本次分享一个CPU软锁死的问题。这个问题致使我们公司K8S集群一个节点被锁死,负载不断飙升,整个集群也被拖死,导致重要业务受影响,现在来回顾一下整个过程。
1 事件现象
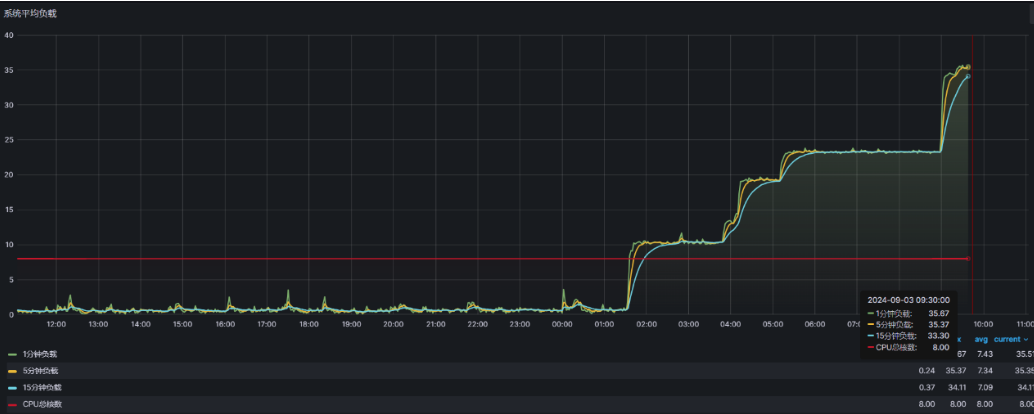
1、用户发现系统无法登入后反馈运维,运维检查情况并定位到是k8s集群问题。 2、进入服务器后无法对K8S集群进行操作 3、查看K8S集群第三个节点负载较高

2 引起原因
通过查看日志,K8S集群的第三个节点服务器存在BUG,导致它无法正常执行操作,陷入死循环。负载持续增高,导致K8S集群崩溃。
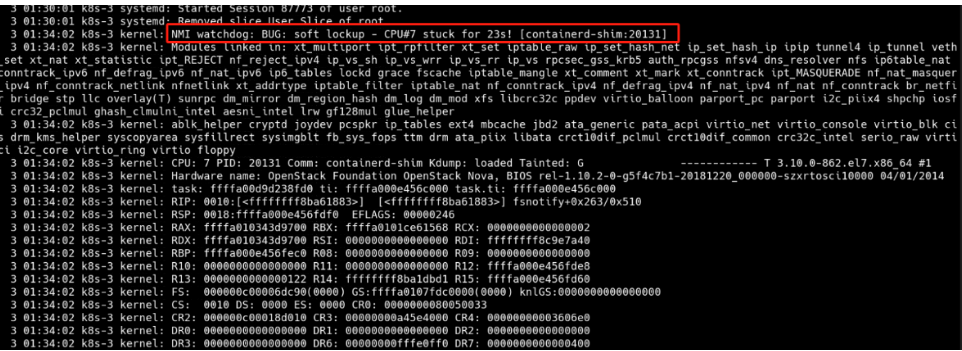
为了解决这个问题,百度了一下,总结了以下几种原因:
驱动程序错误:某些硬件驱动程序可能含有缺陷,导致CPU在执行特定操作时陷入死循环。 硬件故障:硬件问题,如过热或电源不稳定,也可能导致CPU响应缓慢或卡死。 内核bug:Linux内核本身的bug可能会在特定情况下触发软锁定。
3 解决方案
3.1 临时解决:强制重启服务器
由于我们是云服务器,我在服务器使用reboot没有释放负载,于是在云平台直接强制重启才释放。
3.2 彻底解决:调整内核参数
CentOS内核,对应的文件是/proc/sys/kernel/watchdog_thresh。
(1)将 watchlog_thresh 临时设置为 30
sysctl -w kernel.watchdog_thresh=30(2)将 watchlog_thresh 永久设置为 30
echo 30>/proc/sys/kernel/watchdog_thresh(3)将 watchlog_thresh 写入启动文件
kernel.watchdog_thresh=30>> /etc/sysctl.conf重要说明:
在centos6(2.6内核)中:
softlockup_thresh的值等于内核参kernel.watchdog_thresh,默认60秒;
在centos7(3.10内核)中:
内核参数kernel.watchdog_thresh名称未变,但含义变成了hard lockup threshold,默认10秒;
soft lockup threshold则等于(2*kernel.watchdog_thresh),默认20秒;
3.10内核中 高精度计时器(hrtimer),也就是kernel/watchdog.c: watchdog_timer_fn() 的周期是:softlockup_thresh/5 ,默认4s
如果超过了soft lockup threshold(20s)未更新, 那么就会发生soft lockup