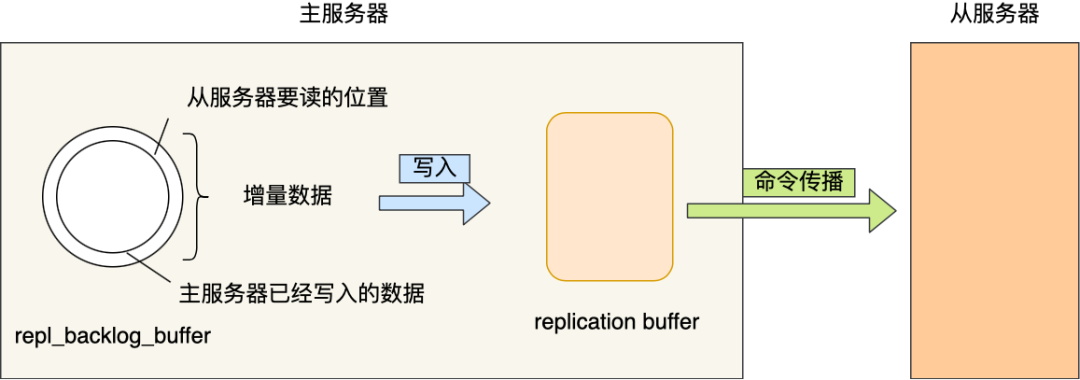
一、repl_backlog_buffer
复制积压缓冲区(Replication Backlog Buffer) 是一个环形内存区域(Ring Buffer),用于临时保存主节点最近写入的写命令,以支持从节点断线重连后的增量同步。
1.1 三个复制偏移量
复制偏移量(offset)是一个 64 位无符号整数 ,是主节点为所有写入操作生成的全局连续递增的序列号 ,表示从主节点启动以来所有写命令的字节总量(按 Redis 协议格式序列化后的字节数)。
例如:主节点执行
SET key value,这条命令会被序列化成 Redis 协议格式(如*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n),总字节数为 30 字节。此时,主节点的master_repl_offset会递增 30。Redis 的设计目标是长期运行的高吞吐系统。假设每秒写入 100MB 数据:耗尽时间 ≈ 1.84e19 / (100 * 1e6) / 31536000 ≈ 5845 年
- master_repl_offset:主节点复制偏移量,表示主节点已写入的复制数据流的总字节数
- 主节点重启或故障切换后,新主节点的 master_repl_offset 会重置;
- slave_repl_offset:从节点的复制进度;
- backlog_first_byte_offset:repl_backlog_buffer 的起始偏移量
- slave_repl_offset >= backlog_first_byte_offset,则增量同步;否则需全量同步;
1.2 repl_backlog_buffer 清理时机
- 缓冲区写满时覆盖旧数据:按照 FIFO 的方式循环覆盖旧数据;
- 所有从节点断开连接时释放缓冲区;