Step 1 : 项目搭建
-
使用 Vite 初始化一个 React 项目:
bashnpm create vite@latest ai-react-translator -- --template react -
进入项目目录并安装依赖:
bashcd react-translator npm install -
运行项目:
bashnpm run dev
Step 2 : 安装 Transformers.js & 思考如何融入大模型
-
从 NPM 安装 Transformers.js:
bashnpm install @huggingface/transformers -
在 Hugging Face 平台上选用一个翻译大模型来为我们完成翻译工作:
Hugging Face 最初专注于开发聊天机器人服务。尽管他们的聊天机器人项目并未取得预期的成功,但他们在GitHub上开源的 Transformers 库却意外地在机器学习领域引起了巨大轰动。如今,Hugging Face 已经发展成为一个拥有超过 100,000 个预训练模型 和 10,000 个数据集 的平台,被誉为机器学习界的 GitHub。
- 在 Hugging Face 的 Model 页面,我们可以看到各式各样的开源大模型。我们可以选择 Translation 标签以找出独具翻译能力特长的大模型。

- 在这里我们选择了 Xenova/nllb-200-distilled-600M 作为我们的翻译模型。
- 它可以在 200 种语言 之间自由切换。
- 可用参数指定语言的 FLORES-200 code 来确定源语言和目标语言,无需再编写 Prompt。
- 它只有 600M(6 亿) 个参数,相对小巧,可以在客户端浏览器中运行。这样的端侧大模型既可以帮我们解决问题,也免去了调取商用大模型的高额开销亦或是部署开源大模型所需的算力资源。
-
思考如何优雅的在浏览器中使用端侧大模型:
- 懒加载 :虽然是端侧模型,但它依旧非常庞大(至少 1 GB),为了用户的体验,在加载页面时不应直接下载大模型,而是等待用户执行翻译任务后再执行下载。
- 单例模式 :既然大模型非常庞大,我们应确保模型只加载一次,避免资源浪费。这时应使用单例模式。 单例模式,保证一个类仅有一个实例,并提供一个访问它的全局节点。
通常我们可以让一个全局变量使得一个对象被访问,但它不能被防止你实例化多个对象,一个最好的方式就是,让类自身负责保存它的唯一实例 。
这个类可以保证没有其它实例可以被创建。后文我们会进行具体实现。
- Web Worker :模型的推理计算量非常大,JS 单线程的设计可能导致计算时页面进程阻塞。因此我们可以使用 HTML5 标准支持的 Web Worker,以赋予 JS 操作多线程的能力,将模型推理与 UI 进程区分开来。
Step 3 : 实现大模型翻译单例
接下来,我们将实现一个单例模式,以编写大模型翻译部分的业务代码。
如何调用大模型执行翻译任务?
首先,我们先了解如何使用 Transformers 调用大模型执行翻译任务。首先,通常每个模型封装的调用方法都不一样,如要快速了解模型的调用方法,最快捷的方式就是到模型页面查看文档:



从上面的信息就可以得知,该模型需要用到 Transformers 库中的 pipeline 来获取一个任务实例。(具体可见文档)
在 Transformers 库中,
pipeline是一个高层次的接口,用于简化和快速执行常见的自然语言处理(NLP)任务。它将预训练的模型与预处理和后处理步骤封装在一起,使得用户能够更轻松地使用这些模型进行任务,如文本分类、情感分析、翻译、问答等,而无需关注底层细节。其他模型也可能要求调用其他类别的接口,这是由模型上传者决定的,我们开发者只要根据示例教程开发即可。
pipeline会根据首个参数指定的任务类型(如 translation)来返回 transformers 封装好的特定任务的方法 (例如 translation 任务对应的是 pipelines.TranslationPipeline) 。然后按照规则调用即可。下面就是简单的调用示例:
js
// 初始化大模型任务实例
const pipe = await pipeline('translation', 'Xenova/nnlb-200-distilled-600M');
// pipeline() 将返回一个方法给 pipe,后续可以调用 pipe() 来运行大模型翻译任务。
// 执行 pipe(),其翻译结果会返回给 output
// 首个参数为翻译的内容(字符串)
// 第二个参数是个对象,指定源语言和目标语言(格式固定,指定方式为 FLORES-200 code,可见文档)
const output = await pipe("我爱你", {
src_lang: 'zho_Hans', // FLORES-200 code:简体中文
tgt_lang: 'eng_Latn', // FLORES-200 code:英语
});如何指定语言可见:FLORES-200 code 文档
实现单例模式
要注意的是,每调用一次 pipeline,就会重新下载一次模型到内存中,这是相当耗费资源的!甚至会导致直接出现报错:

所以我们必须 只构建一次 pipeline ,后续通过这个实例来执行翻译任务。我们在 src 目录下创建一个 translationWorker.js 文件,并在该文件中实现一个 TranslationPipeline 类:
js
// src/translationWorker.js
import { pipeline } from '@huggingface/transformers';
class TranslationPipeline {
static task = 'translation'; // 指定任务类别
static model = 'Xenova/nllb-200-distilled-600M'; // 指定模型
static instance = null; // pipeline 的返回实例
static async getInstance(progress_callback = null) { // 暴露给外部的获取单例对象的方法
if (this.instance === null) { // 如果单例不存在,则创建
this.instance = pipeline(
this.task, // 任务类别
this.model, // 选用模型
{ progress_callback } // 这里本是额外的参数,我们在这里预留一个回调函数,来返回模型的下载进度,后续做一个进度条。
);
}
// 那如果之前已经执行过 pipeline,则实例已经存在,就不会再执行上面的创建过程
return this.instance; // 返回单例对象
}
}透过注释,你便能很轻松地理解整个单例模式的实现过程。其实它就是只向外暴露一个获取实例的方法。透过这个方法,我们可以设置首次访问创建实例,后面再次访问就直接返回先前创建的实例。有效节省资源。下面的 UML 图也可以帮助你理解:

Step 4 : 使用 Web Worker 将翻译进程分离出主线程
我们知道 JS 是单线程的,即页面的 UI 、后台的计算全都是混在一个线程中,如果 JS 忙于计算,就会忽略页面的响应(用户点啥、输入啥都不会有任何反应,就和卡死一样)。 尽管有异步 这一特性,但也是换汤不换药,因为异步只是个缓刑,不代表它就不会在主线程执行了,最终耗时任务还是会阻塞主线程。
这时我们就想用 Web Worker 来赋予我们使用多线程 的能力。如果你不了解它,这里推荐你阅读掘友们的文章:一文彻底学会使用web worker。在这里就简单强调一下使用 Web Worker 的注意事项:
- Web Worker 不能使用本地路径 来调用指定文件,必须是指向同源的网络 URL 地址。
- Web Worker 不能进行任何 dom 操作,也无法获取 dom 对象(因为 window 这个对象只有在主线程才有),因此它只能用作计算用途。
- 主线程和 Web Worker 的子线程可以信息传递,但传递的内容有限。(不可以传递 dom 节点、方法、响应式对象等等,只能传递基本的值和对象)
- Web Worker 在子线程运行的 JS 文件是默认不支持
ES6 Module语法 的。如需import模块或文件,需手动指定 为module模式(后文会介绍)。
接下来我们一起修改 App.jsx 文件,来完成一个用 Web Worker 调用 translationWorker.js 的 demo:
-
使用
useRef()创建一个translationWorker变量存储 Worker 实例:js// src/App.jsx import { useRef } from 'react' import './App.css' function App() { // Worker 线程 const translationWorker = useRef(null); // 创建一个用于保存 Worker 线程的 ref 对象 return ( <> {/* 等待填入页面代码 */} </> ) }; export default App;useRef的特性:useRef是 React 提供的一个 hook,它用于持有对 DOM 元素或其他值的引用。与useState不同的是,useRef在重新渲染时 不会 触发组件的重新渲染,且会保持其值的持久性。- 通过
useRef可以在多个渲染周期中保持对对象(如Worker实例)的引用,而不会因为组件的重新渲染而丢失或重新初始化。
-
接下来,则是在
App.jsx渲染时就初始化一个 Web Worker 实例绑定到刚刚创建的translationWorkerref上。-
这里我们使用
useEffect()来实现:js// src/App.jsx import { useRef, useEffect } from 'react' import './App.css' function App() { // Worker 线程 const translationWorker = useRef(null); // 创建一个用于保存 Worker 线程的 ref 对象 useEffect(() => { // 每次组件渲染后执行 if (!translationWorker.current) { // 如果 Worker 线程不存在,则创建 // 创建一个新的 Worker 线程,加载 translationWorker.js 文件 translationWorker.current = new Worker( new URL('./translationWorker.js', import.meta.url), // 传入 translationWorker.js 文件的 URL { type: 'module' // 指定 Worker 线程的类型为模块(以支持 ES Module) } ); } },[]); // 为 useEffect() 添加第二个参数 "[]" return ( <> {/* 等待填入页面代码 */} </> ) }; export default App;useEffect是 React 提供的一个用于处理副作用的 hook。副作用通常指的是那些不直接影响 UI 渲染的操作,例如:- 数据获取
- 订阅事件
- 操作 DOM
- 启动外部资源(如 Web Worker)
在这种情况下,创建 Web Worker 属于 副作用 ,因为它是一个异步的任务,不直接影响组件的 UI 渲染。因此,使用
useEffect来处理 Web Worker 的创建和销毁是符合 React 的设计理念的。仔细的同学会发现,
useEffect()有两个参数,第 1 个参数是一个函数 ------useEffect执行时调用的函数,第 2 个参数是一个空数组 ------ 依赖数组。只要依赖数组里内容不变,useEffect()就不会再次运行。添加一个空数组作为依赖数组,即可确保useEffect只在页面渲染时加载一次。如不添加,则页面每重新渲染(变更文字、点击按钮等),都会运行一次useEffect()第 1 个参数指定的函数。 -
观察 Web Worker 的创建过程:
jsnew Worker( new URL('./translationWorker.js', import.meta.url), // 传入 translationWorker.js 文件的 URL { type: 'module' // 指定 Worker 线程的类型为模块(以支持 ES Module) } );我们发现,Web Worker 的创建非常简单,就是
new Worker()。它接收两个参数,第一个就是子线程需要执行的 JS 文件路径。要注意,这里的路径不是本地环境里的文件目录,而是互联网上的 URL 地址 。而且这个地址不可跨域 。因此我们这里使用new URL()和 Vite 提供的import.meta.url来为translationWorker.js创建线上访问地址。那么第二个参数则是个对象,是关于这个 Worker 子线程的相关配置。这里我们配置了
type: 'module'是因为我们在translationWorker.js中使用了ES Module语法:jsimport { pipeline } from '@huggingface/transformers';Web Worker 创建的子线程是默认不支持
ES Module的,因此如果我们要使用import语句,就必须做这项配置。
-
-
现在,我们成功用 Web Worker 创建了子线程。那我们如何让子线程执行翻译任务,并将结果返回呢?这一步我们会介绍其原理和实现方式。
- 主线程和 Web Worker 的子线程存在 通信机制 ,二者可以通过 收发消息的方式 来执行某些任务或发送任务执行的结果。这一机制源于以下三个方法:
Worker.postMessage():该方法可以接收一个 JS 对象参数,并将其发送给该 Worker 对应的子线程。DedicatedWorkerGlobalScope: postMessage():这个方法和上一个几乎没有区别,只特别在它在DedicatedWorkerGlobalScope对象上 ------ 也就是Worker(子线程) 的全局作用域。子线程可以直接使用self.postMessage()调用该方法向主线程发送消息。EventTarget.addEventListener():熟悉的老朋友------事件监听器。主线程和子线程接到对方发来的消息时,都会在自身对象上触发message事件。
- 接下来我们就使用这样的通信机制,来试验一下翻译功能:
-
我们先修改
App.jsx,设计了一个简单的页面,并为其添加了一些状态。页面上的"点击翻译"按钮绑定了handleTranslate()方法,点击按钮后该方法会向 Worker 线程发送消息,消息包含需要翻译的文本、源语言、目标语言。js// src/App.jsx import { useRef, useEffect, useState } from 'react' import './App.css' function App() { // 按钮可用状态 const [disabled, setDisabled] = useState(false); // 输入/输出 const [inputText, setInputText] = useState('Hello, world!'); const [outputText, setOutputText] = useState(''); const [srcLang, setSrcLang] = useState('eng_Latn'); const [tgtLang, setTgtLang] = useState('zho_Hans'); // Worker 线程 const translationWorker = useRef(null); // 创建一个用于保存 Worker 线程的 ref 对象 useEffect(() => { // ...此部分代码忽略 },[]); const handleTranslate = () => { setDisabled(true); // 禁用按钮 translationWorker.current.postMessage({ text: 'Hello, world!', src_lang: srcLang, tgt_lang: tgtLang }); } return ( <> <div className='container'> <div className='language-container'> <select value={srcLang} onChange={e => setSrcLang(e.target.value)} aria-label='源语言'> <option value='eng_Latn'>English</option> <option value='zho_Hans'>简体中文</option> </select> <select value={tgtLang} onChange={e => setTgtLang(e.target.value)} aria-label='目标语言'> <option value='eng_Latn'>English</option> <option value='zho_Hans'>简体中文</option> </select> </div> <div className='textbox-container'> <textarea value={inputText} rows={3} onChange={e => setInputText(e.target.value)}></textarea> <textarea value={outputText} rows={3} readOnly></textarea> </div> </div> <button disabled={disabled} onClick={handleTranslate}>点击翻译</button> </> ) }; export default App; -
接着编写
translationWorker.js中接受消息、执行翻译业务并返回翻译结果的业务代码。- 在该文件中使用
self.addEventListener()方法监听主线程发送来的消息。接收到消息后先获取翻译的实例对象,首次调用会先下载模型初始化实例(我们已经做了单例模式)。 - 这里初始化实例的时候,传了一个回调函数,这是我们前文埋下的伏笔,用于获取模型的下载进度并发送给主线程,后续我们可以做一个进度条向用户展示模型加载状态,改善用户体验。
- 模型加载结束后,就可以执行
translator开始翻译,调用方法在前文 "如何调用大模型执行翻译任务? " 部分已经提到。最后将翻译结果使用postMessage返回给主线程。
js// src/translationWorker.js import { pipeline } from '@huggingface/transformers'; class TranslationPipeline { // 此部分代码略 ... } self.addEventListener('message', async (e) => { // 添加一个事件监听器,用于处理主线程发送的消息 const { text, src_lang, tgt_lang } = e.data; // 解构消息中的数据 const translator = await TranslationPipeline.getInstance(load_process => { self.postMessage(load_process); // 将模型下载进度发送回主线程 }); // 获取单例对象 const output = await translator(text, { src_lang, tgt_lang }); // 调用翻译方法 self.postMessage({ status: 'complete', output }); // 将翻译结果发送回主线程 }); - 在该文件中使用
-
最后我们返回到
App.jsx编写一下处理子线程返回的消息的逻辑。- 我们创建了一个
handleWorkerMessage()方法,将事件中的数据打印出来。在useEffect中将该方法挂载到 Worker 的消息事件监听器上。 - 然后在
useEffect中补上一个return(在组件卸载时执行),将事件监听器给移除。
js// src/App.js import { useRef, useEffect, useState } from 'react' import './App.css' function App() { // useState() 部分略... useEffect(() => { // 每次组件渲染后执行 if (!translationWorker.current) { // 如果 Worker 线程不存在,则创建 // new Worker 部分略 ... } // 添加一个事件监听器,用于处理 Worker 线程发送的消息 translationWorker.current.addEventListener('message', handleWorkerMessage); // 在组件卸载时,清除 Worker 线程的事件监听器 return () => translationWorker.current.removeEventListener('message', handleWorkerMessage); },[]); // 为 useEffect() 添加第二个参数 [],来确保只在页面渲染时加载一次。 // 处理 Worker 线程发送的消息 const handleWorkerMessage = (e) => { console.log(e.data); // 打印 Worker 线程发送的消息 }; const handleTranslate = () => { // 此部分省略... } return ( // 此部分省略... ) }; export default App;-
我们先到页面中点击一下翻译按钮,观察一下控制台的输出情况。可以看到控制台弹出了非常多的消息,其中有很多
status: 'progress'的消息,这就是我们在获取pipeline单例时我们埋下的那个回调函数,一直在为我们输出pipeline的加载进度。 -
因为这个下载进度刚好有
status这一字段,并完美的区分了模型当前的状态。所以为了方便我们区分消息类别做消息处理,我们在translationWorker.js中返回翻译结果时也手动添加了status: 'complete'字段。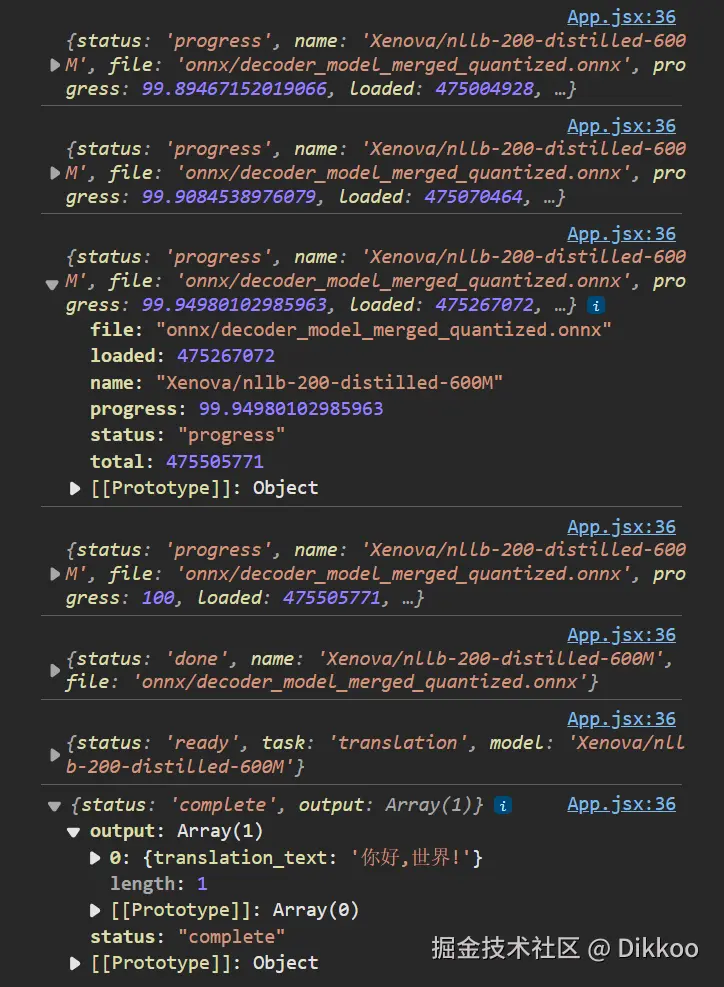
-
这下我们了解了消息体的结构,就可以处理消息,更新翻译结果了。
jsconst handleWorkerMessage = (e) => { switch (e.data.status) { case 'complete': // 如果翻译完成 setOutputText(e.data.output[0].translation_text); // 更新输出文本 setDisabled(false); // 启用按钮 break; }; } -
运行一下,看看效果:

可以看到,等待时间还是很长的,没有任何加载提示 UI 效果特别差。后文我们会继续优化这一问题。但到目前,我们已经完成了最核心的业务功能! 🎉🎉🎉
- 我们创建了一个
-
- 主线程和 Web Worker 的子线程存在 通信机制 ,二者可以通过 收发消息的方式 来执行某些任务或发送任务执行的结果。这一机制源于以下三个方法: