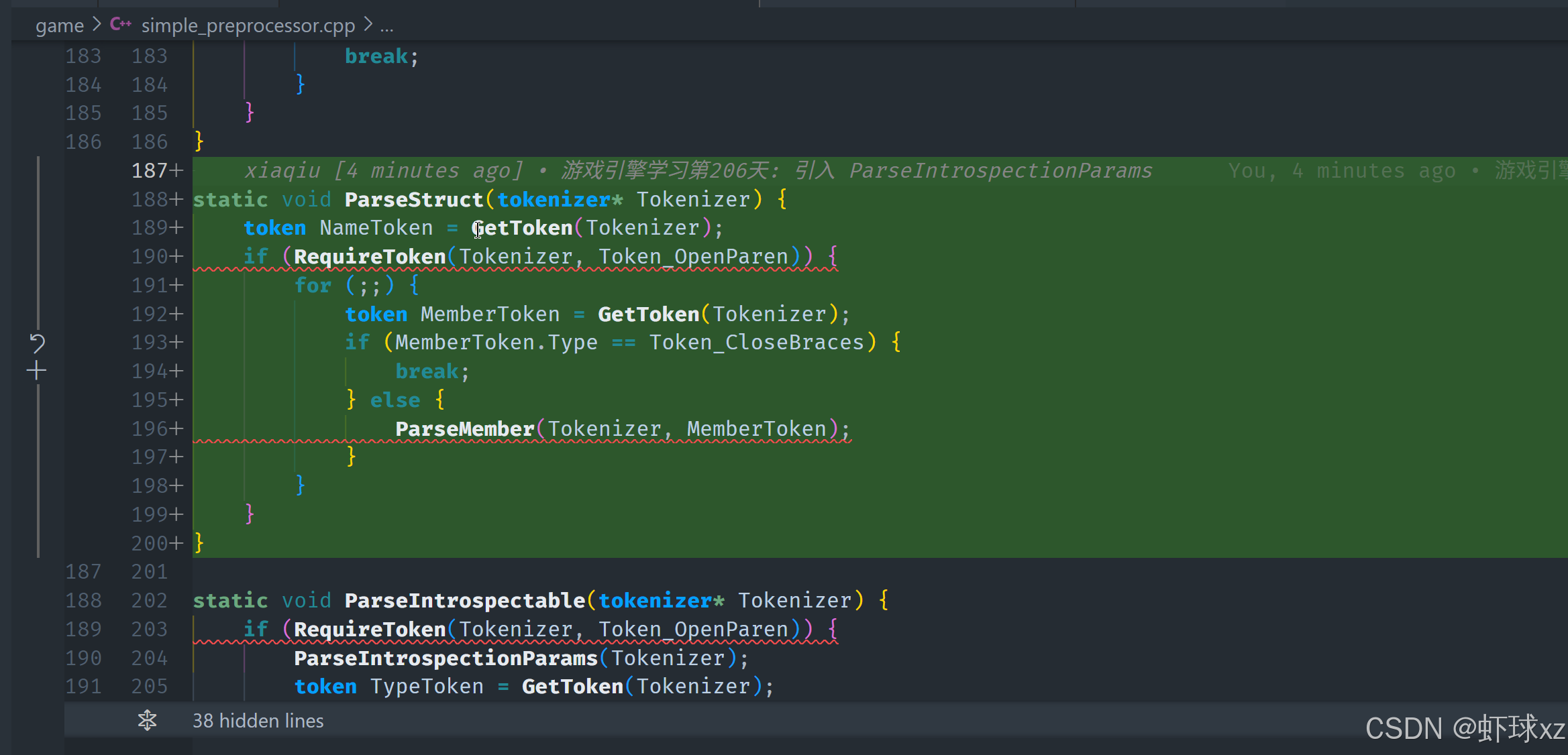
simple_preprocessor.cpp: 引入 ParseMember
解析成员时,可以通过类似的方式来处理。首先需要获取成员标记,这通常是类型标记,例如数字类型等。接下来,在 parse member 函数中,可以通过一个简单的机制来处理成员,暂时只需要读取直到遇到分号(;)为止,这样就可以完成对成员的基本解析。
在代码中,可以编写一个 require token 函数,确保当前标记符合预期类型。parse member 函数的作用就是读取成员的类型标记,直到遇到分号为止,从而完成成员的解析过程。这一部分相对简单,主要任务就是确保解析过程中正确识别并跳过不必要的内容,直到遇到标记分隔符(如分号)为止。

simple_preprocessor.cpp: 引入 RequireToken
require_token 是一个非常简单直接的辅助函数,用来确保从标记流(tokenizer)中获取到的标记类型必须是我们期望的类型。
其工作原理是:从流中获取下一个标记,并检查其类型是否与预期相符。如果相符,表示这是一个有效的标记;否则,这意味着解析失败。这个函数本质上是为了简化语法结构的校验过程------它是一种简写方式,用来表达"我在这个位置只接受某种特定类型的标记"。
接着,运行程序进行初步测试,这时候程序还不会真正执行任何逻辑操作,仅用于确认基本框架是否稳定,比如不会崩溃、死循环或挂起。这个阶段只是为了验证基本的语法结构和控制流程是否正常运行。
下一步的目标是让这整个标记分析器(tokenizer)开始实际输出一些有用的内容,说明解析器开始真正识别和处理代码结构,进入更完整的语义分析或代码生成阶段。整个过程从这里开始真正转向"理解"代码的实际内容。

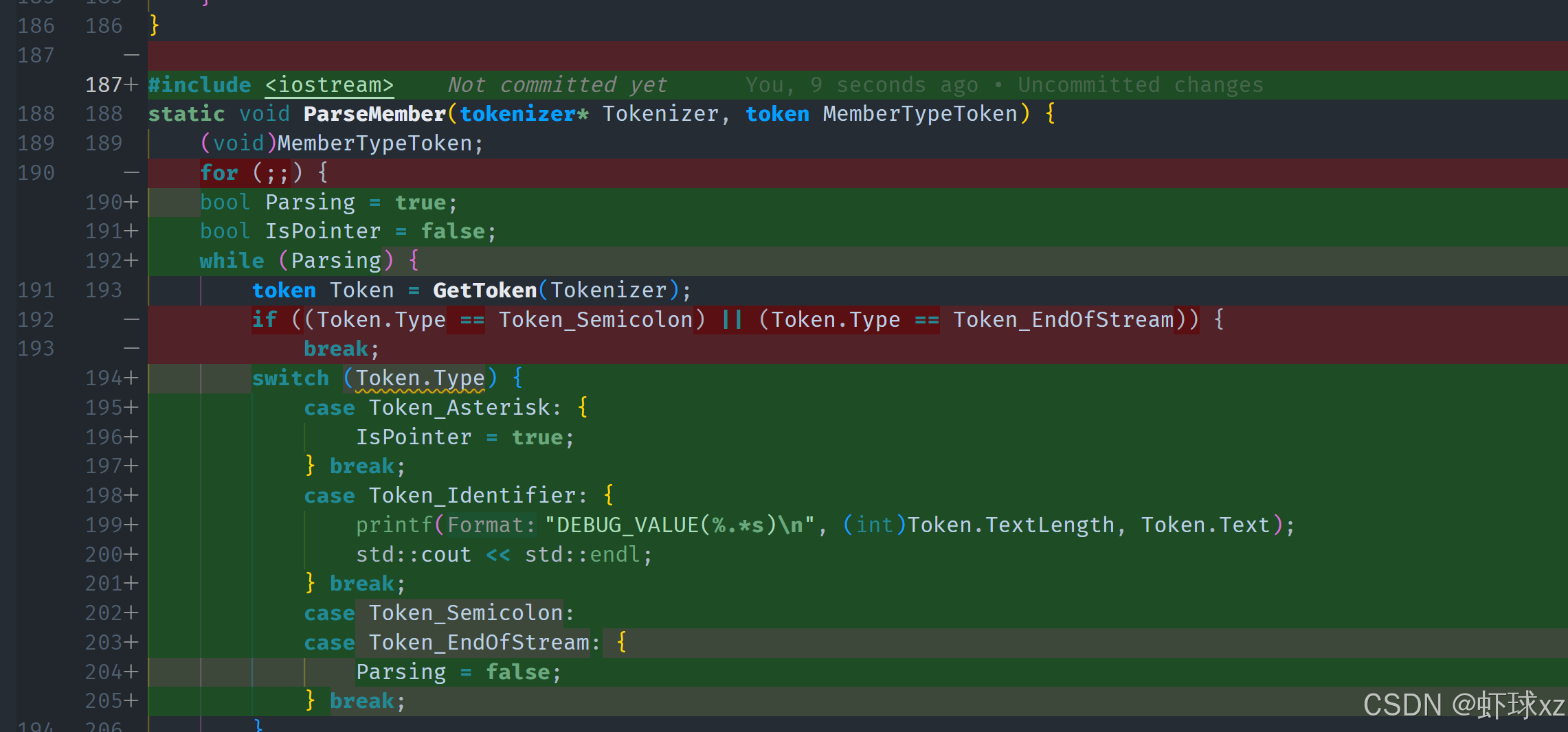
simple_preprocessor.cpp: 提供打印 DEBUG_VALUE 的功能
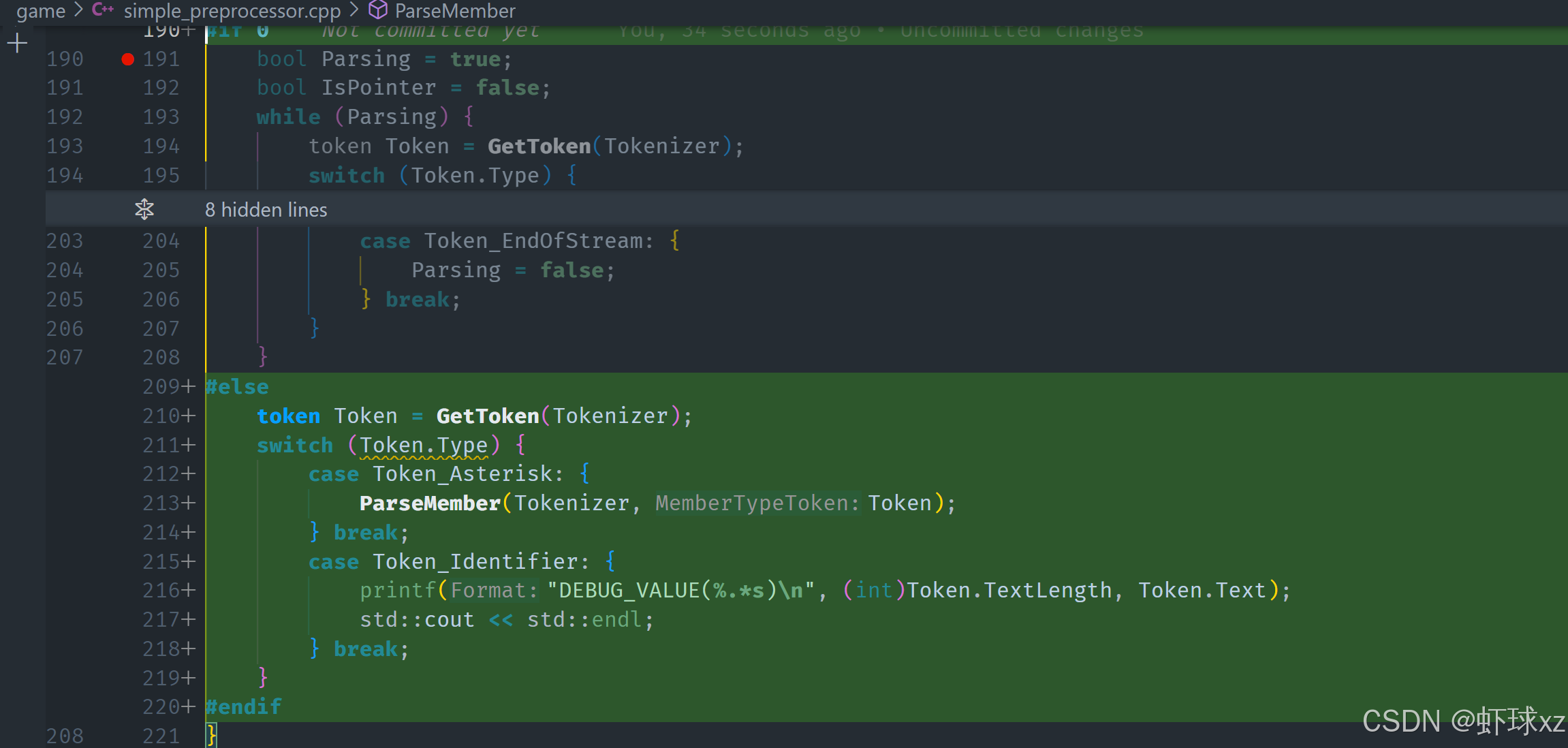
我们在解析结构体成员(struct member)时,希望能够输出每一个成员的调试信息,以验证我们的解析是否工作正常。为此,我们决定在 parse_member 函数中添加调试输出的 printf,用于展示我们所解析出来的成员信息。
每个成员通常包含一个类型(如 int、float)、一个名称,有些情况下还有指针(例如 int* ptr)或数组信息(如 int arr[10])。目前我们先忽略复杂情况,只处理简单的类型和名称组合。
我们首先获取成员的类型标记(member type token),这是结构体成员的第一个部分。随后使用一个 switch 或条件判断来处理这个 token 的类型:
- 如果当前 token 是星号
*,说明这是一个指针成员。我们设置一个布尔值is_pointer = true,表示这个成员是指针类型,并获取下一个 token。 - 如果当前 token 是标识符(identifier),我们假设它是类型名,然后紧接着获取下一个 token 作为变量名。
虽然这种处理方式比较简化,并不能覆盖所有语法情况,但它足以在这个原型阶段输出调试信息验证整体结构是否运作。
在处理 token 时,我们还需要考虑终止条件:
- 如果遇到
;(分号),说明一个成员解析结束。 - 如果遇到 token 流的结束,也意味着不再有更多成员需要解析。
我们设置了 printf 来输出成员名作为调试信息。这个名字 token 假设是成员名并打印出来。
最后,为了测试完整流程,我们编译运行这个初始实现,目的只是确认结构体成员可以被识别并输出其名称,整个流程没有崩溃、死循环或挂起等异常。
虽然现在处理方式还不够严谨,比如我们没检查复杂类型组合或数组声明,但这已经足以为我们接下来实现完整 introspect 支持打好基础。下一步可以在这个框架基础上扩展更复杂的解析逻辑。
运行预处理器并查看结果
发现解析错误
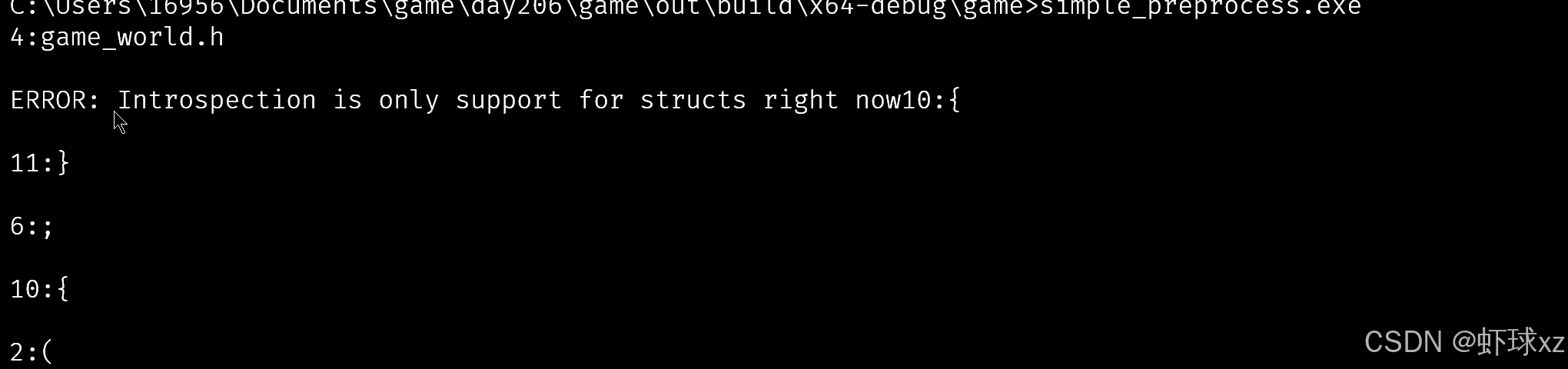
#define introspect(params)
格式不对移动到头文件中
发现//没有跳过一行

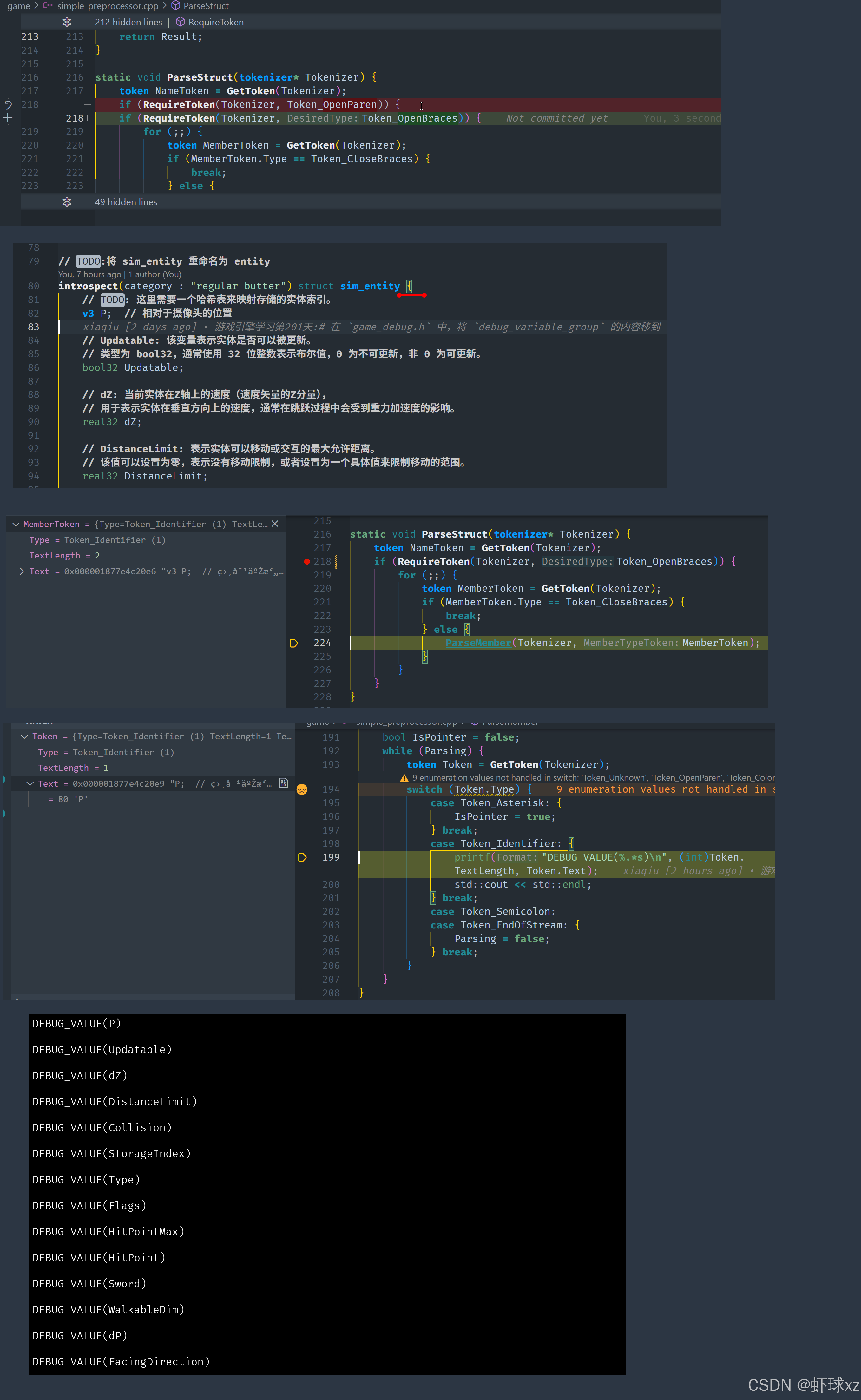
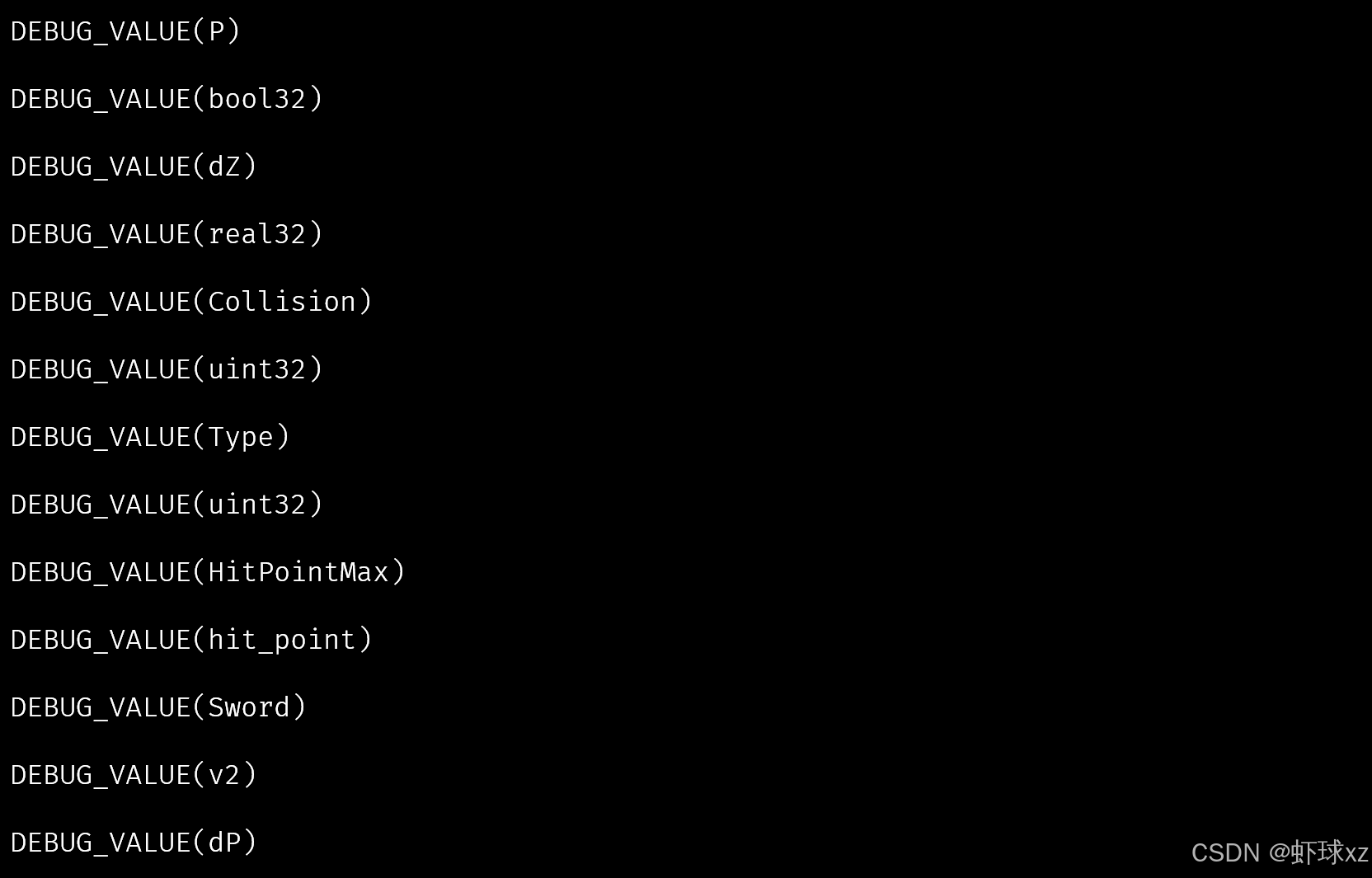
我们运行了代码并观察结果,成功实现了我们想要完成的目标。回到 game.cpp 文件,可以清楚地看到之前我们手动进行的工作现在已经被自动化了。这个结构已经能够正确地将我们需要的信息提取出来,说明整个解析流程已经初步完成。
虽然当前的输出格式可能不是最终想要的效果,但这已经为我们提供了一个基础的 introspection(自省)功能。如果想进一步扩展,还可以在输出形式和数据处理逻辑上进行优化,添加更多的功能或支持更复杂的结构。
从头到尾花费大约一个小时,就完成了初步的 introspection 系统。这只是基础的雏形,如果愿意,我们可以在这个系统之上做很多拓展,比如:
- 改进输出格式
- 支持更多的结构体声明风格
- 加入对指针、数组、嵌套结构体等复杂字段的处理
- 自动生成调试信息、元数据或序列化代码等
看起来你正在做递归下降解析。你认为这算是递归下降解析吗?
是的,这种做法确实可以称作"递归下降解析(recursive descent parsing)"。我们确实是在用这种方式编写解析器,虽然之前没有特别指出来,但实际上整个结构就是标准的递归下降解析的模式。
解析器的构建方式有很多种,而我们采用的方式是比较直接且容易理解的一种:每个语法结构都有一个对应的解析函数,这些函数通常会互相调用,从而递归地完成整个语法树的解析。整个过程围绕"读一个 token,判断类型,决定怎么处理"这一流程展开。
在这个系统里,我们通过:
- 写一个个
parseXXX函数,像parseStruct、parseMember、parseIntrospectable等,分别处理不同的语法部分; - 每个函数读取当前 token,根据其类型决定是否继续解析、调用别的函数或报错;
- 利用
get_token()或require_token()这样的函数不断推进输入流,并做出匹配判断; - 结构上保持函数之间的清晰层级和职责划分。
这就是递归下降解析的核心思路------手动控制递归的层次结构和输入流的推进,以构建出我们想要的抽象语法树或中间表示。
这种方法有以下几个优点:
- 实现简单直观,逻辑清晰;
- 可读性高,容易调试;
- 适合语法不是特别复杂的语言或结构;
- 对错误处理也比较友好,可以按需插入各种错误提示或恢复逻辑。
虽然对于更复杂的语法,可能需要引入更强大的解析器生成工具(如 yacc、bison、ANTLR 等),但对于我们当前实现 introspection 的需求来说,递归下降解析是非常合适、灵活的选择。我们可以轻松地扩展、微调每一部分的行为,甚至根据需要引入语义分析或代码生成。
黑板: 递归下降解析器
是的,我们写的这个解析器确实可以称为"递归下降解析器(recursive descent parser)"。不过更准确地说,目前的实现只是"下降解析器(descent parser)",因为我们还没有真正用到递归部分。
正常来说,在递归下降解析器中,每当遇到一个需要进一步解析的语法结构时,就会调用一个对应的函数去解析它,函数之间会彼此递归调用,从而构建一个语法树或某种层级结构。比如,如果我们遇到一个指针声明(*),理论上我们会再次调用 parse_member 或 parse_type 之类的函数去处理后续的内容,从而形成完整的语义结构。
但这一次,我们为了加快进度,在部分处理上使用了比较"直接"的做法。具体地说:
- 用了很多
while循环代替了函数递归; - 对于复杂类型、嵌套结构、指针、数组等都先做了简化处理;
- 没有构建完整的语法树,而是采取了"快速消费 token 并处理"的方式;
- 省略了很多常规递归解析器中的精细结构。
也就是说,目前写的版本是一个简化版,它的结构和方式可以演化为真正的递归下降解析器,但为了演示效率,我们暂时把递归替换成了迭代,快速跑通了流程。
如果有更多时间,比如下次继续扩展,我们可以:
- 为每种类型写对应的解析函数,严格按照语法结构逐层递归;
- 构建真正的语法树,方便后续分析和代码生成;
- 增加错误恢复机制,更优雅地处理语法错误;
- 引入更复杂类型(指针、数组、泛型等)的支持。
这就是真正意义上的递归下降解析器要做的事。而我们当前的实现,虽然概念上接近,但为了效率和展示,只用了最基础的框架。所以严格来说,它是递归下降解析器的"简化迭代版"。
simple_preprocessor.cpp: 引入更具递归性的 ParseMember 示例
我们实现的这个解析器是一个非常经典的递归下降解析器(recursive descent parser),这是一种手写解析器的传统方法,结构清晰、灵活性强,特别适合构建自定义语法或进行元编程。
具体来说,递归下降解析器的"递归"部分体现在处理结构嵌套时的行为------比如当遇到一个 *(星号,表示指针)时,应该再次调用 parse_member 来解析后续部分。这样处理指针链、多层嵌套类型等结构时,就可以形成类似语法树的层级结构,这种方式就体现了"递归"的部分。
我们最初为了快速推进,采用的是比较"快速而松散"的方式,即用 while 循环来消费 token 而不是使用函数递归。但实际上,如果我们按传统方式来做,代码会像这样:
c
if (token.type == Token_Asterisk) {
parse_member(tokenizer); // 递归调用自身处理剩下部分
}这样写更简洁、更符合语法结构,逻辑也更清晰。这才是真正的"递归下降"方式,解析器会沿着语法结构逐层"下降",每遇到一个子结构就进入下一个解析函数。
递归下降的"下降"含义是:
我们从外层结构开始,比如一个 struct 的定义。我们查看第一个 token,判断它是什么,然后"向下"进入具体的子结构解析,比如字段的类型、是否是指针、是否是数组等等。每下一层,我们都对 token 的上下文了解得更多、更具体,直到整个结构被完整解析为止。这个"逐步缩小范围、逐步深入"的过程就是"下降"。
递归下降解析器的优势在于:
- 易于理解和调试:逻辑直观,结构上跟语法定义一一对应。
- 灵活性高:可以随时插入自定义行为,如 debug 打印、条件处理等。
- 适合元编程和 DSL:尤其适合像 introspection(自省)这样的高级功能。
当然还有其他类型的解析器,比如 移进-归约(shift-reduce)解析器 。这类解析器通常不是手写的,而是由工具自动生成,如 yacc、bison 等。它们通常依赖状态机、栈和跳转表进行控制,结构更像机器代码,效率可能更高,但对人类来说不如递归下降方式直观。
总结一下我们这次的实现特点:
- 手写的、从上到下的、递归下降解析器
- 只使用了 一层 look-ahead(单词前瞻) 来判断接下来要做什么
- 简洁、直观、灵活,适合构建自定义的结构解析器
- 为后续扩展元编程、自定义数据描述、自动生成等功能打下基础
我们已经完成了一个小时内构建 introspection 的目标,并且通过这个简单的解析器建立了良好的起点。后续如果需要,我们可以继续扩展成更加完整、健壮的系统。
能否满足我对 C 标准的细节要求,接受 'v' 和 'f' 作为空格符?
我们决定采用一种标准的"分析偏执"(anal retention)方式,把 \v(垂直制表符)和 \f(换页符)也当作空白符处理。这样可以在解析过程中视它们与空格、换行等普通空白字符一样,统一处理空白区域。
虽然实际中这两个字符很少使用,但既然有人提出这个建议,也确实有一点"严谨"的价值,所以我们选择支持。这样做的一个好处是可以提高解析器的健壮性,哪怕遇到一些少见或古老格式的代码,也能正确处理,不至于报错或行为不一致。
顺带也探讨了一下各个平台的换行符问题:
- Windows:
\r\n - Unix/Linux/macOS:
\n - 旧版 Mac(极老的系统):
\r
不过从来没有见过哪种系统会用 \v 或 \f 来表示换行。所以我们确认,只是作为普通空白符支持它们,而不是作为换行符处理。
整体来说,这是一个偏向于严谨解析行为 的小改进,让解析器在处理各种源代码时更加容错,同时也体现了解析逻辑对规范的细致考虑。

你对 OpenCLC 有什么看法?
我们对于 OpenCL 这块其实没怎么深入使用过,对于 "OpenCL C" 更是了解甚少。可以明确的是,目前对它没有什么具体的看法或者经验。
虽然知道 OpenCL 是一种用于异构计算(例如 GPU 并行计算)的框架,但 OpenCL C 这种语言模式或变体就不是我们熟悉的领域。所以没法给出一个有价值或有深度的意见。
如果将来有机会深入学习或者接触 OpenCL C,那么可能会逐渐形成一些自己的理解和做法,但目前还不具备相关经验,自然也就谈不上如何处理它相关的问题或设计选择了。
如果你在递归中遇到错误,你会如何处理?在每个地方检查返回值是最好的方法吗?
在处理递归深度时,错误处理通常需要根据具体情况来决定。通常来说,错误处理之所以很棘手,是因为它需要在递归过程中进行有效的追踪和处理。为了应对这一点,常见的做法是在遇到错误时,尝试在解析器内部添加足够的逻辑来捕捉和处理这些错误。
一种常见的错误处理方式是创建一个错误令牌(token error),这样就可以在解析过程中将错误传递下去。此外,还可以在词法分析器(tokenizer)中调用错误处理函数,将错误信息堆积在词法分析器内部。这种方式让错误信息能够在解析过程中被捕获并传递。
如果错误处理较为复杂,处理逻辑会更深入,可以通过栈的方式来保存和管理错误,或者通过特殊的错误标记来表示遇到的问题。这是为了保证在解析时能够清晰地知道错误发生的位置并进行适当的回退或调整。
我来得晚。你能解释一下什么是自省吗?
在大多数编程语言中,结构体的定义和代码的执行结构是非常重要的,编译器需要了解这些结构,以便能够将其转换为可执行的代码。结构体不仅仅是数据的集合,函数也是由一系列操作组成的。在编译过程中,编译器能够理解这些结构,并根据它们生成代码。然而,大多数现代编程语言都具备一个功能,即能够在代码中查看这些结构,从而允许开发者在运行时对其进行操作,这种能力称为"自省"(introspection),有时也称为"反射"(reflection)。反射通常不仅仅是查看结构,还能进行更复杂的操作。
C++与大多数现代编程语言相比,缺少这样一个功能。即使语言本身处理这些结构时非常高效,它并不允许开发者在编写的代码中动态查看和操作这些结构。例如,在C++中,不能简单地请求编译器输出结构体的所有成员变量并打印它们,尽管这种操作在JavaScript等其他语言中是可以做到的。因此,C++缺乏这一功能,这也是它与现代语言之间的一个差距。
为了弥补这个缺失,可以自己实现自省功能。通过编写一个简单的预处理器,可以在C++代码中添加类似的自省功能,允许开发者在运行时访问和操作结构体的成员变量。例如,可以通过这种预处理器查看结构体entity中的所有成员变量,并将它们输出。这种方式可以让开发者在代码运行时看到结构体的内容,这对于调试和开发非常有帮助。
在实现的过程中,会遇到一些小问题,例如解析过程中未处理某些特定符号(如分号或流结束符号),这些问题需要解决才能确保预处理器正确工作。通过修改代码,可以确保在解析时能够正确处理这些符号,从而确保输出结构体成员时不会出现问题。通过这种方法,C++代码中的结构体可以获得类似于现代语言的自省能力,从而使得代码更易于调试和扩展。
你知道 Jon 是否为他的语言做了"元编程"吗?
在讨论元编程时,有提到一个问题,询问是否支持元编程。实际上,确实有支持元编程的功能,且这些功能最近在一次展示中首次亮相。根据展示的内容,元编程的特性已经开始加入到语言中,并且看起来这些功能将会非常强大,远远优于C++。C++本身并不支持元编程,尤其是在处理错误和编译时生成代码方面,缺乏必要的特性。这意味着,新的语言在元编程方面的发展将比C++更加完善和易用。
关于错误,再问一下,这种情况下异常处理是否有用?
对于异常处理,观点是异常永远都不应该被使用。尽管有人认为异常处理是解决问题的好方法,但在编程的实际经验中,几乎从来没有遇到过任何一个需要使用异常的情况。曾经可能因为被告知异常是解决问题的方式而认为它有用,但随着经验的积累,现在回顾过去的编程经历,几乎没有任何时候会觉得异常处理是合适的。异常处理并没有带来任何好处,反而可能增加代码复杂度和难度,因此在编程中完全避免使用异常会更好。
现在我们已经有了预处理器,你打算在更多地使用它吗?
对于预处理器的使用,计划是至少将其用于输出调试信息,尤其是输出注解。转换为注解功能只需要一天时间,因此既然已经实现了,就不妨继续使用。至于是否会在项目中进一步利用预处理器,尚未确定,但可以预见未来可能会有所增加。
Jon 是谁,你在谈论的是什么语言?
谈到的是Jonathan Blow,他是《Braid》和《The Witness》的设计师兼主程序员。他目前正在编写一种名为"Jei"的新编程语言,这个语言已经有了相当大的进展,而且非常不错。可以通过搜索"Jonathan Blow"在YouTube频道中找到更多关于这个语言的信息。
我正在写一个类似的解析器,但它运行在多 GB 的文件上,处理起来比较慢。有什么常见的方法可以利用 SIMD 或多线程加速文本解析吗?由于字符不像像素那样"独立",这似乎更加困难。
在处理大文件(例如多吉字节的文件)时,文本解析可能变得比较慢。虽然确实有一些常见的方法可以加速解析,比如使用多线程,但由于字符之间的依赖关系不像像素那样独立,这使得多线程解析变得更加复杂。在这种情况下,虽然可以考虑一些加速方法,但实际上,基于当前的处理经验,通常解析的速度已经足够快,远远超过了编译器的速度。
例如,使用微软C编译器时,编译速度非常慢,导致几乎所有的操作都不会成为编译瓶颈。对于多吉字节的大文件,虽然了解需要一些特别的优化思考,但由于缺乏实际经验,暂时没有足够的了解去提出具体的解决方案。虽然可以大致猜测如何开始优化,但这些想法都是完全推测性的。只有在实际处理过这种程序并面对问题时,才能更准确地给出意见。
这个直播让我感觉自己是一个极其不称职的程序员。你认可这种感觉吗?
对于编程中遇到的复杂性,不必因为看到经验丰富的程序员编写代码很快而感到沮丧或自卑。编程是一个逐步积累经验的过程,很多时候看起来迅速且轻松的代码实际上是因为程序员已经具备了长期的经验,理解了如何高效地解决问题。例如,尽管解析看起来简单,实际上是因为程序员已经编写过多个解析器,掌握了其内部的工作原理,因此可以快速完成。
重要的是,不要因此而怀疑自己是否能够做到。只要花时间学习、练习,理解代码并积累经验,就能做到和那些经验丰富的程序员一样好。最初的编程过程可能非常困难,不理解某些概念也是常见的。记得第一次听别人提到"词法分析器"时自己也感到震惊,这是一个成长的过程。随着时间的推移,经验的积累会让编程变得更加顺畅,编写代码的速度和质量自然也会提升。
同样,编程的进步不仅仅取决于技巧,还与日常的持续练习密切相关。正如一些经验丰富的程序员在年老时可能因为身体原因不再那么迅速,但他们依然能从事编程工作,因为他们积累了几十年的编程经验。最终,编程能力的提升是一个长期过程,只要保持不断学习和实践,就能达到更高的水平。
元编程如何改变你的工作流程?你能谈谈如何将生成的代码与"常规"的 C 文件结合吗?
在将生成的代码与常规的 C 文件结合时,通常的工作流程是通过生成可以被 C 编译器识别的结构体代码。首先,我们会将生成的代码格式化为标准的 C 结构体,这样就可以直接嵌入到 C 文件中。举个例子,生成的调试信息会被替换成某种结构体字段的字符串表示,比如将字段名输出为字符串,并且将其包装成一个可识别的格式。
接下来,我们会为这些生成的字段添加更多的细节,例如字段类型和其他元数据。通过这种方式,生成的代码就变成了标准的 C 代码,几乎可以像手写代码一样,直接插入到项目中的 C 文件中。这样,我们就能够在 C 文件中插入结构体定义,甚至是成员类型的描述,类似于我们手动编写的 C 代码。
生成的代码和手写的 C 代码结合后,最终将其编译成 C 文件,并与项目中的其他 C 文件一起编译。通过这种方式,我们能够实现类似于 C++ 中内省的功能,虽然 C++ 应该早就支持这种功能,但实际上并没有。最终的目标是将这种自动化生成的元数据整合到 C 文件中,使得开发人员可以轻松地访问这些结构体的内部布局,从而简化开发流程。