
基础概念
这几年,随着生成式 AI 和大型语言模型(LLMs)的兴起,AI 领域整体迎来了一波大爆发。
随着各种基于 LLM 的应用程序在企业里落地,人们开始需要评估不同推理部署方案的性价比。
LLM 应用的部署成本,主要取决于它每秒能处理多少请求,同时还能保证对用户来说够快、回答也够准确。
这篇文章,主要聚焦在 LLM 吞吐量(throughput)和延迟(latency)的测量,这也是评估 LLM 应用成本的一部分。
评估 LLM 性能可以用各种工具来实现。市面上常用的这些客户端测试工具,虽然都能测 LLM 的性能指标,但每个工具对指标的定义、测量方式、计算公式都有点不一样。
这就导致,不同工具的测试结果,很难直接拿来互相比对。
所以这篇文章,会澄清常见的一些指标定义,以及流行测试工具在这些指标上的细微差别。同时,还会聊聊做基准测试时需要注意的一些重要参数。
负载测试 vs 性能基准测试
负载测试 和性能基准测试,其实是两种不同的测试方法。
- 负载测试 ,是模拟一大批用户同时访问模型,测试模型在高并发、真实使用场景下的表现。
主要是找出服务器容量、自动扩容策略、网络延迟、资源使用这些方面的问题。 - 性能基准测试 ,则是专注于测模型本身,比如它的吞吐量、响应延迟、每个 Token 的处理速度等等。
这主要用来发现模型效率、优化效果、以及配置合理性方面的问题。
简单讲,负载测试关心"顶得住多少人用",性能基准测试关心"跑得有多快"。
两种测试配合着做,能让开发者更全面了解自己 LLM 部署的能力,找到需要优化的地方。
LLM 推理是怎么回事
在开始讲具体测试指标之前,先搞懂 LLM 推理流程和相关术语。
一个 LLM 应用,在推理时一般分四步:
- Prompt(提示) :用户输入问题或者指令
- 排队(Queuing) :请求进入处理队列
- 预填(Prefill) :模型处理输入内容,为生成做好准备
- 生成(Generation) :模型一个 Token 一个 Token 地生成回答
这里要特别讲一下 Token ------这是 LLM 中的一个核心概念。
Token 是 LLM 处理自然语言时使用的最小单位,相当于"词片段"或"字串"。
每个模型都有自己的 Tokenizer ,会根据训练数据学出来,专门把文本切成 Token,以便更高效地处理。
大致来说,常见英文 LLM 里,一个 Token 差不多等于 0.75 个英文单词。
还有一些跟 Token 长度相关的重要概念:
- 输入序列长度(ISL) :送进模型的总 Token 数,包含用户的问题、系统提示、历史对话、链式推理内容(Chain-of-Thought)、以及检索增强(RAG)返回的文档等。
- 输出序列长度(OSL) :模型生成的 Token 数。
- 上下文长度(Context Length) :生成过程当前已处理过的所有 Token 数(包含输入和已经生成的部分)。
每个 LLM 都有个固定的最大上下文长度,输入+输出的 Token 总数不能超过这个上限。
另外,**流式输出(Streaming)**是一种让模型边生成边返回的模式。
比如在聊天机器人里,这样能让用户尽快看到初步回复,同时后台继续生成后面的内容。
如果不开启流式模式,就得等模型一口气把全部回答生成完,再一次性返回。
LLM 推理性能指标
这一部分,我们来解释一些业界常用的推理性能指标,比如"首 Token 时间"(Time to First Token,简称 TTFT)和"Token 间延迟"(Intertoken Latency,简称 ITL)。虽然这些指标听起来挺直观,但不同测试工具在定义和测量方式上,其实有一些细微但重要的差别。

图 1:LLM 推理性能指标
首 Token 时间(Time to First Token,TTFT)
TTFT 指的是:从用户发出请求,到模型生成第一个 Token所花的时间。
也就是说,用户输入问题后,要等多久才能看到模型给出的第一个字或者词。
需要注意的是,不同的基准测试工具(比如 GenAI-Perf 和 LLMPerf)在测 TTFT 时,通常会忽略那些"无内容"的初始响应,比如返回了空字符串或者没有生成任何 Token 的情况。这是因为,如果第一条返回的内容是空的,TTFT这个指标就没什么参考价值了。

图 2:生成第一个 Token 的过程
一般来说,TTFT 包含了几个阶段的耗时:
- 请求排队的时间
- 预填处理(Prefill)阶段的时间
- 网络传输延迟
而且,Prompt 越长,TTFT 通常也越高。
因为注意力机制(Attention)需要处理整个输入序列,构建所谓的 Key-Value(KV)缓存,才好进入后续的逐 Token 生成循环。
另外,真实生产环境里,通常会同时处理多个请求,所以有可能一个请求还在 Prefill,另一个请求已经开始 Generation。两者可能会互相叠加,影响整体响应时间。
端到端请求延迟(End-to-End Request Latency)
端到端延迟(简称 e2e_latency)指的是:从发出请求,到收到完整回复之间的总耗时。
它包括了排队时间、批处理(Batching)时间,以及网络延迟等因素。
在流式(Streaming)模式下,因为中途可以部分返回 Token,所以在收到最终完整响应之前,可能已经经历了多次中间 detokenization(反 Token 化)处理。

图 3:端到端请求延迟
对于单个请求来说,端到端延迟就是从请求发出 到最后一个 Token 返回的时间差。

需要注意的是,生成阶段的持续时间(generation_time)是从收到第一个 Token 到最后一个 Token 的时间跨度。同时,一些测试工具(比如 GenAI-Perf)会过滤掉最后的完成信号或者空白响应,不把这些算进 e2e_latency 里。
Token 间延迟(Intertoken Latency,ITL)
Token 间延迟,指的是连续两个 Token 生成之间的平均耗时。
有时候也叫每输出一个 Token 的时间(Time Per Output Token,TPOT)。

图 4:ITL ------连续生成 Token 之间的平均时间
虽然定义听着简单,不同工具在测量时还是有差别的。
比如说:
- GenAI-Perf :在计算 ITL 的时候不包含首 Token 时间(TTFT)
- LLMPerf :则是包含首 Token 时间在内
GenAI-Perf 的 ITL 公式大致是:

平均 Token 时间 = (收到最后一个 Token 的时间 - 收到第一个 Token 的时间) / (总 Token 数 - 1)
这里减 1,是为了把首 Token 排除掉,让 ITL 更准确地反映真正的解码(Decoding)阶段性能。
另外,随着输出 Token 数量增加,KV Cache 也会逐渐变大。
每生成一个新 Token,注意力机制的计算量也线性增长。不过通常,这个阶段不会是计算瓶颈。
如果 ITL 保持稳定,说明内存管理和带宽利用都做得不错,Attention 机制也处理得高效。
每秒生成 Token 数(Tokens Per Second,TPS)
TPS 是系统整体每秒生成多少个 Token 的量。
一开始,随着并发请求数增加,系统的 TPS 也会跟着增加,直到 GPU 资源被用满,TPS 就会趋于饱和,甚至可能开始下降。
比如,在一次完整的基准测试中,可以这么理解时间轴上的事件:
- Li:第 i 个请求的端到端延迟
- T_start:基准测试开始时间
- Tx:第一个请求发出的时间
- Ty:最后一个响应完成的时间
- T_end:基准测试结束时间

图 5:一次基准测试运行中的时间线
GenAI-Perf 将 TPS 定义为:总生成 Token 数除以第一个请求和最后一个请求的最后一个响应之间的端到端延迟时间:

LLMPerf 将 TPS 定义为:总生成 Token 数除以整个基准测试持续时间:

因此,LLMPerf 计算 TPS 时,还额外包含了以下开销:
- 输入 Prompt 的生成时间
- 请求准备时间
- 响应保存时间
根据我们的观察,在单并发(single concurrency)场景下,这些开销有时候可以占到整个基准测试持续时间的 33% 左右。
需要注意的是,TPS 的计算是批量(batch)完成的,不是实时(live)动态变化的指标。
另外,GenAI-Perf 使用了滑动窗口技术(sliding window technique)来寻找稳定的测量区间。
这意味着,最终统计的结果是基于一部分已经完成的代表性请求子集得出的,
也就是说,在计算时,会排除掉刚开始预热(warming up)和最后收尾阶段(cooling down)的请求。
每个用户的 TPS(TPS per user)表示从单个用户角度测量的吞吐量,定义为:

这个定义适用于单个用户的每次请求。
当输出序列长度不断增加时,TPS per user 的值会逐渐趋近于 1/ITL(即每个 Token 的平均生成时间的倒数)。
需要注意的是,随着系统中并发请求数的增加:
- 系统整体的总 TPS 会增加,
- 但单个用户的 TPS(TPS per user)会随着延迟增加而下降。
每秒请求数(Requests Per Second,RPS)
RPS 表示系统平均每秒能成功完成多少个请求。
它的计算方式比较简单,就是:
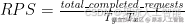
虽然 RPS 这个指标比 TPS 粗一些,但也很重要,尤其是对应用服务器层面的性能评估来说。
基准测试参数和最佳实践
这一节,我们来聊聊在做 LLM 性能测试时,一些非常重要的参数设定,以及它们应该怎么调。合理的测试设置,才能保证测试结果既靠谱,又能真正反映系统性能。
应用场景对 LLM 性能的影响
不同的应用场景,对输入(ISL)和输出(OSL)Token 数量的要求是完全不一样的。
而这些 Token 数的变化,直接影响系统消化输入、构建 KV 缓存、生成输出的速度。
一般来说:
- 输入序列越长,预填阶段(Prefill)需要的显存就越多,首 Token 时间(TTFT)就越高;
- 输出序列越长,生成阶段(Generation)对显存带宽和容量的要求也越高,Token 间延迟(ITL)就越大。
所以,在部署 LLM 时,一定要搞清楚自己应用场景里,输入和输出的长度分布情况。
这样才能更好地规划硬件资源,做到最优利用。
常见应用场景和它们的 ISL / OSL 特征举例:
- 翻译 :
包括语言翻译和代码翻译。特点是输入输出长度差不多,都在 500~2000 个 Token 左右。 - 内容生成 :
比如生成代码、故事、邮件正文或者通过检索生成一般性内容。
特点是输出很长(大概 1000 Token 量级),而输入通常很短(大概 100 Token 量级)。 - 摘要总结 :
包括检索、链式思考提示(CoT prompting)、多轮对话等场景。
特点是输入很长(大约 1000 Token 以上),输出很短(大约 100 Token)。 - 推理(Reasoning) :
最近的新型推理模型,比如做复杂推理、代码生成、数学题、逻辑谜题时,经常需要非常详细的链式思考、反思验证等。
特点是输入短(大概 100 Token),但输出超级长(1000 到 10000 Token 级别)。
负载控制参数(Load Control Parameters)
这里讲一些专门用来"施加负载"的参数。
- 并发数(Concurrency N) :
同时活跃的请求数,也可以理解为有多少个用户在同时发请求。
每当一个用户的请求完成,就立刻发起下一个请求,保证系统里随时有 N 个活跃请求。
通常,描述 LLM 推理负载最常用的就是并发数。 - 最大批处理大小(Max Batch Size) :
指推理引擎一次能同时处理的最多请求数。
这可能是并发请求的一个子集。
如果并发数超过了最大批处理大小 × 活跃副本数,多余的请求就得排队,等待后面有空位再处理。
这种情况下,TTFT(首 Token 时间)也会因为排队而变长。 - 请求速率(Request Rate) :
控制新请求发送频率的另一种方式。 恒定速率 (Constant Rate):每 1/r 秒发 1 个请求 泊松分布速率(Poisson Rate):请求之间的间隔时间是随机的,但平均速率固定
不同测试工具支持的负载控制方式也不太一样,有的更倾向用并发数,有的支持两种。
一般建议优先用并发控制,因为如果只控制发送速率,而系统处理不过来,未完成请求数可能会无限堆积。
小技巧:在设定测试参数时,可以从并发数 1 开始,逐步增加到略高于最大批处理大小的范围。
因为通常,在并发数接近最大批处理时,系统吞吐量会达到饱和,而延迟会继续上升。
其他重要参数
除了负载相关的,还有一些其他设置也会影响推理性能,或者影响测试准确性:
- 是否忽略 EOS(ignore_eos 参数) :
大多数 LLM 都有一个特别的"结束符"(EOS Token),表示生成结束。
正常推理时,模型遇到 EOS 就会停止生成。但在性能测试时,为了测到指定长度、保证每次输出长度一致,通常会设置忽略 EOS,让模型继续生成直到达到最大 Token 数。 - 采样策略(Sampling Parameters) :
不同的采样策略,比如: Greedy (每次选得分最高的 Token) Top-p (按累积概率筛选) Top-k (按最高 k 个概率选) Temperature(调整随机性)
都会影响生成速度。
比如 Greedy 策略最快,因为不用排序、归一化概率分布,直接拿最高分的 Token 就行了。
做基准测试时,不管选哪个采样方法,都要在整个测试过程中保持一致,避免引入额外干扰。
小结
LLM 性能基准测试,是确保模型既快又省钱、能支撑大规模部署的重要一步。
这篇文章讲了在基准测试时,最核心的性能指标、参数设定,以及一些好用的实践建议。
开始行动
给 LLM 做性能基准测试,是保证模型既能跑得快、又能在大规模部署时省钱、省资源的关键一步。
本文已经讲解了在进行 LLM 推理基准测试时,最重要的一些性能指标和参数设置。
如果你想更深入了解,可以参考这些方向:
- AI 推理:平衡成本、延迟和性能
(讲怎么在推理系统里做到又快又省) - 五分钟部署 LLM 微服务指南
(介绍快速部署小型推理微服务的方法) - 简单上手指南:用微服务部署生成式 AI
(手把手教你怎么搭一套生成式 AI 系统)