Linux系列
文章目录
- Linux系列
- 前言
- 一、磁盘
-
- [1.1 初识磁盘](#1.1 初识磁盘)
- [1.2 磁盘的物理结构](#1.2 磁盘的物理结构)
- [1.3 磁盘的存储结构](#1.3 磁盘的存储结构)
- [1.4 磁盘的逻辑结构](#1.4 磁盘的逻辑结构)
- 二、文件系统
-
- [2.1 系统对磁盘的管理](#2.1 系统对磁盘的管理)
- [2.2 文件在磁盘中的操作](#2.2 文件在磁盘中的操作)
前言
Linux 文件系统是操作系统中用于管理和组织存储设备(如硬盘、SSD、USB 等)上数据的一种核心机制。本篇我们将操作系统如何对未打开的文件进行管理的。
一、磁盘
磁盘是是计算机硬件中的唯一的机械设备,被广泛的运用于企业级存储,学习磁盘对数据的存储,对我们学习操作系统的文件系统有很大帮助。
1.1 初识磁盘
随着计算机行业的发展,磁盘由于存储效率较低,慢慢的在我们的私人电脑中被固态硬盘所替代,但是在企业中,磁盘依旧是存储的主流。这是因为:
1、相较于固态硬盘来说,磁盘的成本较低。
2、磁盘虽然效率低,但是容量较大,在企业中往往存在海量的不常访问数据需要保存,所以磁盘就成了比较适合的选择,
3、固态硬盘在存储和删除数据是对自身会有一定损耗,长时间的使用会有数据丢失的风险。
1.2 磁盘的物理结构

一个磁盘会包含好几个盘片,每个盘片具有两个盘面,这两个盘面都会进行数据存储,每个盘面都会配有对应的磁头,在工作时,磁盘会在主轴的带动下开始旋转,磁头则会在磁臂的带动下开始水平摆动,这个过程磁头并不会和磁盘接触。
1.3 磁盘的存储结构
下面我们来对一个磁面进行分析:
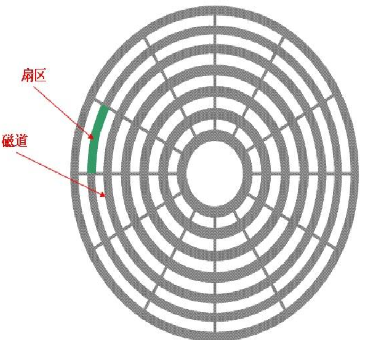
在一个磁面中,以主轴为圆心,向外会分成多个同心园,我们称这些同心圆为磁道,这些磁道又会被等分为多分弧段,这些弧段就叫做扇区,在磁盘进行数据的读写时就是以扇区为最小单位,每个扇区一般为512字节,从主轴向外扇区的长度是不同的,为了保证存储空间一致,设计规定离主轴越远数据的存储密度越小。
拓展: 磁盘在工作时,主轴带动磁盘旋转,磁头通过摆动来确定数据在哪个磁面、磁道,当确定磁道后,磁头停止摆动,此时磁盘继续旋转完成数据读写工作。
为了对方便管理,我们磁面、磁道、扇区进行编号,当我们要对磁盘数据进行访问时,就可以通过编号快速完成,具体怎么进行的我们下面介绍。
1.4 磁盘的逻辑结构
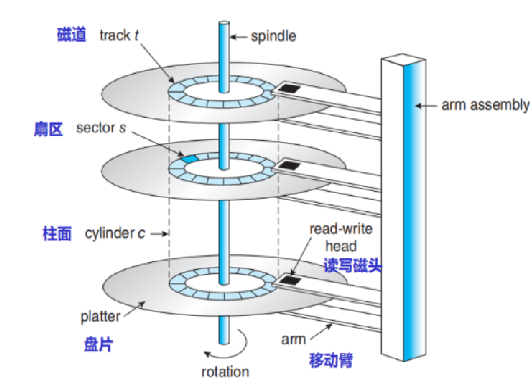
由于磁盘的大小相同,且磁臂是被固定的,这时再将磁盘划分磁道,我们就会得到一个由磁道组成的柱面结构,当我们对磁盘进行访问时,我们就可以先确定在哪一个柱面(cylinder) ,也就是磁盘,然后再确定再哪一个盘片(platter),由于每个盘片都配有一个磁头,所以我们是通过 磁头(head) 来确定的,再确定磁道(track),最后确定扇区(sector) 我们称这种定位方法为 CHS定位法。为了将它于操作系统建立联系,我们需要将它进一步抽象。
不知到大家有没有接触过磁带,来看下图:

左侧图片是磁带卷起的样子,会呈现出一个圆类似于盘面,当我们将它展开就会呈现出右侧有宽度的带子,我们可以依据这个特性将盘面中的磁道抽象为一个,条带子:
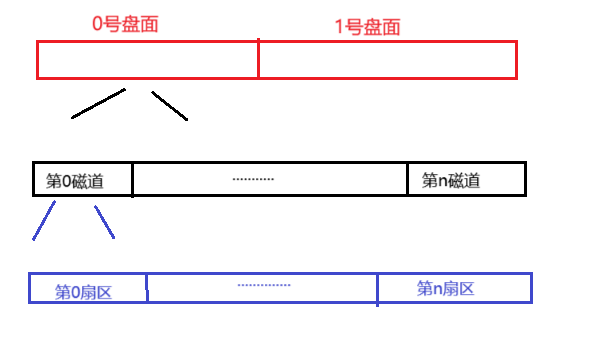
这里我们就可以将所有盘面全部抽象为一个线性结构(当成数组也可以,为了方便这里仅画出了一个盘),这时我们对磁盘的访问,就变为了对线性结构的访问,当操作系统要定位一个扇区时,我们只需要知道这个扇区的地址就可以完成对扇区的访问了,如要查找扇区编号为:355
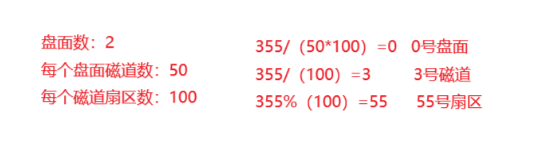
由于是从0开始编号,所以计算时只需要向下取整即可。
这样我们就成功定位到了扇区,而我们将这种编号称为LBA地址,定位过程就是LAB地址转化为CHS地址的过程。
二、文件系统
2.1 系统对磁盘的管理
我们可以确切的感受到,在我们的计算机中,磁盘是非常大的,如果操作系统直接对他进程管理,效率是非常低的,那么该如何让操作系统对它进行管理呢?对于这个问题,我们的工程师采用了分治思想,将整个磁盘划分为小块空间,通过对所以小块空间的管理,达到对整个磁盘的管理。
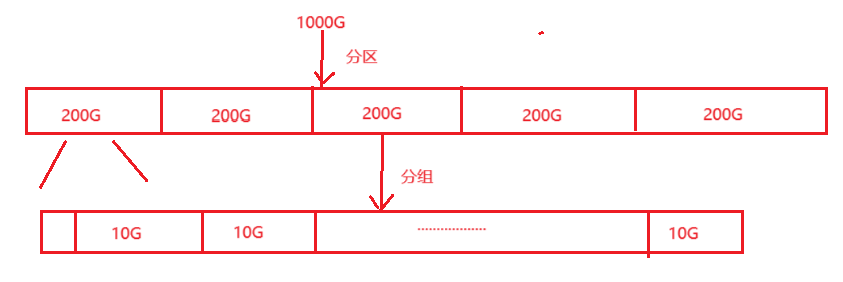
这样操作系统只需要完成对每个组的管理,就可以达到对整个磁盘的管理。
每个组又会被划分为以下几个区:

具体如何管理我们结合文件在磁盘中的存储,进行分析:
我们知道文件=内容+属性,而在Linux中文件的内容和属性是分开进行存储的,那么两者分开存储是如和建立联系的呢?或者说是如何管理的呢?
存储属性信息: 在Linux中每个文件都会对应一个inode结构体,这个结构体(对象)的大小是固定的,通常为128字节,文件的所有信息都存储在这个结构体对象中,其中并包含文件名,这是因为,Linux并不通过文件名进行查找文件,每个inode都会有一个编号,操作系统通过编号进行查找。上图的inode Table就是inode表(inode集合,下面会再次解释)。
存储文件内容: 在Linux文件内容是存储在上图Data blocks区域中的,而这个区域被划分为块(这些块也是会被分配编 号的),操作系统在访问磁盘时是以块为单位进行访问的,块中包含多个扇区,通常块的大小为4KB,此处可以理解为对读取性能的优化,因为当计算机要访问一段数据是,这段数据周围的数据也有很大可能被访问,所以直接读取4KB,这是一种以空间换时间的方法。(这个块大小是可以修改的,感兴趣的可以去了解)
属性与内容建立联系: 在inode对象中会存在,一个数组,数组中存储的是该文件内容存储块的编号。
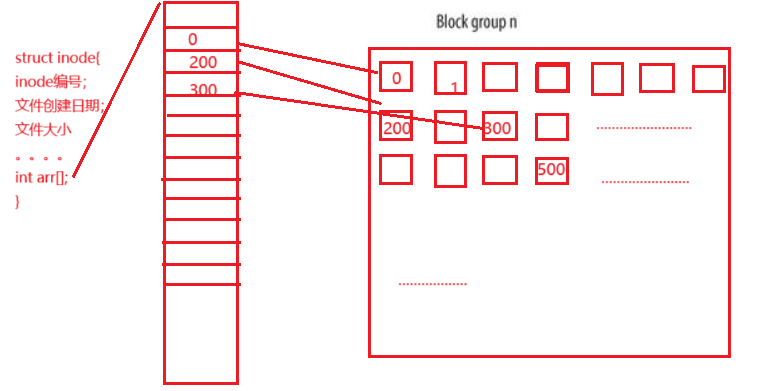
这样我们就大概的知道了,存储逻辑了,下面我们解释一下,组中各个模块的含义。

Boot Block:引导块,引导操作系统启动,我们不做研究。
Super Block:超级块,存储文件系统的整个信息(整个分区信息),包含bolck和inode的总量,未使用的量,一个bolck和inode的大小,文件系统状态(是否干净卸载)等。
Group Descriptor Table:块组描述符,描述块组的属性信息。
Block Bitmap:块位图,记录Date bolck中的块是否被使用,通过块编号映射,相信学过位图的都可以理解。
inode Bitmap:inode位图,标识inode是否被使用。
复习的时候再看看超级块-----这句话给作者看的
2.2 文件在磁盘中的操作
我通过对文件的增、删、查、改,带领大家熟悉上面知识。
查看文件的inode编号:
bash
ls -li
还可以使用stat 文件名查看更多信息,大家自己去了解一下。
创建文件:
创建文件时,将文件存储在哪个分区,路径会帮助我们,这里我们就不关心了,首先操作系统根据,超级块中的信息,剩余inode和bolck较多的组,遍历该组的inode Bitmap,得到未被使用的inode编号,找到该inode将文件属性存储,并将对应位置位图置1,再遍历Block Bitmap得到未被使用的块编号,找到对应块,将文件内容存储,并将对应位置位图置1,再将对应的块编号,存入该文件inode的数组中。
读取文件:
读取文件首先查找文件,拿到该文件的inode编号,根据编号找到对应的分组(LBA->CHS ),找到inode中存储块编号的数组,那到块编号,读取块数据。
修改文件:
首先拿到该文件的inode编号,根据编号找到对应的分组(LBA->CHS ),找到inode中存储块编号的数组,那到块编号,修改数据。
删除文件:
首先拿到该文件的inode编号,根据编号找到对应的分组(LBA->CHS ),找到inode中存储块编号的数组,那到块编号,使用块编号,将块位图对应位置置0(表示未被使用),通过inode编号将inode位图置0。
通过上面的方法我们就可实现文件的增、删、查、改了,但是我们还面临一个问题,操作系统该如何来获取文件的inode编号呢?
我们首先来看这样一个问题:

上面我们说,操作系统在磁盘访问文件不通过文件名,是通过inode进行的,但现在为什么操作系统不认识它呢?
要回答这个问题我们就得思考一下,目录文件在磁盘中存储的内容是什么了,在磁盘中目录文件存储的其实是,该目录下的文件名与文件inode编号的映射关系,当在用户访问文件时,操作系统就会根据当前目录的inode编号,找到当前目录的内容,从而通过映射关系找到对应文件的inode编号,这样就可以得到用户要访问文件的inode,但是当前目录文件的inode又从哪来呢,当然是通过它的上级目录了,就像这样一直索引,知道找到操作系统启动时固定的,目录inode编号,然后逐级返回。这个过程为路径解析,但是由于太过复杂影响效率,所以操作系统会将常用路径解析后缓存在dentry缓存。

这样我们就将这个问题完美解决了。