每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/


要点总结:
- 我们发布了 Llama 4 家族中的首批模型,让人们能够打造更加个性化的多模态体验。
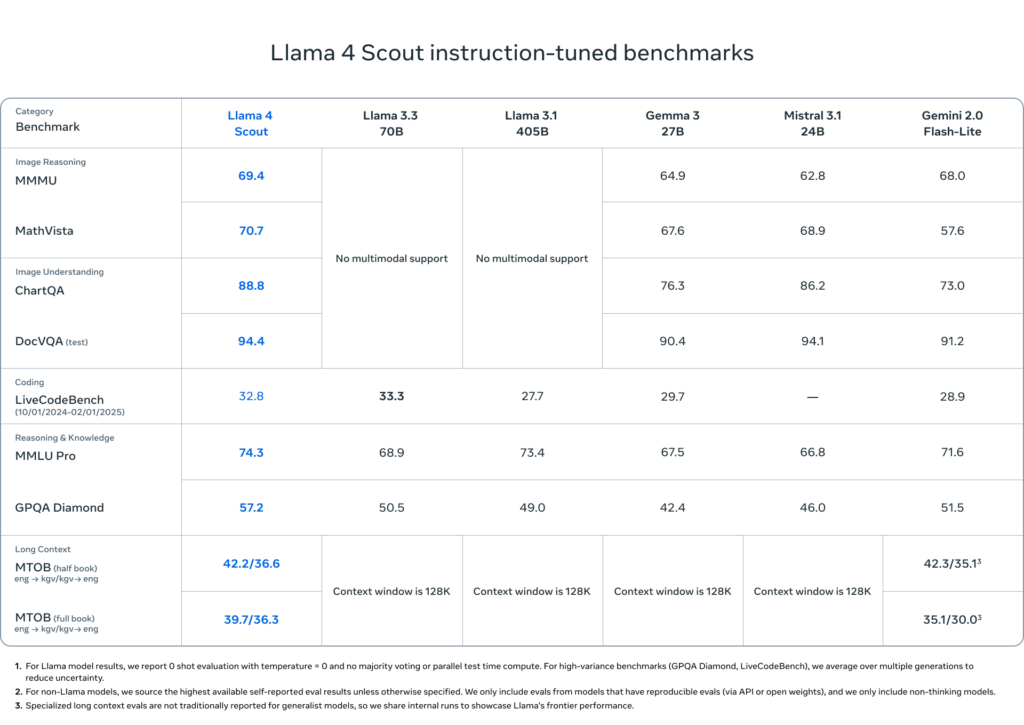
- Llama 4 Scout 是一款拥有 170 亿激活参数和 16 个专家模型的多模态模型,在同类模型中性能最强,胜过所有前代 Llama 模型,并可在单张 NVIDIA H100 GPU 上运行。此外,Llama 4 Scout 拥有业界领先的 1000 万上下文窗口,在多个知名基准测试中超越了 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
- Llama 4 Maverick 拥有 170 亿激活参数、128 个专家,是同类中最强的多模态模型,在广泛基准测试中优于 GPT-4o 和 Gemini 2.0 Flash,且在推理和编程能力方面达到与 DeepSeek v3 相当的水平------但参数量仅为后者的一半。Maverick 实验版聊天模型在 LMArena 中取得了 1417 的 ELO 分数,展现出卓越的性价比。
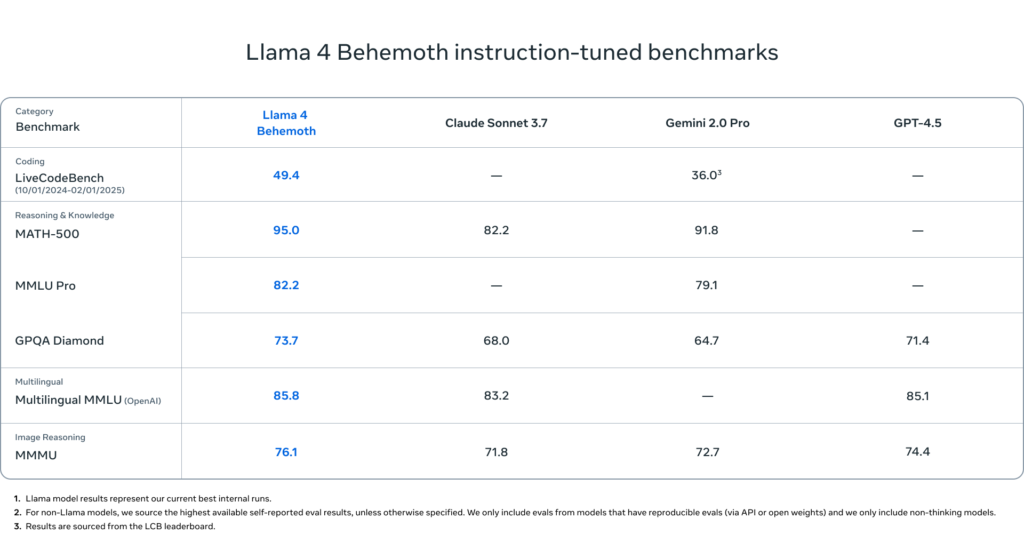
- 这些模型得益于 Llama 4 Behemoth 的蒸馏训练------这是我们目前最强大的模型,拥有 2880 亿激活参数和 16 个专家,是全球最智能的大型语言模型之一,在多项 STEM 基准上超越 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。Llama 4 Behemoth 仍在训练中,更多细节将持续披露。
- Llama 4 Scout 和 Maverick 模型现已开放下载(可在 llama.com 和 Hugging Face 获取),Meta AI 搭载 Llama 4 的版本也可在 WhatsApp、Messenger、Instagram Direct 和网页版使用。
多模态新时代的开启
我们隆重推出 Llama 4 Scout 和 Llama 4 Maverick,这是首批开源权重的原生多模态模型,支持前所未有的长上下文,并首次采用专家混合(MoE)架构。此外,我们还预览了 Llama 4 Behemoth,它是全球最强之一的大型语言模型,也是我们的教师模型。
这些新模型代表了 Llama 生态系统迈入新纪元的起点。Scout 模型设计紧凑,使用 INT4 量化后可以部署在单张 H100 GPU 上,而 Maverick 则部署于单台 H100 主机。它们均基于 Behemoth 模型蒸馏而成,后者在 STEM 领域表现出色。我们尚未开放 Behemoth 下载,但很快将分享更多技术细节。
我们始终相信,开放是推动创新的核心动力,对开发者、Meta 以及整个世界都有益。因此,Llama 4 Scout 和 Maverick 均已开放下载,我们也将通过合作伙伴提供更多渠道访问。你还可以在 Meta 旗下多款产品中直接体验 Llama 4。
模型训练与架构
Llama 4 是我们首批采用 专家混合(MoE)架构 的模型,其中每个 token 仅激活部分参数,从而大幅提高训练与推理效率。Maverick 模型拥有 4000 亿总参数,但仅使用 170 亿活跃参数,128 个专家交替启用,使得在 NVIDIA H100 上运行高效灵活,适合本地部署与分布式推理。
Llama 4 原生支持多模态,在骨干网络中通过 早期融合(early fusion) 将文本和图像 token 融合。我们还对视觉编码器进行了强化,使其更好地适应语言模型。我们开发的新训练技术 MetaP,可自动设定每层的学习率和初始化比例,确保模型在不同配置下的稳定性。
预训练使用超过 30 万亿 token(是 Llama 3 的两倍),支持 200 种语言,其中 100 多种语言的 token 数超过 10 亿。我们采用 FP8 精度训练,在 32K GPU 上达成了 390 TFLOPs/GPU 的利用率。
Scout 支持 1000 万的上下文窗口,远超 Llama 3 的 128K,为长文本处理和大规模代码分析提供可能。此外,我们采用了 iRoPE 架构,通过交错式注意力层和旋转位置编码的组合来支持超长上下文。
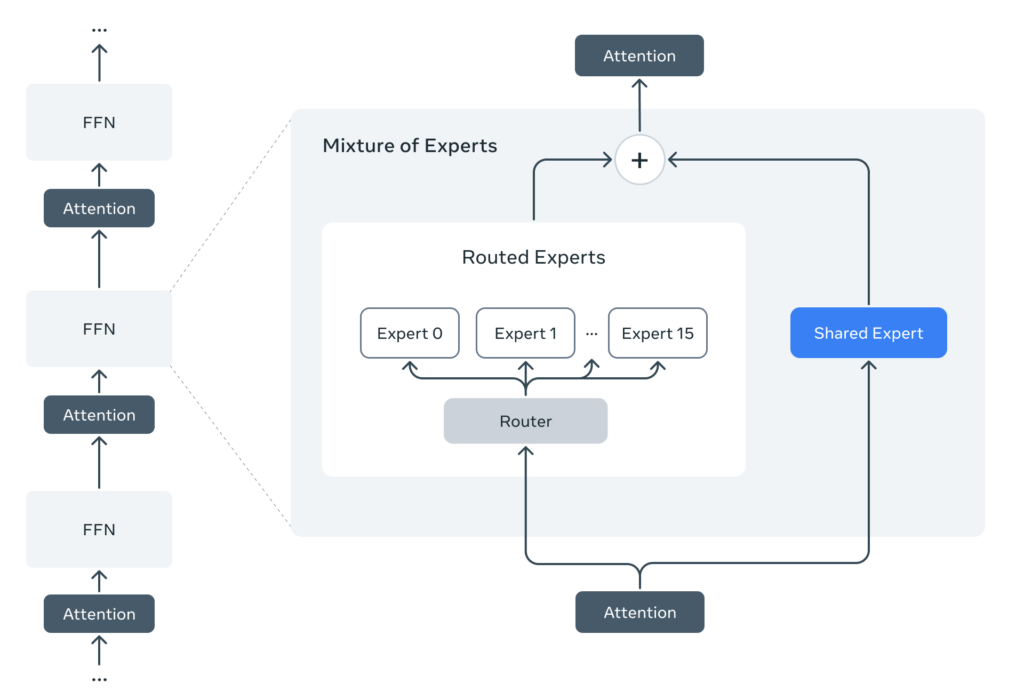
后训练与优化
Maverick 是我们面向通用助手和聊天用例的主力模型,擅长图像理解和创意写作。为平衡多模态输入、推理和对话能力,我们采用了全新后训练流程:
- 轻量监督微调(SFT)
- 在线强化学习(RL)
- 轻量直接偏好优化(DPO)
我们使用 Llama 模型作为"裁判",筛除超过 50% 的简单数据,仅在困难数据上进行微调。随后在在线 RL 阶段选用更高难度的提示,提升模型能力。通过动态数据筛选和系统指令多样化采样,我们大幅提升了模型的推理与编程能力。
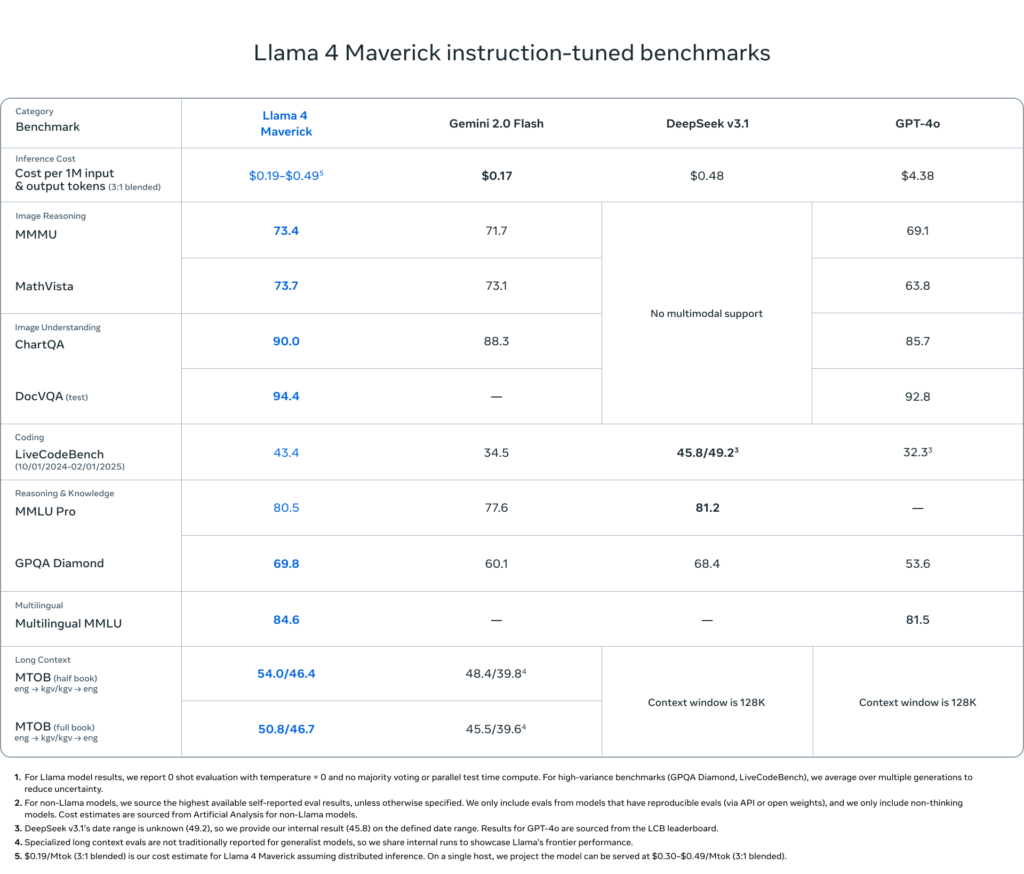
Maverick 的性能优于 GPT-4o 和 Gemini 2.0,在多语言、编程、图像、长上下文等领域均表现出色,并与 DeepSeek v3.1 相媲美。
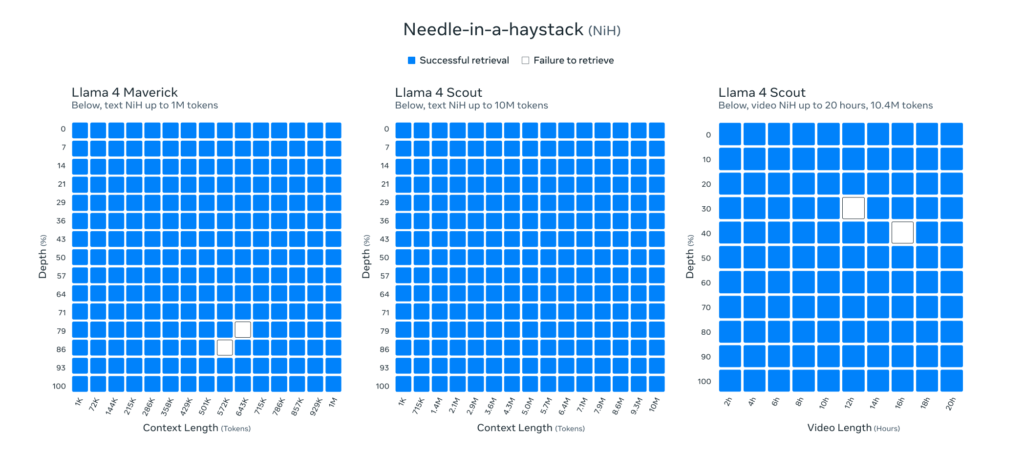
Scout 模型同样拥有 170 亿激活参数、16 个专家与 1090 亿总参数,在小模型中表现卓越,并在图像定位(image grounding)任务中表现领先,能够将用户提示与视觉概念精准对齐。
Llama 4 Behemoth:两万亿参数的巨兽
我们预览了 Llama 4 Behemoth,这是拥有 2880 亿激活参数、近两万亿总参数的多模态专家混合模型。Behemoth 不仅在数学、多语言和图像任务上表现顶尖,也是训练 Scout 和 Maverick 的教师模型。
我们为此开发了新型蒸馏损失函数,动态加权软标签与硬标签,通过 Behemoth 的推理结果生成训练数据,显著提升学生模型的表现。
由于模型体量庞大,后训练过程需对 SFT 数据进行 95% 精简,并在 RL 阶段构建高难度训练计划,通过分批难度分层、系统指令多样化提升模型泛化能力。我们重构了 RL 基础设施,实现 10 倍训练效率提升。
安全机制与保护
我们构建了 Llama 4 的全流程安全机制:
预训练与后训练防护
- 数据过滤与清洗
- 安全数据注入策略
系统级防护工具(已开源):
- Llama Guard:用于识别输入/输出是否违反应用安全政策
- Prompt Guard:识别恶意提示(如 Jailbreak 和注入攻击)
- CyberSecEval:评估模型网络安全风险
风险评估与红队测试
我们采用自动与人工相结合的方式进行模型极限测试,开发了 GOAT(生成式攻击测试) 工具,可模拟中等攻击者进行多轮交互,极大提升测试覆盖率与效率。
消除偏见的努力
我们努力减少模型在政治与社会话题上的偏见,让 Llama 能平衡呈现不同观点:
- Llama 4 在敏感议题上的拒答率由 7% 降至 2% 以下
- 拒答偏差(对某些立场过于敏感)降至 1% 以下
- 与 Llama 3.3 相比,Llama 4 的强偏政治倾向回答减少了一半,表现与 Grok 相当
拓展 Llama 生态系统
Llama 不只是模型,而是完整生态。除了模型本身,我们也在扩展产品集成,持续与开源社区合作。我们期待在 4 月 29 日的 LlamaCon 大会上分享更多未来愿景。
不论你是开发者、企业用户还是 AI 爱好者,Llama 4 Scout 和 Maverick 都是下一代智能产品的理想选择。我们也期待看到你用这些模型创造的精彩应用。