文章目录
- 每日一句正能量
- [第4章 Spark SQL结构化数据文件处理](#第4章 Spark SQL结构化数据文件处理)
- 章节概要
-
- [4.3 Dataset概述](#4.3 Dataset概述)
-
- [4.3.1 Dataset简介](#4.3.1 Dataset简介)
- [4.3.2 Dataset对象的创建](#4.3.2 Dataset对象的创建)

每日一句正能量
士欲宣其义,必先读其书。
第4章 Spark SQL结构化数据文件处理
章节概要
在很多情况下,开发工程师并不了解Scala语言,也不了解Spark常用API,但又非常想要使用Spark框架提供的强大的数据分析能力。Spark的开发工程师们考虑到了这个问题,利用SQL语言的语法简洁、学习门槛低以及在编程语言普及程度和流行程度高等诸多优势,从而开发了Spark SQL模块,通过Spark SQL,开发人员能够通过使用SQL语句,实现对结构化数据的处理。本章将针对Spark SQL的基本原理、使用方式进行详细讲解。
4.3 Dataset概述
4.3.1 Dataset简介
Dataset是从Spark1.6 Alpha版本中引入的一个新的数据抽象结构,最终在Spark2.0版本被定义成Spark新特性。Dataset提供了特定域对象中的强类型集合,也就是在RDD的每行数据中添加了类型约束条件,只有约束条件的数据类型才能正常运行。Dataset结合了RDD和DataFrame的优点,并且可以调用封装的方法以并行方式进行转换等操作。下面通过图4-5来理解RDD、DataFrame与Dataset三者的区别。

图4-1RDD、DataFrame、Dataset数据示例
在图4-5中,序号(1)--(4)分别展示了不同数据类型的抽象结构,其中:
(1)它是基本的RDD数据的表现形式,此时RDD数据没有数据类型和元数据信息。
(2)它是DataFrame数据的表现形式,此时DataFrame数据中添加了Schema元数据信息(列名和数据类型,例如ID: String),DataFrame每一行的类型固定为Row类型,每一列的值无法直接访问,只有通过解析才能获取各个字段的值。
(3)-(4)它们都是Dataset数据的表现形式,具中序亏(3)足任RDBt记1女PQoonlo将数掘米型,在型(value: String)作为Schema元数据信息。而序号(4)则针对每行数据添加了People强数据类型,在DatasetPerson中里存放的是3个字段和属性,Dataset每一行数据类型都可以自己定义,一旦定义后,就具有严格的错误检查机制。
4.3.2 Dataset对象的创建
-
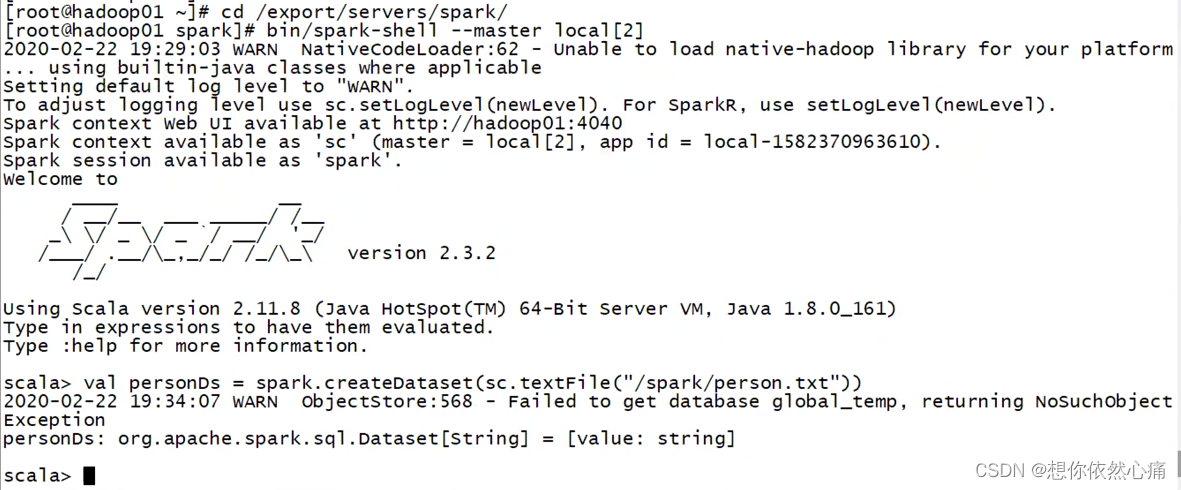
通过SparkSession中的createDataset来创建Dataset,具体代码如下所示。
scala > val personDs=spark.createDataset(sc.textFile("/spark/person.txt"))
personDs: org.apache.spark.sql.Dataset[String] = [value: string]scala > personDs.show()
+---------------+
| value |
+---------------+
|1 zhangsan 20|
|2 lisi 29|
|3 wangwu 25|
|4 zhaoliu 30 |
|5 tianqi 35|
|6 jerry 40|
+---------------+
结果如下图所示
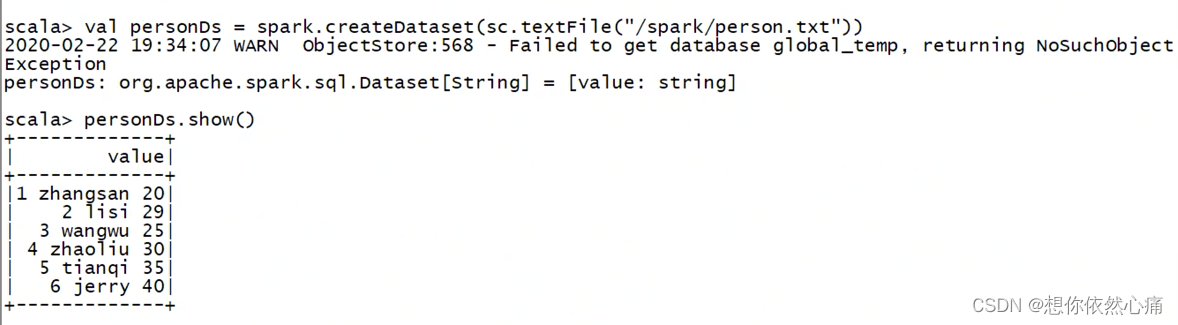
从上述返回结果personDs的属性可以看出,Dataset从已存在的RDD中构建成功,并且赋予value为String类型。Dataset和DataFrame拥有完全相同的成员函数,通过show()方法可以展示personDs中数据的具体内容。
-
DataFrame通过"asElementType"方法转换得到Dataset
Dataset不仅能从RDD中构建,它与DataFrame可以互相转换,DataFrame可以通过"asElementType"方法转换为Dataset,同样Dataset也可以使用toDF()方法转换为DataFrame,具体代码如下所示。scala> spark.read.text("/spark/person.txt").as[String]
res14: org.apache.spark.sql.Dataset[String] = [value: string]scala> spark.read.text("/spark/person.txt").as[String].toDF()
res15: org.apache.spark.sql.DataFrame = [value: string]
结果如下图所示

Dataset操作与DataFrame大致相同,读者可查看官方API http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset详细学习更多的Dataset操作
转载自:https://blog.csdn.net/u014727709/article/details/136033323
欢迎 👍点赞✍评论⭐收藏,欢迎指正