五、大语言模型
1.NLP
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,专注于研究 计算机如何理解、生成和处理人类语言。它的目标是让机器能够像人类一样"读懂"文本或语音,并执 行翻译、问答、摘要等任务。
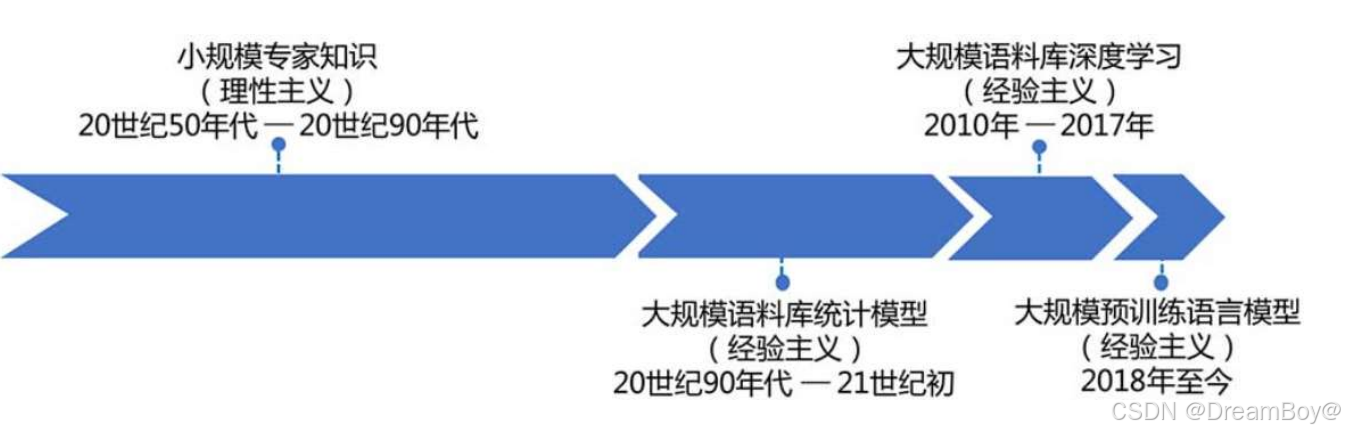
大模型不仅仅是模型规模庞大,也涵盖了训练数据规模庞大,以及由此衍生出的模型能力的强大。
截止 2024 年 6 月,国内外已经见证了超过百种大语言模型的诞生,这些大语言模型在学术界和工业界 均产生了深远的影响。
2.Scaling Laws(尺度定律)
描述了在模型规模(参数量)、数据量和计算量等资源增加时,模型性 能如何变化的规律。这些规律是由一系列实验发现并总结出来的,帮助研究者理解大型模型的行为,优 化资源配置,以及预测更大规模模型的表现。
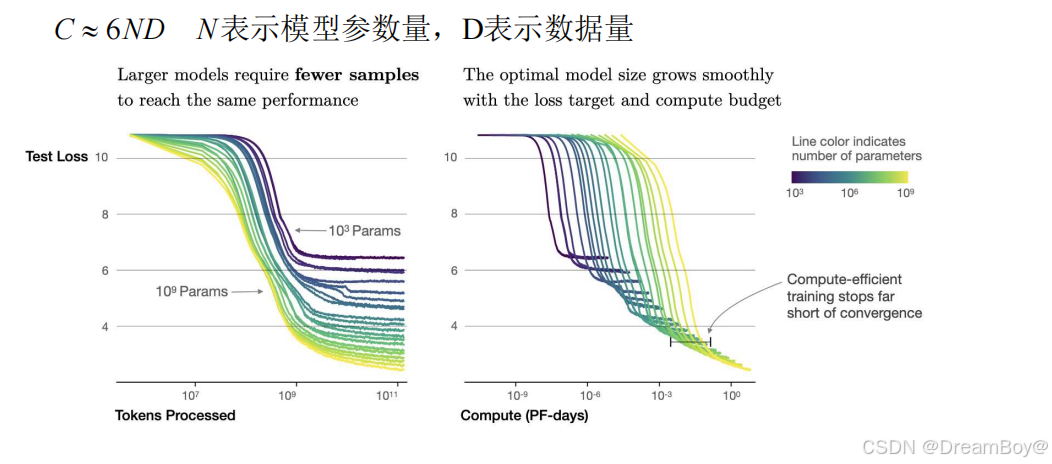
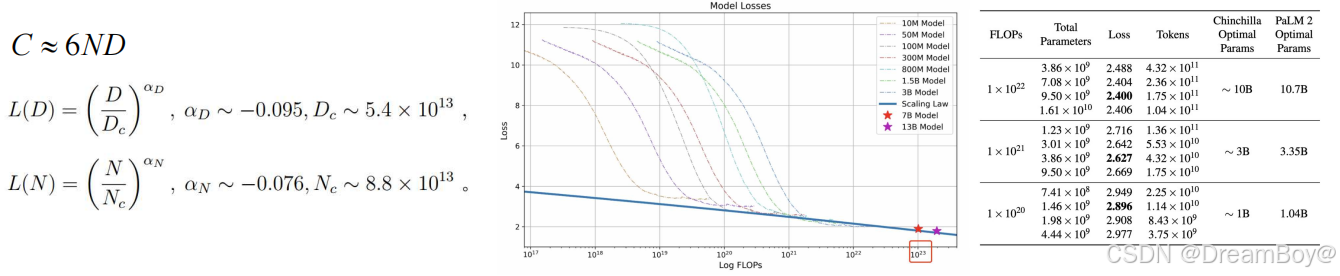
在这一条件下,如果计算预算增加,为了达到最优模型性能,数据集的规模 D 以及模型规模 N 都
应同步增加。**模型规模的增长速度应该略快于数据规模的增长速度。**有争议,如OPENAI遵循上述规则,但是DeepMind却减小模型规模的增长,更加重视数据的增长。
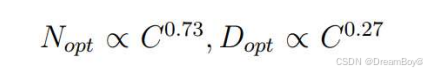

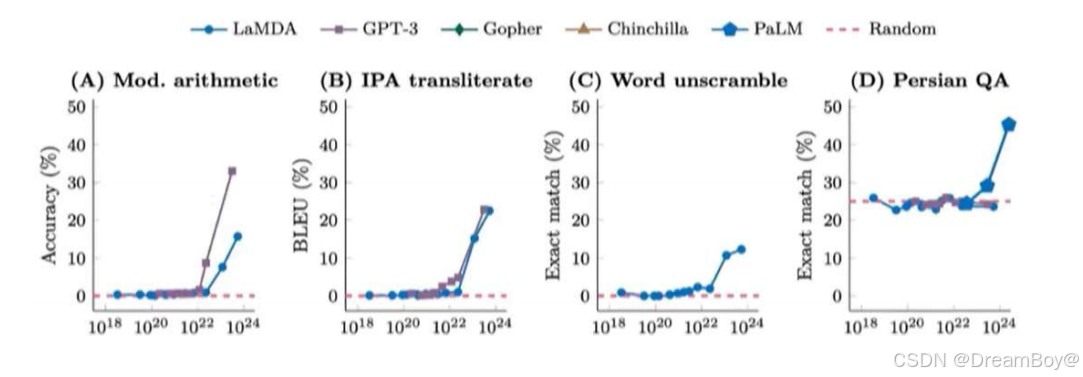
3.涌现
涌现能力的概念源自于物理学中的定义,即当系统的量变导致行为的质变的现象。在大规模语言模
型中,涌现能力表现为在小模型中没有表现出来,但是在大模型中变现出来的能力。
上下文学习能力
常识推理能力
数学运算能力
代码生成能力
值得注意的是,这些新能力并非通过在特定下游任务上通过训练获得,而是随着模型复杂度的提升
凭空自然涌现。这些能力因此被称为大语言模型的涌现能力。
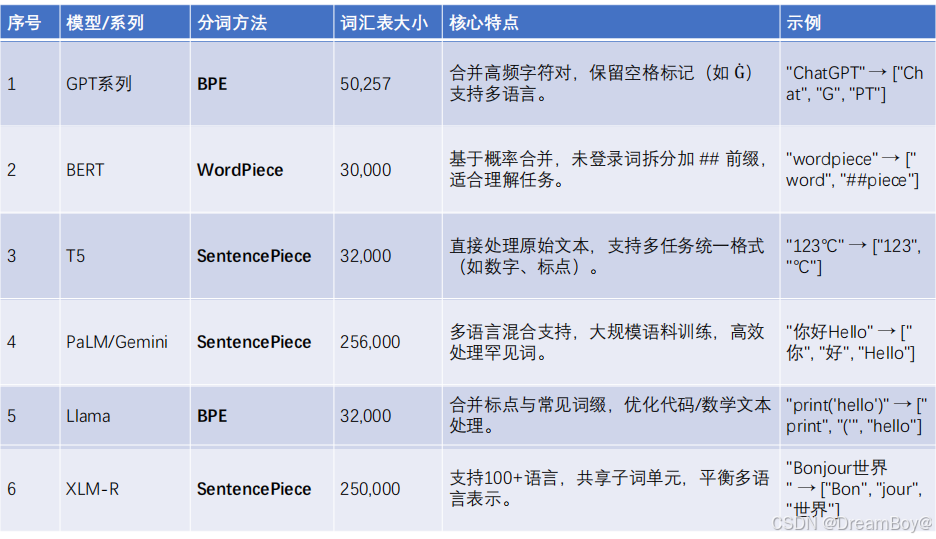
4.Token 与分词
在自然语言处理中,Token指文本处理的基本单位。Tokenization(分词) 指把文本内容处理为最小基本单 元,即token,用于后续的处理。按照划分粒度分为:单词(word)、子词(subword)或字符(character)。