言简意赅的讲解XTTS解决的痛点
📎 前置操作:如何使用 OBS Studio 录制高质量 WAV 语音(建议先阅读并准备录音样本)
本教程介绍如何使用 Coqui TTS 的 XTTS v2 模型 实现中文语音克隆,支持直接传入 .wav 文件,还原你的音色与语调,生成带有个性化音色的语音合成结果。
✅ 背景说明
与 ChatTTS 不同,XTTS v2 支持通过 speaker_wav 参数传入一个用户语音样本文件,自动提取发音人嵌入,无需手动处理 speaker_vector。
但前提是:音频格式必须标准,否者容易出现:
- 声音变形、模糊、爆音
- 模型推理失败(采样率错误 / 多声道)
所以我们准备了两套方案:
- 方案一:直接合成 ,适合你手头有干净、合规的
.wav - 方案二:带音频预处理,推荐使用,可处理 OBS 默认录音格式
🧰 安装依赖(推荐虚拟环境)
将以下内容保存为 requirements.txt:
txt
torch==2.7.1
torchaudio==2.7.1
TTS==0.22.0
numpy==1.24.3
scipy==1.11.4
soundfile==0.13.1安装命令:
bash
pip install -r requirements.txt🚀 方案一:快速语音克隆(需标准音频)
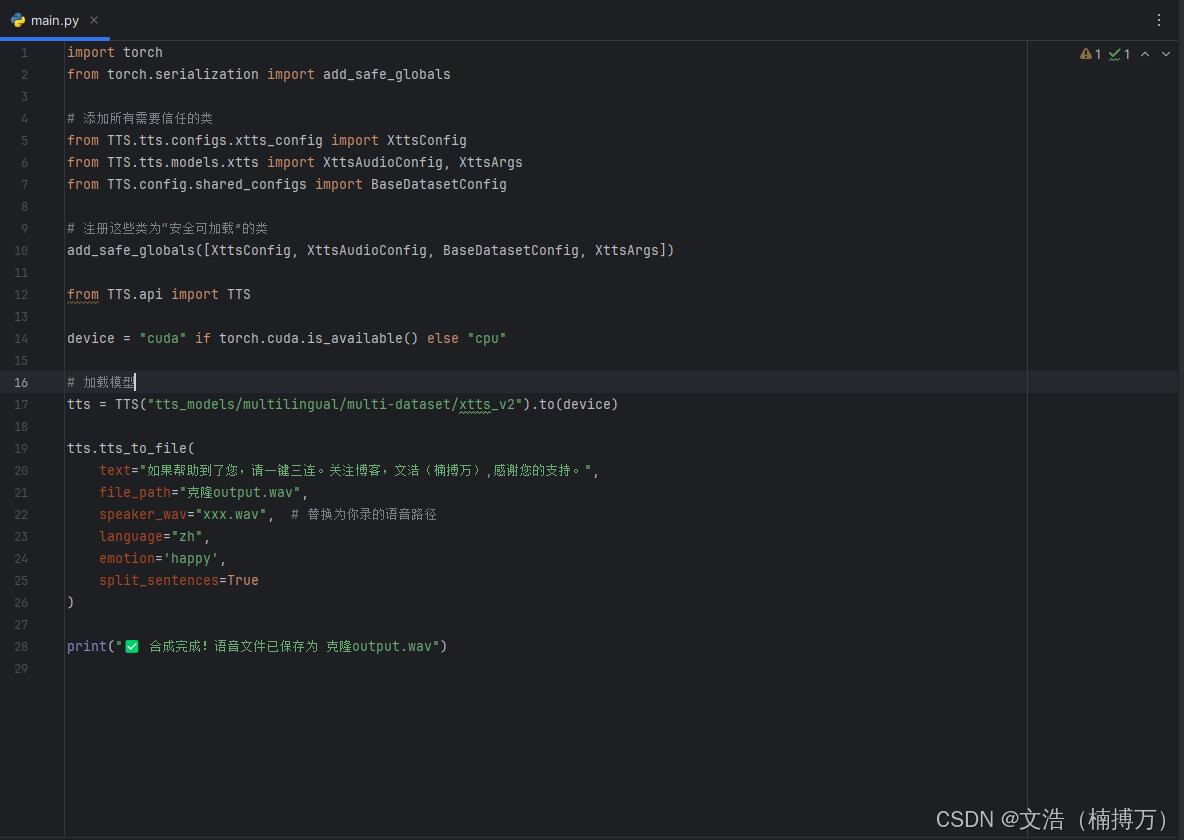
python
import torch
from torch.serialization import add_safe_globals
# 添加所有需要信任的类
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import XttsAudioConfig, XttsArgs
from TTS.config.shared_configs import BaseDatasetConfig
# 注册这些类为"安全可加载"的类
add_safe_globals([XttsConfig, XttsAudioConfig, BaseDatasetConfig, XttsArgs])
from TTS.api import TTS
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)
tts.tts_to_file(
text="如果帮助到了您,请一键三连。关注博客,文浩(楠搏万),感谢您的支持。",
file_path="克隆output.wav",
speaker_wav="xxx.wav", # 替换为你录的语音路径
language="zh",
emotion='happy',
split_sentences=True
)
print("✅ 合成完成!语音文件已保存为 克隆output.wav")🎧 试听下载 :克隆output.wav(← 请替换为实际试听链接)
🧼 方案二:推荐做法(自动处理音频格式)
OBS 默认输出通常是 44.1kHz / 双声道,XTTS 模型不兼容。以下脚本会自动处理格式问题:
python
import torch
from torch.serialization import add_safe_globals
# 先注册这些类为可信任的全局对象
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import XttsAudioConfig, XttsArgs
from TTS.config.shared_configs import BaseDatasetConfig
add_safe_globals([XttsConfig, XttsAudioConfig, BaseDatasetConfig, XttsArgs])
# 再导入 TTS
from TTS.api import TTS
import torchaudio
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)
# 预处理你的 speaker 音频
def preprocess_wav(path, out_path="clean.wav"):
signal, sr = torchaudio.load(path)
if signal.shape[0] > 1:
signal = signal.mean(dim=0, keepdim=True)
if sr != 16000:
resample = torchaudio.transforms.Resample(orig_freq=sr, new_freq=16000)
signal = resample(signal)
torchaudio.save(out_path, signal, 16000)
return out_path
speaker_wav = preprocess_wav("xxx.wav") # 替换为你录的语音路径
# 合成文本
my_text = "如果帮助到了您,请一键三连。关注博客,文浩(楠搏万),感谢您的支持。"
# 合成并保存
tts.tts_to_file(
text=my_text,
speaker_wav=speaker_wav,
file_path="克隆过滤版output.wav",
language="zh",
split_sentences=True,
emotion='happy',
speed=1.2
)
print("✅ 合成完成,输出为 克隆过滤版output.wav")🎧 试听下载 :克隆过滤版output.wav(← 请替换为实际试听链接)
🎛️ 可调参数说明(重点推荐)
| 参数名 | 功能描述 | 示例 |
|---|---|---|
emotion |
控制语气,如 'happy' |
'happy' |
speed |
控制语速,1.0为默认 | 1.2 |
split_sentences |
自动分句朗读 | True |
language |
设置合成语言(中文为 "zh") |
"zh" |
🔁 音频来源建议
-
使用 OBS Studio 录音时:
- 格式设为
.wav - 采样率设置为 48kHz(后续会统一成16kHz)
- 声道选单声道或立体声(脚本可自动降维)
- 格式设为
-
录音内容控制在 5~15 秒
-
自然语气朗读,普通话标准即可
通过上述内容,你就已经基本理解了这个方法,基础用法我也都有展示。如果你能融会贯通,我相信你会很强
Best
Wenhao (楠博万)