一. 初识 Redis
Redis 是一个在内存中存储数据的中间件. 主要用于作为数据库, 作为数据缓存. 主要应用在分布式系统中.
Redis 最核心的特点是将数据存储在内存中.
Redis 是在分布式系统中 才能发挥威力的 ~ 如果只是单机程序, 直接通过变量的方式存储数据, 是比使用 Redis 更优的选择.
MySQL 最大的问题在于访问速度比较慢. 访问内存的速度比访问硬盘的速度快几个数量级.
和 MySQL相比, Redis 最大的劣势在于它的存储空间有限.
开发中的典型方案是把 Redis 和 MySQL 结合起来使用.
1. 浅谈分布式系统
1.1 单机架构:
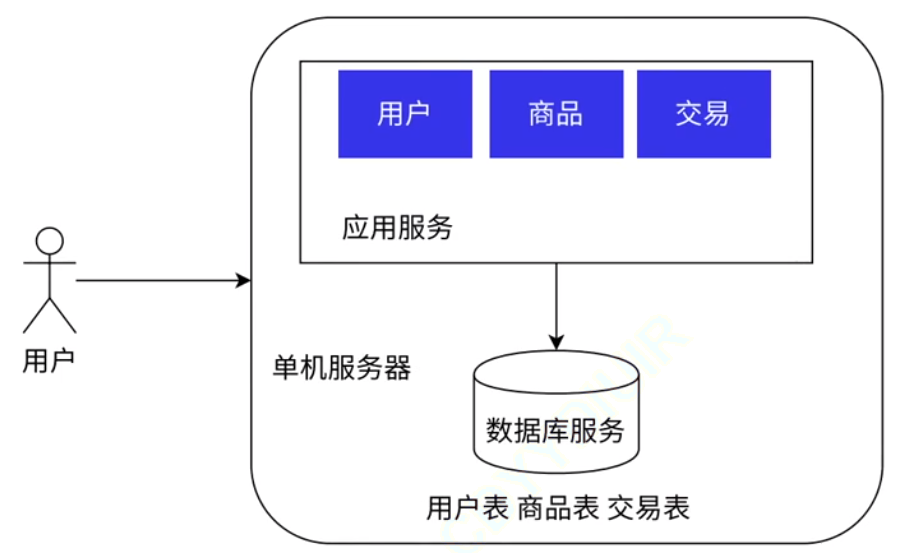
整个项目, 包括数据库服务器, 都部署到一台服务器上.
现在绝大多数公司的产品, 还是在采用单机架构 (足以应付小规模的用户量和数据量).
1.2 分布式架构:
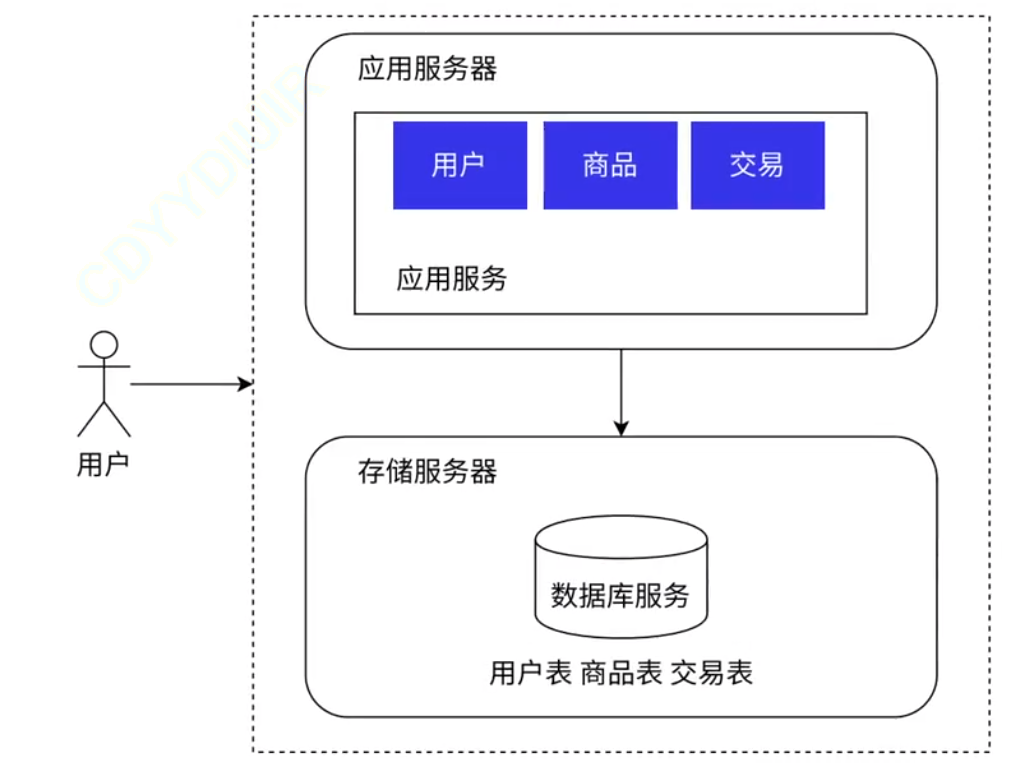
(两台服务器: 应用服务器 + 存储服务器. 将业务和存储分离)
1.3 引入负载均衡器 (网关):
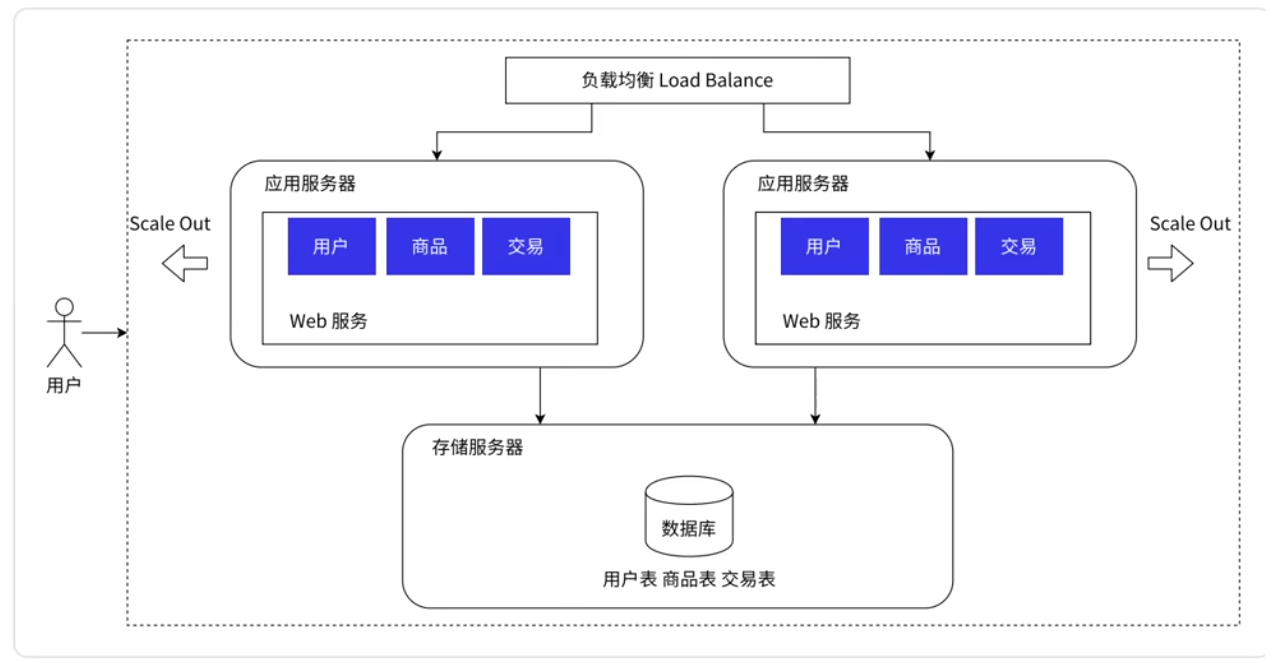
多台应用服务器
负载均衡器 (又叫网关): 用于分配任务, 使多台服务器处理的任务量尽可能均衡 (负载均衡器有很多具体的负载均衡算法).
类比: 负载均衡器是领导 (分配任务) ; 应用服务器是组员 (执行任务).
但此时数据库压力又大了, 怎么办? --> 开源节流 (1. 增加数据库服务器数量 ; 2. 数据库调优)
我们采用第二种方法: 数据库调优.
1.4 数据库读写分离:
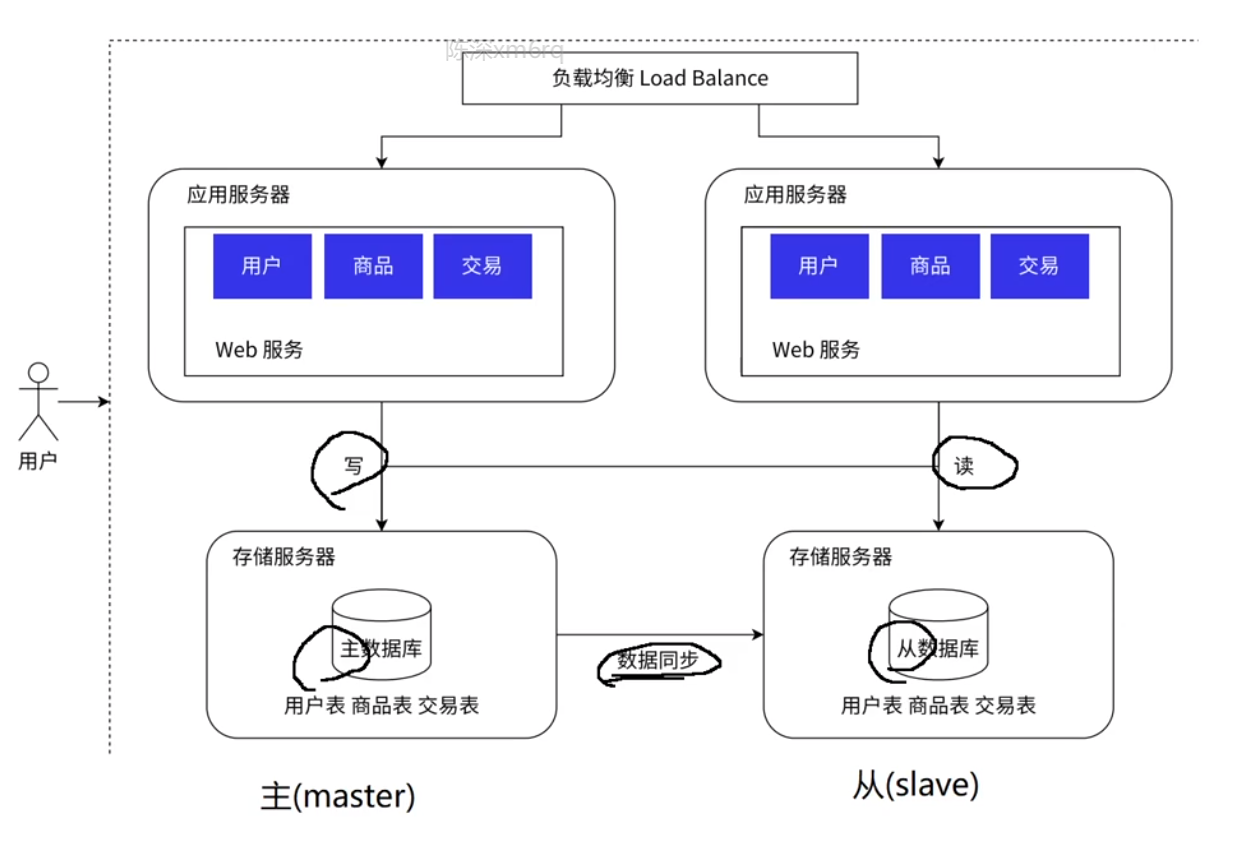
如上图, 我们把数据库服务器分为 "主", "从" 两种. 主服务器负责写数据, 从服务器负责读数据.
实际应用场景中, 读的评率是要比写的频率高得多的. 所以我们就需要引入更多从服务器来应对更大的需求 (一般是 "一主多从" 的形式).
1.5 引入缓存:
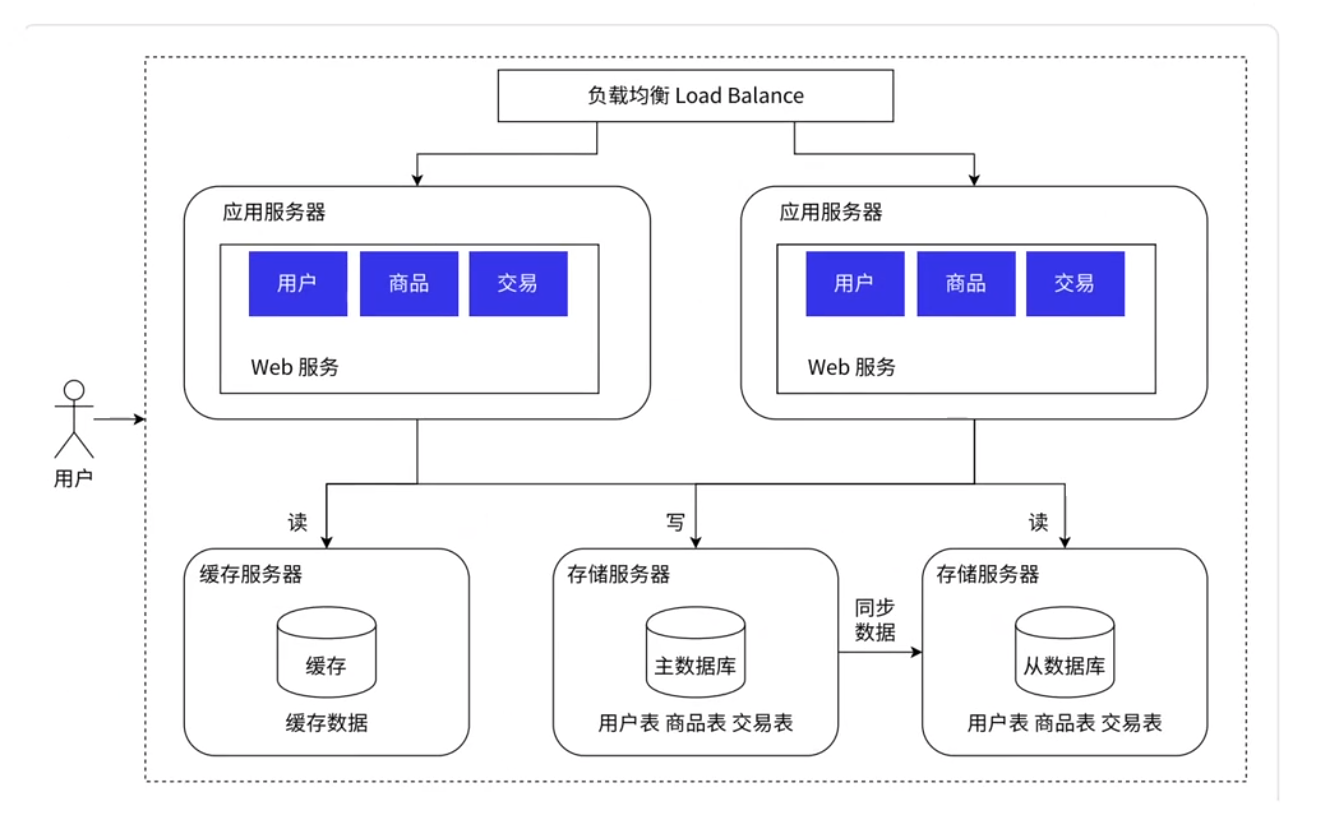
数据库天然有个问题: 就是数据存在硬盘中, 这就导致数据库的访问速度是很慢的. 但是有些情境下我们对响应速度要求很高, 这就不能再去读硬盘了. 为了解决这个问题, 我们把数据分为 "冷, 热" 两种, 将热点数据放到缓存中 (从缓存中读取数据是要比数据库中快很多的).
如上图, 缓存中只放一小部分 "热点数据" (会频繁被访问到的数据).
("二八原则": 20%的数据能够支持80%的访问量)
Redis 主要的应用场景就是作为缓存.
1.6 数据库分库分表:
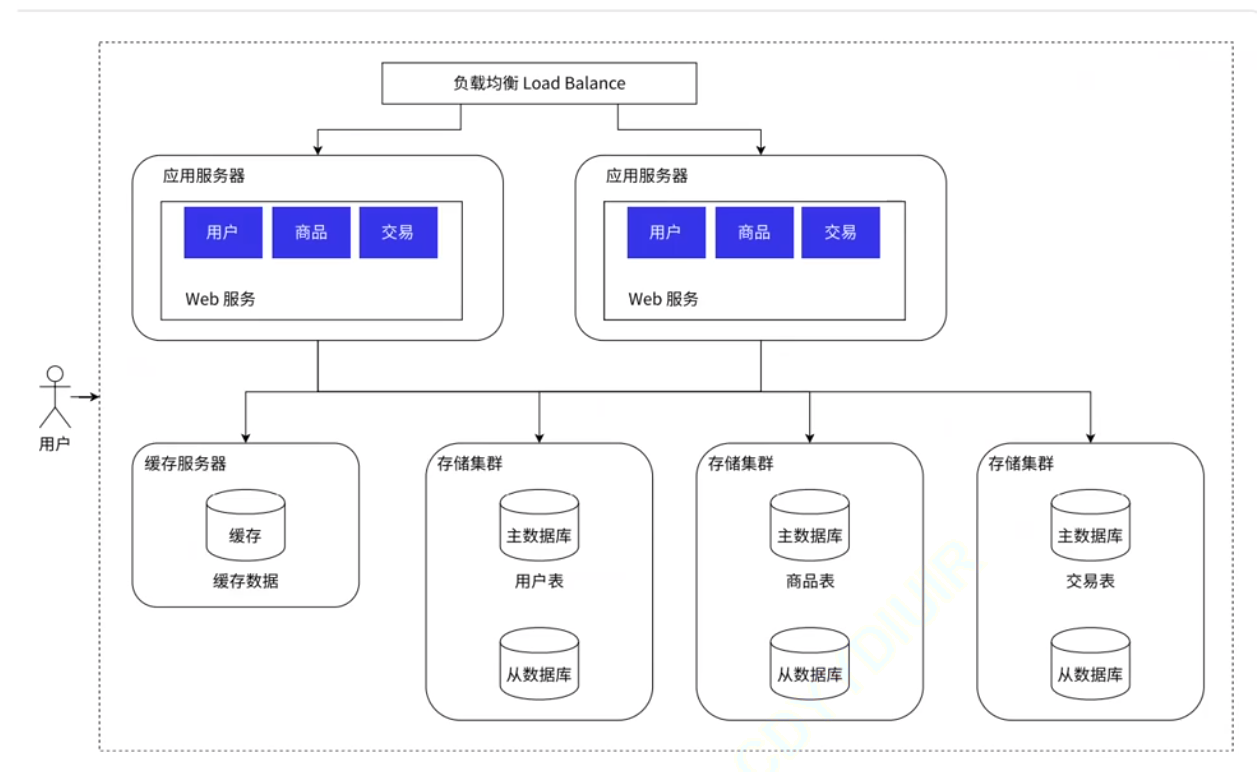
引入分布式系统, 不光要能够应对更高的请求量 (并发量), 同时也要能应对更大的数据量.
分库分表: 不同的业务对应自己的数据库, 有自己的数据库服务器. (eg: 用户业务 --> 用户数据库 --> 用户数据库服务器 ; 商品业务 --> 商品数据库 --> 商品数据库服务器)
如果某个数据表特别大, 大到一台服务器存不下, 也可以进行分表 (对数据表进行拆分) 操作.
具体分库分表如何实现? 还是要结合实际的业务场景来看. (业务至关重要!!!, 技术只是给业务提供支持~~ 业务决定技术)
1.7 微服务架构:
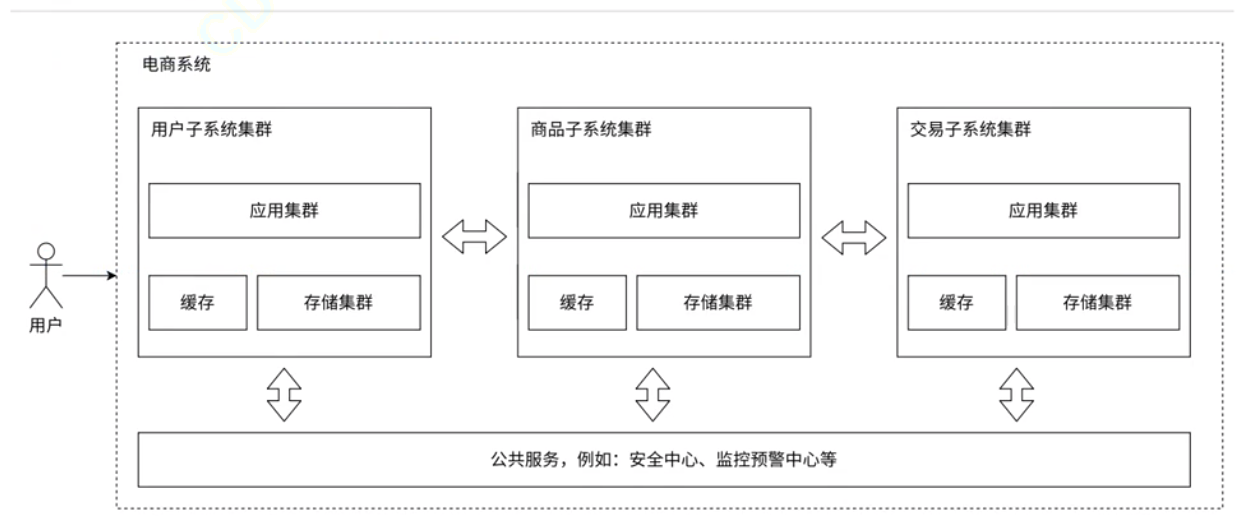
之前的应用服务器, 一个服务器程序里面做了很多业务, 这就可能会导致这一个服务器的代码越来越复杂. 为了方便维护, 我们就可以把这样一个复杂的服务器拆分成更多的, 功能更单一, 更小的服务器.
按照功能, 将项目拆分成多组微服务, 有利于人员任务分配和单块业务的维护.
引入微服务, 必然带来的问题是系统性能的下降 (因为一个服务拆分成多个服务, 多个服务之间是更依赖网络通信的, 而网络通信的速度很可能是比硬盘还慢的).
1.8 小结
(1) 单机架构 (应用程序 + 数据库服务器)
(2) 数据库和应用分离
应用程序和数据库服务器分别放到不同主机上部署了
(3) 引入负载均衡, 集群
通过负载均衡器, 把请求比较均匀的分发给集群中的每个应用服务器. 当集群中的某个主机挂了, 其他的主机仍然可以承担服务, 提高了整个系统的可用性.
(4) 引入读写分离, 数据库主从结构
一个数据库节点作为主节点, 其他N个数据库节点作为从节点. 主节点负责写数据, 从节点负责读数据. 主节点需要把修改过的数据同步给从节点.
(5) 引入缓存, 冷热数据分离
进一步的提升了服务器针对请求的处理能力. Redis 在一个分布式系统中, 通常就扮演着缓存这样的角色. (引入的问题: 数据库和缓存的数据同步问题)
(6) 引入分库分表.
数据库能够进一步扩展存储空间.
(7) 引入微服务, 从业务上进一步拆分应用服务器
从业务功能的角度, 把应用服务器, 拆分成更多的功能更单一, 更简单, 更小的服务器.
!NOTE
所谓分布式系统, 就是想办法引入更多的硬件资源.
上述这样的几个演化的步骤, 只是一个粗略的过程.
实际上一个商业项目, 真实的演化过程, 都是和它的业务发展密切相关的. 业务是更重要的, 技术只是给业务提供支持.
2. 概念说明
中间件:
与业务无关的服务 (功能更通用的服务), 比如: 数据库, 缓存, 消息队列 ... ...
可用性:
系统整体可正常使用时间 / 总时间.
响应时长:
(一般用于衡量服务器性能, 响应时长越小越好)
响应时长和具体所做的业务密切相关 (业务越复杂, 响应时长越久.)
吞吐量 / 并发量:
衡量系统处理请求的能力, 也是衡量服务器性能的一种方式.
3. Redis 特性
(1) 非关系型数据库
MySQL 主要是通过"表"的形式来组织数据的 --> "关系型数据库".
Redis 主要是通过"键值对"的形式来组织数据的 --> "非关系型数据库".
(2) 在内存中存储数据
Redis 主要将数据存储在内存中, 以实现对数据的高访问速度.
(3) 可扩展性
Redis 自身已经提供了很多数据结构和命令, 我们可以自己去扩展, 让 Redis 支持更多的数据结构和更多的命令.
(4) 持久化
我们知道, Redis 是把数据存储在内存中的. 但是内存中的数据是"易失"的, 进程退出或系统重启都会导致内存中数据的丢失. 所以为了解决这个问题, Redis 在内存中存储数据时, 会同步一份到硬盘上 (备份). 如果 Redis 重启或发生其他突发情况, Redis 就会去加载硬盘中的数据, 保证数据一致.
(5) 支持集群
Redis 支持 "集群" 和 "水平扩展". 一个 Redis 节点能够存储的数据是有限的, 我们就可以进入多台主机, 部署多个 Redis 节点, 这样就可以存储大量数据了
(6) 高可用
高可用 --> 冗余/备份
Redis 自身是支持"主从"结构的, 从节点相当于主节点的备份.
小结
- 为啥 Redis 快?
① Redis 数据在内存中, 就比访问硬盘的数据库, 要快很多.
② Redis 核心功能都是比较简单的逻辑 (核心功能都是比较简单的操作内存的数据结构)
③ 从网络角度上, Redis 使用了 IO 多路复用的方式 (epoll) --> 使用一个线程, 管理很多个 socket.
④ Redis 使用的是单线程模型 (虽然更高版本的 Redis 引入了多线程) 这样的单线程模型, 减少了不必要的线程之间的竞争开销.
!NOTE
注: 多线程提高效率的前提是: CPU 密集型的任务, 使用多个线程可以充分的利用 CPU 多核资源. 但是 Redis 的核心任务, 主要就是操作内存的数据结构, 不会吃很多 CPU.
4. Redis 应用场景
(1) 作为内存数据库
某些应用场景下, 对数据库访问速度要求很高 (如搜索引擎), 此时我们就不能再使用 MySQL 这种硬盘数据库了. 所以这时候就选择使用 Redis 这种内存数据库.
!CAUTION
此时, Redis 是作为内存数据库的, 存储的是全量数据 , 里面的数据是不能随便丢失的.
(2) 作为缓存
某些情境下, Redis 用于作为缓存, 来存储热点数据.
!CAUTION
这种情况下, Redis 里存的是部分数据 . 全量数据是存在 MySQL 里的, Redis 里的数据就算丢了, 也可以从 MySQL 里同步过来.
Redis 也可以用于存储 Session 会话:
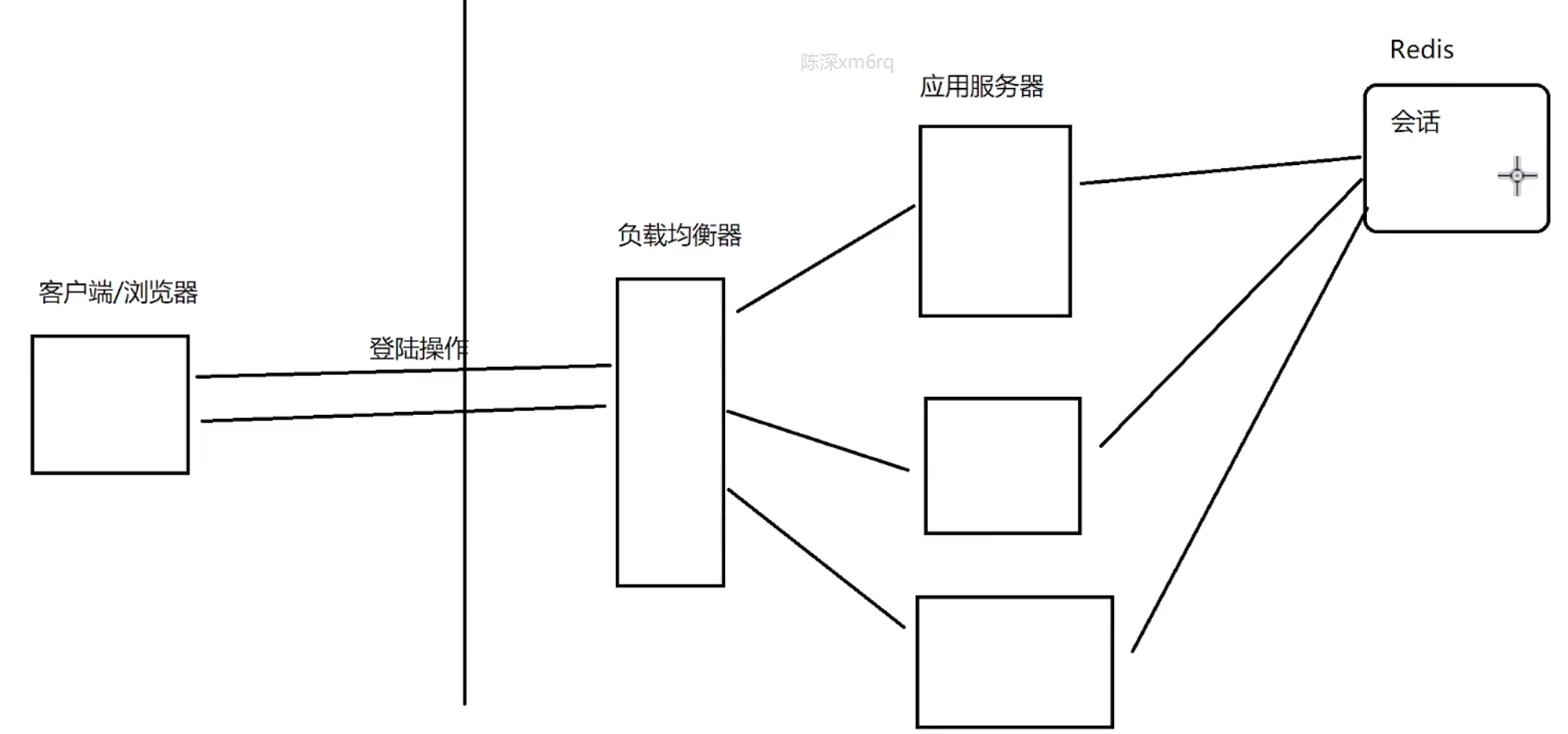
(3) 作为消息队列
(不常用)
业界有很多知名的消息队列, 如: RabbitMQ, RocketMQ, Kafka ... ...
Redis 也提供了消息队列的功能.
!NOTE
Redis 不适用的应用场景: Redis 通常不适用大规模的数据存储.