目录
1、需求
迁移部分新集群没有的索引和数据
2、工具elasticdump
Elasticdump 的工作原理是将输入发送到输出 。两者都可以是 elasticsearch URL 或 File
2.1 mac安装
前置:已经安装有npm
npm install elasticdump -g(-g 全局)
报错:
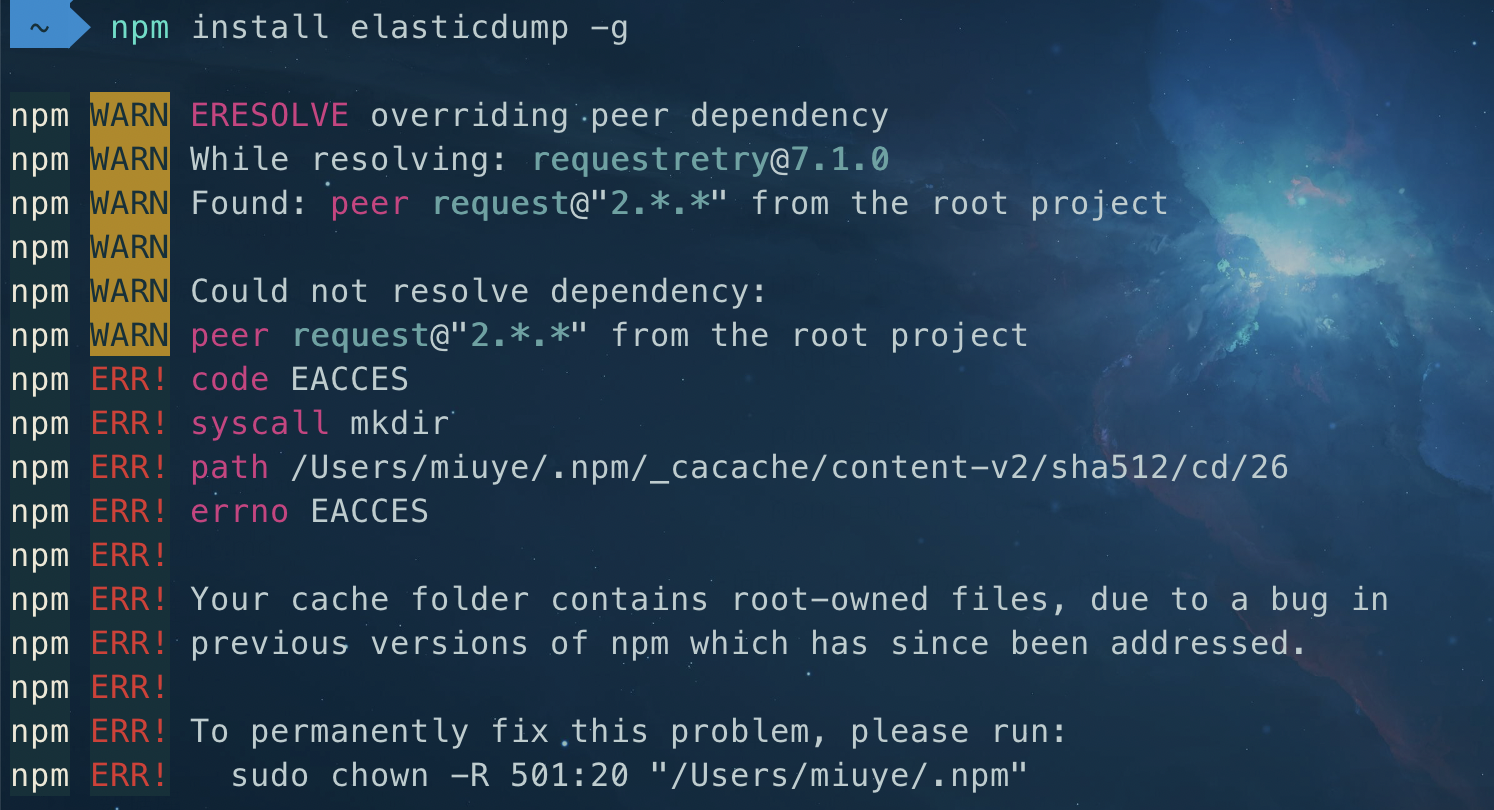
npm WARN ERESOLVE overriding peer dependency
npm WARN While resolving: requestretry@7.1.0
npm WARN Found: peer request@"2.." from the root project
npm WARN npm WARN Could not resolve dependency:
npm WARN peer request@"2.." from the root project
npm ERR! code EACCES
npm ERR! syscall mkdir
npm ERR! path /Users/miuye/.npm/_cacache/content-v2/sha512/cd/26
npm ERR! errno EACCES
npm ERR!
npm ERR! Your cache folder contains root-owned files, due to a bug in
npm ERR! previous versions of npm which has since been addressed.
npm ERR!
npm ERR! To permanently fix this problem, please run:
npm ERR! sudo chown -R 501:20 "/Users/miuye/.npm"
问题
1、依赖冲突 2、权限不足
解决
# 升级相关包
sudo npm install requestretry@latest -g
# sudo重新执行
sudo npm install elasticdump -g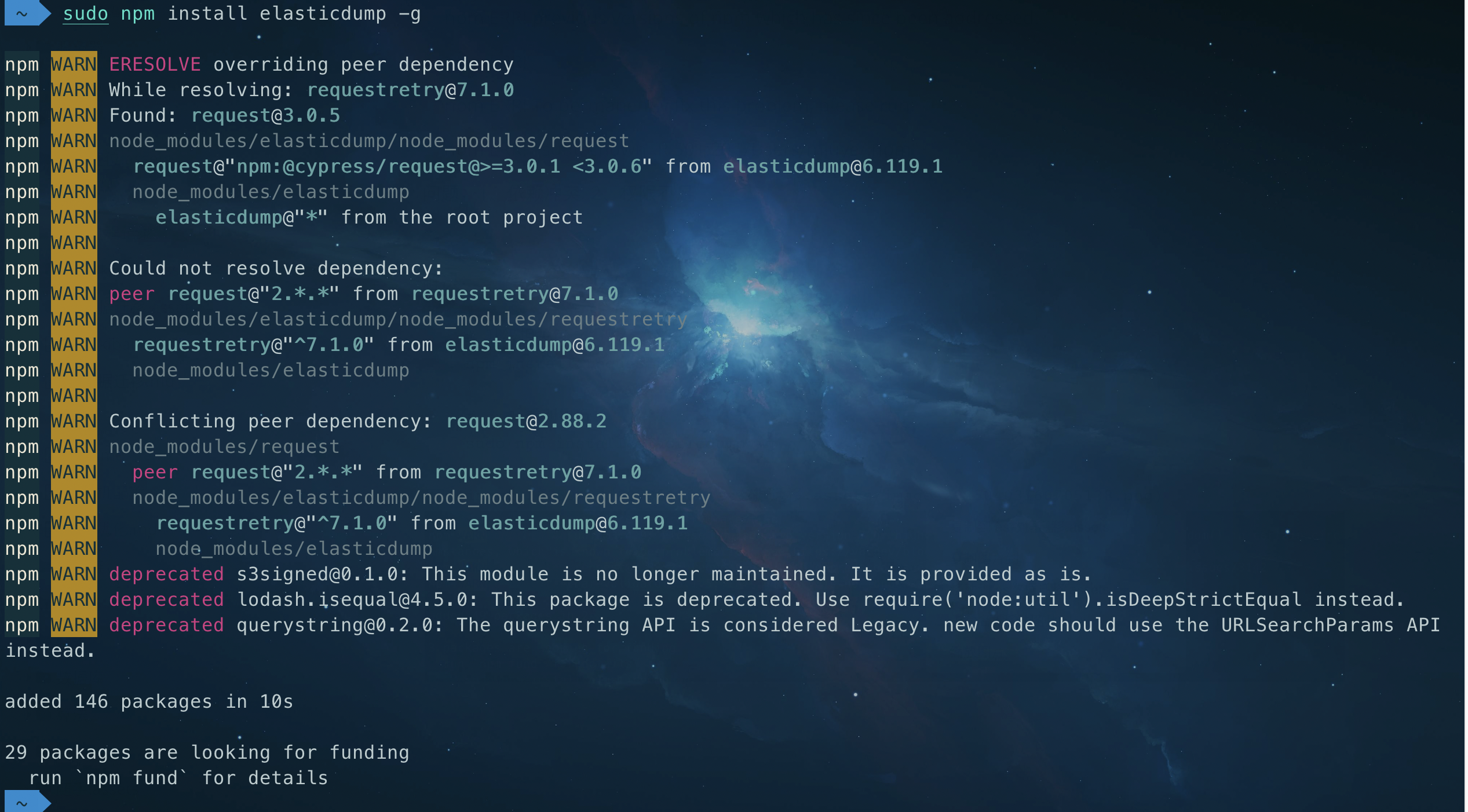
2.2 elasticdump文档
https://github.com/taskrabbit/elasticsearch-dump
3、迁移
迁移mapping
elasticdump --input="http://username:password@testing.es.com:9200/my_index" --output="http://username:password@staging.es.com:9200/$INDEX_NAME" --type=mapping
迁移data
elasticdump --input="http://username:password@testing.es.com:9200/my_index" --output="http://username:password@staging.es.com:9200/$INDEX_NAME" --type=data
【注意】:鉴权的用户名和密码写在url中,以@分割,无鉴权就只写es url
如果目的es中已经存在对应资源,会报错,可以设置--skip-existing=true,如果资源存在,不报错
我使用的脚本进行对比和迁移,如果需要新集群的配置信息和新集群保持一致,可以先迁移setting
shell
#!/bin/bash
# 源集群和目标集群的配置
SOURCE_ES_URL="http://testing.es.com:9200"
TARGET_ES_URL="http://staging.es.com:9200"
SOURCE_USERNAME="testing"
SOURCE_PASSWORD="123456"
TARGET_USERNAME="staging"
TARGET_PASSWORD="123456"
# 获取源集群中所有索引的名称
INDEXES=$(curl -u $SOURCE_USERNAME:$SOURCE_PASSWORD -s -X GET "$SOURCE_ES_URL/_cat/indices?h=index&s=index")
while IFS= read -r INDEX_NAME; do
# 只迁移以_dev结尾的
if [[ "$INDEX_NAME" == *_dev ]]; then
# 查询新集群索引
INDEX_EXISTS=$(curl -u $TARGET_USERNAME:$TARGET_PASSWORD -s -o /dev/null -w "%{http_code}" -X GET "$TARGET_ES_URL/$INDEX_NAME")
# 检查 curl 命令是否成功
if [ $? -ne 0 ]; then
echo "Failed to check index existence for $INDEX_NAME"
continue
fi
if [ "$INDEX_EXISTS" -eq 200 ]; then
echo "Index $INDEX_NAME exists, jump"
elif [ "$INDEX_EXISTS" -eq 404 ]; then
echo "Index $INDEX_NAME not exists, transfer..."
# 迁移结构
elasticdump --input="http://$SOURCE_USERNAME:$SOURCE_PASSWORD@testing.es.com:9200/$INDEX_NAME" --output="http://$TARGET_USERNAME:$TARGET_PASSWORD@staging.es.com:9200/$INDEX_NAME" --type=mapping
# 迁移数据
elasticdump --input="http://$SOURCE_USERNAME:$SOURCE_PASSWORD@testing.es.com:9200/$INDEX_NAME" --output="http://$TARGET_USERNAME:$TARGET_PASSWORD@staging.es.com:9200/$INDEX_NAME" --type=data
else
echo "Unknown $INDEX_EXISTS for $INDEX_NAME"
fi
fi
done <<< "$INDEXES"