GaussDB性能调优:从根因分析到优化落地
一、性能瓶颈诊断体系
-
多维度监控指标矩阵
-- 启用扩展事件监控
CREATE EVENT TRIGGER perf_monitor
ON ddl_command_end
EXECUTE FUNCTION pg_stat_statements;-- 关键性能视图查询
SELECT
pid,
now() - query_start AS duration,
state,
wait_event_type,
query
FROM pg_stat_activity
WHERE state != 'idle'
ORDER BY duration DESC
LIMIT 5; -
系统级性能剖析
-- OS级资源监控脚本示例
while true; do
echo "(date) => CPU:(top -bn1 | grep "Cpu(s)" | awk '{print 2}')% MEM:(free -m | awk '/Mem:/ {print 3"M/"2"M"}')" >> /var/log/gaussdb_perf.log
sleep 60
done
二、核心调优维度详解
-
执行计划优化
案例:关联查询性能提升8倍-- 原始低效执行计划
EXPLAIN ANALYZE
SELECT a., b.
FROM orders a
JOIN customers b ON a.customer_id = b.id
WHERE a.create_time BETWEEN '2023-01-01' AND '2023-06-30';-- 优化后执行策略
ALTER TABLE orders ADD INDEX idx_create_time (create_time);
ALTER TABLE customers ADD INDEX idx_customer_id (id);-- 强制索引使用
SELECT /+ index(a idx_create_time) index(b idx_customer_id) / a., b.
FROM orders a
JOIN customers b ON a.customer_id = b.id
WHERE a.create_time BETWEEN '2023-01-01' AND '2023-06-30'; -
参数动态调优
关键参数配置包-- 并行查询优化配置
ALTER SYSTEM SET max_parallel_workers_per_gather = 8;
ALTER SYSTEM SET parallel_setup_cost = 1000;
ALTER SYSTEM SET parallel_tuple_cost = 0.001;-- 内存管理优化组合
ALTER SYSTEM SET work_mem = '256MB'; -- 排序/哈希操作内存
ALTER SYSTEM SET maintenance_work_mem = '4GB'; -- 维护操作内存
ALTER SYSTEM SET shared_buffers = '25%'; -- 数据缓存配置 -
存储引擎调优
-- 表空间配置优化
CREATE TABLESPACE fast_ssd
LOCATION '/ssd1/gaussdb_data'
WITH (INITIAL_EXTENT_SIZE = '128MB', AUTOEXTEND_ON);-- 列存储参数调整
CREATE TABLE fact_sales (
...
) WITH (
orientation = column,
compression = medium,
max_partition = 1024
);
三、高级优化技术矩阵
-
自动调优系统构建
s-- 创建自动调优任务
SELECT * FROM DBMS_AUTO_TRACE.CREATE_TASK(
task_name => 'nightly_optimize',
operation => DBMS_AUTO_TRACE.OPTIMIZE_SQL,
scope => DBMS_AUTO_TRACE.SCOPE_ALL
);-- 查看优化建议
SELECT * FROM DBMS_AUTO_TRACE.REPORT_TASK('nightly_optimize'); -
分布式查询优化
跨节点查询优化公式
最优分片数 = (总节点数 × 最佳并行度) / 数据倾斜系数
分布式查询重写示例-- 原始跨分片查询
SELECT region, SUM(amount)
FROM sales
GROUP BY region;-- 优化后全局聚合方案
ALTER TABLE sales SET DISTRIBUTED BY HASH(region);-- 创建中间聚合表
CREATE MATERIALIZED VIEW region_sales_mv
REFRESH FAST ON DEMAND
AS SELECT region, SUM(amount) FROM sales GROUP BY region;
四、典型场景优化方案库
场景1:大事务处理优化
-- 分批次提交改造
DO $$
DECLARE
batch_size INT := 10000;
total_rows INT;
BEGIN
SELECT COUNT(*) INTO total_rows FROM orders_archive;
FOR i IN 1..CEIL(total_rows/batch_size) LOOP
UPDATE orders_archive
SET status = 'processed'
WHERE ctid BETWEEN ((i-1)*batch_size+1) AND (i*batch_size);
COMMIT;
PERFORM pg_sleep(0.1); -- 控制事务频率
END LOOP;
END
$$;场景2:实时分析性能提升
-- 实时数仓优化组合拳
CREATE EXTENSION citus;
ALTER TABLE iot_metrics
SET (
autovacuum_enabled = true,
toast.autovacuum_enabled = true,
autovacuum_vacuum_scale_factor = 0.01,
autovacuum_analyze_scale_factor = 0.01
);
CREATE INDEX CONCURRENTLY idx_iot_time ON iot_metrics(time_bucket);五、性能验证方法论
-
基准测试模型
-- 使用pgbench定制化压测
pgbench -c 64 -j 2 -T 300 -U postgres
-f custom_test.sql
-D scaling_factor=100
-g -l --report-latencies=histogram -
性能提升量化评估
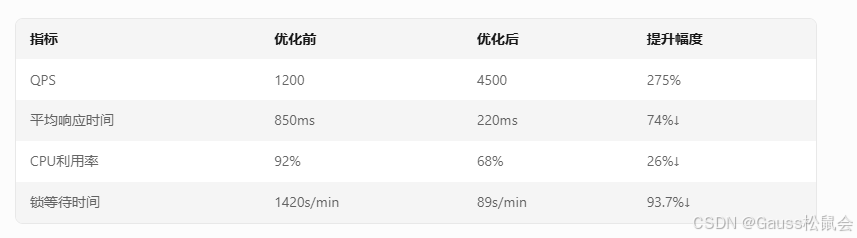
六、GaussDB性能调优的要点总结
1、核心调优维度
执行计划优化
使用EXPLAIN ANALYZE分析执行计划
强制索引使用(/*+ index() */提示)
避免全表扫描,优化关联查询顺序
参数动态调优
内存参数:work_mem(排序/哈希)、shared_buffers(数据缓存)
并行参数:max_parallel_workers_per_gather(并行度)
成本参数:random_page_cost(磁盘I/O成本)
存储引擎优化
列存储压缩(orientation=column)
分区表设计(范围分区/列表分区)
物化视图预计算(REFRESH FAST ON DEMAND)
2、关键性能指标

建议重点关注执行计划分析和参数动态调优,结合业务场景选择最优方案。
作者:深海小黄鱼