JVM基础回顾
Java 作为一门高级程序语言,由于它自身的语言特性,它并非直接在硬件上运行,而是通过编译器(前端编译器)将 Java 程序转换成该虚拟机所能识别的指令序列,也就是字节码,然后运行在虚拟机之上的;JVM的存在主要
- 提供了可移植性,一旦 Java 代码被编译为 Java 字节码,便可以在不同平台上的 Java 虚拟机实现上运行,选择在虚拟机上实现就可以避免在硬件上实现的高成本
- 提供了一个代码托管的环境,代替我们处理部分冗长而且容易出错的事务,例如内存管理。以及在这个运行时的环境里可以加入垃圾回收,类型检查,安全权限等功能,使开发人员免于书写无关业务逻辑的代码,提升开发效率
那么我们知道从硬件视角来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。这里也是java与一些静态编译语言的不同。
在 HotSpot 里面,上述翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。
前者的优势在于启动速度快,无需等待编译,无额外内存占用;而后者的优势在于实际运行速度更快,程序启动后,编译器逐渐发挥作用,把越来越多的热点代码优化编译保存成成本地代码,可以减少解释器的中间消耗,提高执行效率。
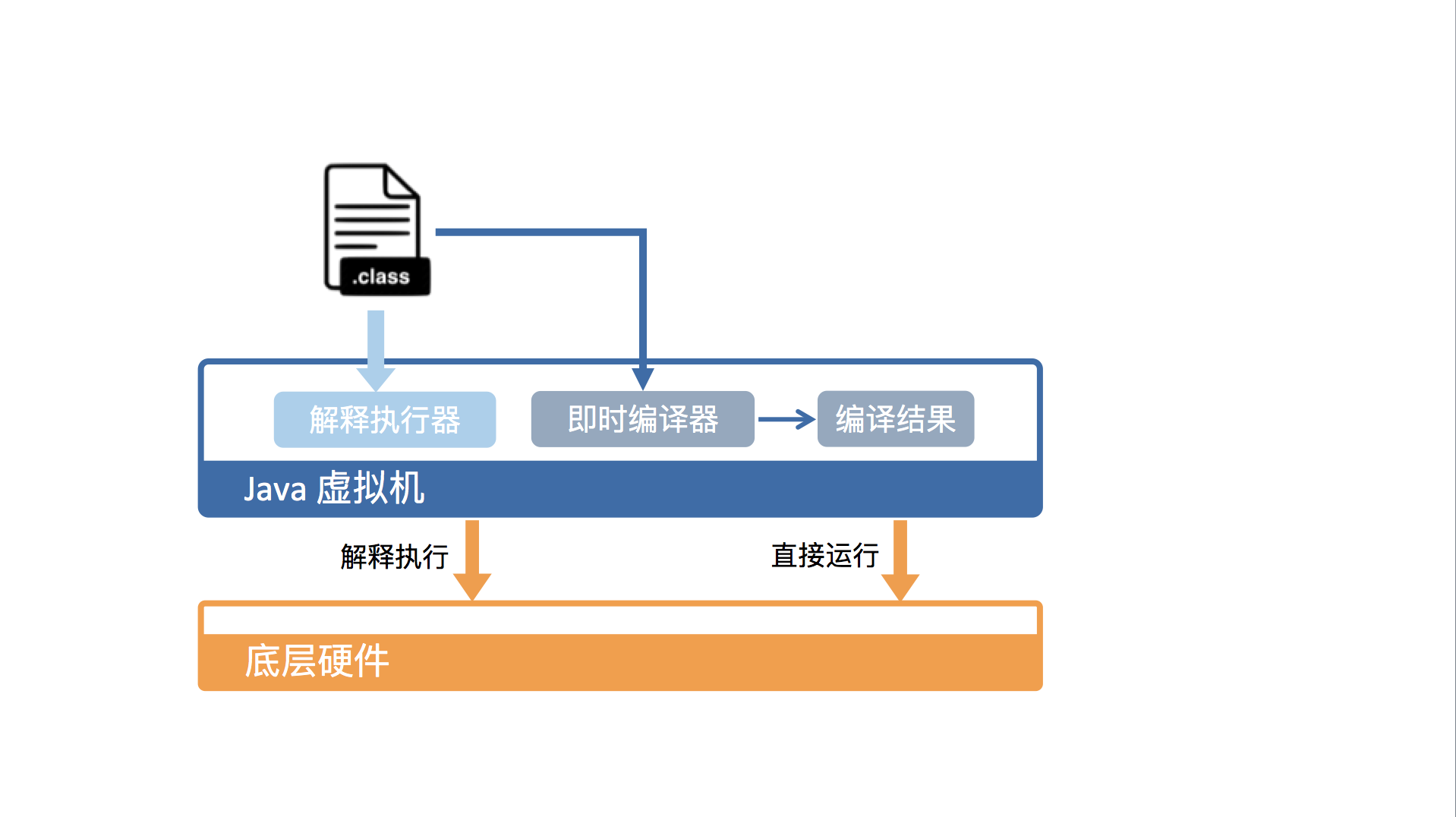
HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
Hot Spot即时编译器
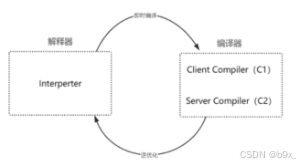
为了满足不同用户场景的需要,HotSpot 内置了多个即时编译器:C1、C2 和 Graal(Java 10 引入的实验性即时编译器)。
C1 又叫做 Client 编译器,面向的是对启动性能有要求的客户端程序,采用的优化手段相对简单,因此编译时间较短。
C2 又叫做 Server 编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
在 Java 7 以前,我们需要根据程序的特性选择对应的即时编译器。启动性能有要求的程序,我们采用编译效率较快的 C1。对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的 C2。
Java 8 默认使用分层编译,可以动态的选择使用C1和C2编译器。方法代码会先被解释器解释执行,然后热点方法首先会被 C1 编译,而后热点方法中的热点会进一步被 C2 编译。
分层编译的引入在于让即时编译更具备灵性,针对不同代码的实际情况选取最佳的编译路径,也是在程序启动速度、编译时间与运行效率之间达到最佳平衡。
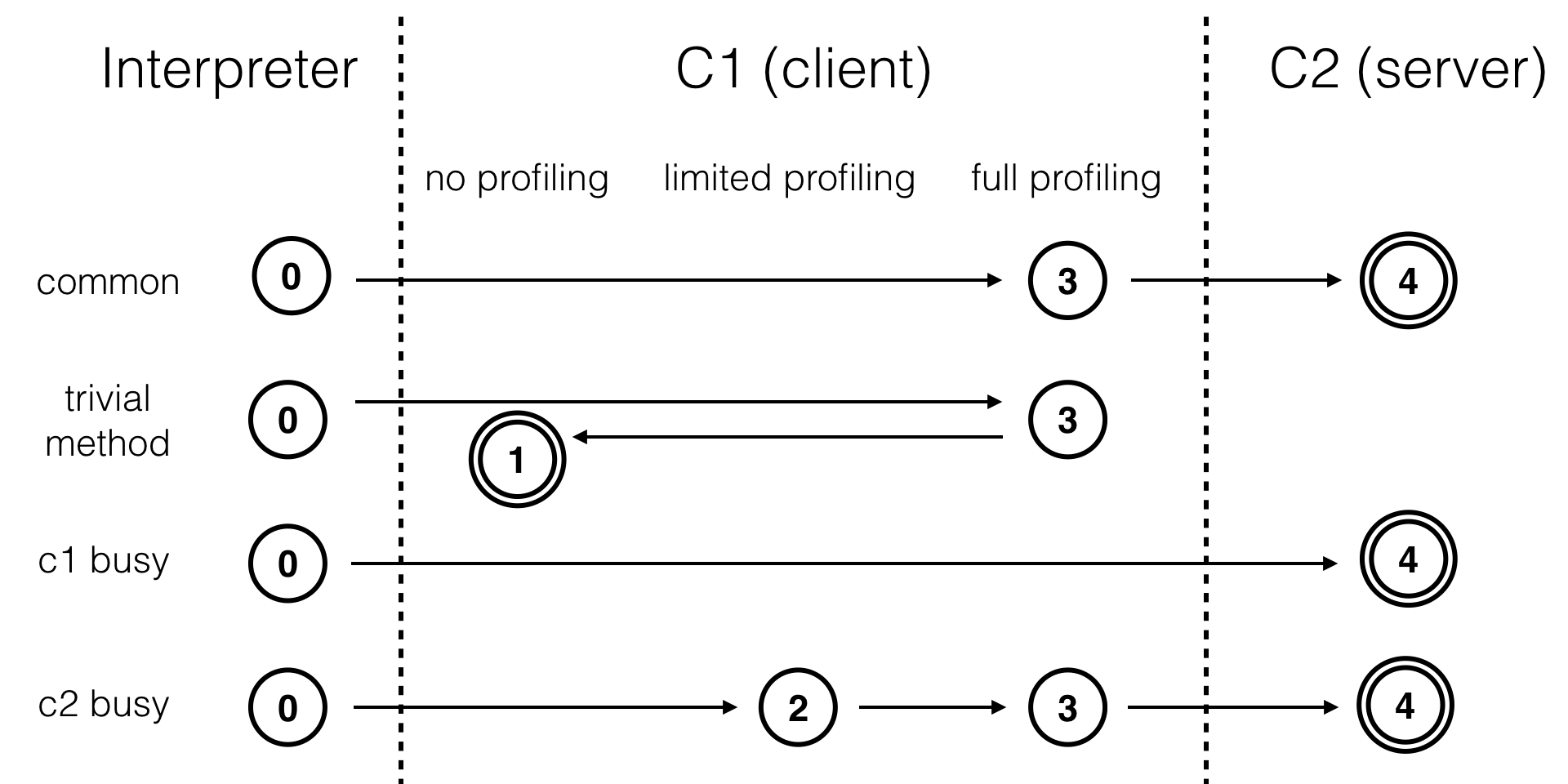
那么具体分层编译的运行机制是什么呢?(http://cr.openjdk.java.net/~iveresov/tiered/Tiered.pdf)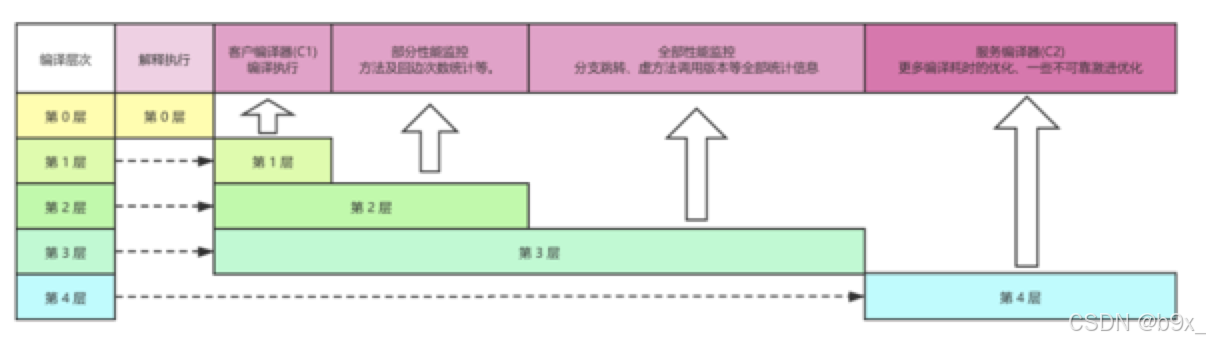
- 解释执行;(带 profiling , profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据)
- 执行不带 profiling 的 C1 代码;
- 执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
- 执行带所有 profiling 的 C1 代码;
- 执行 C2 代码。
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。
对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层
即时编译的触发
Java 虚拟机是根据方法的调用次数以及循环回边的执行次数来触发即时编译的。上边提到,Java 虚拟机在分层编译 0 层、2 层和 3 层执行状态时进行 profiling,其中就包含方法的调用次数和循环回边的执行次数。
循环回边:字节码中可以简单理解为往回跳转的指令;
具体来说,在不启用分层编译的情况下,当方法的调用次数和循环回边的次数的和,超过由参数 -XX:CompileThreshold 指定的阈值时(使用 C1 时,该值为 1500;使用 C2 时,该值为 10000),便会触发即时编译。当启用分层编译时,Java 虚拟机将不再采用由参数 -XX:CompileThreshold 指定的阈值(该参数失效),而是使用另一套阈值系统。在这套系统中,阈值的大小是动态调整的。所谓的动态调整其实并不复杂:在比较阈值时,Java 虚拟机会将阈值与某个系数 s 相乘。该系数与当前待编译的方法数目成正相关,与编译线程的数目成负相关。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 系数的计算方法为: s = queue_size_X / (TierXLoadFeedback * compiler_count_X) + ``1 其中X是执行层次,可取``3``或者``4``; queue_size_X是执行层次为X的待编译方法的数目; TierXLoadFeedback是预设好的参数,控制``3``、``4``层,其中Tier3LoadFeedback为``5``,Tier4LoadFeedback为``3``; compiler_count_X是层次X的编译线程数目。 |
通常情况下,方法会首先被解释执行,然后被 3 层的 C1 编译,最后被 4 层的 C2 编译。
http://cr.openjdk.java.net/~iveresov/tiered/Tiered.pdf

即时编译的优化
基于分支的优化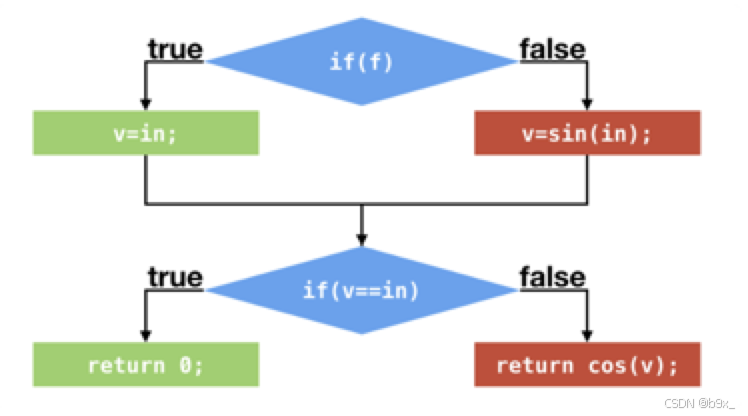

假设应用程序调用该方法时,所传入的 boolean 值皆为 true。那么针对两次判断,false跳转的次数都为 0。C2 可以根据这两个分支 profile 作出假设,在接下来的执行过程中,这两个条件跳转指令仍旧不会发生跳转。基于这个假设,C2 便不再编译这两个条件跳转语句所对应的 false 分支了。
那么优化后的C代码将直接返回0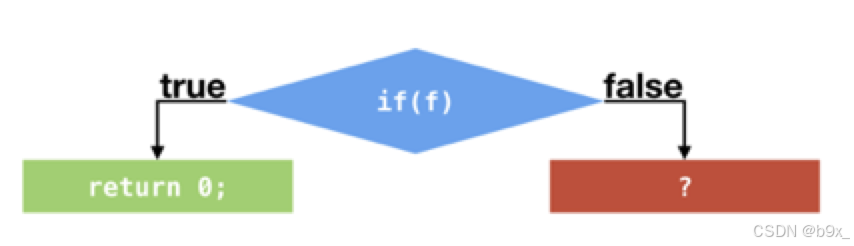
;
根据条件跳转指令的分支 profile,即时编译器可以将从未执行过的分支剪掉,以避免编译这些很有可能不会用到的代码,从而节省编译时间以及部署代码所要消耗的内存空间。分支 profile 出现仅跳转或者仅不跳转的情况并不多见。即时编译器对分支 profile 的利用也不仅限于"剪枝"。它还会根据分支 profile,计算每一条程序执行路径的概率,以便某些编译器优化优先处理概率较高的路径。当假设失败的情况下,Java 虚拟机给出的解决方案便是去优化,即从执行即时编译生成的机器码切换回解释执行
基于类型的优化
方法内联
公共子表达式消除
数组边界检查消除
逃逸分析
总结:
1.即时编译-将Java字节码编译成可优化可复用的机器码,运行在底层硬件之上,这么做是为了提高代码的执行效率,提高性能峰值,其触发点是热点代码,热点代码是通过方法的调用次数或者回边循环的次数来筛选的
2.分层编译的引入是为了让即时编译更具备灵性,使得虚拟机可以根据实际运行情况以及相应的算法动态选择执行代码的编译路径,通常情况下,热点方法会先被解释执行,然后被C1编译,再被C2编译
分层编译是一种折衷的方式,既能够满足部分不热的代码能够在短时间内执行完成,也能满足很热的代码能够拥有最好的优化、执行效率.
资料来源:
1.《深入拆解虚拟机》 郑雨迪