1.什么是 CountVectorizer
CountVectorizer 是 scikit-learn 中用于文本特征提取的工具之一,其核心功能是 将文本转换为词频矩阵(Bag of Words)。
通俗理解:
-
文本 → 词的集合(去掉顺序) → 每个词出现次数 → 数值向量表示
-
它属于 词袋模型(Bag of Words, BoW) 的实现
数学表达
假设有一个文档集合 D={d1,d2,...,dn},词汇表V={w1,w2,...,wm}:
- 对于文档 di,CountVectorizer 会计算每个词 wj 在文档中的出现次数:
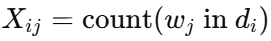
最终得到矩阵 X 形状为 (n,m),即 文档数 × 词汇表大小。
2.CountVectorizer 的核心流程
-
文本预处理
-
小写化(默认将文本转为小写)
-
去掉标点符号(可以自定义)
-
可以去掉停用词(如"的、是、and"等)
-
-
分词(Tokenization)
-
将每篇文档拆分为一个个 token(单词或字符)
-
默认以空格或正则匹配拆分,也可以自定义分词函数
-
-
建立词汇表(Vocabulary)
-
收集训练语料中的所有 token
-
词汇表通常按字典顺序或出现顺序排列
-
每个词分配唯一索引
-
-
统计词频(Counting)
-
遍历每篇文档
-
计算文档中每个词在词汇表中的出现次数
-
输出文档-词矩阵(sparse matrix 推荐存储)
-
3. 函数原型
class sklearn.feature_extraction.text.CountVectorizer(
input='content', # 输入类型:'filename','file','content'
encoding='utf-8', # 文本编码
decode_error='strict', # 解码错误处理方式
strip_accents=None, # 是否去掉重音符号
lowercase=True, # 是否将文本转换为小写
preprocessor=None, # 自定义预处理函数
tokenizer=None, # 自定义分词函数
stop_words=None, # 停用词列表
token_pattern=r"(?u)\b\w\w+\b", # 正则表达式匹配 token
ngram_range=(1, 1), # n-gram 范围,如 (1,2) 表示提取一元和二元词组
analyzer='word', # 分析单位:'word' 或 'char'
max_df=1.0, # 词语在文档中出现比例的上限(超过忽略)
min_df=1, # 词语在文档中出现比例或次数的下限(低于忽略)
max_features=None, # 仅考虑前 N 个最常出现的词语
vocabulary=None, # 自定义词汇表
binary=False, # True 表示只记录存在与否,不记录频率
dtype=np.int64 # 输出矩阵的数据类型
)
4. 常用参数解析
| 参数 | 作用 |
|---|---|
lowercase |
是否将文本转换为小写,默认 True |
stop_words |
是否去停用词,可选 'english' 或自定义列表 |
max_features |
最大词汇数量,按词频选择最常见的前 k 个 |
ngram_range |
控制 n-gram 范围,默认 (1,1),如 (1,2) 表示 unigrams + bigrams |
analyzer |
分词方式,'word' 或 'char',甚至可以自定义 |
token_pattern |
正则匹配 token 的模式,默认 r"(?u)\b\w\w+\b" |
5. 使用示例
"""
CountVectorizer 是 scikit-learn 库中一个常用的文本特征提取工具,它将文本数据转换为基于词频的数值特征矩阵。
其主要工作原理是:
对文本集合进行分词处理
构建词汇表(所有文档中出现的不重复词语集合)
统计每个词语在各文档中的出现次数,形成词频矩阵
"""from sklearn.feature_extraction.text import CountVectorizer
corpus = [
"I love NLP",
"NLP is fun",
"I love learning NLP"
]
# 初始化 CountVectorizer
vectorizer = CountVectorizer()
# 拟合语料并转换为矩阵
X = vectorizer.fit_transform(corpus)
print("词汇表:", vectorizer.get_feature_names_out())
print("文档-词矩阵:\n", X.toarray())输出示例
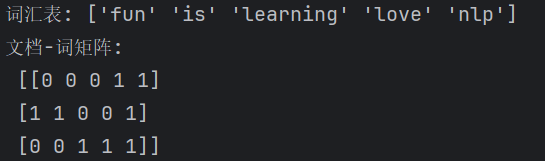
.get_feature_names()返回词汇表
.fit_transform()返回每个文档对应的词频向量
进阶理解
-
稀疏矩阵
- 文档-词矩阵通常很大且稀疏(大多数词在大多数文档中不出现),所以 CountVectorizer 返回
scipy.sparse矩阵以节省内存。
- 文档-词矩阵通常很大且稀疏(大多数词在大多数文档中不出现),所以 CountVectorizer 返回
-
和 TF-IDF 的关系
- CountVectorizer 只统计出现次数,而
TfidfVectorizer在此基础上加上了逆文档频率权重(IDF)。
- CountVectorizer 只统计出现次数,而
-
支持 n-gram
- 不止单词频率,还可以统计连续词组:
CountVectorizer(ngram_range=(1,2)) # unigrams + bigrams
6. 总结
CountVectorizer 是文本特征工程中非常基础且实用的工具,它能够快速将文本转换为可用于机器学习模型的数值特征矩阵。
通过合理调整参数(如 ngram_range、max_features、stop_words 等),可以灵活控制特征的粒度和数量,从而适应不同的 NLP 任务。
机器学习方法里常见的词向量表示方式 vs 深度学习方法里的词向量表示方式
| 类别 | 方法 | 特点 |
|---|---|---|
| 机器学习(传统词向量) 主要是 基于统计和矩阵分解 的方法 | CountVectorizer(词袋模型) | * 向量值 = 词频统计。 * 文档 → 稀疏向量(几万维)。 |
| TF-IDF | * 改进 CountVectorizer,降低常见词的权重,提升关键字权重。 | |
| One-Hot Encoding | * 每个词用一个长度等于词表大小的向量表示,某一维为 1,其余为 0。 * 缺点:高维稀疏,没有语义关系。 | |
| LSA(Latent Semantic Analysis,潜在语义分析) | * 对 词-文档矩阵 做 SVD(奇异值分解),降维得到稠密向量。 * 能捕捉部分语义,但仍然依赖统计。 | |
| LDA(Latent Dirichlet Allocation,主题模型) | * 用主题分布表示文档或词,得到低维向量。 * 语义解释更好,但仍基于概率统计。 | |
| 深度学习(分布式词向量) 主要是 神经网络学习得到的嵌入 | Word2Vec | * CBOW(上下文预测中心词) * Skip-gram(中心词预测上下文) * 结果:静态词向量(同一个词在不同上下文中的向量相同)。 |
| GloVe | * 基于全局词共现矩阵 + 神经网络优化,得到静态词向量。 | |
| FastText | * Word2Vec 升级版,把词拆成子词(n-gram),解决 OOV 问题。 | |
| ELMo(基于双向 LSTM) | * 上下文相关词向量,能区分同形异义词。 | |
| BERT(Transformer) | Transformer,动态语义向量 | |
| GPT系列 | * 生成式模型的词向量,同样基于 Transformer。 * 上下文依赖更强,适合生成任务。 |