- 项目源码地址:github.com/SpringCat10...
- 关注公众号【Spring Cat 】回复 003,获取Markdown/PDF格式的原文文档。
一、引言
Why Do This?
学习Apache Shenyu Gateway(API网关中间件)源码了解到,Shenyu官方默认推荐使用WebSocket或HTTP长轮询方式去实现网关元数据的全量拉取和增量同步。
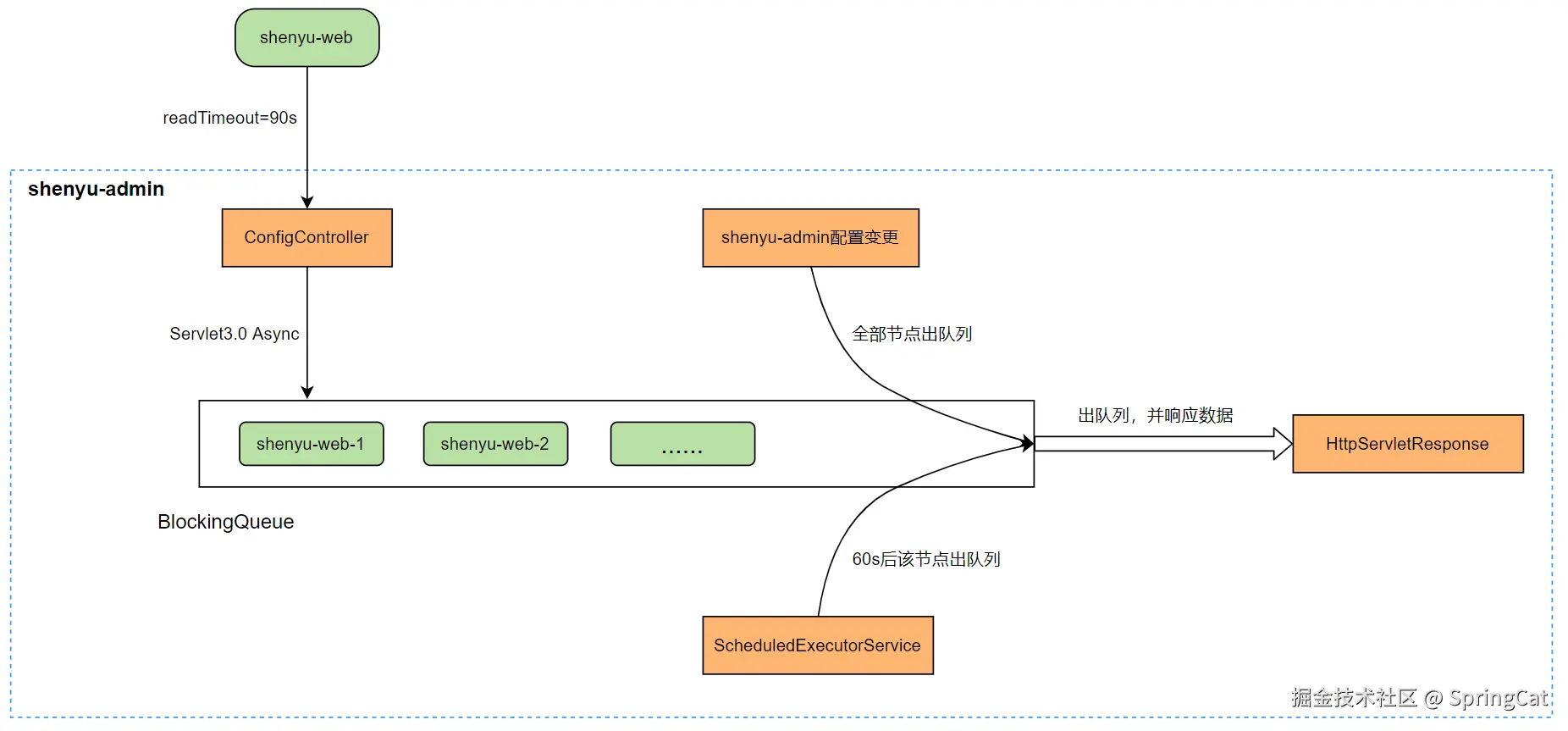
以HTTP长轮询方式为例(如下图所示),网关内核在运行时会向管理态(shenyu-admin)不断发起轮询请求,为了保证数据一致性,每当增加一个admin节点都会在网关内核额外开辟一个新的线程去发起轮询,轮询期间该线程是需要一直被阻塞,直到某个admin端响应结果或连接断开。
流程图解如下所示:
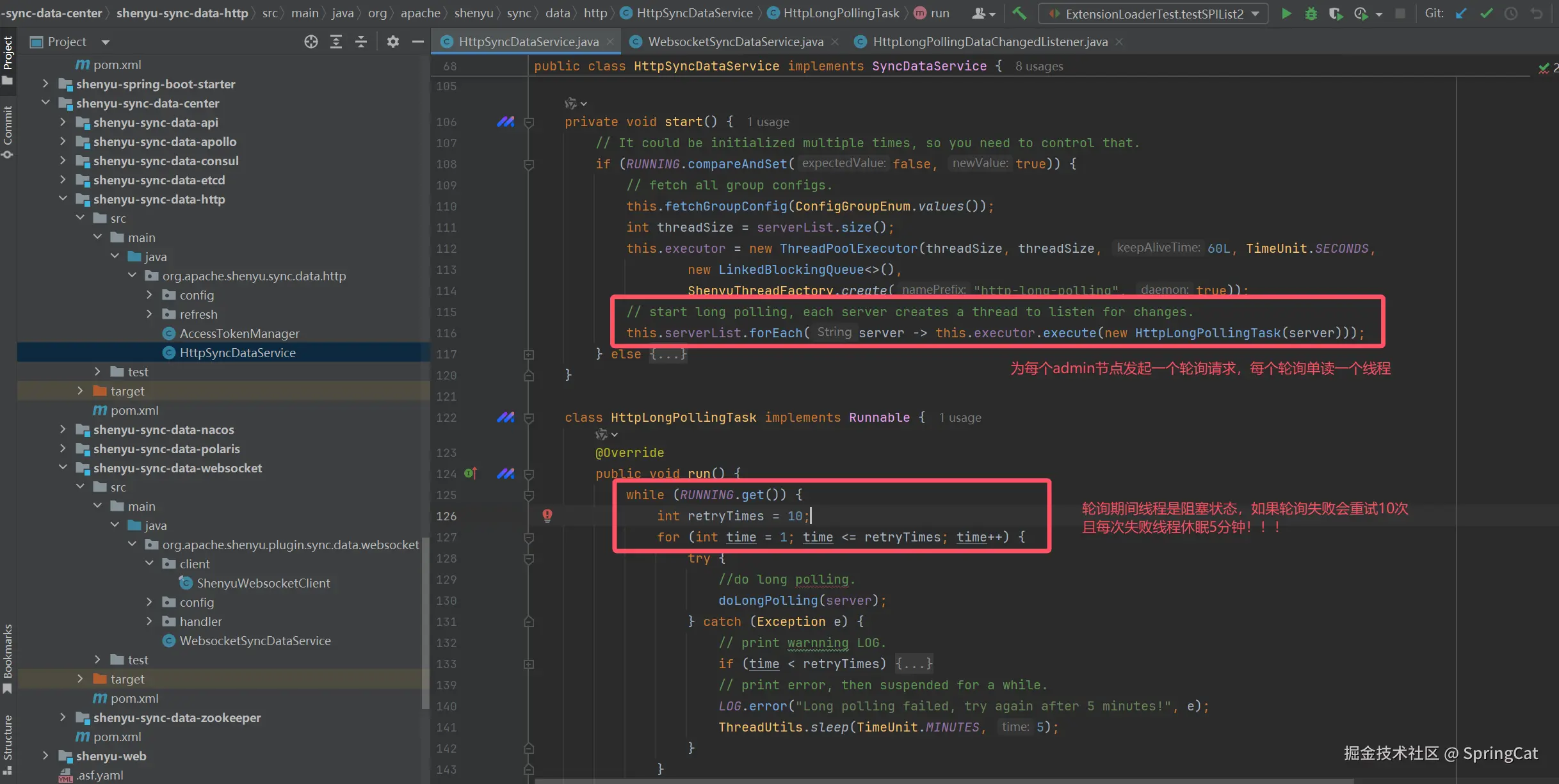
核心代码如下所示:
【当前设计方案潜在性能瓶颈】
- 资源线性增长:网关线程数与admin节点数呈 1:1 正比关系,admin集群扩所容时,会影响网关内核线程数波动。
- 线程利用率低:长轮询期间线程持续阻塞,造成系统资源空转。
- 稳定性风险:大规模部署时可能触发线程数过载,导致OOM风险。
举个🌰,假设我们的admin节点有20台容器实例,那么就需要每个Shenyu网关内核阻塞20个线程向admin发起轮询,另外网关本身也会有一些定时任务线程和守护线程的占用(例如Shenyu的Plugin定时加载机制)。这样会导致本该尽量分配给处理用户请求的线程资源浪费在系统内部处理上。
Q:相比现在的服务器硬件配置和后端系统性能,占用20个线程有什么大不了的?
A:我们知道 Tomcat 每接收一个用户端HTTP请求都会单独分配一个线程处理,它的默认 线程池 最大上限也才200个线程。
API网关系统中用户流量和API就是核心资产。尽量多的把有限线程资源分配给处理用户请求上,不仅可以提高单机吞吐量也可以一定程度上减少一些服务器容器数量。
此外,API网关通常是通过大集群进行部署的,而管理后台(admin)作为非核心系统可能只有少量实例,admin模块依赖了包含数据库在内的众多第三方组件,在二者集群性能不对等的情况下,应该尽量减少耦合,避免因非核心系统故障导致网关内核被连带影响。
例如,当有一批admin节点由于开发者变更发布异常导致服务不可用。这时候所有网关内核都会跟着阻塞一批本该用于轮询的线程,sleep 5分钟。
同样地,Shenyu网关基于WebSocket全双工通信方式实现的配置拉取和同步,也是会为每个admin节点开辟一个独立线程:
java
/**
* Websocket数据同步服务
*/
@Slf4j
public class WebsocketSyncDataService implements SyncDataService, AutoCloseable {
private final List<WebSocketClient> clients = new ArrayList<>();
private final ScheduledThreadPoolExecutor executor;
/**
* 创建Websocket数据同步服务
*/
public WebsocketSyncDataService(final WebsocketConfig websocketConfig,
final PluginDataSubscriber pluginDataSubscriber,
final List<MetaDataSubscriber> metaDataSubscribers,
final List<AuthDataSubscriber> authDataSubscribers) {
// admin端的同步地址,有多个的话,使用","分割
String[] urls = StringUtils.split(websocketConfig.getUrls(), ",");
// 创建调度线程池,一个admin分配一个
executor = new ScheduledThreadPoolExecutor(urls.length, ShenyuThreadFactory.create("websocket-connect", true));
for (String url : urls) {
try {
// 创建WebsocketClient,一个admin分配一个
clients.add(new ShenyuWebsocketClient(new URI(url), Objects.requireNonNull(pluginDataSubscriber), metaDataSubscribers, authDataSubscribers));
} catch (URISyntaxException e) {
log.error("websocket url({}) is error", url, e);
}
}
try {
for (WebSocketClient client : clients) {
// 和websocket server建立连接
boolean success = client.connectBlocking(3000, TimeUnit.MILLISECONDS);
if (success) {
log.info("websocket connection is successful.....");
} else {
log.error("websocket connection is error.....");
}
// 执行定时任务,每隔10秒执行一次
// 主要作用是判断websocket连接是否已经断开,如果已经断开,则尝试重连。
// 如果没有断开,就进行 ping-pong 检测
executor.scheduleAtFixedRate(() -> {
// 具体逻辑代码,省略
}, 10, 10, TimeUnit.SECONDS);
}
/* client.setProxy(new Proxy(Proxy.Type.HTTP, new InetSocketAddress("proxyaddress", 80)));*/
} catch (InterruptedException e) {
log.info("websocket connection...exception....", e);
}
}
// 其他代码略
}Q:那么如何实现一个少量线程占用,就能动态从远端配置中心拉取元数据呢?
A:行业现成解决方案,例如ZooKeeper、Nacos、Apollo等配置中心组件。比如当网关admin后台发布新的元数据配置后,马上由配置中心推送给网关内核,并不会过多占用网关核心线程。
Shenyu官方提供的HTTP长轮训方案借鉴自Nacos1.x版本。
而在Nacos2.x版本时,已不再使用HTTP长轮询方式去拉取配置。
而是采用性能更好的gRPC长连接方式实现。
| 特性 | gRPC 长连接 | HTTP 长轮询 |
|---|---|---|
| 通信基础 | 基于 HTTP/2,二进制传输 | 基于 HTTP/1.x,文本传输 |
| 连接方式 | 持久连接,多路复用 | 短连接,频繁轮询 |
| 数据流动 | 双向流,支持实时推送和双向通信 | 单向,轮询请求,需等待服务器响应 |
| 性能差异 | 高效传输,低网络开销 | 请求-响应开销较大,需设置合理的轮询间隔 |
| 实时性 | 优秀,服务端主动推送数据更新 | 较差,客户端需等待请求响应后再获取更新 |
| 协议扩展 | 支持 Protocol Buffers,方便跨语言实现 | 基于 HTTP 原生,更易与现有 HTTP 应用集成 |
| 功能支持 | 支持认证、压缩等功能,适用于复杂场景 | 功能扩展有限,更适合简单应用 |
| 适用场景 | 需要高效通信和实时性较高的应用,如配置中心、消息推送 | 简单应用场景或实时性要求不高的场景 |
PS:不了解gRPC的小伙伴自行补课 -> gRPC官方文档中文版
API网关所依赖的元数据配置数据量并不多,数据不会频繁更新(典型的读多写少场景),也没有非常复杂的结构体定义。单独去集成一整套配置中心和服务注册集群(例如Nacos)先不说购买云上Nacos成本费用,中间件项目本身过多依赖其他第三方中间件服务,也不是一个好的选择。Shenyu网关源码中,是需要对配置推送做一些很多定制逻辑处理的,直接集成Nacos和ZK也需要一些代码改动。这可能也是Shenyu官方不直接推荐使用Nacos或者ZK用来作为自己的元数据中心吧?
Q:如何不单独部署一套Nacos服务,实现简单轻量的配置中心能力呢?
A:参考Nacos底层的JRaft协议,自己实现一个简单的集群数据强一致性(线性一致)的配置中心。
What Is Raft? What Is CAP?
我们以一个Java面试八股文知识点为切入点 "Nacos是如何实现集群之间数据一致性的?",翻阅Nacos源码了解到,Nacos基于JRaft和Distro两种协议实现分布式集群数据一致性,其中Distro协议是Nacos自研的基于AP模式(Availability And Partition tolerance)实现的数据最终一致性算法;而JRaft协议则是基于CP模式(Consistency And Partition tolerance)实现的数据强一致性(线性一致)算法,由蚂蚁SOFA JRaft开源。
- 对于临时实例,Nacos优先保证数据可用性,采用的是Distro算法。
properties
#*************** Distro模式,用于临时实例 ***************#
### Distro数据同步延迟时间,当同步任务延迟时,任务将合并为相同的数据密钥。默认为1秒。
nacos.core.protocol.distro.data.sync.delayMs=1000
### 一个同步数据的发行版数据同步超时,默认为3秒。
nacos.core.protocol.distro.data.sync.timeoutMs=3000
### 同步数据失败或超时时的发行版数据同步重试延迟时间,与delayMs相同的行为,默认3秒。
nacos.core.protocol.distro.data.sync.retryDelayMs=3000
### 验证同步数据是否在某个时间间隔内过期。默认5秒
nacos.core.protocol.distro.data.verify.intervalMs=5000
### 一次验证的发行版数据验证超时,默认为3秒。
nacos.core.protocol.distro.data.verify.timeoutMs=3000
### 加载快照数据失败时的发行版数据加载重试延迟,默认为30秒。
nacos.core.protocol.distro.data.load.retryDelayMs=30000- 对于永久实例,Nacos优先保证数据一致性,采用的是JRaft算法。
properties
#*************** JRaft模式,用于永久实例 ***************#
### 设置Raft集群选举超时时间,默认为5秒
nacos.core.protocol.raft.data.election_timeout_ms=5000
### 设置Raft快照将定期执行的时间,默认为30分钟
nacos.core.protocol.raft.data.snapshot_interval_secs=30
### raft内部工作线程数量
nacos.core.protocol.raft.data.core_thread_num=8
### raft业务请求处理所需线程数
nacos.core.protocol.raft.data.cli_service_thread_num=4
### raft线性读取策略:
### 默认情况下使用安全线性读取ReadOnlySafe,即读和写都必须由Leader执行
### 另外一种是ReadOnlyLeaseBased 由Leader执行写,允许Follower执行读
nacos.core.protocol.raft.data.read_index_type=ReadOnlySafe
### Raft节点之间rpc请求超时,默认5秒
nacos.core.protocol.raft.data.rpc_request_timeout_ms=5000- Nacos源码(2.5.0版本)中区分使用JRaft还是Distro协议由如下代码控制:
临时实例注册入口:
com.alibaba.nacos.naming.core.v2.service.impl.EphemeralClientOperationServiceImpl
com.alibaba.nacos.core.distributed.distro.DistroProtocol
java
@Component("ephemeralClientOperationService")
public class EphemeralClientOperationServiceImpl implements ClientOperationService {
@Override
public void registerInstance(Service service, Instance instance, String clientId) throws NacosException {
NamingUtils.checkInstanceIsLegal(instance);
Service singleton = ServiceManager.getInstance().getSingleton(service);
// 检查服务是否为临时实例,如果不是则抛出异常
if (!singleton.isEphemeral()) {
throw new NacosRuntimeException(NacosException.INVALID_PARAM,
String.format("Current service %s is persistent service, can't register ephemeral instance.",
singleton.getGroupedServiceName()));
}
// 调用Distro协议进行数据同步
DistroProtocol distroProtocol = ApplicationUtils.getBean(DistroProtocol.class);
distroProtocol.sync(new DistroKey(service.getGroupedServiceName(), DataOperation.CHANGE),
DistroConfig.getInstance().getSyncDelayMillis());
// ... 其他代码
}
}永久实例注册入口: com.alibaba.nacos.naming.core.v2.service.impl.PersistentClientOperationServiceImpl
com.alibaba.nacos.core.distributed.raft.JRaftProtocol
java
@Component("persistentClientOperationServiceImpl")
public class PersistentClientOperationServiceImpl extends RequestProcessor4CP implements ClientOperationService {
@Override
public void registerInstance(Service service, Instance instance, String clientId) throws NacosException {
NamingUtils.checkInstanceIsLegal(instance);
Service singleton = ServiceManager.getInstance().getSingleton(service);
if (singleton.isEphemeral()) {
throw new NacosRuntimeException(NacosException.INVALID_PARAM,
String.format("Current service %s is ephemeral service, can't register persistent instance.",
singleton.getGroupedServiceName()));
}
// 调用JRaft协议进行数据写入
JRaftProtocol jRaftProtocol = ApplicationUtils.getBean(JRaftProtocol.class);
WriteRequest request = new WriteRequest();
// 设置请求数据
request.setData(/* 实例数据 */);
jRaftProtocol.write(request);
// ... 其他代码
}
}下面,我们就参考Nacos永久实例使用的JRaft算法 + gRPC实现一个轻量级的元,轻量级的、线性一致(CP)的元数据配置中心&服务注册中心。
PS:不清楚集群数据一致性CAP原则理论知识的小伙伴,自行补课 -> CAP原则(CAP定理)、BASE理论、raft.github.io/
Project Introduction
- Demo案例介绍:基于Raft集群数据一致协议实现一个轻量级的元数据配置中心&服务注册中心,使我们的后端程序可以在不依赖Nacos、ZooKeeper、ConfigServer、Etcd、Consul、Apollo、Redis的情况下,实现集群实例间的元数据一致性与数据推送、监听、增量同步。
- Demo案例代码库:github.com/SpringCat10...
- Project基础依赖:JDK17、JRaft1.3.14、gRPC1.64.2、Protobuf3.25.5
- Project模块划分:
bash
ohara-mcs # OHara MCS(Metadata Config Service)
├── logs # 日志输出
├── ohara-mcs-api # API定义、gRPC结构体定义、Protobuf编译时生成gRPC类对象
├── ohara-mcs-client # 客户端SDK
├── ohara-mcs-common # 通用组件、工具类
├── ohara-mcs-core # gRPC服务、Raft服务核心模块
├── ohara-mcs-demo
│ ├── ohara-mcc-demo-cluster1 # 模拟服务端集群 -> 元数据(监听、推送)、集群Leader选举、服务注册、服务发现...
│ └── ohara-mcc-demo-cluster2
│ └── ...
│ └── ohara-mcs-demo-client1 # 模拟客户端集群 -> 配置监听、推送、读取...
│ └── ohara-mcs-demo-client2
│ └── ...
├── ohara-mcs-spi # 自定义SPI扩展机制
├── ohara-mcs-spring-boot-starter
│ ├── ohara-mcs-client-spring-boot-starter # 客户端 -> spring-boot-stater
│ └── ohara-mcs-server-spring-boot-starter # 服务端 -> spring-boot-stater
└── raft # Raft协议核心日志存放文件夹
├── config_center_group # 配置中心Raft分组(eg: 服务配置分组、服务实例分组)
└── ip_port # 通过IP+端口区分集群实例
└── logs # Raft日志(LogEntry),用于集群Leader选举、动作复制
└── meta # Raft过程元数据存储
└── snapshot # Raft快照文件,用于断电恢复、启动时配置加载、定期快照备份Quick Start
服务端
Step1:引入POM依赖:
xml
<dependency>
<groupId>org.ohara.mcs</groupId>
<artifactId>ohara-mcs-server-spring-boot-starter</artifactId>
<version>${project.version}</version>
</dependency>Step2:主启动类开启MCS服务
java
@SpringBootApplication
@EnableOHaraMcsServer(enable = true) // 开启MCS服务
public class Demo1Application {
public static void main(String[] args) {
SpringApplication.run(Demo1Application.class, args);
}
}Step3:application.properties配置
yml
ohara-mcs:
local-mode: true # 开启本机测试模式,用于本地开发调试使用
namespace: default # 命名空间,ohara-mcs通过命名空间实现配置租户隔离
rpc-type: grpc # 客户端与服务端通信协议类型,当前仅实现了grpc,后续可以扩展http、websocket、nacos等
grpc-config:
keep-alive-time: 3000
keep-alive-timeout: 3000
permit-keep-alive-time: 3000
max-inbound-message-size: 10240
raft-config:
election-timeout: 1000 # Leader选举超时时间,默认1000
read-only-option: read_only_lease_based # 读写模式,默认read_only_safe
port-offset: 1001 # Raft服务端口偏移,默认1001
single-node: false # 是否为单节点模式,用于单机测试使用
cluster-address:
- 127.0.0.1:9001 # Raft集群实例地址,为了单机测试方便这里通过端口作区分
- 127.0.0.1:9101
- 127.0.0.1:9201
- 127.0.0.1:9301
port: 8000 # gRPC服务默认端口8000,用于客户端与服务端节点通信
# HTTP 端口
server:
port: 7100Step4:启动服务端
客户端
Step1:引入POM依赖:
xml
<dependency>
<groupId>org.ohara.mcs</groupId>
<artifactId>ohara-mcs-client-spring-boot-starter</artifactId>
<version>${project.version}</version>
</dependency>Step2:主启动类开启MCS服务
java
@SpringBootApplication
@EnableOHaraMcsClient(enable = true) // 开启MCS客户端
public class Client1Application {
public static void main(String[] args) {
SpringApplication.run(Client1Application.class, args);
}
}Step3:application.properties配置
yml
ohara-mcs:
rpc-type: grpc # 客户端与服务端通信协议
cluster-address:
- 127.0.0.1:8000 # 服务端集群地址
- 127.0.0.1:8100
- 127.0.0.1:8200
- 127.0.0.1:8300
namespace: default # 命名空间
# HTTP 端口
server:
port: 9527Step4:构建OHaraMcsClient
java
@Configuration
public class OHaraMcsConfiguration {
@Bean
@Scope("singleton") // 显式声明单例
public OHaraMcsService oHaraMcsClient(OHaraMcsConfig config) {
GrpcOption option = new GrpcOption();
// 初始化服务端集群地址
option.initServers(config.getClusterAddress());
// 构建OHaraMcsClient
OHaraMcsClient mcsClient = OHaraMcsClient.builder(config.getNamespace(), option).build();
return new OHaraMcsService(mcsClient);
}
}Step5:监听服务端端推送过来的数据变更 这里演示案例中,我定义了一个User对象,监听服务端的推送过来的User信息。
java
@Data // lombok 注解
public class User implements ConfigData { // 实现ConfigData接口,用于不通的监听器消息分发
private String name;
private Integer age;
}
@Join // ohara-mcs SPI扩展机制注解,用于识别客户端用户自定义的监听器
public class UserConfigListener extends AbstractConfigListener<User> {
@Override
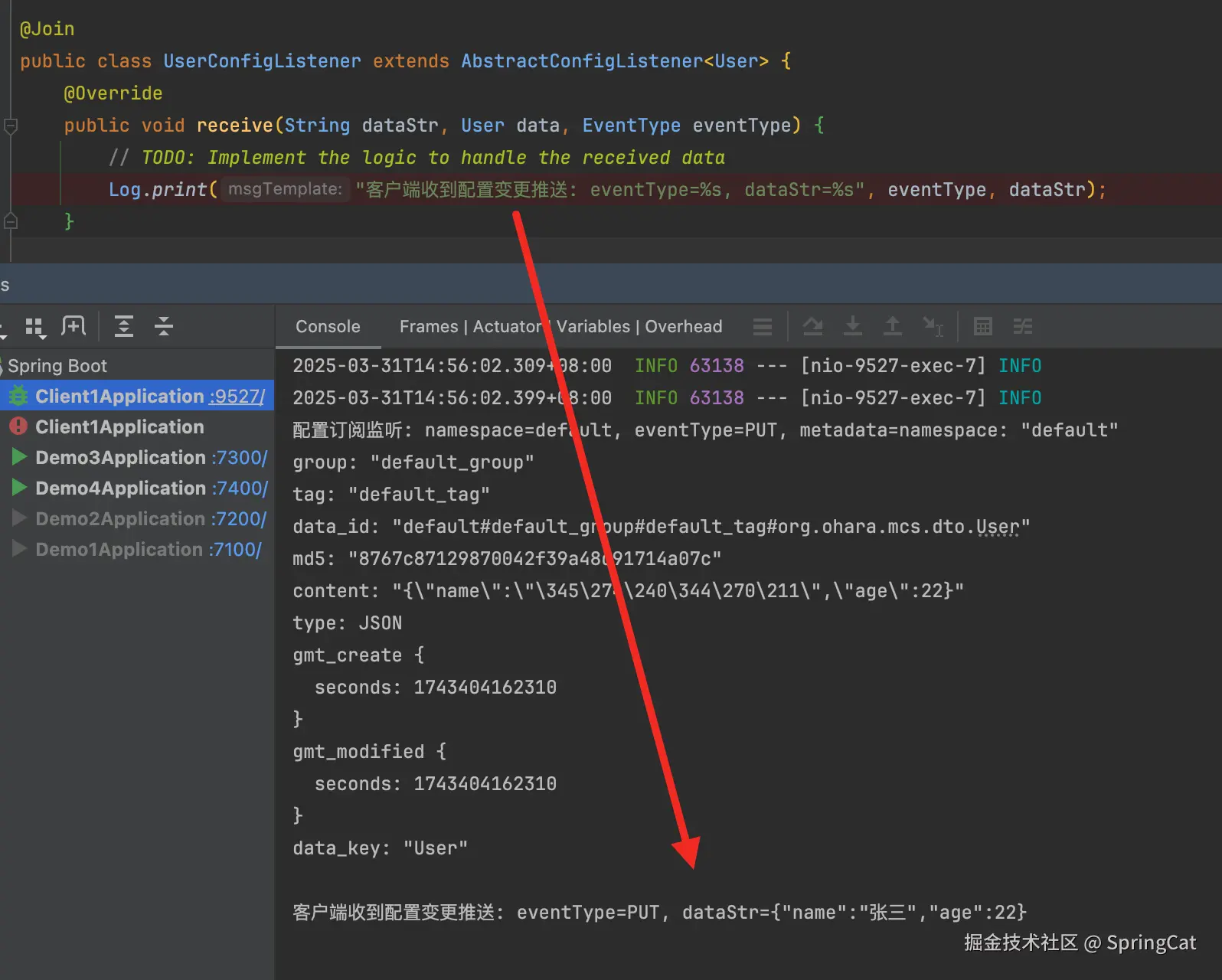
public void receive(String dataStr, User data, EventType eventType) {
// TODO: Implement the logic to handle the received data
Log.print("客户端收到配置变更推送: eventType=%s, dataStr=%s", eventType, dataStr);
}
}src/main/resources文件夹下创建/META-INF/ohara目录,并创建 org.ohara.msc.listener.ConfigListener 文件:
properties
# 声明客户端自定义的监听器,客户端启动时,MCS的SPI加载机制会加载到内存中。
user=org.ohara.mcs.listener.UserConfigListener
test=org.ohara.mcs.listener.TestConfigListener
demo=org.ohara.mcs.listener.DemoConfigListenerStep6:启动客户端,测试任意一个客户端向MCS服务端集群推送配置,并由服务端广播给各个客户端。
测试一个元数据配置推送、查询、监听的demo:
java
@RestController
@RequestMapping("/user/config")
public class UserController {
@Resource
private OHaraMcsService oHaraMcsService;
@GetMapping("/get")
public String get() {
Payload payload = Payload.builder().build();
payload.setNamespace("default");
payload.setGroup("default_group");
payload.setGroup("default_tag");
payload.setDataId("default#default_group#org.ohara.mcs.dto.User");
Response response = oHaraMcsService.request(payload, EventType.GET);
Any data = response.getData();
try {
Metadata metadata = data.unpack(Metadata.class);
return GsonUtils.getInstance().toJson(metadata);
} catch (Exception e) {
return null;
}
}
@GetMapping("/put")
public String put(@RequestParam("name") String name, @RequestParam("age") String age) {
Payload payload = Payload.builder().build();
payload.setConfigData(new User(name, Integer.parseInt(age)));
payload.setNamespace("default");
payload.setGroup("default_group");
payload.setGroup("default_tag");
// data_id 数据唯一表示
payload.setDataId("default#default_group#org.ohara.mcs.dto.User");
Response response = oHaraMcsService.request(payload, EventType.PUT);
Any data = response.getData();
try {
Metadata metadata = data.unpack(Metadata.class);
return GsonUtils.getInstance().toJson(metadata);
} catch (Exception e) {
return null;
}
}
@RequestMapping("/delete")
public String delete() {
Payload payload = Payload.builder().build();
payload.setNamespace("default");
payload.setGroup("default_group");
payload.setGroup("default_tag");
payload.setDataId("default#default_group#org.ohara.mcs.dto.User");
Response response = oHaraMcsService.request(payload, EventType.DELETE);
Any data = response.getData();
try {
Metadata metadata = data.unpack(Metadata.class);
return GsonUtils.getInstance().toJson(metadata);
} catch (Exception e) {
return null;
}
}
}- 测试向配置中心put数据,客户端收到监听推送:http://localhost:9527/user/config/put?name=张三&age=22
- 测试向配置中心get数据 http://localhost:9527/user/config/get
- 测试向配置中心delete数据:http://localhost:9527/user/config/get
二、RAFT核心原理
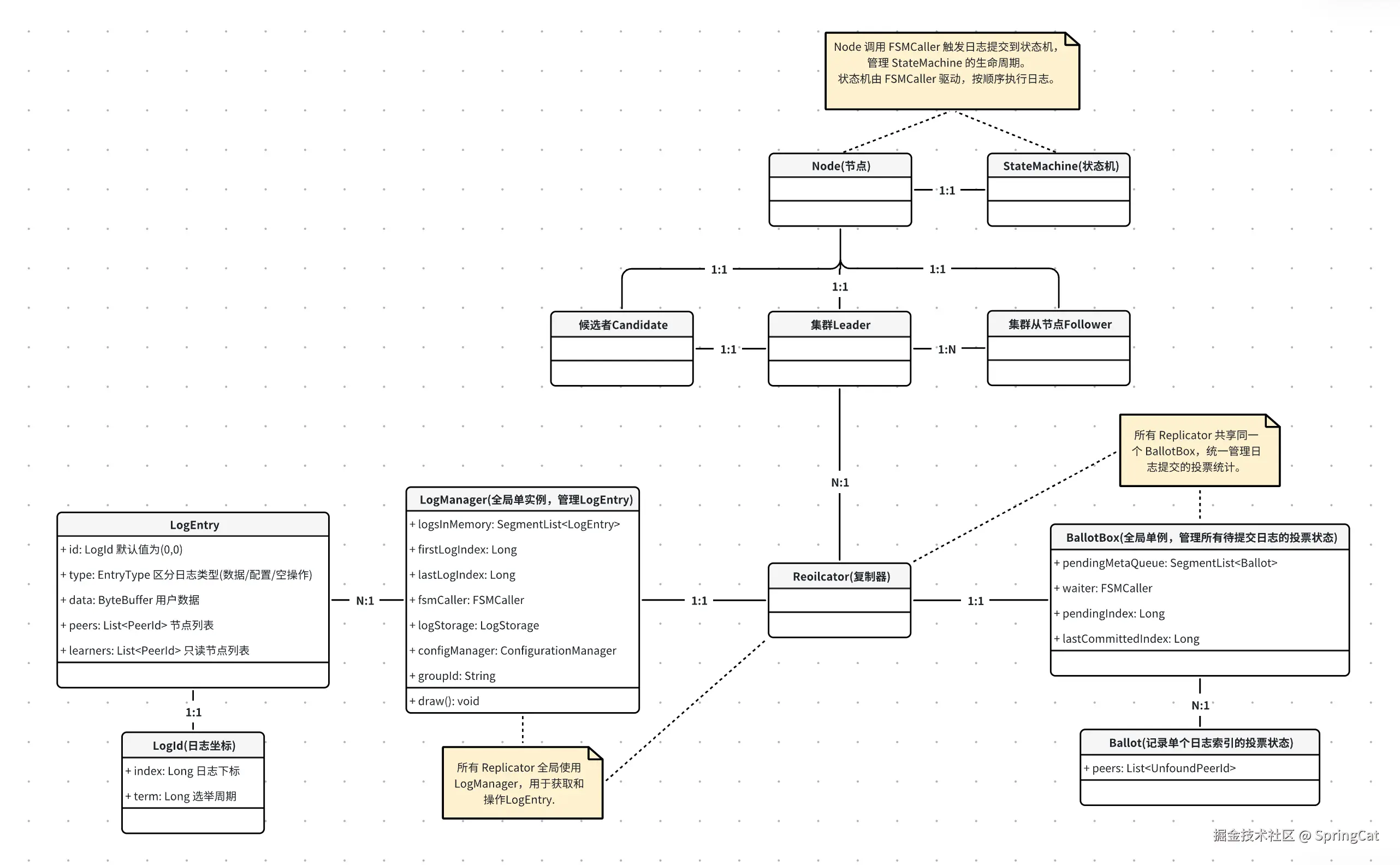
2.1 核心组件关系梳理
| 组件 | 职责与作用 | 关键功能 |
|---|---|---|
| NodeImpl(Node) | Raft 节点的核心实现,负责协议状态管理(Leader/Follower/Candidate)、选举、日志复制、提交等全局协调。 | - 处理状态转换(Leader 选举) - 协调 LogManager、Replicator、FSMCaller 的协作。 |
| FSMCaller | 状态机调用协调者,管理日志提交到状态机的流程,确保顺序性和原子性。 | - 按顺序调用 StateMachine 应用日志 - 处理快照生成与加载。 |
| StateMachine | 用户自定义的业务状态机,执行日志对应的具体操作(如数据更新)。 | - 实现 onApply 处理日志数据 - 实现快照的保存与加载。 |
| LogEntry | 表示一个日志条目,包含业务数据、日志类型(数据/配置变更)、集群配置等信息。 | - 存储用户数据或配置变更信息 - 通过 LogId 标识唯一性。 |
| LogId | 日志的唯一标识符,包含 index(日志索引)和 term(选举周期)。 | - 确保日志顺序和一致性 - 用于冲突检测(如选举和日志复制)。 |
| Replicator | 管理单个 Follower 的日志复制,维护复制状态(如 nextIndex、matchIndex)。 | - 发送 AppendEntries RPC 请求 - 处理响应并更新 BallotBox 的投票状态。 |
| LogManager | 日志的存储、检索、提交管理,处理日志持久化与快照。 | - 持久化日志到存储引擎 - 提供日志查询接口 - 管理 commitIndex 和 lastApplied。 |
| Follower | Raft 节点的被动角色,接收 Leader 的日志和心跳,不主动发起请求。 | - 响应 Leader 的日志复制请求 - 转发客户端请求给 Leader。 |
| Leader | Raft 节点的主动角色,处理客户端请求,复制日志到所有 Follower。 | - 生成新日志条目 - 维护与所有 Follower 的 Replicator 实例。 |
| Candidate | 节点在选举过程中临时成为候选者,发起投票请求以竞争 Leader 身份。 | - 发起 RequestVote RPC - 收集多数派投票以赢得选举。 |
| Ballot | 单个日志条目的投票器,记录哪些节点已成功复制该日志。 | - 跟踪每个日志条目的复制状态 - 判断单个日志是否达成多数派。 |
| BallotBox | 全局投票管理器,统计所有日志条目的多数派状态,确定可提交的日志索引。 | - 维护待提交日志队列 - 更新 lastCommittedIndex 并触发 FSMCaller 提交。 |
组件关系模型图如下所示:
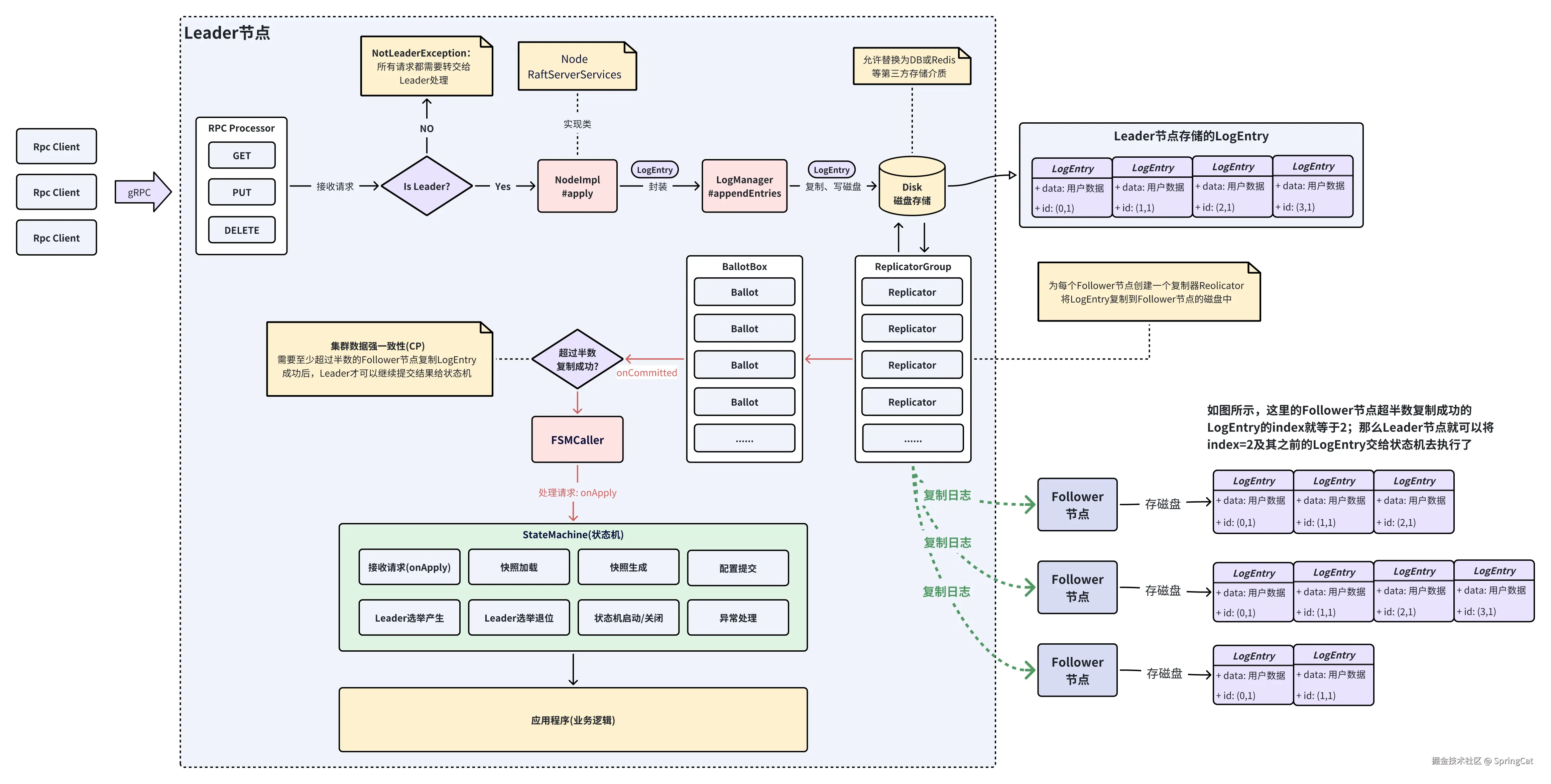
2.2 RAFT请求处理图解
Raft收到用户(客户端)请求时,会先交给Raft协议处理,只有Leader节点可以执行读写请求。Leader会先将用户请求打包成LogEntry写入磁盘,通过一个个Replicator(复制器)将所有打包好的LogEntry复制到Follower节点,每复制成功一个LogEntry,都会向计票器(BallotBox)增加一次计票,直到某一时间点超过半数的Follower成功复制LogEntry(index,term),这时候BallotBox会通知Leader将这些LogEntry打包成Task任务交给自己的状态机(StateMachine)处理。
当Raft协议内部处理完用户请求,这时候才会交给应用程序处理。应用程序需要通过状态机器onApply方法才能拿到数据,官方提供StateMachineAdapter基类。
PS:Replicator(复制器)与Follower节点之间的日志复制、快照下载等动作,都是通过Raft协议内部的RPC通信。JRaft中支持gRPC和BoltRPC两种方式,官方默认推荐使用性能更好的BoltRPC。
2.3 Leader选举原理图解
2.3.1 选举周期与选举时机
- 选举周期:所有Raft节点参与选举投票,每个节点只有1次投票机会,若所有节点投票完,没有形成多数派胜选者(Leader),则会自动进入下一轮选举,直到选举出Leader为止。每新增一个选举周期,LogEntry的term属性会自增1。
- 选举时机:
- Raft集群首次启动时,如果发现集群中没有Leader,自动会触发选举(第一个发起选举投票的Follower接会投票给自己,自己成为候选者Candidate)。
- 当Leader宕机或无法正常向所有Follower节点发送存活心跳(默认间隔100ms),自动触发新的选举(第一个发起选举投票的Follower接会投票给自己,自己成为候选者Candidate)。
- 网络分区,Leader与Follower节点之间无法正常通信。
2.3.2 预选举与正式选举(JRaft优化)
- Raft协议中并没有定义预选举机制,这是JRaft自己在Raft协议基础上做的优化;目的是减少Raft集群选举期间带来的抖动,加快正式选举的Leader诞生,降低选举周期Term次数。
- 预选举请求投票条件:
- 候选人LogEntry日志Term需要大于等于请求接收方Term
- 候选人LogEntry日志索引Index需要大于等于请求接收方Index
- 请求接收方在最近没有收到Leader心跳
2.3.3 退位、宕机、断电恢复
2.4 快照生成与加载
Raft快照(Snapshot)的作用:避免日志无限增长,减少磁盘占用和恢复时间。
随着Raft节点生成或复制的LogEntry越多,日志文件占用磁盘空间也越大,加载读取的IO耗时也更长。
Raft不会像Redis那样去定期重写AOF文件,因为Raft LogEntry中承载的data数据格式是由业务系统决定的,Raft自身无法确定所有LogEntry的data数据格式。
为了避免日志文件越来越大,Raft引入了"快照"机制,将Raft节点将某一时刻内存中的业务数据写入磁盘持久化。
快照写入磁盘完成后,就可以将之前日志文件中的LogEntry数据内容删除了。
节点重启时,如果发现本地日志不完整(如被截断),会优先加载最近的快照恢复状态。
Raft快照相关的配置属性位于com.alipay.sofa.jraft.option.NodeOptions中,三者是逻辑与的关系("&",需要同时满足)
- snapshotIntervalSecs: 默认3600s(1h),快照保存间隔。
- snapshotLogIndexMargin: 默认为0,表示LogEntry的index下标延展到目标值后,触发快照保存。
- snapshotUri: 快照文件存储path,可以由业务系统自定义。
JRaft快照操作具体实现是由com.alipay.sofa.jraft.StateMachine接口定义的:
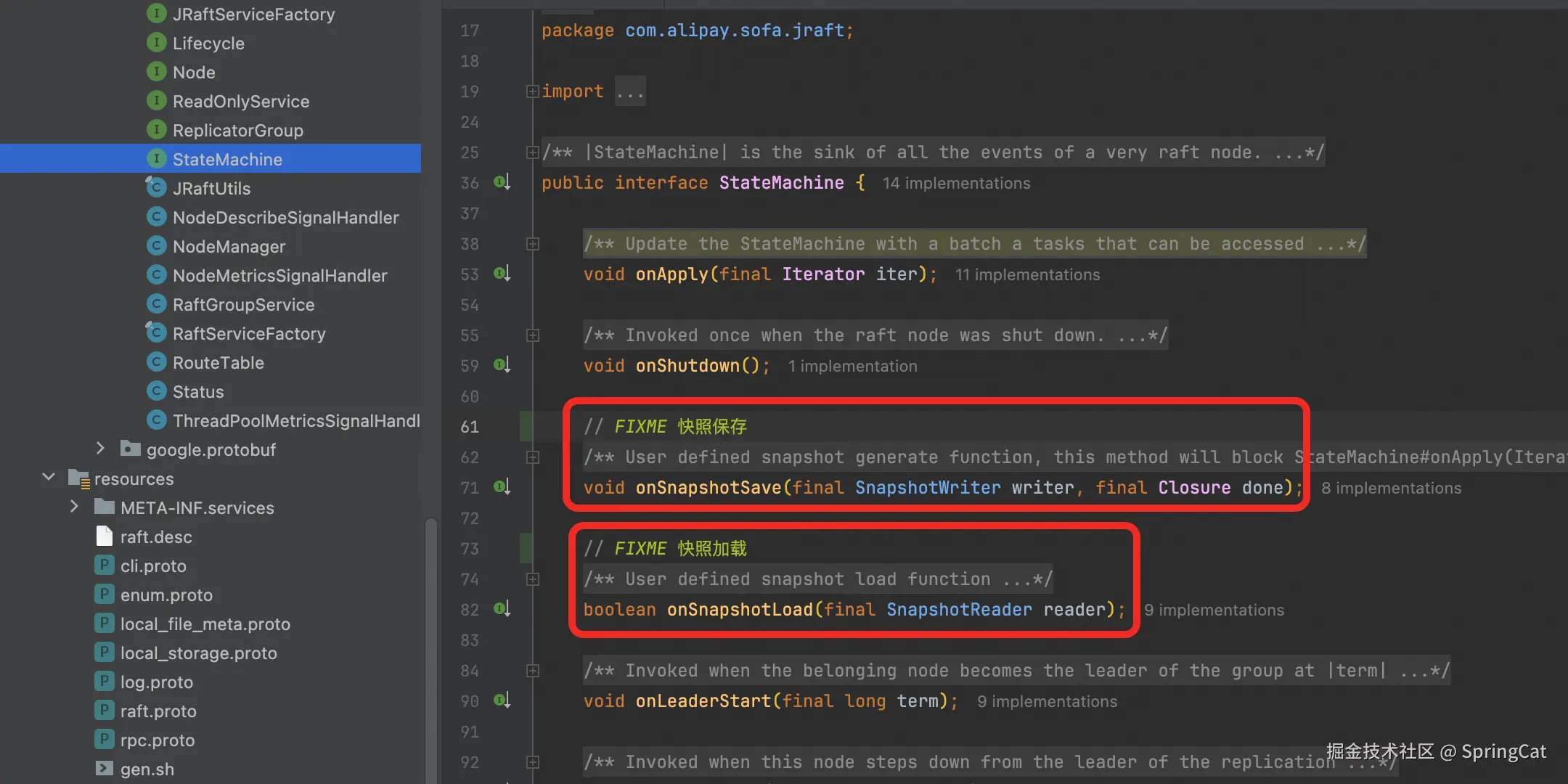
JRaft 默认使用 RocksDB 作为日志存储引擎(也可通过配置替换为其他存储引擎),日志条目会按顺序写入 RocksDB 的键值对中。
日志条目(LogEntry)的持久化存储是集中写入单个日志文件,而不是为每个 LogEntry 单独创建文件。
RocksDB 内部通过 WAL(Write-Ahead Logging) 和 SST(Sorted String Table)文件 管理数据持久化,但用户无需直接操作这些文件。
假设配置的日志存储路径为 raft/logs,RocksDB 会生成以下文件结构:
java
raft/logs/
├── CURRENT // 当前活跃的 Manifest 文件指针
├── IDENTITY // 数据库标识
├── LOCK // 文件锁
├── LOG // RocksDB 预写操作日志(WAL),用于崩溃恢复
├── MANIFEST-000001 // 元数据清单(文件版本、SST 文件列表等)
├── OPTIONS-000005 // 数据库配置
└── *.sst // SST 文件(实际存储日志条目(LogEntry)的键值对数据)
raft/snapshot/snapshot_xxx/ // 快照目录(last_included_index=100, term=5)
├── __raft_snapshot_meta // JRaft 自动生成的快照元数据
└── 用户业务数据文件 // 用户生成的业务数据(数据格式由业务系统定义,序列化后写入)
__raft_snapshot_meta文件内容:
last_included_index:快照包含的最后一个日志条目的索引。
last_included_term:快照对应的任期。
peers:当前集群的节点列表(格式为 host:port)。
learners:只读节点列表(无投票权的节点)。
old_peers:旧集群配置(用于 Joint Consensus 过渡阶段)。
示例:
last_included_index: 100
last_included_term: 5
peers: "127.0.0.1:8080"
peers: "127.0.0.1:8081"
files: "用户业务数据文件"
*.sst文件内容:日志条目(LogEntry)
LogId:日志的索引(index)和任期(term)。
data:用户提交的业务数据(如序列化的操作命令)。
type:日志类型(数据日志 ENTRY_TYPE_DATA 或配置变更 ENTRY_TYPE_CONFIGURATION)。
未压缩的日志:在快照生成前,所有日志条目按顺序存储在 .sst 文件中。
示例:Key: 0x0000000000000064 (100) → Value: LogEntry{index=100, term=5, data=...}
Key: 0x0000000000000065 (101) → Value: LogEntry{index=101, term=5, data=...}
如何单机查看 RocksDB 数据内容?
需要先安装 RocksDB 源码编译插件:
bash
git clone https://github.com/facebook/rocksdb.git
cd rocksdb
make sst_dump使用 sst_dump 解析查看 .sst 文件:
bash
./sst_dump \
--file=/Users/xxx/IdeaProjects/ohara-mcs/raft/config_center_group/127.0.0.1_9001/logs/000037.sst \
--command=scan \
--show_properties在JRaft中,快照保存由以下4个条件触发:
- 1、LogEntry日志条目数累计达到阈值(snapshotLogIndexMargin):1.3.14版本后默认为0。
- 2、定时触发(snapshotIntervalSecs):默认1小时自动触发一次。1和2是逻辑与"&"的关系,二者需同时满足。
- 3、主动调用接口:业务系统可以通过状态机或Raft Client主动调用 NodeImpl#snapshot方法触发快照保存。
- 4、Follower日志落后较多:避免因Follower和Leader日志差距过大导致同步效率低下。
快照生成与加载图解:
