背景
前段时间接到需求要在内网部署DeepSeekR1:70b,由于手里的服务器和显卡比较差(四台 四块Tesla T4- 16g显存的服务器),先后尝试了ollama、vllm、llamacpp等,最后选择用vllm的分布式推理来部署。
需要准备的资源
- vllm的docker镜像(可以从docker hub 下载,使用docker save -o命令保存拿到内网服务器中)
- run_cluster.sh脚本(用来启动docker镜像和进行ray通信,下面会贴上我目前在用的版本)
- 模型文件(huggingface下载,国内可以用hf-mirror镜像站),需要下载到所有分布式机器的磁盘中,最好保持存储路径一致。
- nvidia驱动、cuda等是必备的,不提了
部署过程
-
载入vllm的docker镜像
docker load -i vllm.tar
-
编写脚本vi run_cluster.sh
所有机器都使用如下脚本
点击查看代码
``#!/bin/bash
# Check for minimum number of required arguments
if [ $# -lt 4 ]; then
echo "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"
exit 1
fi
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4
# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")
# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
# Define a function to cleanup on EXIT signal
cleanup() {
docker stop node
docker rm node
}
trap cleanup EXIT
# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# Run the docker command with the user specified parameters and additional arguments
#docker run \
# -d \
# --entrypoint /bin/bash \
docker run \
--entrypoint /bin/bash \
--network host \
--name node \
--shm-size 10.24g \
--gpus all \
-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \
"${ADDITIONAL_ARGS[@]}" \
"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"-
查看网卡信息
输入ip a
找到这台机器对应的编号,用在之后的启动命令中

-
启动脚本(每台机器都需要启动,选择任意一台为主节点,其他为工作节点)
启动命令:( --head为主机 --worker为其他机器使用,命令中的ip都需要填写主机的ip)
主机脚本 bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --head /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
工作机脚本 bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
后台运行 也可以通过nohup后台运行,如:nohup bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0 >/ray_file 2>&1 &
/data/vllm_model为你模型文件的位置,如下图则启动成功
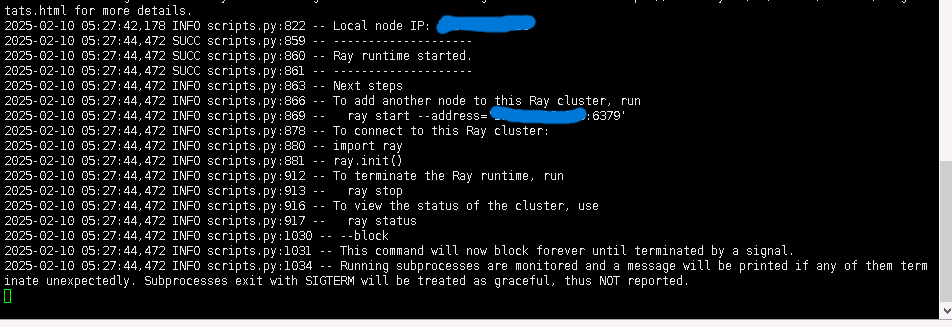
-
所有都成功启动后可以使用任何一台机器的ssh会话,因为已经通信,所以哪台机器都可以启动vllm。注意不要关闭任何一台机器的run_cluster启动的页面,
使用docker ps 查看运行的镜像
进入镜像内部
输入docker exec -it 镜像号 /bin/bash进入
输入ray status可以查看当前通信状态
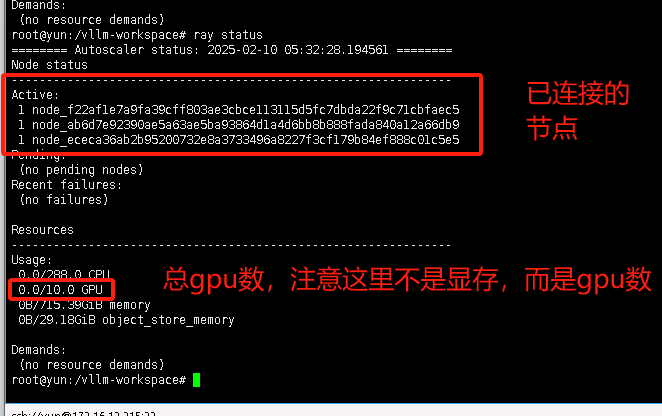
-
直接在docker中启动vllm
命令:vllm serve /model/DeepSeek-R1-Distill-Llama-70B --tensor-parallel-size 4 --pipeline-parallel-size 4 --dtype=float16
注:我的vllm运行命令中tensor-parallel对应每台服务器的gpu数,pipeline-parallel-size对应服务器数,--dtype=float16这个由于Tesla T4计算精度的问题需要添加这个配置降低模型的精度,如果显卡计算能力8.0以上可以不加这个配置。关于分布式并行的参数这里博主没有深究含义,如果有更好的使用方式也可以交流下。
参数含义
🔹 --tensor-parallel-size
这个参数表示 张量并行(Tensor Parallelism) 的规模。
将一个神经网络的 权重矩阵 切分到多个 GPU 上。
通常用于切分 Transformer 中的 attention 或 FFN 层的权重。
例如设置为 4,意味着一个 attention 层的计算会被分成 4 份,在 4 个 GPU 上并行进行。
适用于具有较大权重矩阵的模型,如 LLaMA、GPT 等,能充分利用多个 GPU 的显存和计算资源。
🔹 --pipeline-parallel-size
这个参数表示 流水线并行(Pipeline Parallelism) 的规模。
将整个模型的 不同层 分配到不同的 GPU 上,形成一个"流水线"。
每个 GPU 处理模型的一部分,然后把结果传给下一个 GPU。
设置为 2 表示模型被分成 2 段,分别在两个 GPU 上依次运行。
适用于模型层数较多时进一步扩展模型到更多 GPU 上。