论文题目:RandAR: Decoder-only Autoregressive Visual Generation in Random Orders(随机顺序下仅解码器的自回归视觉生成)
会议:CVPR2025
摘要:我们介绍了RandAR,一种仅解码器的视觉自回归(AR)模型,能够以任意令牌顺序生成图像。与之前依赖于预定义生成顺序的纯解码器AR模型不同,RandAR消除了这种归纳偏差,解锁了纯解码器生成的新功能。我们的基本设计通过在每个要预测的图像标记之前插入"位置指令标记"来实现随机顺序,表示下一个图像标记的空间位置。RandAR在随机排列的标记序列上进行训练,这是一项比固定顺序生成更具挑战性的任务,它的性能与传统的光栅顺序相当。更重要的是,从随机指令训练的只有解码器的变压器获得了新的能力。针对AR模型的效率瓶颈,RandAR在推理时采用KV-Cache并行解码,在不牺牲生成质量的情况下享受2.5 ×加速。此外,RandAR以零样本学习的方式支持绘制,绘制和分辨率外推。我们希望RandAR能激发解码器视觉生成模型的新方向,并拓宽它们在不同场景中的应用
源码链接:https://rand-ar.github.io/

引言
在人工智能图像生成领域,autoregressive(自回归)模型一直扮演着重要角色。受到GPT等语言模型成功的启发,研究者们将"下一个token预测"的思想应用到图像生成中,诞生了VQGAN、LLaMAGen等经典模型。然而,这些模型都有一个共同的限制:必须按照预定义的顺序(通常是从左到右、从上到下的光栅顺序)生成图像。
今天要介绍的RandAR模型,彻底打破了这一传统限制,实现了真正意义上的随机顺序图像生成,为decoder-only模型开启了全新的可能性。
传统方法的局限性
单向偏置问题
传统的decoder-only图像生成模型存在一个根本性问题:单向偏置。由于必须按照固定的光栅顺序生成,模型只能利用"过去"的信息(已生成的token)来预测"未来"的token。这就像用一只眼睛看世界一样,无法充分理解2D图像中像素之间的复杂关系。
传统光栅顺序生成:
1 → 2 → 3
↓ ↓ ↓
4 → 5 → 6
↓ ↓ ↓
7 → 8 → 9在这种模式下,当生成位置5的内容时,模型只能看到位置1、2、4的信息,完全无法感知位置3、6、8、9的内容。这严重限制了模型对图像全局结构的理解。
应用场景受限
由于生成顺序固定,传统模型在以下任务中表现不佳:
- 图像修复(Inpainting):无法有效利用损坏区域周围的完整上下文信息
- 图像外延(Outpainting):只能采用滑动窗口等折衷方案,无法保证全局一致性
- 并行生成:必须严格按序生成,无法实现加速
RandAR的创新突破
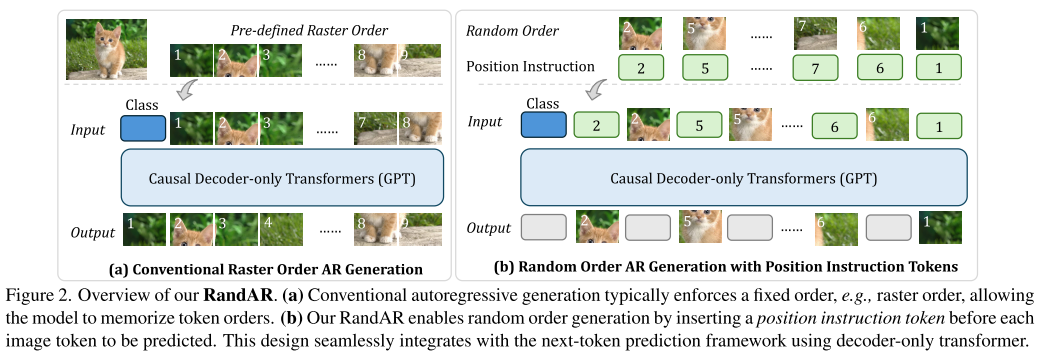
核心设计思想
RandAR的核心创新在于引入了位置指令token(Position Instruction Token)的概念。简单来说,就是在告诉模型要预测哪个token之前,先告诉它这个token应该放在图像的哪个位置。
传统方式:直接预测 → token_5
RandAR方式:位置指令[pos_5] → token_5这个看似简单的改动,却带来了革命性的变化。
技术实现细节
1. 随机排列序列
RandAR将原本有序的token序列进行随机打乱:
原始顺序:[token_1, token_2, token_3, ..., token_256]
随机顺序:[token_73, token_156, token_2, token_99, ...]2. 位置指令插入
在每个图像token前插入对应的位置指令:
最终序列:[pos_73, token_73, pos_156, token_156, pos_2, token_2, ...]3. 位置编码设计
位置指令token使用共享的可学习嵌入结合2D RoPE(旋转位置编码):
P_i = RoPE(e, h_i, w_i)其中e是共享嵌入,(h_i, w_i)是2D坐标。
训练策略
RandAR的训练比传统方法更具挑战性。对于256×256的图像(256个token),可能的排列数量达到256! ≈ 8×10^506。虽然训练过程中只能覆盖极小部分的排列组合,但模型却能学会在任意顺序下生成高质量图像。
令人惊喜的零样本能力
RandAR最令人兴奋的地方在于,仅仅通过随机顺序训练,就自然获得了多种零样本能力:
1. 并行解码加速
传统模型必须逐个生成token,而RandAR可以在一个前向传播中同时预测多个位置的token:
传统方式:256步 → 生成256个token
RandAR:88步 → 生成256个token(2.5×加速)性能对比:
- 推理延迟:从16.8秒降低到6.6秒
- 生成质量:几乎无损失(FID从2.22微升至2.25)
2. 图像修复能力

在图像修复任务中,RandAR可以利用损坏区域周围的所有可见像素作为上下文:
修复过程:
[可见区域tokens] + [位置指令] → [修复区域tokens]这种全上下文的修复方式,效果远超传统的单向修复。
3. 外延绘制

RandAR支持使用完整序列注意力进行图像外延,生成更加一致的扩展区域:
传统方法 vs RandAR:
- 传统:滑动窗口 → 局部一致性差
- RandAR:全序列注意力 → 全局一致性好
4. 分辨率外推
最令人惊喜的是,仅在256×256分辨率上训练的RandAR,可以零样本生成512×512的高分辨率图像!
两阶段生成策略:
- 生成偶数坐标位置的token(建立整体布局)
- 填充奇数坐标位置的token(添加细节信息)
5. 双向特征提取
通过两次前向传播,RandAR可以提取具有双向上下文的特征表示:
第一轮:获取单向特征
第二轮:整合双向信息 → 更好的特征表示在语义对应任务中,这种双向特征的PCK指标达到31.3%,相比单向特征的22.1%有显著提升。
实验结果与性能评估
生成质量
在ImageNet 256×256基准测试中,RandAR展现出与传统方法相当的生成质量:
| 模型 | 参数量 | FID↓ | IS↑ | 步数 |
|---|---|---|---|---|
| 光栅顺序对照模型 | 775M | 2.16 | 282.71 | 256 |
| RandAR-XL | 775M | 2.25 | 317.77 | 88 |
值得注意的是,RandAR在学习更困难任务的同时,仍然保持了竞争性的性能。
效率提升
并行解码带来的效率提升非常显著:
| 指标 | 传统方法 | RandAR | 改善 |
|---|---|---|---|
| 推理步数 | 256 | 88 | 2.9× |
| 推理延迟 | 16.8s | 6.6s | 2.5× |
| KV-Cache支持 | ✓ | ✓ | - |
零样本任务效果
在各种零样本任务中,RandAR都展现出了优秀的性能:
- 图像修复:能够生成与原图风格一致的修复内容
- 外延绘制:扩展区域与原图的衔接自然流畅
- 分辨率外推:512×512图像细节丰富,结构合理
- 特征提取:双向特征在下游任务中表现更佳
技术深度分析
位置指令设计的重要性
研究团队对位置指令token的设计进行了深入的消融研究:
设计方案对比:
- 默认方案:共享嵌入 + 2D RoPE(FID: 2.82)
- 密集嵌入:每个位置独立嵌入(FID: 3.07)
- 融合方案:位置信息直接加到图像token上(FID: 3.37)
结果表明,默认的共享嵌入方案在性能和参数效率之间达到了最佳平衡。
并行解码的技术细节
并行解码的实现巧妙地保持了训练时的序列格式:
# 并行解码示例(预测2个token)
输入:[P1, x1, ..., Pn-1, xn-1, Pn, Pn+1]
预测:[xn, xn+1]
重排:[P1, x1, ..., Pn-1, xn-1, Pn, xn, Pn+1, xn+1]这种设计确保了因果掩码的正确性,同时保持了KV-Cache的兼容性。
分辨率外推的创新方法
分辨率外推采用了分层解码策略,灵感来自频域分析:
- 布局阶段:生成偶数坐标的token,建立图像的整体结构
- 细化阶段:生成奇数坐标的token,添加高频细节信息
此外,还引入了**空间上下文引导(SCG)**技术,通过维护两个序列(原始序列和随机丢弃token的序列)来增强高频细节的生成质量。
局限性与未来方向
尽管RandAR取得了显著突破,但仍存在一些局限:
当前局限
- 高频细节生成:在极高分辨率外推时,某些精细结构的生成仍不够完美
- 计算复杂度:随机顺序训练相比固定顺序更加困难
- 外推比例限制:目前主要验证了2×分辨率外推,更大比例的外推有待探索
未来发展方向
- 更好的位置编码:探索更适合随机顺序的位置表示方法
- 多尺度训练:在训练时就引入多分辨率数据
- 更高效的并行策略:进一步提升并行解码的效率
- 跨模态应用:将随机顺序的思想扩展到文本-图像等跨模态任务
对领域的影响与意义
理论贡献
RandAR证明了一个重要观点:预定义的生成顺序并非decoder-only模型的必要约束。这为重新思考序列建模开辟了新的道路。
实用价值
- 统一架构:单一模型支持生成、修复、外延等多种任务
- 效率提升:并行解码显著减少推理时间
- 灵活性增强:可根据任务需求选择合适的生成顺序
启发意义
RandAR的成功启发我们思考:在其他序列建模任务中,是否也存在类似的固化假设需要被打破?
结论
RandAR代表了decoder-only图像生成模型的一个重要里程碑。通过引入简单而优雅的位置指令机制,它成功地将随机顺序生成引入到传统的自回归框架中,不仅保持了原有的生成质量,还获得了多种强大的零样本能力。
这项工作的意义不仅在于技术创新,更在于它打破了我们对传统序列建模的固有认知。正如论文作者所希望的,RandAR为decoder-only视觉生成模型指明了新的研究方向,相信会激发更多创新性的探索。
在AI图像生成日益重要的今天,RandAR的出现为我们提供了一个更加灵活、高效、功能丰富的工具。它告诉我们,有时候打破传统约束,反而能够释放出更大的潜力。