文章目录
- 一、Unet网络简介
-
- [1.1 输入图像](#1.1 输入图像)
- [1.2 编码器部分(Contracting Path)](#1.2 编码器部分(Contracting Path))
- [1.3 解码器部分(Expanding Path)](#1.3 解码器部分(Expanding Path))
- [1.4 最后一层(输出)](#1.4 最后一层(输出))
- [1.5 跳跃连接(Skip Connections)](#1.5 跳跃连接(Skip Connections))
- 二、Unet网络的Pytorch实现
-
- [2.1 网络构建](#2.1 网络构建)
- [2.2 网络训练测试](#2.2 网络训练测试)
- 三、Unet网络的Matlab实现
-
- [3.1 网络构建](#3.1 网络构建)
- [3.2 网络训练](#3.2 网络训练)
- [3.3 网络预测](#3.3 网络预测)
一、Unet网络简介
UNet 是一种常用于图像分割任务的卷积神经网络(CNN)架构,在论文《U-Net: Convolutional Networks for Biomedical Image Segmentation》中提出。这个网络专为生物医学图像分割设计,但由于其优越的性能,现在已被广泛应用于遥感、自动驾驶、医学图像处理等领域。
UNet 是一种编码器-解码器(Encoder-Decoder)结构的对称网络,其名字中的 "U" 来自于其结构在图像中的形状像一个 "U"。如下图所示

1.1 输入图像
- 尺寸:
512 x 512,通道数:1(表示单通道灰度图),3(表示RGB图像)
这里 UNet 中使用了 padding=1 的卷积方式,所以卷积输出尺寸保持不变。
1.2 编码器部分(Contracting Path)
编码器类似于传统的 CNN,用于提取图像的特征,逐步降低空间维度、增加特征通道。
每一步都包含:
- 两次
3x3 卷积 + ReLU - 一次
2x2 max pooling - 通道数:每次加倍,64 → 128 → 256 → 512 → 1024
- 特征图尺寸:每次减半
层分析(从上到下):
| 层级 | 输入大小 | 卷积后大小 | 通道数变化 |
|---|---|---|---|
| L1 | 512×512 | 512×512 | 1 → 64 → 64 |
| L2 | 256×256 | 256×256 | 128 → 128 |
| L3 | 128×128 | 128×128 | 256 → 256 |
| L4 | 64×64 | 64×64 | 512 → 512 |
| Bottom | 32×32 | 32×32 | 1024 |
1.3 解码器部分(Expanding Path)
解码器用于将编码器压缩后的特征图逐步恢复到原始图像的空间分辨率,生成与输入大小一致的分割图。
每一步都包含:
2x2 up-convolution- 与编码器相同层进行特征图拼接
- 两次
3x3 卷积 + ReLU - 通道数逐渐减半:1024 → 512 → 256 → 128 → 64
解码过程分析:
| 层级 | 上采样后大小 | 拼接后通道数 | 卷积输出通道数 | 卷积后尺寸 |
|---|---|---|---|---|
| L4 | 32×32 → 64×64 | 512 + 512 | 512 | 64×64 |
| L3 | 64×64 → 128×128 | 256 + 256 | 256 | 128×128 |
| L2 | 128×128 → 256×256 | 128 + 128 | 128 | 256×256 |
| L1 | 256×256 →512×512 | 64 + 64 | 64 | 388×388 |
1.4 最后一层(输出)
- 使用了一个
1x1 卷积,将通道数变成2。
1.5 跳跃连接(Skip Connections)
UNet 的核心创新是将编码器中对应层的特征图直接传递到解码器的对应层进行拼接。这种做法有两个好处:
- 保留高分辨率的空间信息
- 有助于训练时的梯度传播
二、Unet网络的Pytorch实现
2.1 网络构建
import torch
import torch.nn as nn
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=2):
super(UNet, self).__init__()
# ========== 编码器部分 ==========
# 每个 encoder 包括两个卷积(double conv)+ 一个最大池化(下采样)
self.enc1 = self.double_conv(in_channels, 64) # 输入通道 -> 64
self.pool1 = nn.MaxPool2d(2)
self.enc2 = self.double_conv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.enc3 = self.double_conv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.enc4 = self.double_conv(256, 512)
self.pool4 = nn.MaxPool2d(2)
# ========== Bottleneck ==========
# 最底层特征提取器,包含较多通道(1024),增强感受野
self.bottom = self.double_conv(512, 1024)
self.dropout = nn.Dropout(0.5) # 防止过拟合
# ========== 解码器部分(上采样 + 拼接 + double conv) ==========
self.up4 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2) # 上采样
self.dec4 = self.double_conv(1024, 512) # 拼接后再 double conv(512 来自 skip,512 来自 up)
self.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec3 = self.double_conv(512, 256)
self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self.double_conv(256, 128)
self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self.double_conv(128, 64)
# ========== 输出层 ==========
# 使用 1x1 卷积将通道数变为类别数(像素级分类)
self.out_conv = nn.Conv2d(64, out_channels, kernel_size=1)
def double_conv(self, in_ch, out_ch):
"""包含两个3x3卷积 + ReLU 的结构"""
return nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
# ========== 编码器前向传播 ==========
e1 = self.enc1(x) # -> [B, 64, H, W]
p1 = self.pool1(e1) # -> [B, 64, H/2, W/2]
e2 = self.enc2(p1) # -> [B, 128, H/2, W/2]
p2 = self.pool2(e2) # -> [B, 128, H/4, W/4]
e3 = self.enc3(p2) # -> [B, 256, H/4, W/4]
p3 = self.pool3(e3) # -> [B, 256, H/8, W/8]
e4 = self.enc4(p3) # -> [B, 512, H/8, W/8]
p4 = self.pool4(e4) # -> [B, 512, H/16, W/16]
# ========== Bottleneck ==========
b = self.bottom(p4) # -> [B, 1024, H/16, W/16]
b = self.dropout(b)
# ========== 解码器前向传播 + skip connection 拼接 ==========
up4 = self.up4(b) # 上采样 -> [B, 512, H/8, W/8]
d4 = self.dec4(torch.cat([up4, e4], dim=1)) # 拼接 encoder 的 e4
up3 = self.up3(d4)
d3 = self.dec3(torch.cat([up3, e3], dim=1))
up2 = self.up2(d3)
d2 = self.dec2(torch.cat([up2, e2], dim=1))
up1 = self.up1(d2)
d1 = self.dec1(torch.cat([up1, e1], dim=1))
# ========== 输出层 ==========
out = self.out_conv(d1) # -> [B, num_classes, H, W]
return out
# ========== 模型测试:构造随机输入看看输出尺寸 ==========
if __name__ == "__main__":
model = UNet(in_channels=1, out_channels=2)
x = torch.randn(1, 1, 512, 512) # 随机生成一个 1 张单通道图像
y = model(x)
print("Output shape:", y.shape) # 应为 [1, 2, 512, 512],2 表示类别数2.2 网络训练测试
这里用到的数据集是公开数据集(MoNuSeg 2018 Data)
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
import matplotlib.pyplot as plt
from model import UNet
from dataset import MonuSegDataset # 自定义的数据集类
import os
# ========================
# 1️⃣ 数据路径配置
# ========================
train_image_dir = "TrainingData/TissueImages" # 训练图像路径
train_mask_dir = "TrainingData/Masks" # 训练标签路径
test_image_dir = "TestData/TissueImages" # 测试图像路径
test_mask_dir = "TestData/Masks" # 测试标签路径
# ========================
# 2️⃣ 数据预处理方式定义
# ========================
resize_size = (512, 512) # 所有图像统一 resize 的尺寸,需与模型输入一致
# 图像预处理:Resize → ToTensor(归一化到 0~1,3通道 RGB)
transform_img = transforms.Compose([
transforms.Resize(resize_size),
transforms.ToTensor()
])
# 掩码预处理:Resize → 转张量 → squeeze → 转 long 类型(整数标签)
transform_mask = transforms.Compose([
transforms.Resize(resize_size, interpolation=transforms.InterpolationMode.NEAREST), # 保留 mask 标签值
transforms.PILToTensor(), # 依旧是整数值,不做归一化
transforms.Lambda(lambda x: x.squeeze().long()) # [1,H,W] → [H,W],保持 long 类型
])
# ========================
# 3️⃣ 加载数据集(训练 + 测试)
# ========================
train_dataset = MonuSegDataset(train_image_dir, train_mask_dir, transform_img, transform_mask)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
test_dataset = MonuSegDataset(test_image_dir, test_mask_dir, transform_img, transform_mask)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
# ========================
# 4️⃣ 初始化模型、损失函数、优化器
# ========================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = UNet(in_channels=3, out_channels=2).to(device) # 3通道输入,2类输出
criterion = nn.CrossEntropyLoss() # 用于像素级分类
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# ========================
# 5️⃣ 模型训练主循环
# ========================
for epoch in range(30): # 总共训练 30 个 epoch
model.train()
running_loss = 0.0
for imgs, masks in train_loader:
imgs, masks = imgs.to(device), masks.to(device)
outputs = model(imgs) # 输出尺寸 [B, 2, H, W]
loss = criterion(outputs, masks) # CrossEntropy 会自动处理 one-hot 标签
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}: Loss = {running_loss / len(train_loader):.4f}")
# ========================
# 6️⃣ 测试 + 可视化预测结果
# ========================
model.eval() # 切换为评估模式(关闭 Dropout/BN 等)
with torch.no_grad(): # 不计算梯度,加速推理
for img, mask in test_loader:
img = img.to(device)
output = model(img) # 网络前向推理,输出 shape [1, 2, H, W]
pred = torch.argmax(output, dim=1) # 取每个像素的最大概率类别 → shape [1, H, W]
# 可视化结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.title("Image")
plt.imshow(img[0].cpu().permute(1, 2, 0)) # [C,H,W] → [H,W,C] 显示 RGB 图
plt.subplot(1, 3, 2)
plt.title("Prediction")
plt.imshow(pred[0].cpu(), cmap="gray") # 显示预测掩码
plt.subplot(1, 3, 3)
plt.title("Ground Truth")
plt.imshow(mask[0], cmap="gray") # 显示真值掩码
plt.tight_layout()
plt.show()
break # 只可视化第一张测试图像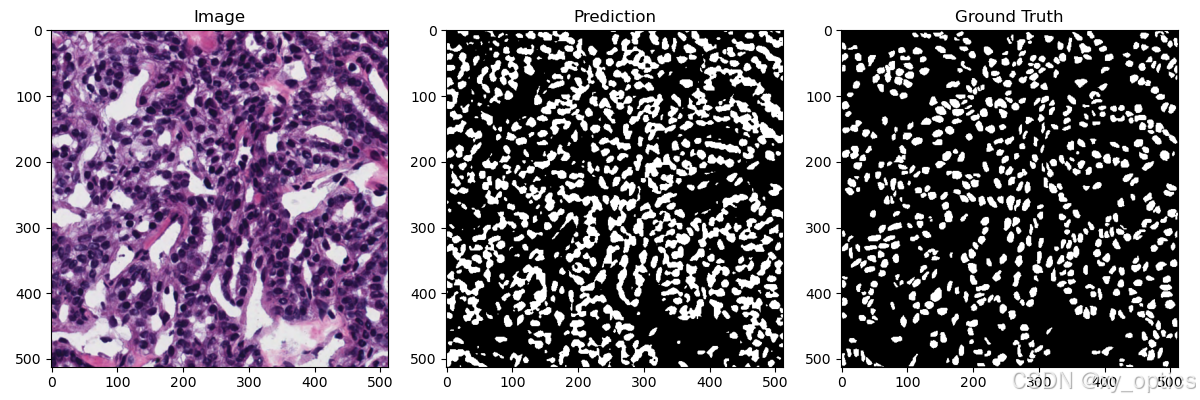
三、Unet网络的Matlab实现
3.1 网络构建
主函数如下
function lgraph = unetLayers(inputSize, numClasses)
% unetLayers 构建一个标准的 U-Net 分割网络结构
%
% 输入参数:
% inputSize - 输入图像的尺寸,例如 [512 512 3]
% numClasses - 分割类别数(例如背景+前景=2)
%
% 输出参数:
% lgraph - layerGraph 对象,包含整个 U-Net 网络结构
% === 输入层 ===
% 输入图像大小为 inputSize(例如 [512 512 3])
layers = imageInputLayer(inputSize, 'Name', 'input');
% === 编码器部分(Encoder)===
% 每个 encoderBlock 包括 2 个卷积 + ReLU + 最大池化,逐步提取特征 & 降维
% 同时记录每个 block 的输出,用于后续的 skip connection
[enc1, enc1Out] = encoderBlock('enc1', 64); % 第一层编码器,输出 64 通道特征图
[enc2, enc2Out] = encoderBlock('enc2', 128); % 第二层编码器
[enc3, enc3Out] = encoderBlock('enc3', 256); % 第三层编码器
[enc4, enc4Out] = encoderBlock('enc4', 512); % 第四层编码器
% === Bottleneck(编码器与解码器之间的连接)===
% 特征最抽象、最小尺寸的位置
% 加入 Dropout 层,增强模型泛化能力,避免过拟合
bottleneck = [
convolution2dLayer(3, 1024, 'Padding','same','Name','bottom_conv1')
reluLayer('Name','bottom_relu1')
dropoutLayer(0.5, 'Name','bottom_dropout') % 50% 随机丢弃通道
convolution2dLayer(3, 1024, 'Padding','same','Name','bottom_conv2')
reluLayer('Name','bottom_relu2')
];
% === 解码器部分(Decoder)===
% 每个 decoderBlock 先上采样,再与对应 encoder 输出进行 skip connection
% 然后通过卷积融合特征图,逐步恢复空间分辨率
dec4 = decoderBlock('dec4', 512); % 解码器第4层,对应 encoder 的第4层
dec3 = decoderBlock('dec3', 256);
dec2 = decoderBlock('dec2', 128);
dec1 = decoderBlock('dec1', 64);
% === 输出层 ===
outputLayer = [
convolution2dLayer(1, numClasses, 'Name', 'final_conv') % 1x1 卷积,通道映射为类别数
softmaxLayer('Name', 'softmax') % 每个像素的类别概率
pixelClassificationLayer('Name', 'pixelClassLayer') % 自动处理标签+计算交叉熵损失
];
% === 组装整个网络 ===
% 把所有层拼成一个大的 LayerGraph(U-Net 主干结构)
lgraph = layerGraph([
layers;
enc1; enc2; enc3; enc4;
bottleneck;
dec4; dec3; dec2; dec1;
outputLayer
]);
% === 添加 skip connections(跳跃连接)===
% 将 encoder 的中间输出与对应 decoder 的拼接输入连接起来
% 连接的是 decoderBlock 中的 depthConcatenationLayer 的第 2 个输入端口(in2)
lgraph = connectLayers(lgraph, enc4Out, 'dec4_concat/in2');
lgraph = connectLayers(lgraph, enc3Out, 'dec3_concat/in2');
lgraph = connectLayers(lgraph, enc2Out, 'dec2_concat/in2');
lgraph = connectLayers(lgraph, enc1Out, 'dec1_concat/in2');
end上面函数里用到的两个辅助函数encoderBlock和decoderBlock。分别如下所示
function [layers, outputName] = encoderBlock(name, outChannels)
% encoderBlock 生成 U-Net 编码器模块的一组层
%
% 输入参数:
% name - 当前模块的名字前缀,用于给每一层命名(如 "enc1")
% outChannels - 输出通道数,即卷积核数量,决定了特征图的深度
%
% 输出参数:
% layers - 一组 Layer,用于组成 layerGraph 的一部分
% outputName - 最后一层 relu 的名称,用于后续 skip connection 连接
layers = [
% 第1个卷积层,使用 3x3 卷积核,输出通道为 outChannels,padding=same 保持尺寸不变
convolution2dLayer(3, outChannels, "Padding", "same", "Name", [name, '_conv1'])
% ReLU 激活函数,增加非线性表达能力
reluLayer("Name", [name '_relu1'])
% 第2个卷积层,继续提取特征(仍是 3x3 卷积)
convolution2dLayer(3, outChannels, "Padding", "same", "Name", [name, '_conv2'])
% ReLU 激活函数
reluLayer("Name", [name '_relu2'])
% 最大池化层,使用 2x2 核,步长为 2,用于降采样(尺寸缩小一半)
maxPooling2dLayer(2, 'Stride', 2, 'Name', [name '_pool'])
];
function layers = decoderBlock(name, outChannels)
% decoderBlock 生成 U-Net 解码器模块的一组层
%
% 输入参数:
% name - 当前模块的名字前缀(如 "dec1")
% outChannels - 输出通道数(卷积核数量)
%
% 输出参数:
% layers - 一组层,用于构建 U-Net 的解码器部分
layers = [
% 上采样层:使用 2x2 转置卷积进行上采样,步长为2,使特征图尺寸扩大一倍
transposedConv2dLayer(2, outChannels, 'Stride', 2, 'Name', [name '_upconv'])
% 跳跃连接:将 encoder 的输出与上采样结果拼接在深度维度上(channel 维)
% 注意:输入端需要通过 connectLayers 手动连接 encoder 的输出
depthConcatenationLayer(2, 'Name', [name '_concat'])
% 卷积层1:拼接后做一次卷积提取融合后的特征
convolution2dLayer(3, outChannels, 'Padding','same','Name', [name '_conv1'])
% 激活层1:ReLU 非线性激活
reluLayer('Name',[name '_relu1'])
% 卷积层2:再进一步提取特征
convolution2dLayer(3, outChannels, 'Padding','same','Name', [name '_conv2'])
% 激活层2:ReLU
reluLayer('Name',[name '_relu2'])
];
end用matlab可以简单画出这个网络的结构,如下图
inputSize = [512 512 1]; % 输入图像大小
numClasses = 2; % 前景 / 背景
lgraph = unetLayers(inputSize, numClasses);
plot(lgraph) % 可视化网络结构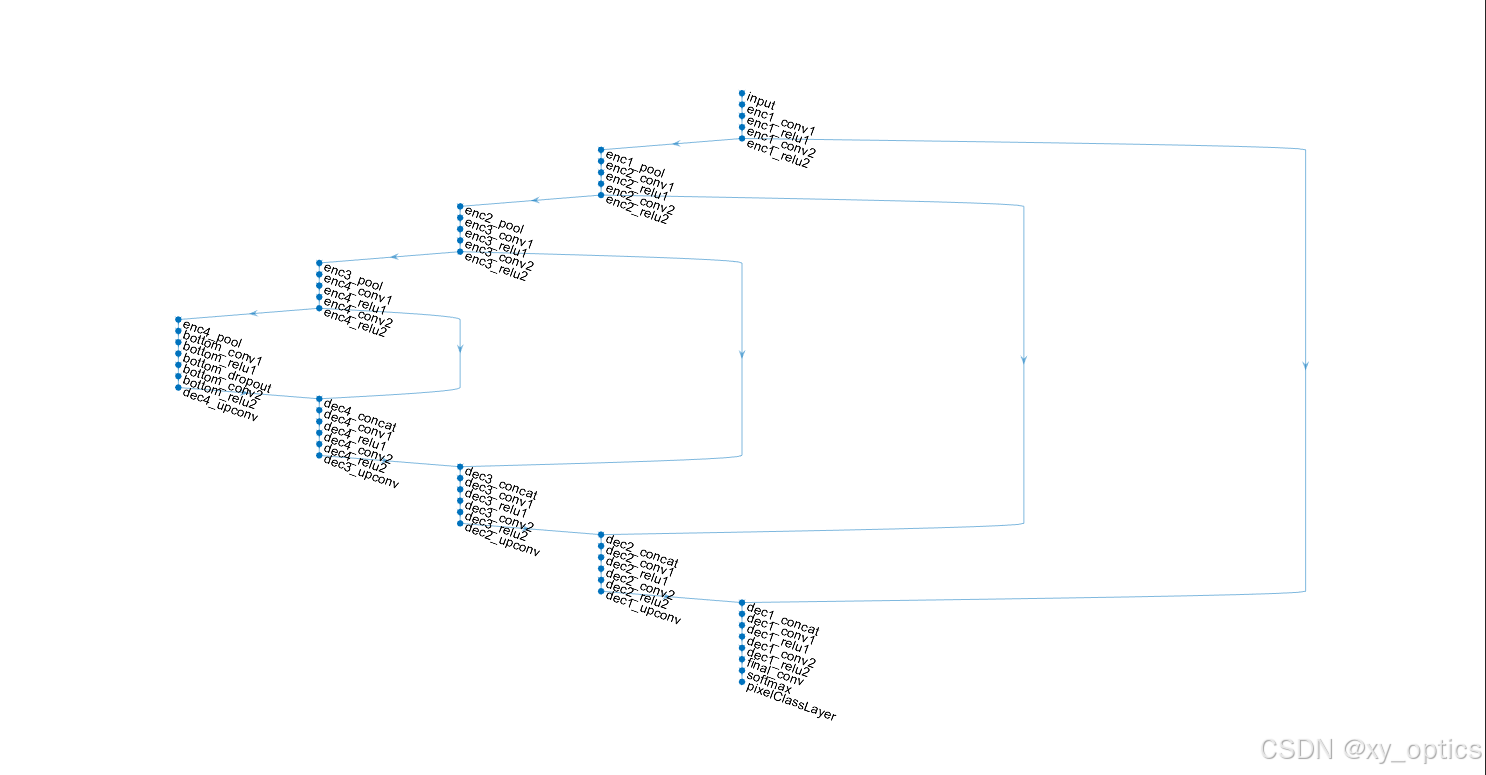
3.2 网络训练
数据集用到的是网络上公开的数据集(MoNuSeg 2018 Data)。
训练程序如下
% === 路径设置 ===
% 设置训练图像和对应标签(掩膜)的路径
imageDir = 'Training Data/Tissue Images'; % 原始图像路径
maskDir = 'Training Data/Masks'; % 对应的标签图路径(掩码)
% === 分类标签设置 ===
% 定义语义分割任务中的类别名称和对应的像素值
% 这些 pixel 值应该和 mask 图像中的像素一致
classNames = ["background", "nuclei"]; % 类别名称
labelIDs = [0, 1]; % 对应的像素值,0=背景,1=细胞核
% === 创建图像和标签的 Datastore ===
imds = imageDatastore(imageDir); % 加载图像(支持自动批量读取)
resizeSize = [512 512]; % 所有图像统一 resize 的尺寸
% pixelLabelDatastore 将 mask 图像转为每像素的分类标签
pxds = pixelLabelDatastore(maskDir, classNames, labelIDs);
% === 创建联合数据源:pixelLabelImageDatastore ===
% 用于将图像和标签按顺序配对,并自动 resize
trainingData = pixelLabelImageDatastore(imds, pxds, 'OutputSize', resizeSize);
% 返回的对象可直接输入到 trainNetwork 作为训练集
% === 定义网络结构 ===
inputSize = [512 512 3]; % 图像尺寸是 512x512,RGB 三通道
numClasses = 2; % 类别数为 2(背景 + 细胞核)
% 创建 U-Net 网络结构(调用你自定义的 unetLayers 函数)
lgraph = unetLayers(inputSize, numClasses);
% === 设置训练参数 ===
options = trainingOptions('adam', ... % 使用 Adam 优化器
'InitialLearnRate', 1e-4, ... % 初始学习率
'MaxEpochs', 30, ... % 最大训练轮数(epoch)
'MiniBatchSize', 2, ... % 每次训练使用 2 张图像
'Shuffle','every-epoch', ... % 每轮训练时打乱数据顺序
'VerboseFrequency', 10, ... % 每 10 次迭代输出一次信息
'Plots','training-progress', ... % 实时绘制训练损失曲线
'ExecutionEnvironment','auto'); % 自动选择 CPU / GPU
% === 开始训练 ===
% 使用训练数据、U-Net 结构和训练参数进行模型训练
net = trainNetwork(trainingData, lgraph, options);
% === 保存模型到文件 ===
% 将训练好的模型保存在本地,方便后续使用或预测
save('trained_unet_monuseg.mat', 'net');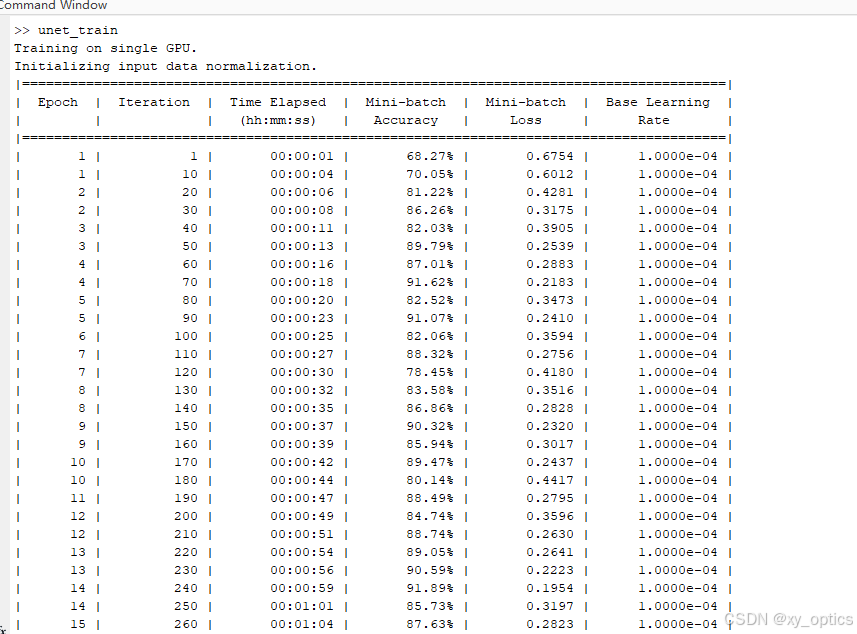
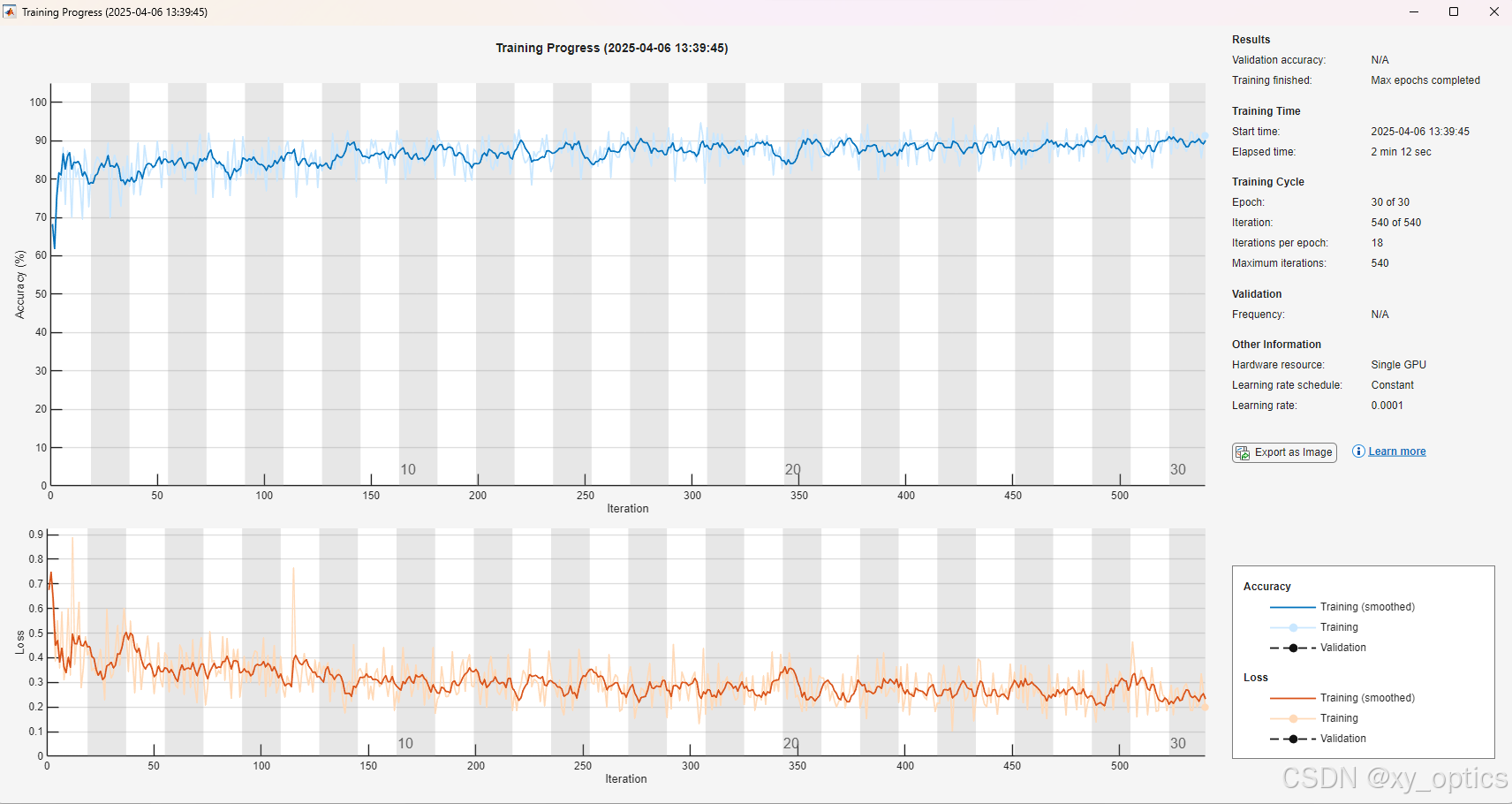
3.3 网络预测
% === 设置路径 ===
% 读取一张测试图像以及其对应的 ground truth 掩码(标签)
testImage = imread('Test Data/Tissue Images/TCGA-2Z-A9J9-01A-01-TS1.tif'); % 测试原图
gt_mask = imread('Test Data/Masks/TCGA-2Z-A9J9-01A-01-TS1.png'); % 对应的真实标签图
% === Resize 成训练时的网络输入大小 ===
% 如果训练时输入图像是 [512×512],推理时也要保证尺寸一致
testImage = imresize(testImage, [512 512]);
% === 加载训练好的 U-Net 模型 ===
% 模型应包含名为 net 的变量,即训练阶段保存的网络结构和权重
load('trained_unet_monuseg.mat'); % 加载变量 net
% === 执行语义分割预测 ===
% 调用 MATLAB 的 semanticseg 函数,自动处理输入并输出预测分类图
% 返回的是 categorical 类型的预测图,每个像素是 "background" 或 "nuclei"
pred = semanticseg(testImage, net);
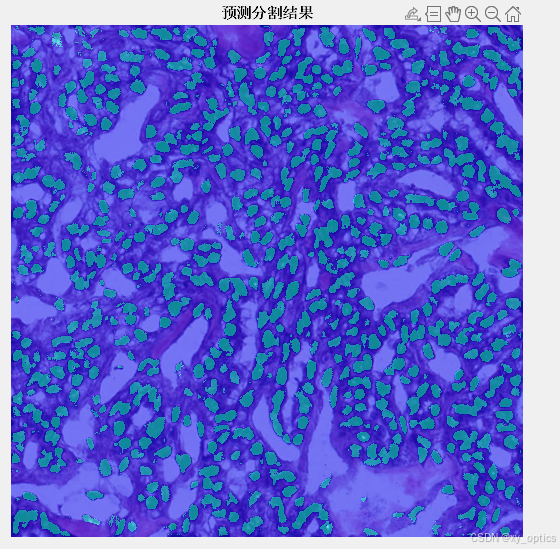
% === 可视化预测分割结果(与原图叠加)===
% 使用 labeloverlay 将分割掩码叠加在原图上,便于直观观察分割效果
figure;
imshow(labeloverlay(testImage, pred))
title('预测分割结果')
% === 将预测结果转为二值图像 ===
% 把 categorical 类型的预测图转为 0/1 掩码图(uint8)
% nuclei → 1,background → 0
pred_mask = uint8(pred == "nuclei");
% === 显示 原图、预测掩码、真实掩码 的对比 ===
figure;
subplot(1,3,1); imshow(testImage); title('原图'); % 显示输入图像
subplot(1,3,2); imshow(pred_mask,[]); title('预测'); % 显示模型预测的掩码(0/1图)
subplot(1,3,3); imshow(gt_mask,[]); title('真值'); % 显示人工标注的 ground truth 掩码