❝
近日看到多篇有关并发和并行的文章,读后有感,遂撰文梳理核心概念,以解其中之惑:
++并发与并行是计算机科学中处理多任务执行的核心概念。并发关注任务的协调与交错执行,而并行则强调任务的真正同时执行,以提升计算效率。这两个术语常被混用,但实际上它们代表了不同的任务执行方式。++
1. 引言
随着计算需求的不断增长,现代计算机系统正面临前所未有的挑战。从智能手机到超级计算机,多核处理器、分布式系统和云计算的广泛应用使得并发与并行技术成为提升系统性能和响应能力的关键支柱。
并发通过管理多个任务的执行顺序,确保系统在高负载下仍能保持响应性;并行则利用多处理器或多核心硬件,真正同时执行任务,以加速计算。这两者在高性能计算、实时系统和用户交互应用中发挥着不可替代的作用。
在多核处理器时代,传统串行编程已无法充分利用硬件潜力。并行计算通过将任务分解到多个核心执行,显著缩短了计算时间。然而,并发与并行的实现并非没有代价,它们引入了诸如竞争条件、死锁和负载均衡等复杂问题,需要开发者具备深厚的理论基础和实践经验。
2. 并发与并行的理论基础
2.1 定义
- 并发(Concurrency) :
- 指系统在一段时间内管理多个任务的能力。并发关注任务的协调与交错执行,通过时间分片等技术在一个或多个处理器上实现,因此并发看似同时进行,但不一定在同一时刻执行。
- 并发强调任务的逻辑组织和协调。
- 举例:一个Web服务器可以并发处理多个客户端请求,通过快速切换任务确保每个请求都能及时响应。
- 并行(Parallelism) :
- 指多个任务在同一时刻真正同时执行,通常依赖于多核处理器或分布式系统。其核心目标是提升计算速度,通过将问题分解为独立的子任务并同时处理。并行适用于计算密集型任务。
- 并行关注物理执行的并行性。
- 举例:在并行矩阵乘法中,不同的核心可以同时计算矩阵的不同部分,从而显著缩短总计算时间;科学模拟或图像处理,其效果依赖于多核处理器、GPU或分布式计算系统的硬件支持。
2.2 区别
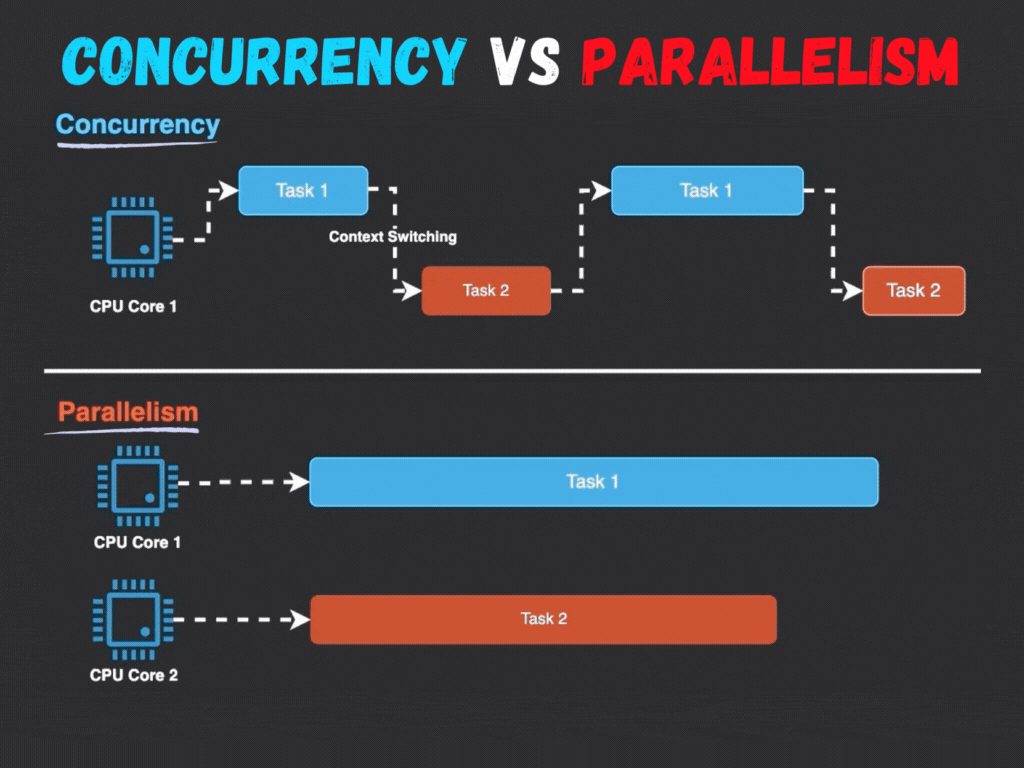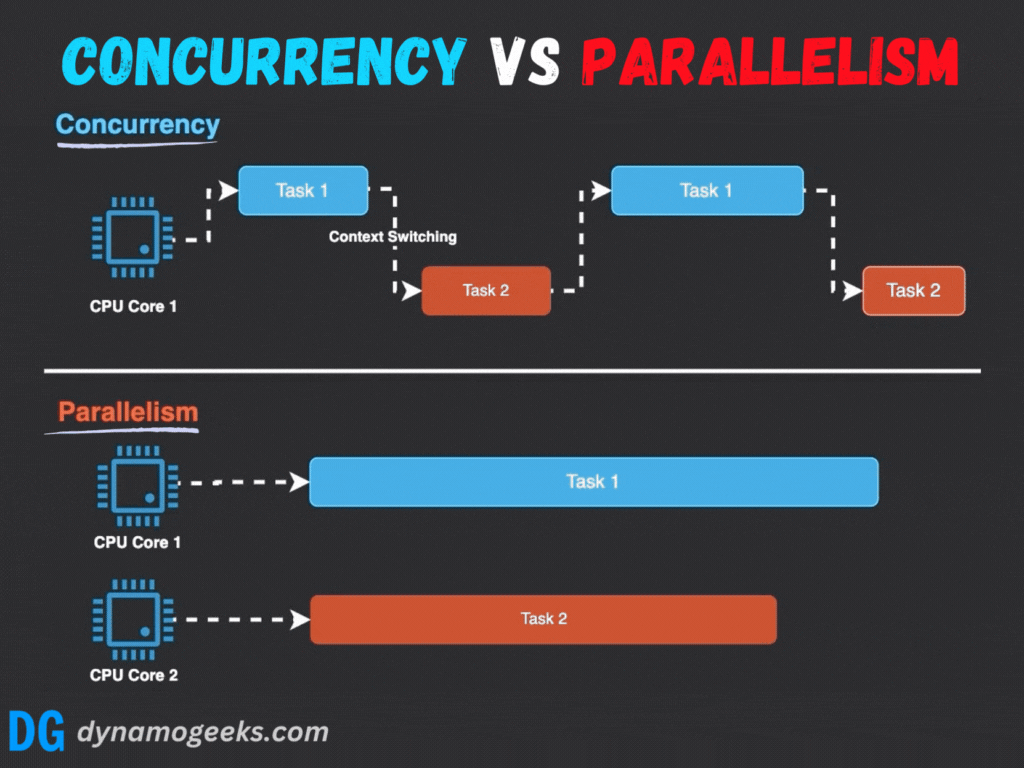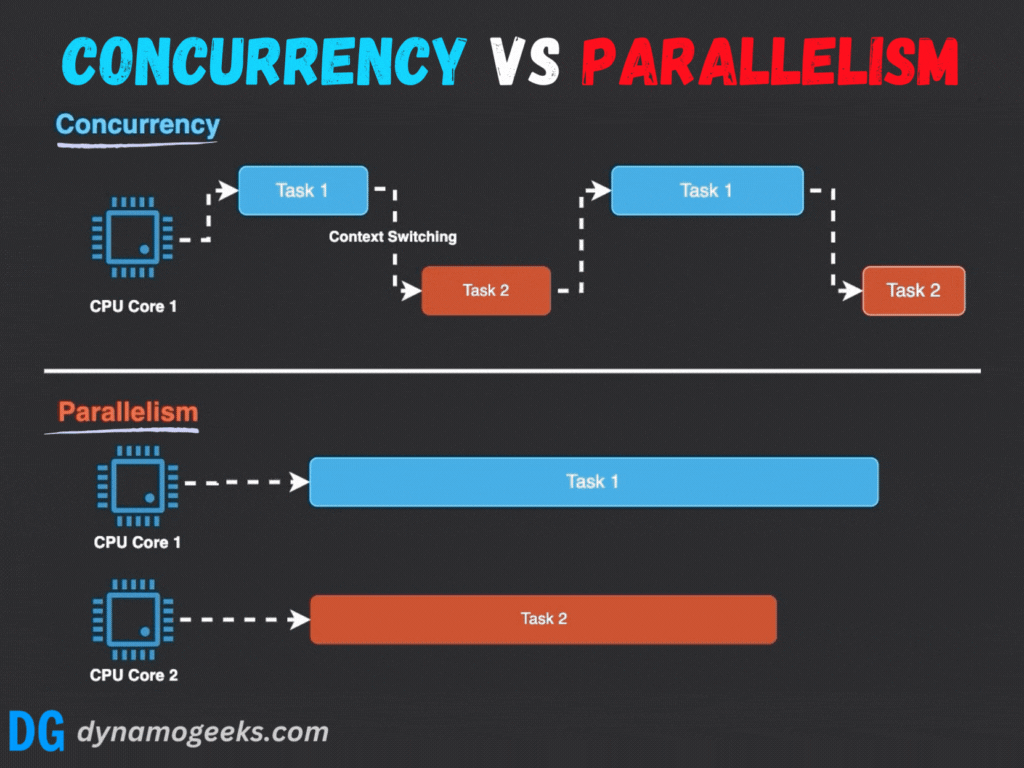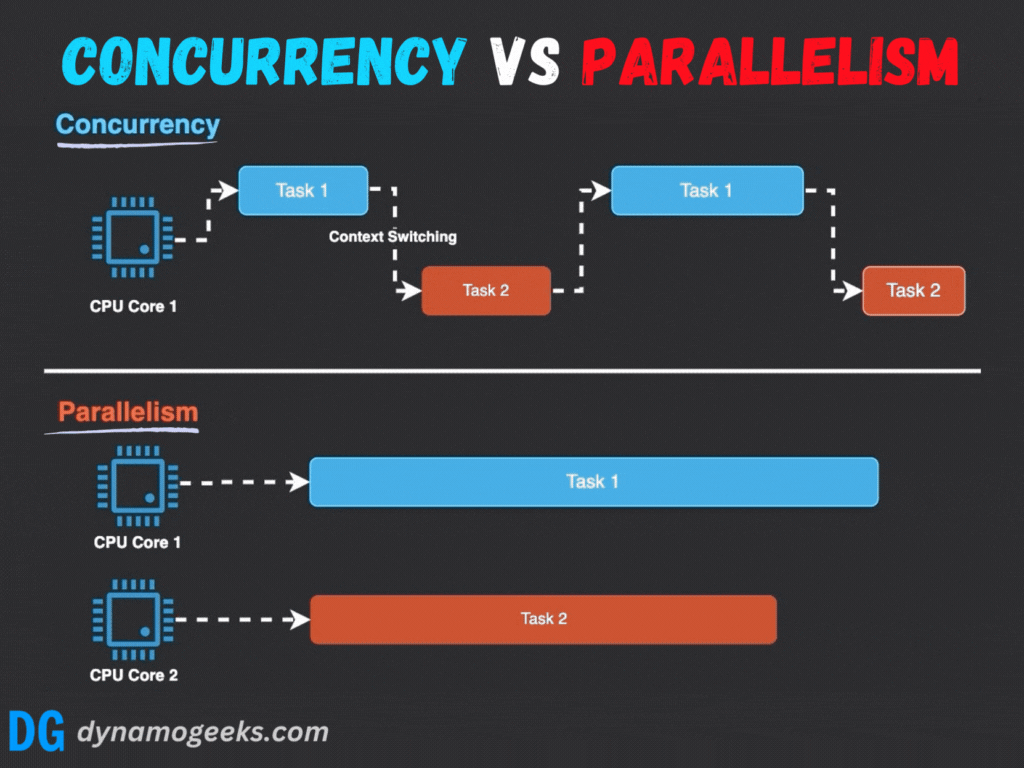
并发与并行的根本区别在于执行的时间性 和资源依赖性:
- 执行模式 :并行强调真正的同时执行,而并发通过任务切换营造同时进行的假象。
- 硬件依赖:并行需要多处理器或多核心支持,而并发在单核系统上即可实现。
- 目标:并行旨在加速计算,而并发注重系统响应性和多任务处理能力。
例如,在单核系统中,操作系统通过时间片轮转调度多个线程;而多核系统中,线程可以分配到不同核心并行运行。
2.3 并发理论
并发理论为理解和管理多任务系统提供了形式化工具:
- 交错执行(Interleaving):并发任务的执行可以看作动作序列的交错组合。由于任务切换的非确定性,可能导致不同的执行路径,增加了系统验证的复杂性。
- 进程代数(Process Algebra):如通信顺序进程(CSP)Hoare, 1978,用于建模并发系统并验证其性质,例如死锁自由性。
- Petri网:一种图形化工具,用于表示任务依赖、资源共享和并发行为,常用于系统设计和分析。
2.4 并行计算模型
并行计算依赖于理论模型来指导算法设计和性能分析:
- Amdahl定律 Amdahl, 1967:量化了并行化的潜在加速比,指出加速受限于不可并行化的部分。其公式为: S = \\frac{1}{(1 - P) + \\frac{P}{N}} 其中 (S) 为加速比,(P) 为可并行化比例,(N) 为处理器数量。
- Gustafson定律:与Amdahl定律相对,该定律认为随着问题规模增加,并行的收益会更显著,尤其适用于大数据处理。
- PRAM模型(并行随机访问机):假设多个处理器共享内存并同步执行,用于分析并行算法的时间和空间复杂度。
这些理论为并发与并行的实现提供了坚实基础,帮助开发者设计高效、可验证的系统。
3. 实现并发
3.1 并行实现并发
在多核处理器上,任务可以分配到不同核心并行执行,从而实现高效并发。例如,Web服务器通过多线程并行处理客户端请求。
伪代码示例:多线程并行处理
function process_requests(requests):
thread_pool = create_thread_pool(num_cores) # 创建线程池
for request in requests:
thread_pool.submit(handle_request, request) # 提交任务
thread_pool.wait_for_completion() # 等待所有任务完成
function handle_request(request):
response = process(request) # 处理请求
send_response(response) # 发送响应3.2 任务调度
在单核处理器上,通过时间片轮转等调度算法实现并发。操作系统在任务间快速切换,营造同时执行的假象。
伪代码示例:时间片轮转调度
function scheduler(tasks, time_slice):
while tasks not empty:
for task in tasks:
run_task(task, time_slice) # 执行任务一段时间
if task not finished:
requeue(task) # 未完成则重新排队
else:
remove(task) # 完成后移除3.3 多线程
多线程通过创建多个执行单元实现并发。线程共享进程资源,通过同步机制(如互斥锁)协调访问。
伪代码示例:多线程同步
mutex = create_mutex() # 创建互斥锁
shared_data = initialize_data() # 初始化共享数据
function thread_function():
lock(mutex) # 加锁
modify(shared_data) # 修改共享数据
unlock(mutex) # 解锁3.4 异步编程
异步编程通过事件循环和回调函数处理I/O密集型任务,避免阻塞主线程。
伪代码示例:异步I/O
function async_read(file, callback):
event_loop.add_task(read_file, file, callback) # 添加异步任务
function read_file(file, callback):
data = read_from_disk(file) # 读取文件
callback(data) # 执行回调
# 事件循环
while True:
task = event_loop.get_next_task()
task.execute()3.5 协程
协程通过yield和resume机制在单线程内实现并发,适用于I/O密集型任务,具有低开销优势。
伪代码示例:协程
function coroutine_example():
while True:
data = yield # 暂停并接收数据
process(data) # 处理数据
coroutine = coroutine_example()
coroutine.send(data) # 发送数据并恢复执行3.6 事件驱动
事件驱动编程通过事件循环监听和处理事件,适用于GUI和网络应用。
伪代码示例:事件驱动
function event_loop():
while True:
event = wait_for_event() # 等待事件
handler = get_handler(event) # 获取处理函数
handler(event) # 处理事件3.7 多进程
多进程通过创建独立进程实现并发,进程间通过IPC(如管道或消息队列)通信,适用于CPU密集型任务。
伪代码示例:多进程
function main():
processes = []
for i in range(num_processes):
p = create_process(target=worker, args=(i,)) # 创建进程
processes.append(p)
p.start() # 启动进程
for p in processes:
p.join() # 等待进程结束
function worker(id):
result = compute(id) # 执行计算任务
send_result(result) # 发送结果4. 实现并行的技术
4.1 多线程(Multithreading)
多线程通过在单个或多个处理器核心上运行多个线程来实现并行。在多核处理器上,线程可以真正并行执行;在单核处理器上,通过时间片切换实现伪并行。多线程适用于I/O密集型和计算密集型任务,能提高资源利用率和程序响应速度。
伪代码示例:
// 创建并启动多个线程
threads = []
for i in 1 to N:
thread = create_thread(task_function, args)
threads.append(thread)
start_thread(thread)
// 等待所有线程完成
for thread in threads:
join_thread(thread)
// 线程执行的函数
function task_function(args):
result = perform_task(args)
return result4.2 多进程(Multiprocessing)
多进程通过创建多个独立进程实现并行,每个进程运行在不同的处理器核心上。进程间通过管道或消息队列等通信机制协调工作。多进程适用于需要高隔离性和安全性的任务,如科学计算和服务器应用。
伪代码示例:
// 创建并启动多个进程
processes = []
for i in 1 to N:
process = create_process(target=worker_function, args=(i,))
processes.append(process)
start_process(process)
// 等待所有进程完成
for process in processes:
join_process(process)
// 进程执行的函数
function worker_function(id):
result = compute(id)
send_result(result)4.3 分布式计算(Distributed Computing)
分布式计算将任务分配到网络中的多台计算机上并行执行,通常使用消息传递接口(MPI)进行通信。适用于大规模数据处理和复杂计算任务,如天气预报和分布式数据库。
伪代码示例:
// MPI 伪代码示例
if rank == 0: // 主节点
data = load_data()
for worker in 1 to num_workers:
send_data(data_chunk, worker)
results = []
for worker in 1 to num_workers:
result = receive_result(worker)
results.append(result)
final_result = aggregate(results)
else: // 工作节点
data_chunk = receive_data(0)
result = process(data_chunk)
send_result(result, 0)4.4 GPU并行计算
GPU并行计算利用图形处理单元(GPU)的多核心架构,通过CUDA或OpenCL等技术实现高度并行。适用于数据密集型任务,如图像处理和机器学习。
伪代码示例:
// CUDA 伪代码示例
function gpu_kernel(input, output):
tid = get_thread_id()
if tid < input.size:
output[tid] = compute(input[tid])
// 主函数
input = load_input()
output = allocate_output()
launch_kernel(gpu_kernel, input, output)
synchronize() // 等待GPU完成4.5 任务并行(Task Parallelism)
任务并行将一个大任务分解为多个独立子任务,并行执行这些子任务。适用于任务间依赖较少的场景,如编译器并行处理多个文件。
伪代码示例:
// 使用 OpenMP 实现任务并行
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task
task1()
#pragma omp task
task2()
#pragma omp task
task3()
}
}4.6 数据并行(Data Parallelism)
数据并行将数据分割成多个部分,每个部分由不同的处理器或线程并行处理。适用于矩阵运算和图像处理等数据密集型任务。
伪代码示例:
// 使用 OpenMP 实现数据并行
#pragma omp parallel for
for i in 0 to N-1:
output[i] = compute(input[i])4.7 流水线并行(Pipeline Parallelism)
流水线并行将任务分解为一系列阶段,每个阶段由不同处理器或线程处理,形成处理流水线。适用于数据流处理和视频编码等场景。
伪代码示例:
// 流水线并行伪代码
function stage1(input):
intermediate1 = process_stage1(input)
return intermediate1
function stage2(intermediate1):
intermediate2 = process_stage2(intermediate1)
return intermediate2
function stage3(intermediate2):
output = process_stage3(intermediate2)
return output
// 在不同线程或处理器上执行各阶段
thread1: stage1(input)
thread2: stage2(stage1_output)
thread3: stage3(stage2_output)4.8 Actor模型
Actor模型是一种并发计算模型,通过将系统分解为独立执行的Actor来实现并发和并行。每个Actor可以通过消息传递与其他演员通信,避免共享内存和锁的使用。常见的Actor模型有Orleans、Akka、Erlang等。
伪代码示例:
// 创建两个Actor
actor1 = create_actor(1)
actor2 = create_actor(2)
// Actor1 发送 Ping 消息给 Actor2
send_message(2, Ping, 1)
// Actor2 收到 Ping 后会回复 Pong 给 Actor1
// Actor1 收到 Pong 后打印消息
// 停止两个Actor
send_message(1, Stop, 0) // 0可以是系统或主线程的ID
send_message(2, Stop, 0)5. 实践应用
5.1 软件开发中的并行应用
并行广泛应用于需要高计算能力的场景,包括:
- 科学模拟:天气预报、分子动力学等任务涉及大量方程求解,可通过并行化显著加速。
- 机器学习:深度神经网络训练依赖矩阵运算,TensorFlow和PyTorch等框架利用GPU并行性加速训练过程。
- 图像与视频处理:如3D渲染或视频滤镜应用,可将任务分配到多核或GPU上并行执行。
常见的并行编程模型包括:
- TPL :
TPL是.NET中用于并行编程的一个强大库 - OpenMP :基于指令的共享内存并行
API,适用于C/C++和Fortran。 - MPI(消息传递接口):分布式内存并行的标准,用于高性能计算集群。
- CUDA :
NVIDIA的并行计算平台,支持GPU上的细粒度并行。
5.2 软件开发中的并发应用
并发在需要处理多任务或事件的系统中至关重要,例如:
- Web服务器 :如
Apache和Nginx,通过多线程、多进程或事件驱动架构并发处理大量客户端请求。 - 图形用户界面(GUI):并发确保界面在执行后台任务(如数据加载)时仍能响应用户输入。
- 数据库系统:通过锁和事务等并发控制机制,管理多用户对数据的并发访问。
常见的并发模型包括:
- 多线程 :C#、Java和C++提供线程库(如
System.Thread、java.lang.Thread、std::thread)实现并发。 - 异步编程 :Node.js和Python的
asyncio支持非阻塞代码,适用于I/O密集型任务。 - Actor模型:Erlang和Akka框架通过独立的Actor单元和消息传递实现并发,避免共享内存问题。
6. 并发与并行编程的挑战
6.1 并发挑战
并发引入了多个复杂问题:
- 竞争条件(Race Conditions):多个线程同时访问共享资源,可能导致不可预测的结果。例如,未同步的计数器递增可能丢失更新。
- 死锁(Deadlocks):线程间相互等待对方释放资源,导致永久阻塞。例如,两个线程各自持有对方需要的锁。
- 活锁(Livelocks):线程不断尝试解决问题但无进展,如反复让出资源。
- 饥饿(Starvation):某些线程因调度不公而无法获得资源。
解决这些问题通常依赖同步原语(如互斥锁、信号量),但过度同步可能降低性能。
6.2 并行挑战
并行计算也有其难点:
- 负载均衡:确保所有处理器或核心均匀分担工作量,避免部分核心空闲。
- 通信开销:分布式系统中,节点间通信成本可能抵消并行收益。
- 可扩展性:随着处理器数量增加,同步开销或串行部分可能导致收益递减。
并行算法需精心设计,采用动态负载均衡或工作窃取等技术应对这些挑战。
7. 管理并行与并发的工具与技术
7.1 调试与测试
并发与并行程序的非确定性使其调试异常困难,常用工具包括:
- 静态分析:如Intel Inspector或FindBugs,可在不运行代码的情况下检测潜在问题。
- 运行时验证:Valgrind的Helgrind等工具在程序运行时监控同步错误。
- 测试框架:JUnit或pytest可扩展用于并发测试,模拟多线程场景。
7.2 设计模式
设计模式为常见问题提供解决方案:
- 线程池:管理固定数量的线程执行任务,减少创建和销毁开销。
- 生产者-消费者:生产者生成数据,消费者处理数据,通过同步队列协调。
- Map-Reduce:将任务映射到数据分片并归约结果,适用于大数据处理。
7.3 编程语言支持
现代语言内置了对并行与并发的支持:
- CSharp :通过
TPL和System.Collections.Concurrent等库简化并发和并行编程。 - Go :通过
goroutines和通道简化并发编程。 - Rust:通过所有权模型在编译时防止数据竞争。
- Java :提供
java.util.concurrent包,包括线程池、并发集合等高级工具。
8. 并行与并发的权衡
8.1 复杂度与性能
并行与并发提升性能的同时增加了代码复杂度:
- 多线程:提供细粒度控制,但易引入竞争条件。
- 异步编程:避免线程开销,但可能导致回调地狱或复杂逻辑。
8.2 共享内存与消息传递
并发模型分为两种:
- 共享内存:线程共享数据,需同步以避免冲突,效率高但易出错。
- 消息传递:通过消息通信避免共享状态,安全性高但可能引入延迟。
如何选择取决于性能、安全性和应用需求。
9. 结语
并行与并发是现代软件开发不可或缺的技术,它们使系统能够充分利用多核处理器和分布式环境,同时提升性能与响应性。尽管它们带来复杂性和挑战,但通过理论理解、工具支持和设计模式,开发者一定可以构建高效、可扩展的系统。
10. 参考文献
- Lamport, L. (1979). "How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs." IEEE Transactions on Computers, 28(9), 690-691.
- Herlihy, M., & Shavit, N. (2008). The Art of Multiprocessor Programming. Morgan Kaufmann.
- Amdahl, G. M. (1967). "Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities." AFIPS Conference Proceedings, 30, 483-485.
- Hoare, C. A. R. (1978). "Communicating Sequential Processes." Communications of the ACM, 21(8), 666-677.