世界重塑,你我重逢
------ 25.4.3
引言:大模型训练两大问题
**1.效率问题:**数据量大,如何快速完成训练
**2.显存问题:**模型太大,如何在GPU上完成运算
一、并行训练
1.方式一:数据并行 DP
① 复制模型到多个GPU
将模型复制到多块GPU上,然后将数据切分成多份,每份数据传入一个GPU,然后各自并行进行数据的计算,反向传播,得到当前GPU上的梯度,然后将多块GPU上计算的梯度传入其中一个GPU上,在这块GPU上将多块GPU计算得到的梯度求平均,再反向传播进行梯度的更新,然后将更新后的模型反传复制到其余几块GPU上,实现所有GPU上模型的更新
② 各自计算梯度后累加 ,再反传更新
分散到多块GPU上进行并行计算效率要比使用一块GPU计算快得多
③ 需要单卡就能训练整个模型(显存够大)
**前提:**每块GPU都有能力单独对一个模型进行训练

2.方式二:模型并行 PP
① 将模型的不同层放在不同的GPU上
将模型的不同层放在不同的GPU上,前向计算时,将x传入第一块卡,将计算完成后的结果通讯传入第二层,第二层再传入第三层,以此类推,直到传入最后一块卡上的最后一层,与真实值计算Loss,反向传播,在每一层求偏导进行对应权重的更新
② 解决单块卡不够大的问题(模型比显存大)
单块卡支持不了的大模型可以拆分多层放在多块GPU上,解决单块卡不够大的问题
③ 需要更多的通讯时间
**代价:**卡之间互相传输数据,需要更多的通讯时间
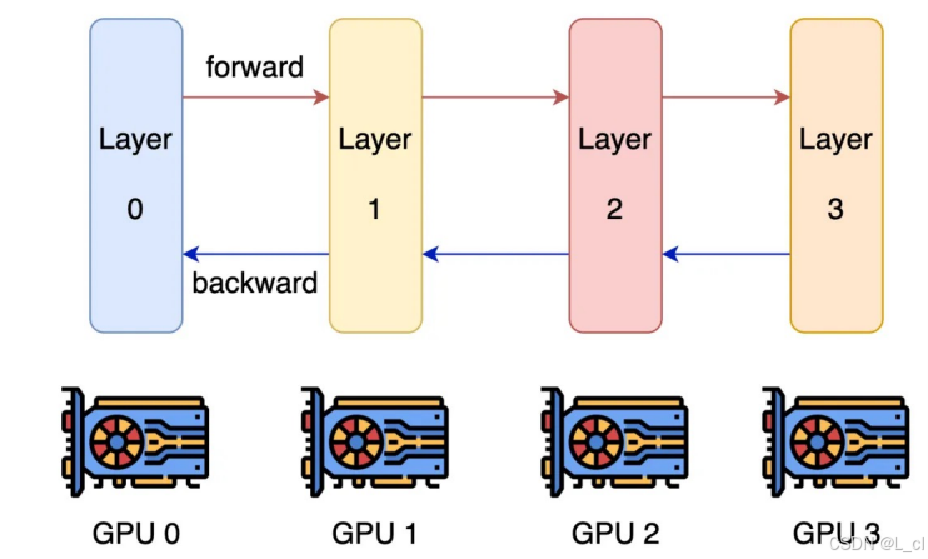
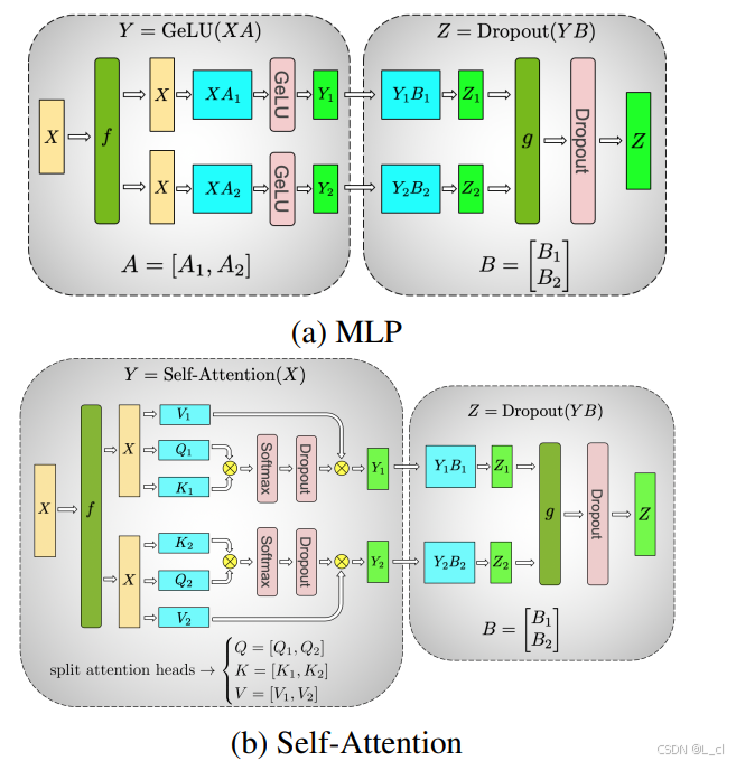
3.方式三:张量并行 TP
① 将张量划分到不同GPU上进行运算
将张量矩阵进行切分,切分后的每一个部分小张量矩阵传入不同的GPU上进行张量的运算,然后将每个GPU上计算的小张量矩阵最终进行相加 / 拼接,得到的张量矩阵与直接两个大矩阵相乘得到的结果一致
② 进一步减少对单卡显存的需求
每块GPU上只需要计算切分后的小矩阵,而不需要计算完整的大型矩阵,
③ 需要更多的数据通讯
**代价:**拆分矩阵传入不同的GPU,需要更多的数据通讯时间

在tranformer多头机制中,每个头在一个GPU上进行计算
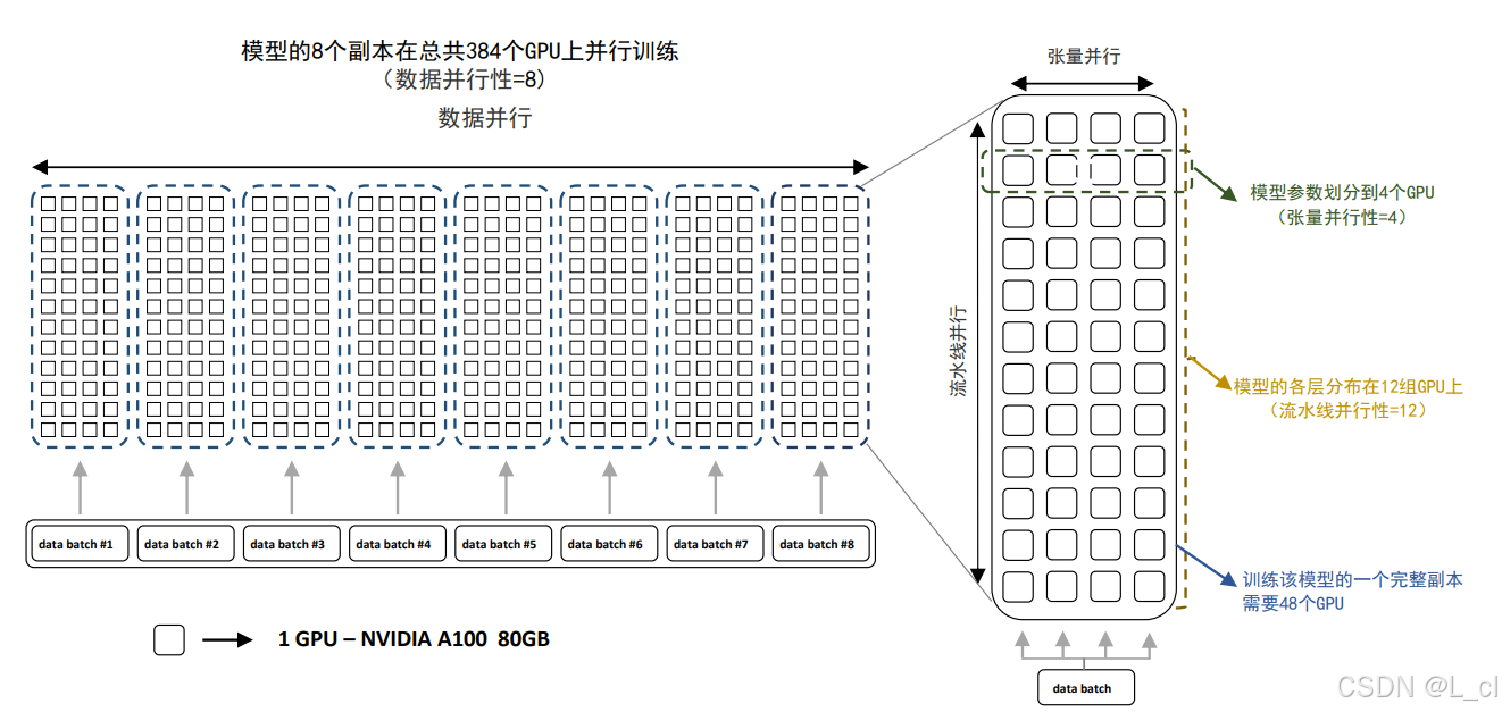
4.方式四:混合并行
BLOOM模型训练时采用的并行计算结构
并行流程
流程:数据并行 DP ------> 模型并行 PP ------> 张量并行 TP
采用数据并行 DP ,使用8个副本模型,将数据分为8份,分别传入8个副本模型,其中每一份副本模型使用48个GPU训练,将模型的各个层进行模型并行 PP ,分布在12组GPU上,再采用张量并行 TP,每层的模型参数再划分到4个GPU上,进行张量计算
多机和多卡
一台电脑上可以装多个卡,最多插卡数与槽位有关,而一个机器上的插卡数有限制,不足以训练一个大的模型,所以我们使用多台机器,机器间的传输也需要消耗时间,所以所谓的集群、机房也就是将多台机器放在一起,尽可能降低其延迟,提升其训练效率
二、混合精度
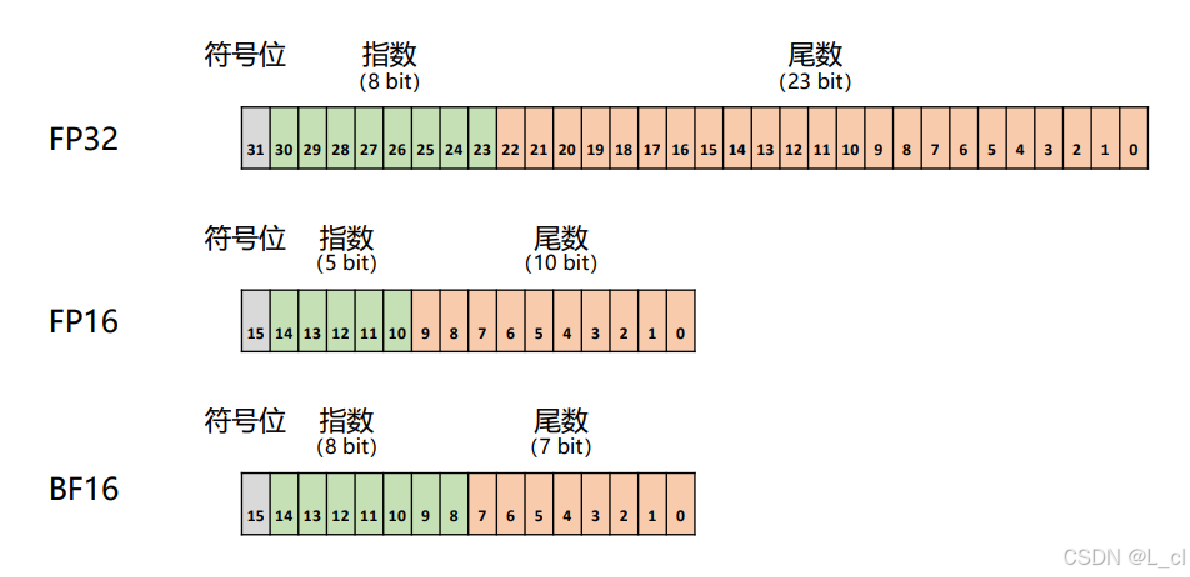
1.浮点数类型
1T = 1024GB;1GB = 1024MB;1MB = 1024KB;1KB = 1024B;1B(字节) = 8 bit
**FP32:**32位(比特)单精度浮点数,4字节
**FP16:**16位(比特)半精度浮点数,2字节
**BF16:**脑浮点 16 位(比特)半精度浮点数,Brain Floating Point 16,2字节
2.浮点数表示方法
M是尾数,E是指数
尾数越多,值表示的越精确
指数越多,值所能表示的范围越大
总位数越多,该数字占空间越大(1字节=8bit)

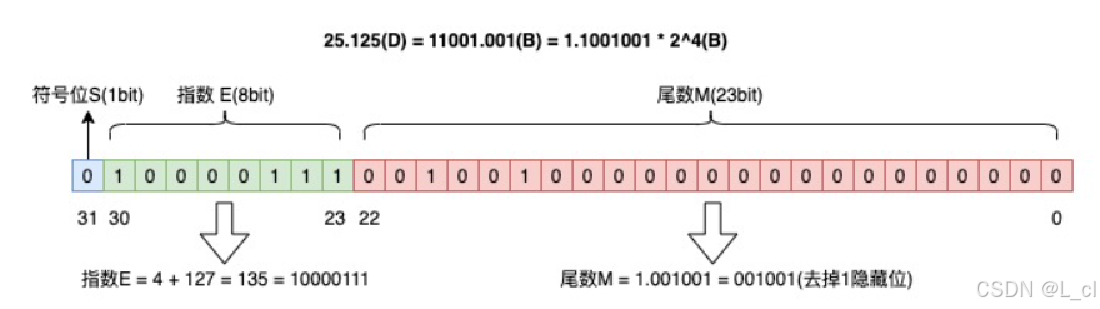
例:25.125
D = 十进制 B = 二进制
**整数部分:**25(D)= 11001(B)
**小数部分:**0.125(D)= 0.001(B)
**二进制科学计数法表示:**25.125(D)= 11001.001(B)= 1.1001001 * 2 ^ 4(B)
**符号位:**S = 0
**尾数:**M = 001001(去掉1,隐藏位)
**指数:**E = 4 + 127(因为要减去中间数127)= 135(D)= 10000111(B)
3.浮点数精度损失
将0.2(十进制)转化为二进制数:
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
...
0.2(D) = 0.00110...(B)
由于浮点数尾数位数有限,最后只能截断,导致精度损失
例如: 0.00..(800个0)..01 + 1 = 1
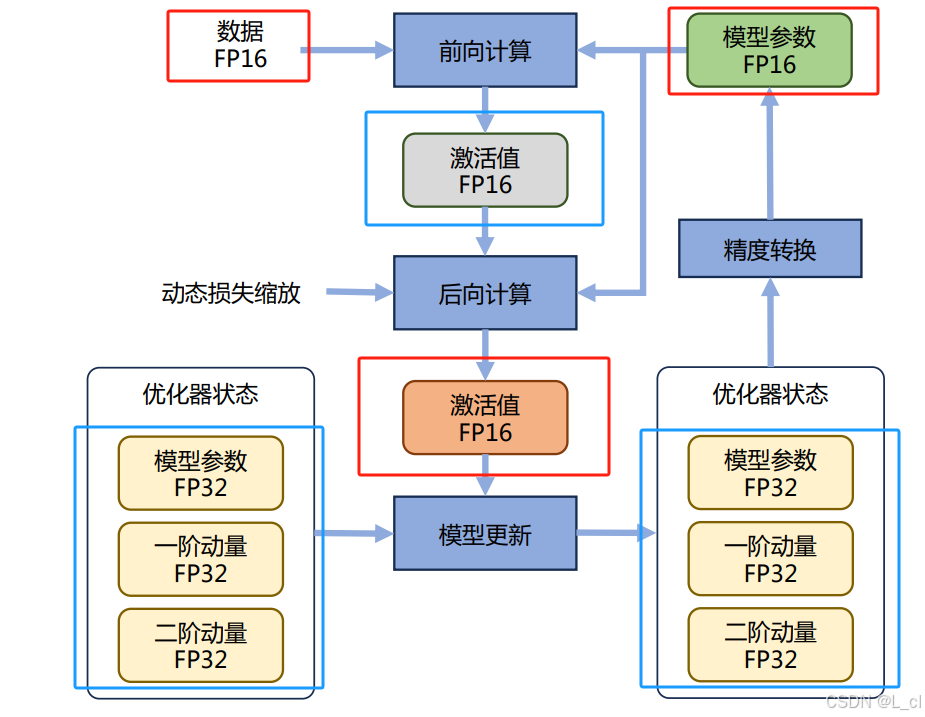
4.混合精度训练
在模型训练过程中,在梯度参数优化时,我们一般需要精度要求高一点;而在前向计算时,参数精度的要求可以降低一些;所以在一个模型训练过程中,可以采用混合精度
三、deepspeed 零冗余优化器 ZeRO
1.ZeRO
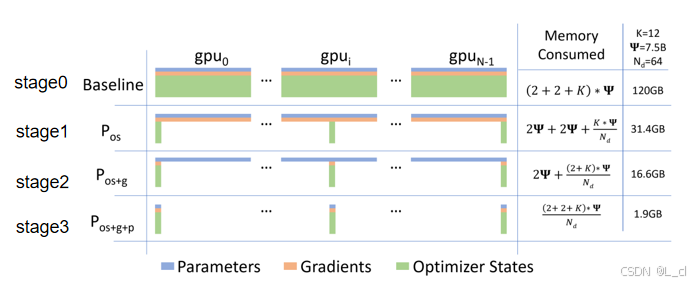
ZeRO中的四种设置,只能选一种
stage0: 最基础的模型并行,Parameters:存储模型自身的权重、Gradients:存储模型计算的梯度、Optimizer State:存储优化器信息
stage1: 将权重信息最大的部分(Optimizer State)分散到多个GPU上进行存储,每个GPU需要的显存资源就下降了
stage2: 将Optimizer State正常计算,将Gradients和Optimizer State,分散到多个GPU上进行存储,每个GPU需要的显存资源就下降了
stage3: 将Optimizer State、Gradients和Optimizer State都分散到多个GPU上进行存储,每个GPU需要的显存资源就下降了
代价: 付出的通讯时间(速度)
2.ZeRO-offload
把一部分计算放到内存 中,用CPU计算,目的是解决显存不足问题
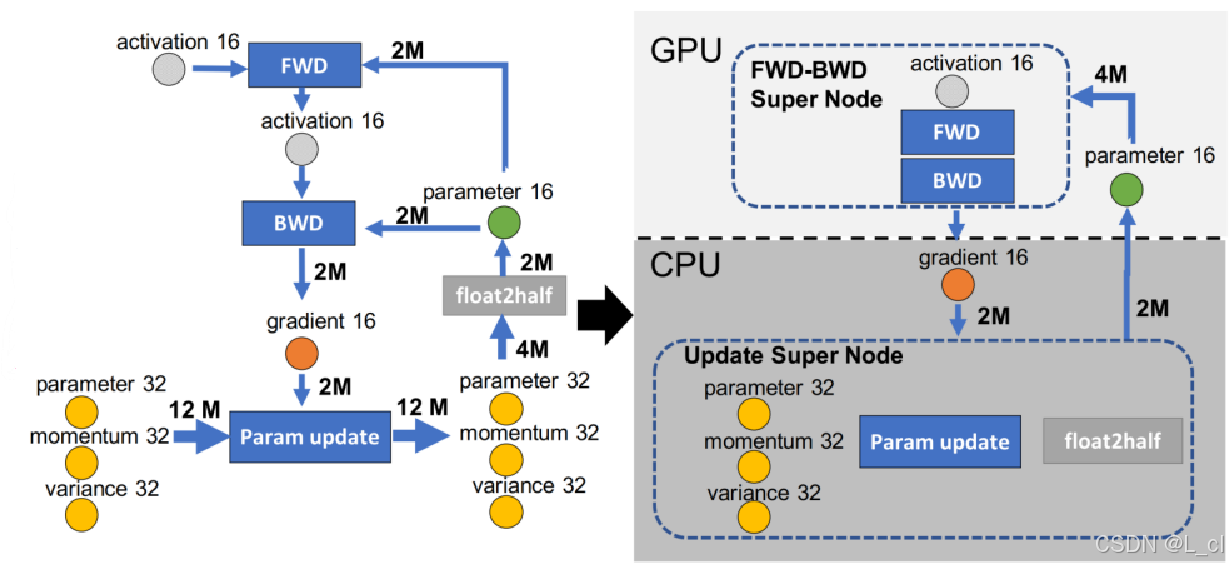
3.策略对比
① 训练速度:
Stage 0 > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads
② 显存效率(指固定显存下,能够训练的模型大小):
Stage 0 < Stage 1 < Stage 2 < Stage 2 + offload < Stage 3 < Stage 3 + offloads
四、PEFT微调 Parameter-Efficient Fine-Tuning
当训练整个大模型不能实现时,可以采取的一种策略
通过最小化微调参数的数量缓解大型预训练模型的训练成本
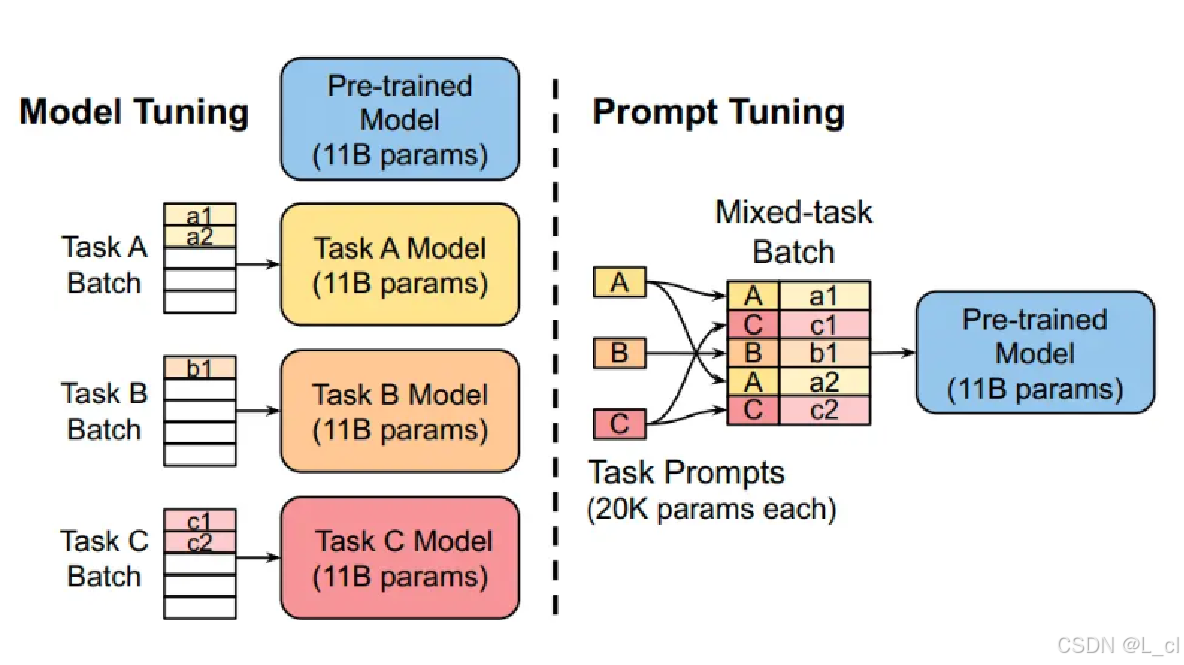
1.Prompt Tuning 提示词调整
传统上,对预训练语言模型进行微调时,需要更新模型的所有参数,这在数据量和计算资源方面成本较高。Prompt Tuning 提出了一种新的思路,它通过在输入文本中加入特定的提示(prompt),并仅对这些提示相关的参数进行调整,而保持预训练模型的大部分参数不变。这样,在不同的下游任务中,模型只需学习如何利用这些精心设计的提示来适配任务,从而大大减少了需要训练的参数量
工作原理
提示构建:设计与任务相关的文本提示,这些提示通常插入到输入文本中。例如,在情感分类任务中,提示可以是 "这段文本表达的情感是:填空",其中 "填空" 位置预期模型根据文本内容填入 "积极""消极" 等情感类别。
参数调整:在微调过程中,只有提示相关的参数(如提示向量)会被更新。这些提示向量可以被视为可学习的嵌入,模型在训练过程中学习如何利用这些提示更好地完成任务。而预训练模型的主体参数保持冻结,不参与梯度更新。通过这种方式,在不同任务间切换时,仅需调整少量的提示参数,就能快速适配新任务。
2.Prefix-tuning 前缀调整
传统的预训练模型微调方法需要更新模型的全部参数,计算成本高且可能导致过拟合。Prefix - tuning 则引入了可训练的前缀(prefix),该前缀被插入到模型的输入层或中间层,模型在微调过程中仅更新这些前缀的参数,而预训练模型的主体参数保持不变。这种方式使得模型能够在不同下游任务间快速切换,同时大大降低了微调的计算开销。
工作原理
前缀构建 :在 Transformer 架构的模型中,Prefix - tuning 在前馈神经网络(FFN)和多头注意力机制(Multi - Head Attention)模块前插入可训练的前缀向量。这些前缀向量可以看作是一种任务特定的软提示(soft prompt),其维度与输入的隐藏状态维度相同。例如,在一个由多层 Transformer 块组成的模型中,每个块的输入前都可以添加前缀向量。
训练过程 :在微调阶段,只有前缀向量的参数会通过反向传播进行更新,而预训练模型的权重保持冻结。模型通过学习前缀向量来调整其对输入数据的处理方式,从而适应特定的下游任务。当前缀向量与输入数据相结合后,模型像往常一样进行前向传播计算,生成任务相关的输出(如文本分类的类别、问答任务的答案等)。在反向传播过程中,梯度仅会传播到前缀向量的参数上,对其进行更新优化,以最小化任务的损失函数。

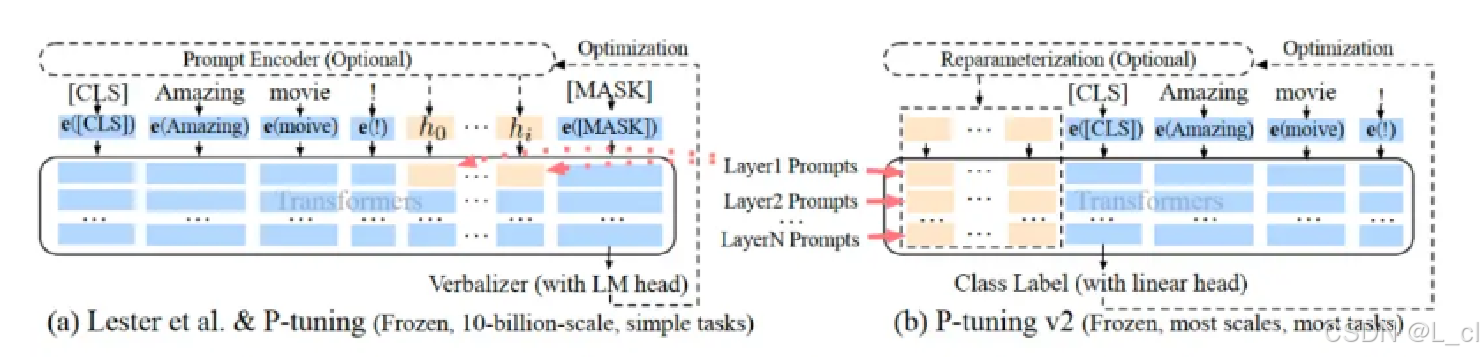
3.P-tuning & P-tuning v2
P - tuning(Prompt Tuning 的一种变体)是一种针对预训练语言模型(PLM)的参数高效微调技术,旨在通过优化离散的文本提示(prompt)来更好地适配下游任务,而不是像传统微调那样更新整个模型的参数。它的核心思想是将提示视为可学习的变量,通过调整这些提示来引导预训练模型完成特定任务。
工作原理
提示构造 :在输入文本前添加一系列特殊的提示词,这些提示词构成一个文本模板。例如,在情感分类任务中,模板可能是 "CLS 这段文本表达了 MASK 情感 SEP 文本内容 SEP",其中 "MASK" 是需要模型预测的情感类别位置,而 "CLS" 和 "SEP" 是 BERT 等模型中的特殊标记。
提示优化 :与传统的 Prompt Tuning 不同,P - tuning 不是直接优化连续的嵌入向量,而是通过在模型中引入一个小型的神经网络(如多层感知机 MLP)来生成离散的提示词。这个小型神经网络的参数是可训练的,在微调过程中,通过反向传播更新这些参数,使得生成的提示词能够引导模型在下游任务上取得更好的性能。预训练模型的主体参数在微调过程中通常保持不变。
P - tuning v2 是对 P - tuning 的改进版本,进一步提升了参数高效微调的性能和灵活性,在保持低参数量微调的同时,增强了模型对复杂任务的适应能力。
工作原理
多段提示与多模态优化 :P - tuning v2 在模型的多个层都引入了可学习的提示,而不仅仅是在输入层。这些提示可以看作是不同层次的 "软提示",它们能够在模型的不同深度影响信息的处理。同时,它采用了一种多模态优化策略,将离散提示词的优化与连续的提示嵌入优化相结合。具体来说,除了像 P - tuning 那样通过小型神经网络生成离散提示词外,还对这些提示词对应的嵌入向量进行微调,从而更全面地优化提示信息在模型中的传播和利用。
提示共享与任务特定调整 :在多个任务之间,可以共享一部分提示参数,同时针对每个具体任务,也有少量特定的提示参数进行调整。这种方式既利用了任务之间的共性,减少了总的参数量,又能让模型针对不同任务进行个性化的优化。
4.Adapter
Adapter 的核心思想是在预训练模型的基础上,针对每个下游任务添加少量特定的参数层(即适配器),而保持预训练模型的大部分参数固定不变。这些适配器可以看作是轻量级的插件,它们学习任务特定的表示,使得模型能够在不同任务间快速切换,同时显著减少了每个任务所需训练的参数量。
工作原理
适配器结构 :通常在 Transformer 架构的模型中,适配器被插入到 Transformer 层内的特定位置,比如在多头注意力机制(Multi - Head Attention)和前馈神经网络(FFN)之间。适配器一般由两个全连接层组成,一个是降维层,将高维的特征向量映射到一个低维空间,另一个是升维层,再将低维向量映射回原始维度。这种结构设计使得适配器能够以较少的参数捕捉任务特定的信息。
训练过程 :在微调阶段,只有适配器的参数会被更新,预训练模型的主体参数保持冻结。模型在处理输入数据时,先经过预训练模型的常规层,提取通用的特征表示,然后这些特征进入适配器进行任务特定的变换。适配器通过反向传播算法,根据下游任务的损失函数来更新自身参数,学习如何对预训练特征进行调整以适应

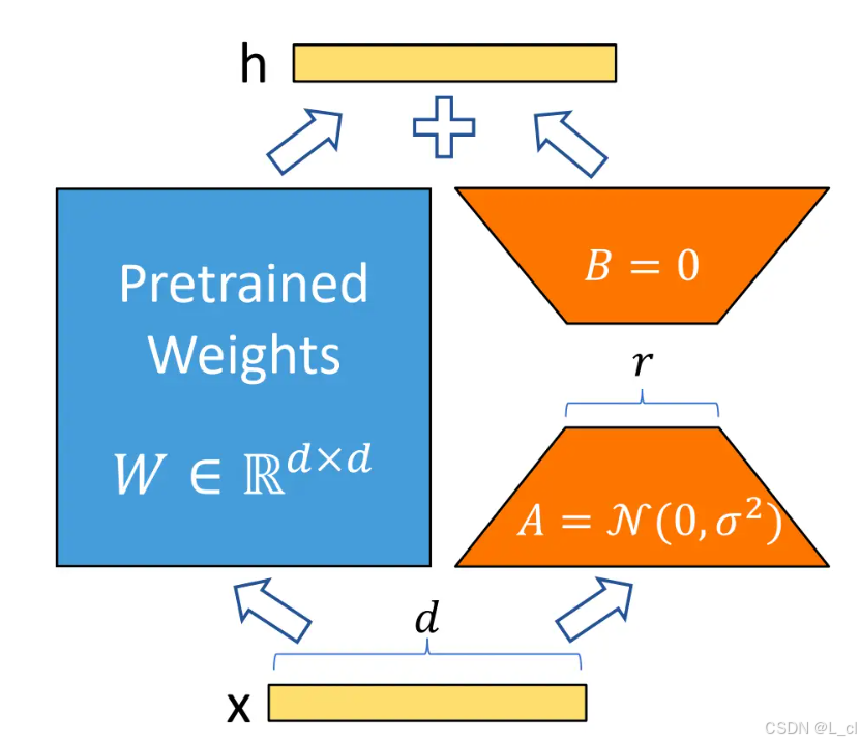
5.LoRA
LoRA(Low - Rank Adaptation of Large Language Models)即大语言模型的低秩自适应,是一种在微调大语言模型时显著减少可训练参数的技术。
原理
在传统的微调过程中,大语言模型(LLMs)通常需要更新所有参数,计算成本高昂。LoRA 则另辟蹊径,它在预训练模型的特定层插入可训练的低秩矩阵,通过调整这些低秩矩阵来适配下游任务,而预训练模型的原始权重保持不变。
加入一些低秩矩阵,通过在低秩矩阵间计算减少预训练模型训练的计算量,LoRA可以在任意线性层的位置增加,通过LoRA矩阵将参数量维度先减小,再放大,跳过预训练模型的计算过程,减小计算量
Deepseek在训练时也使用了LoRA技术
五、文本分类任务 ------ LoRA 🚀
1.数据文件
通过网盘分享的文件:文本分类任务+LoRA
链接: https://pan.baidu.com/s/1UzKro6AriMUEhcTI7Y1voQ?pwd=h5qq 提取码: h5qq
--来自百度网盘超级会员v3的分享
2.模型配置文件 config.py
**model_path:**指定模型输出的路径。训练完成后,模型的相关文件(如权重文件等)会保存到这个路径下。
**train_data_path:**训练数据的文件路径。指向了一个 JSON 格式的文件,该文件包含用于训练模型的数据。
**valid_data_path:**验证数据的文件路径。与训练数据类似,它指向用于验证模型性能的数据文件,通常在训练过程中,会使用验证数据来评估模型是否过拟合以及调整模型超参数。
**vocab_path:**词汇表文件的路径。词汇表定义了模型能够处理的所有词元(token)。模型在处理文本时,会将文本中的词映射到词汇表中的相应词元。
**model_type:**指定所使用的模型类型。
**max_length:**输入文本的最大长度。
**hidden_size:**模型隐藏层的维度大小。
**kernel_size:**卷积核的大小。
**num_layers:**模型的层数。对于具有多层结构的模型(如多层的 Transformer 层或循环神经网络层等),num_layers 确定了模型的深度。
**epoch:**训练模型时数据遍历的轮数。每一轮遍历,模型会对整个训练数据集进行一次完整的前向传播和反向传播计算,更新模型参数。
**batch_size:**每次训练时使用的样本数量。
**tuning_tactics:**微调策略。
**pooling_style:**池化方式。
**optimizer:**优化器的选择。
**learning_rate:**学习率。它控制着优化器在每次参数更新时步长的大小。
**pretrain_model_path:**预训练模型的路径。
**seed:**随机数种子。设置固定的随机数种子可以使实验具有可重复性。
python
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "output",
"train_data_path": r"F:\人工智能NLP\NLP\Day12_LLM通用能力评价方式\训练大模型\peft训练\data/train_tag_news.json",
"valid_data_path": r"F:\人工智能NLP\NLP\Day12_LLM通用能力评价方式\训练大模型\peft训练\data/valid_tag_news.json",
"vocab_path": "chars.txt",
"model_type": "bert",
"max_length": 20,
"hidden_size": 128,
"kernel_size": 3,
"num_layers": 2,
"epoch": 10,
"batch_size": 64,
"tuning_tactics": "lora_tuning",
# "tuning_tactics":"finetuing",
"pooling_style": "max",
"optimizer": "adam",
"learning_rate": 1e-3,
"pretrain_model_path": r"F:\人工智能NLP\NLP资料\week6 语言模型\bert-base-chinese",
"seed": 987
}3.数据加载文件 loader.py
python
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.index_to_label = {0: '家居', 1: '房产', 2: '股票', 3: '社会', 4: '文化',
5: '国际', 6: '教育', 7: '军事', 8: '彩票', 9: '旅游',
10: '体育', 11: '科技', 12: '汽车', 13: '健康',
14: '娱乐', 15: '财经', 16: '时尚', 17: '游戏'}
self.label_to_index = dict((y, x) for x, y in self.index_to_label.items())
self.config["class_num"] = len(self.index_to_label)
if self.config["model_type"] == "bert":
self.tokenizer = BertTokenizer.from_pretrained(config["pretrain_model_path"])
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
tag = line["tag"]
label = self.label_to_index[tag]
title = line["title"]
if self.config["model_type"] == "bert":
input_id = self.tokenizer.encode(title, max_length=self.config["max_length"], pad_to_max_length=True)
else:
input_id = self.encode_sentence(title)
input_id = torch.LongTensor(input_id)
label_index = torch.LongTensor([label])
self.data.append([input_id, label_index])
return
def encode_sentence(self, text):
input_id = []
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
input_id = self.padding(input_id)
return input_id
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id):
input_id = input_id[:self.config["max_length"]]
input_id += [0] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dict
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
if __name__ == "__main__":
from config import Config
dg = DataGenerator("valid_tag_news.json", Config)
print(dg[1])4.模型文件 model.py
python
import torch.nn as nn
from config import Config
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoModel
from torch.optim import Adam, SGD
TorchModel = AutoModelForSequenceClassification.from_pretrained(Config["pretrain_model_path"])
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)5.模型评估文件 evaluate.py
python
# -*- coding: utf-8 -*-
import torch
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = {"correct": 0, "wrong": 0} # 清空上一轮结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_ids)[0]
self.write_stats(labels, pred_results)
acc = self.show_stats()
return acc
def write_stats(self, labels, pred_results):
# assert len(labels) == len(pred_results)
for true_label, pred_label in zip(labels, pred_results):
pred_label = torch.argmax(pred_label)
# print(true_label, pred_label)
if int(true_label) == int(pred_label):
self.stats_dict["correct"] += 1
else:
self.stats_dict["wrong"] += 1
return
def show_stats(self):
correct = self.stats_dict["correct"]
wrong = self.stats_dict["wrong"]
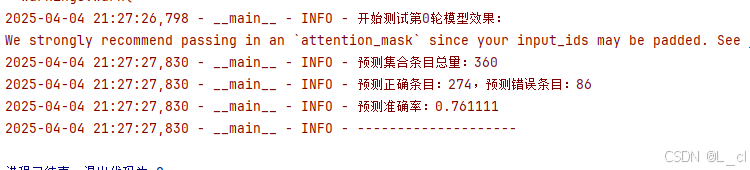
self.logger.info("预测集合条目总量:%d" % (correct +wrong))
self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))
self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))
self.logger.info("--------------------")
return correct / (correct + wrong)6.模型训练文件 main.py
python
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import torch.nn as nn
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, \
PromptTuningConfig, PrefixTuningConfig, PromptEncoderConfig
#[DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def main(config):
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
#加载训练数据
train_data = load_data(config["train_data_path"], config)
#加载模型
model = TorchModel
#大模型微调策略
tuning_tactics = config["tuning_tactics"]
if tuning_tactics == "lora_tuning":
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "key", "value"]
)
elif tuning_tactics == "p_tuning":
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prompt_tuning":
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prefix_tuning":
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = get_peft_model(model, peft_config)
# print(model.state_dict().keys())
if tuning_tactics == "lora_tuning":
# lora配置会冻结原始模型中的所有层的权重,不允许其反传梯度
# 但是事实上我们希望最后一个线性层照常训练,只是bert部分被冻结,所以需要手动设置
for param in model.get_submodule("model").get_submodule("classifier").parameters():
param.requires_grad = True
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
#加载优化器
optimizer = choose_optimizer(config, model)
#加载效果测试类
evaluator = Evaluator(config, model, logger)
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
optimizer.zero_grad()
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
output = model(input_ids)[0]
loss = nn.CrossEntropyLoss()(output, labels.view(-1))
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
acc = evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "%s.pth" % tuning_tactics)
save_tunable_parameters(model, model_path) #保存模型权重
return acc
def save_tunable_parameters(model, path):
saved_params = {
k: v.to("cpu")
for k, v in model.named_parameters()
if v.requires_grad
}
torch.save(saved_params, path)
if __name__ == "__main__":
main(Config)7.模型预测文件
python
import torch
import logging
from model import TorchModel
from peft import get_peft_model, LoraConfig, PromptTuningConfig, PrefixTuningConfig, PromptEncoderConfig
from evaluate import Evaluator
from config import Config
logging.basicConfig(level=logging.INFO, format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
#大模型微调策略
tuning_tactics = Config["tuning_tactics"]
print("正在使用 %s"%tuning_tactics)
if tuning_tactics == "lora_tuning":
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "key", "value"]
)
elif tuning_tactics == "p_tuning":
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prompt_tuning":
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prefix_tuning":
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
#重建模型
model = TorchModel
# print(model.state_dict().keys())
# print("====================")
model = get_peft_model(model, peft_config)
# print(model.state_dict().keys())
# print("====================")
state_dict = model.state_dict()
#将微调部分权重加载
if tuning_tactics == "lora_tuning":
loaded_weight = torch.load('output/lora_tuning.pth', weights_only=True)
elif tuning_tactics == "p_tuning":
loaded_weight = torch.load('output/p_tuning.pth', weights_only=True)
elif tuning_tactics == "prompt_tuning":
loaded_weight = torch.load('output/prompt_tuning.pth', weights_only=True)
elif tuning_tactics == "prefix_tuning":
loaded_weight = torch.load('output/prefix_tuning.pth', weights_only=True)
print(loaded_weight.keys())
state_dict.update(loaded_weight)
#权重更新后重新加载到模型
model.load_state_dict(state_dict)
#进行一次测试
if torch.cuda.is_available():
model = model.cuda()
evaluator = Evaluator(Config, model, logger)
evaluator.eval(0)