最近在接手一个中型项目的服务器运维工作,需要同时管理多台 Linux 主机,用于部署前端、后端、数据库、日志服务等。
原本以为只要用 SSH + 命令脚本就能搞定,但真正上线后,连续踩了不少坑,今天总结一下我遇到的三个典型问题,顺便分享一些实践经验,供需要多机运维的朋友参考。

坑一:每台服务器都要单独维护,工作量极其繁琐
最开始的做法非常原始:每台服务器都通过 SSH 登录,单独安装服务、配置防火墙、修改 Nginx 配置文件......一台还好,三台还能接受,到第六台时我脑子嗡了。
- 每次要部署新版服务,得逐台执行命令
- 配置文件不一致,容易"同一套服务表现不同"
- 故障排查分散在不同机器上,定位极其困难
解决方案: 我使用一款支持"集中式多机管理"的 运维面板工具 ,配置一次,可以批量部署和统一管理所有服务器。实际体验过程中,运维效率有了质的提升,也更标准化。
例如,当我需要给每台服务器安装 Openresty应用 时,我只需要在应用商店选择需要安装的应用和部署的主机即可,全程可视化操作界面操作,快捷高效且直观。 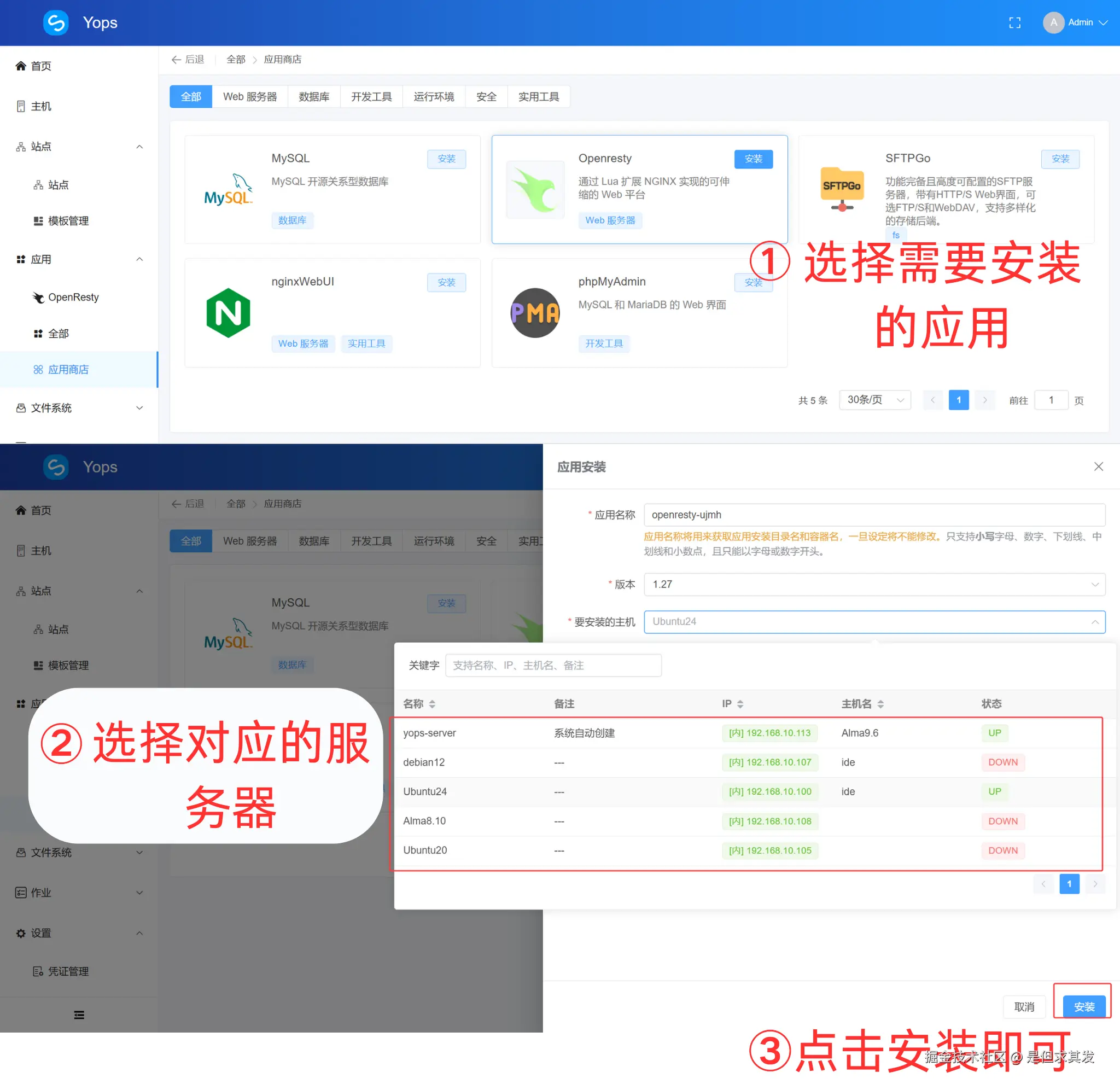
坑二:端口与服务状态混乱,服务挂了都不知道
有一次生产环境的 docker 容器挂了,直到第二天开发同事反馈才发现。原因很简单:没有配置有效的服务监控机制。
ps -ef | grep不是监控systemctl status手动查毫无意义- 没有主动告警,出了问题只能靠"猜"
你通过以下命令一个个去排查,费时费力
bash
uptime #显示系统运行时间、登录用户数及1/5/15分钟平均负载
top #实时查看整体及进程级CPU占用
free -h #以易读格式显示内存总量、已用、空闲及缓存
df -h #查看文件系统磁盘空间(挂载点、总量、已用、可用)
du -sh /path #统计目录/文件磁盘占用(如 du -sh /var/log)
docker ps -a #查看所有容器状态(运行/停止)
netstat -tunlp #列出监听端口、协议及进程
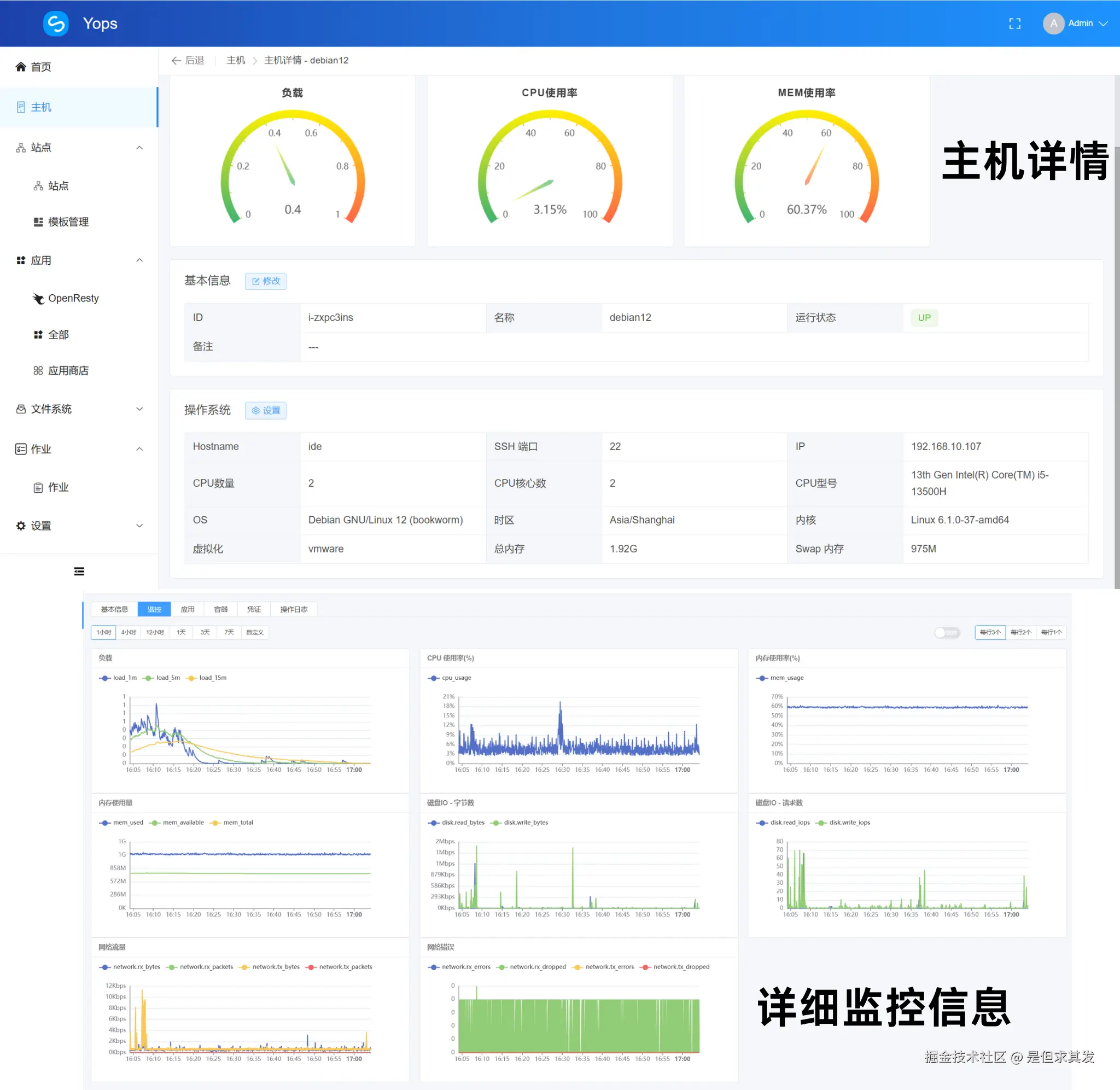
lsof -i :端口号 #查询指定端口占用进程解决方案: 通过部署的 Yops运维面板 对以下几个主机信息进行监控:
- 应用 / 站点 / 主机 运行状态
- 关键端口(80, 443, 3306 等)监听状态
- 磁盘占用 / 内存负载 / CPU 占用
这些信息被统一汇总到运维面板的仪表盘上,有异常可以一眼看到,并通过邮件或消息实时提醒。

 容器列表除了对容器的基础监控以外,还可以对容器进行一些基本的操作,如启停、日志、删除等
容器列表除了对容器的基础监控以外,还可以对容器进行一些基本的操作,如启停、日志、删除等 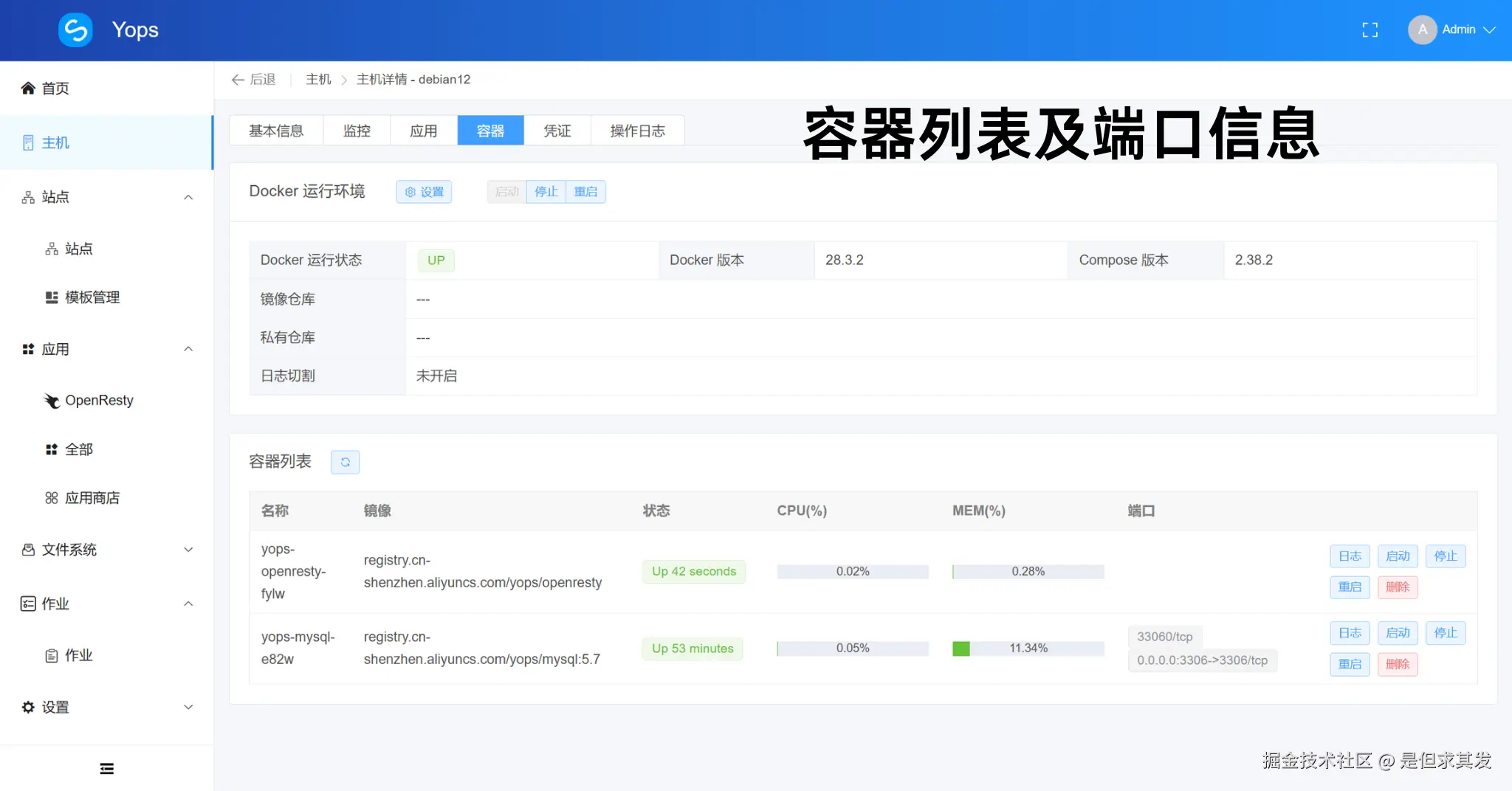
坑三:权限分散、操作不可追溯,安全风险大
多机运维一旦涉及多人协作,比如研发人员需要进服务器排查问题,就会暴露一堆潜在风险:
- 研发人员更改了关键目录,完全无法追踪是谁做的
- 临时开放权限,忘记回收,成为安全隐患
- sudo/root 操作缺乏限制,日志缺失
解决方案:
- 所有服务器统一由面板授权操作,禁用 root 密码登录
- 针对每一次远程操作都记录审计日志(包括所属模块、操作类型、时间、关联IP、详情等)
- 对重要目录采取监控措施,每次变更前后都进行备份,一键恢复即可
审计日志可根据操作时间、类型、模块进行快速查询,方便溯源 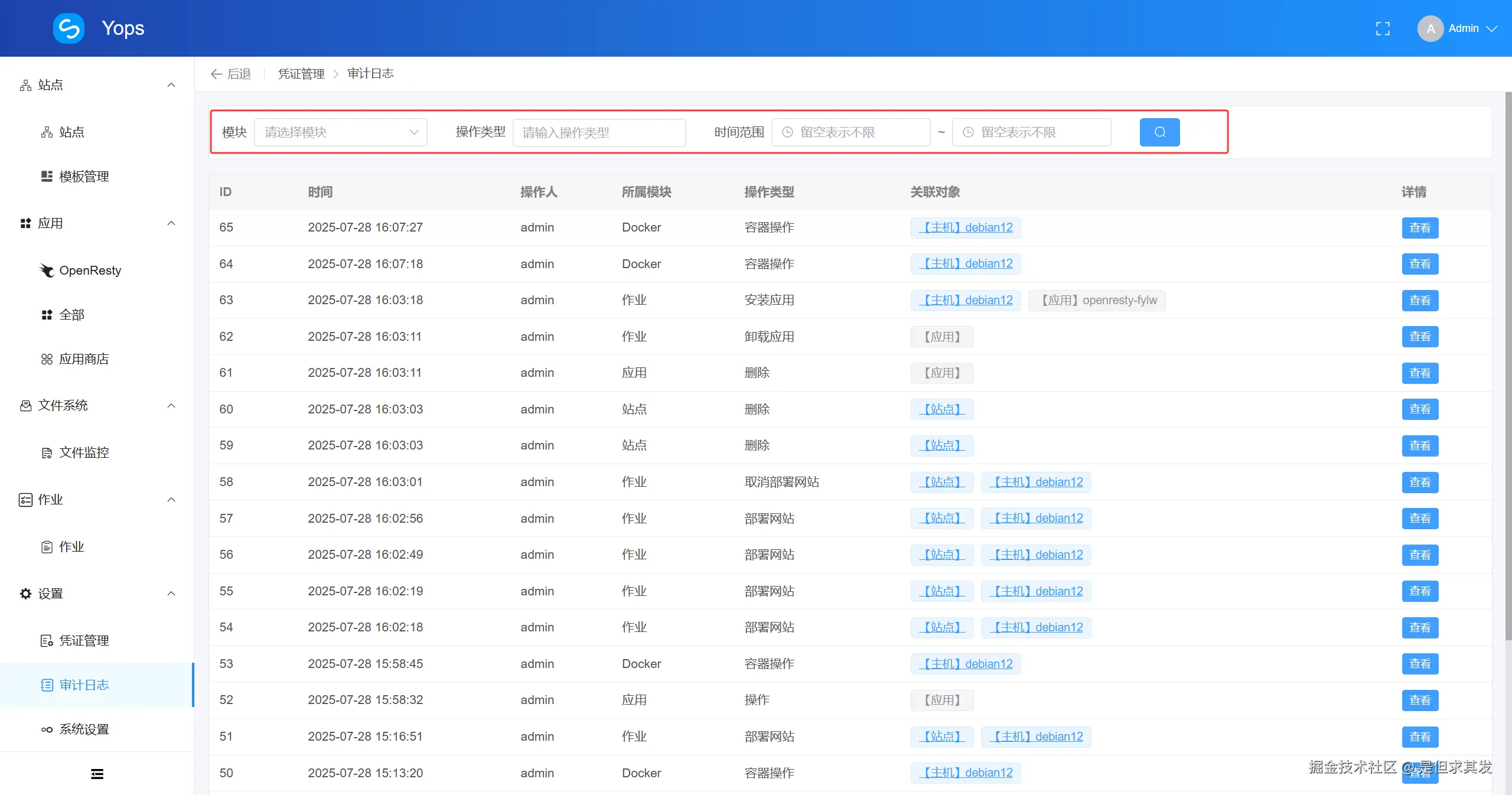
文件监控计划检测到新增文件以后,会告知文件变更内容,并进行备份 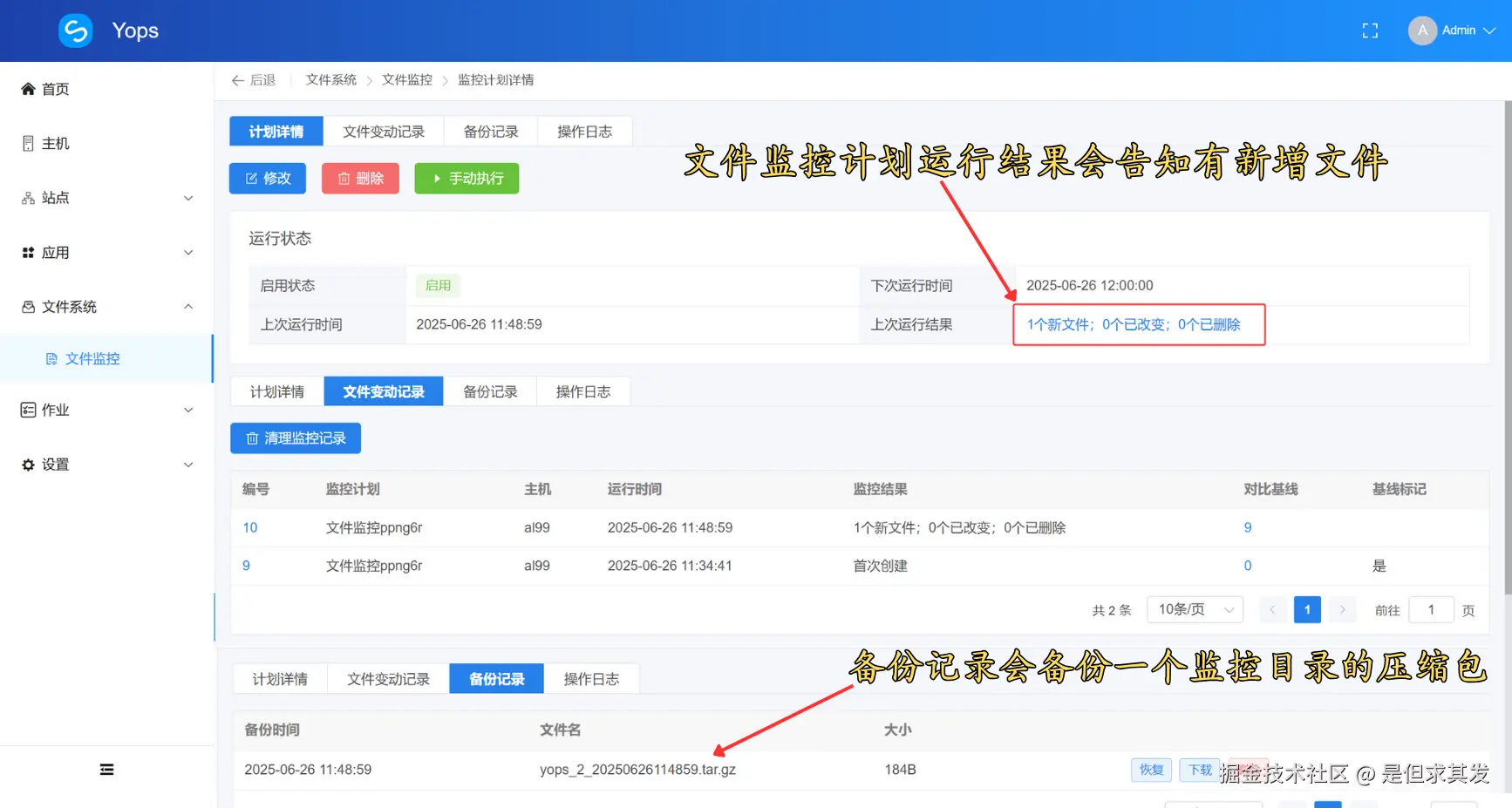
文件监控计划检测到文件删除以后,会告知文件变更内容,并进行备份 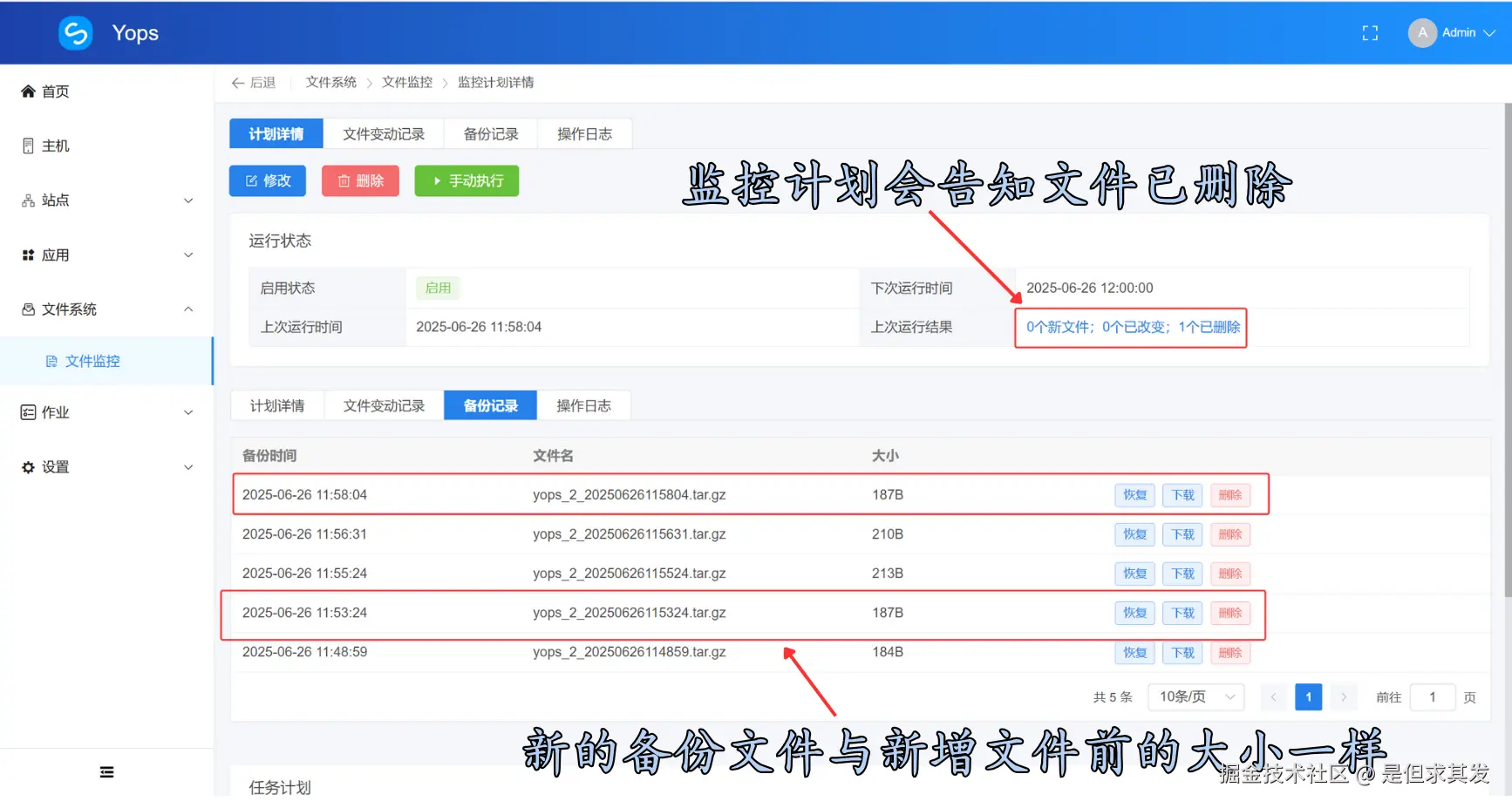
文件监控计划检测到文件变更以后,会告知文件变更内容,并进行备份 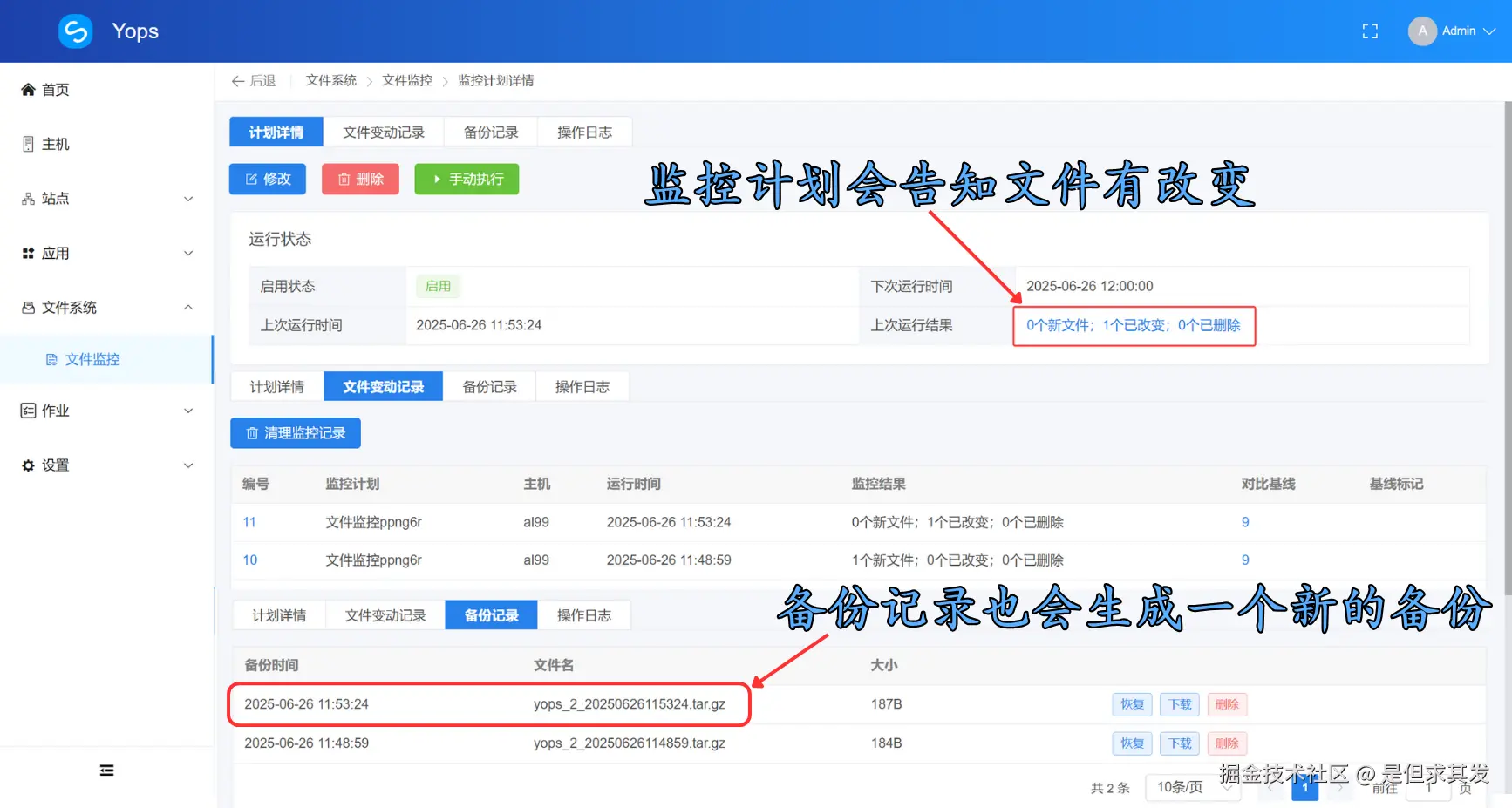
✍️ 一些感想
多机运维不是主机数量变多那么简单,而是成倍放大的配置、监控、安全、协作问题。不能停留在手动 SSH 的思维做事,效率低下的同时还容易犯错误,能使用现成工具的情况下尽量使用工具。
我现在基本养成了几个习惯:
- 能用面板集中处理的,就不手动逐台做,因为面板审计日志能记录操作行为
- 所有服务都要设监控 + 异常告警
- 操作留痕,权限最小化管理
这些不是高级技巧,但是真能保命。
🌱 工具用得早,用得对,才能让你真正从繁琐中解放出来。