目录
一、特殊类的设计:
1、设计一个不能够拷贝的类:
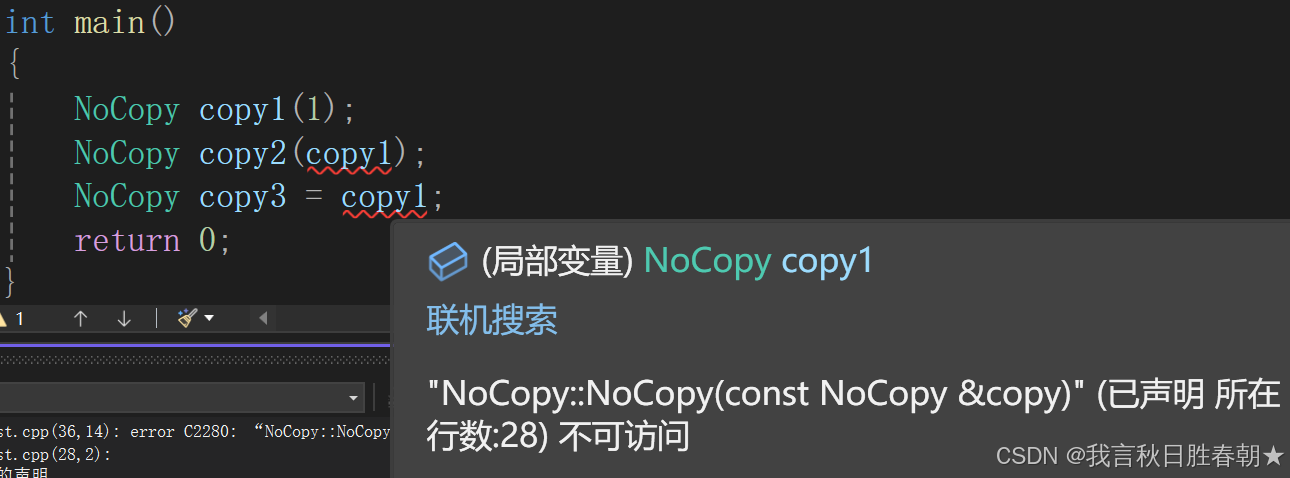
在C++98中,可以将该类的拷贝构造 和复制重载 在私有访问权限中声明不定义
cpp
//设计一个不能被拷贝的类
class NoCopy
{
public:
NoCopy(int n)
:_n(n)
{}
private:
NoCopy(const NoCopy& copy)
{}
NoCopy& operator=(const NoCopy& copy)
{}
int _n;
};
为什么呢?
这样能够保证其在外面定义的类不能够调用拷贝构造和赋值重载,进而这个类创建的对象就不能被拷贝了
在C++11中新增了delete的用法,在默认成员函数后面跟上 = delete,这样就表示让编译器删除该默认成员函数
cpp
class NoCopy
{
public:
NoCopy(int n)
:_n(n)
{}
private:
NoCopy(const NoCopy& copy) = delete;
NoCopy& operator=(const NoCopy& copy) = delete;
int _n;
};
2、设计一个只能在堆上创建的类
设计这个类有三步:
1、首先将构造函数私有化,这样就保证不能随便创建新对象,就只能通过我们自己写的接口来创建对象
2、向外部提供一个创建对象的接口,并且这个接口要设计成静态的,返回就直接返回new 对象
3、完成上述两个还不全,还要防止在外面进行拷贝构造导致在栈上创建了新对象
cpp
class HeapOnly
{
public:
static HeapOnly* CreatObj()
{
return new HeapOnly;
}
private:
//将构造函数私有化
HeapOnly(){}
//将拷贝构造和赋值重载删掉
HeapOnly(const HeapOnly& honly) = delete;
HeapOnly& operator=(const HeapOnly& honly) = delete;
};
当我们进行赋值操作后,打印地址看看发现地址是不一样的,为什么呢?----- 难道拷贝构造或者赋值重载没有被删吗
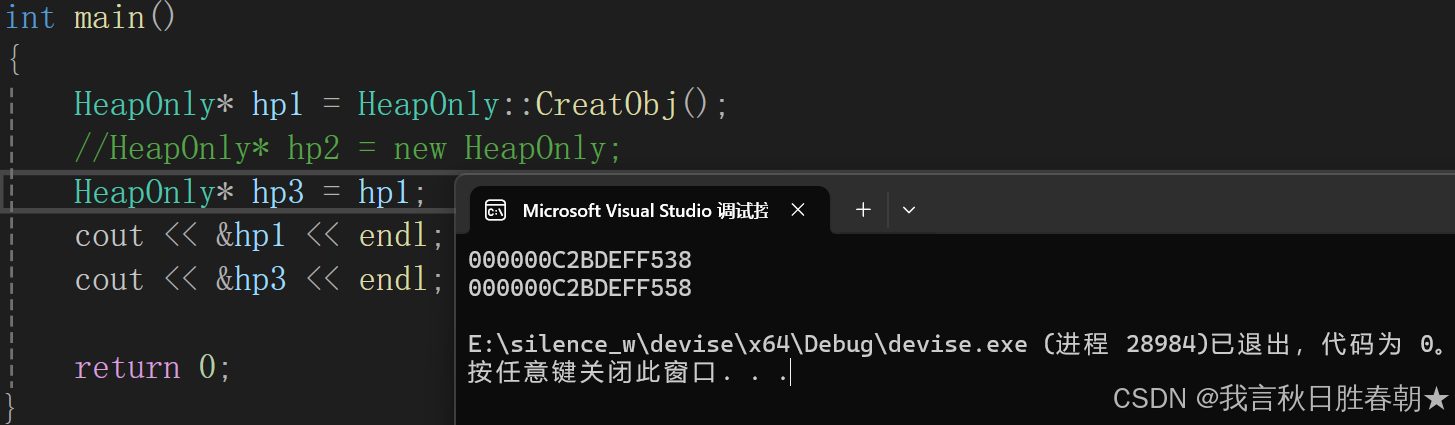
他们其实是被删了,这里发生的是指针拷贝而非对象拷贝,这里是将指针变量hp3和hp1进行拷贝,这是属于内置类型的浅拷贝,与HeapOnly对象无关

当我们进行解引用操作后进行赋值或者拷贝构造此时就发现编译错误了
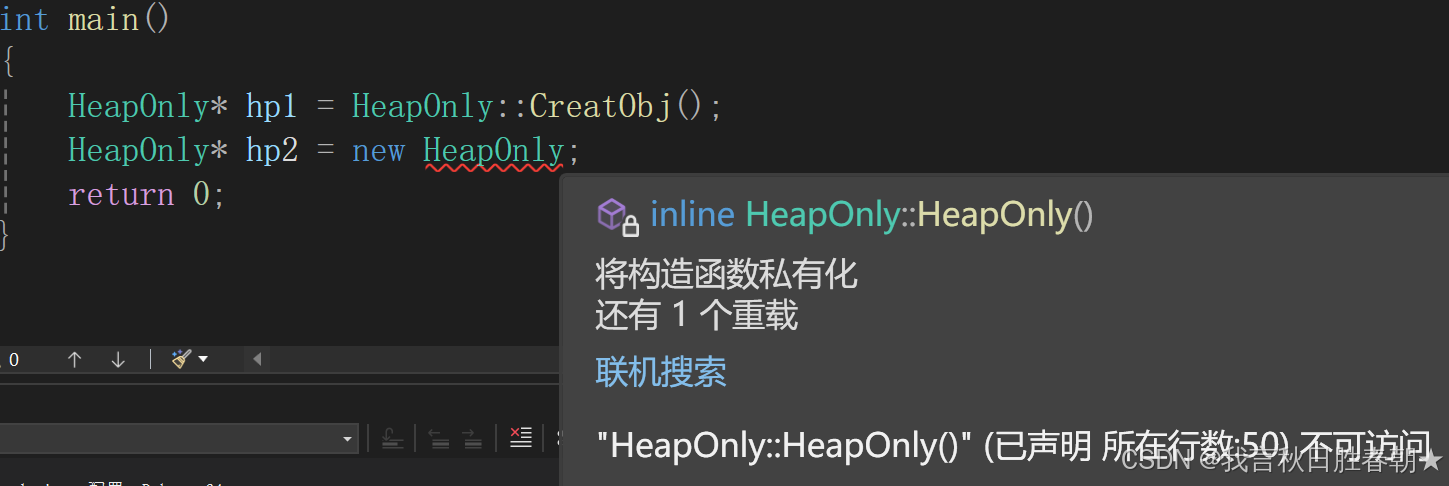
为什么CreatObj函数要设计成静态的呢?
如果CreateObj函数不设计成静态的,那么它就是一个非静态成员函数,此时调用它就需要一个对象,但是我们又没有对象,要创建第一个对象,在外面是创建不了的,因为把构造函数私有了,这自然就导致了逻辑矛盾,
所以这里要将CreatObj函数设计成静态,这样调用这个静态函数直接通过类域进行调用(HeapOnly::CreatObj()),这样就不需要实例化了,很好解决了需要对象而又没有对象的问题
通过上述了解,这样就能够强制对象只能在堆上创建,如果外面想在栈上创建,但是因为构造函数私有化了,不能够创建,所以只能通过我们写的CreatObj函数在堆上创建对象
3、设计一个只能在栈上创建的类
设计这个类有三步:
1、将构造函数私有化,防止外部直接调用构造函数
2、在向外部提供一个static的接口,直接在栈上创建一个对象返回
3、将new和delete禁用,防止外部通过new在堆上创建对象
cpp
class StackOnly
{
public:
static StackOnly CreatObj()
{
return StackOnly();
}
private:
StackOnly()
{}
//将new和delete禁用
void* operator new(size_t size) = delete;
void operator delete(void* ptr) = delete;
};·new和delete的原理:
new在堆上申请空间实际分为两步,首先调用operator new函数在堆上申请空间,然后是在申请的堆空间上执行构造函数,完成对象的初始化工作
delete在释放堆空间也分为两步,第一步是在该空间上执行析构函数,完成对象中资源的清理工作,第二步是调用operator delete函数释放对象的空间
默认是调用在全局中的new和delete,但是如果在类中重载了专属的new和delete那么就会调用专属的重载的函数,所以只要把operator new函数和operator delete函数屏蔽掉,那么就无法再使用new在堆上创建对象了
4、设计一个不能被继承的类:
方法一:
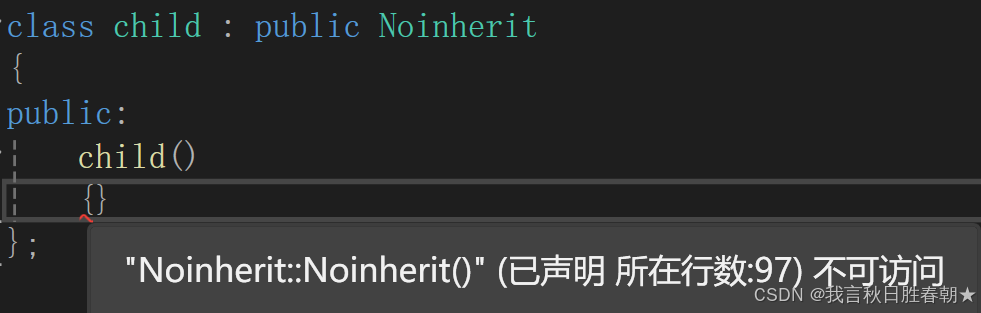
将构造函数私有化即可,这是因为当将父类的构造函数私有化了后,子类调用构造函数的时候,必须调用父类的构造函数,但是父类的构造函数私有化了,这样子类是无法访问父类的构造函数的,所以该类被继承后的子类是无法创建出对象的
cpp
class Noinherit
{
public:
private:
Noinherit()
{}
};
方法二:
C++11中引入了关键字final
这个就比较简单了,直接在类后面加上final关键字修饰,被final修饰的类叫做最终类,是不能够被继承的
cpp
class Noinherit final
{
public:
Noinherit()
{}
};二、单例模式:
在C++中,有大佬根据其经验了许多设计模式,类似于打仗时期的兵法,这些设计模式目的是让代码保证可靠性,更容易被他人理解,使编程更加工程化
设计一个只能创建一个对象的类:
一个类只能创建一个对象,这是单例模式,保证整个程序中,该类只有一个实例化的对象
实现单例模式有两种方法 饿汉模式 与 懒汉模式
饿汉模式:
饿汉模式就是不管在将来的程序中是否使用,在程序启动的时候就创建一个唯一的实例化对象
1、保证在程序启动的时候就创建一个对象
2、将构造函数私有化,保证在外面不能创建对象
3、提供获取单例对象的接口函数
4、防拷贝,将拷贝构造和赋值重载删掉
cpp
namespace hungry
{
class single
{
public:
static single& Getsingle()
{
return _single;
}
void Add(const pair<string, string> kv)
{
_dict[kv.first] = kv.second;
}
void Print()
{
for (auto& e : _dict)
{
cout << e.first << ":" << e.second << endl;
}
}
private:
single(){}
single(const single& sg) = delete;
single& operator=(const single& sg) = delete;
//类内声明
static single _single;
map<string, string> _dict;
};
//类外定义
single single::_single;
}这样,我们的饿汉模式的单例就能够跑起来了
cpp
int main()
{
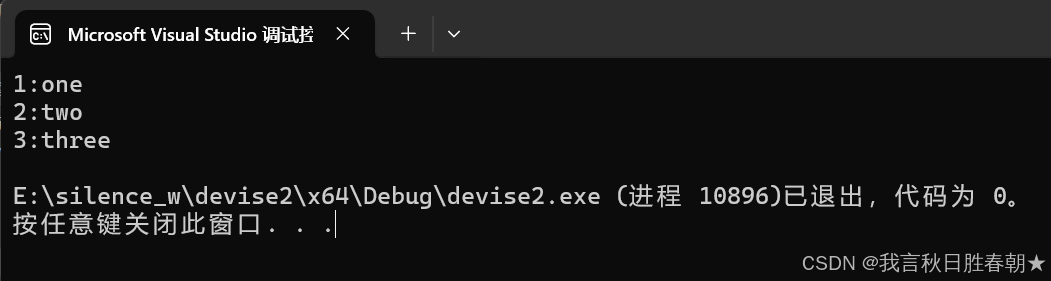
hungry::single::Getsingle();
hungry::single::Getsingle().Add({ "1","one" });
hungry::single::Getsingle().Add({ "2","two" });
hungry::single::Getsingle().Add({ "3","three" });
hungry::single::Getsingle().Print();
return 0;
}
优点:代码简洁直观,适合快速开发,实例在类加载时已创建,调用 Getsingle() 方法时直接返回,无延迟
缺点:要提前实例化,导致进程启动慢,并且若实例未被使用或初始化代价较高,可能造成资源浪费
适用场景:
- 实例占用资源较少,且程序运行中一定会被使用。
- 对性能敏感的场景,希望避免首次访问的延迟
懒汉模式:
与饿汉模式不同的是,懒汉模式并不是在程序启动的时候创建,而是当在第一次使用的时候生成唯一的实例
饿汉模式和懒汉模式的理解:
这就好像在吃完饭后,如果是饿汉模式,就将碗洗了,这样在下一次吃饭的时候直接用就可以了,如果是懒汉模式,那么就是在下一次吃饭的时候再洗碗后用
1、将构造函数私有化,保证在外面不能创建对象
2、防拷贝,将拷贝构造和赋值重载删掉
3、用指针初始化的时候就设置为 nullptr了,证明没有实例,但是如果不使用指针,当直接声明的时候,其实就已经调用构造函数了,就不能保证延迟实例化
4、一般单例不用释放,但是如果在特殊场景:中途需要显示释放,程序结束时,需要做一些特殊动作(如打印日志到文件),此时就需要显示写一个释放指针函数,并且这里如果抛异常导致执行流很乱,或者是有多个出口,那么最好不手动调用,而是创建一个对象在程序结束的时候调用析构函数
cpp
namespace lazy
{
class single
{
public:
static single& Getsingle()
{
if (_psing == nullptr)
{
_psing = new single;
}
return *_psing;
}
static void Delsingle()
{
//如果_psing不为空,这里是手动释放
if (_psing)
{
cout << "static void Delsingle()" << endl;
delete _psing;
_psing = nullptr;
}
}
void Add(const pair<string, string> kv)
{
_dict[kv.first] = kv.second;
}
void Print()
{
for (auto& e : _dict)
{
cout << e.first << ":" << e.second << endl;
}
}
//嵌套一个内部类,当这个成员销毁的时候调用我们显示写的手动释放指针函数
class AUTO
{
public:
~AUTO()
{
cout << "~AUTO()" << endl;
lazy::single::Delsingle();
}
};
private:
single(){}
single(const single& sg) = delete;
single& operator=(const single& sg) = delete;
map<string, string> _dict;
//类内声明
//指针保证延迟实例化
static single* _psing;
static AUTO _AUTO;
};
//类外定义
single::AUTO single::_AUTO;
single* single::_psing;
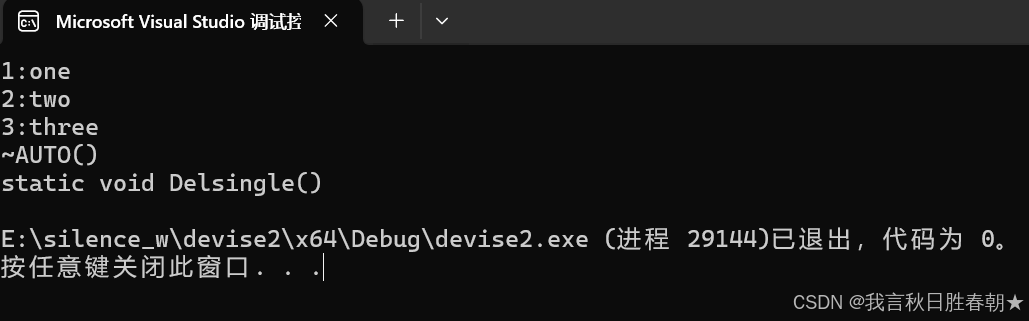
}这样就成功了,并且能够看到自动调用对应的释放指针函数了
cpp
int main()
{
lazy::single::Getsingle().Add({ "1","one" });
lazy::single::Getsingle().Add({ "2","two" });
lazy::single::Getsingle().Add({ "3","three" });
lazy::single::Getsingle().Print();
return 0;
}
优点:要用的时候才进行初始化,能够节省资源,延迟加载、资源利用高效、适应性强等
缺点:代码复杂度较高,需要处理同步
适用场景:
- 资源敏感型应用:如移动端APP、嵌入式系统,需严格控制内存和启动时间
- 条件化初始化:实例依赖运行时参数(如用户配置、环境状态)
- 模块化系统:避免因加载顺序导致的初始化问题
- 高开销对象:如数据库连接池、大型缓存对象
| 特性 | 懒汉模式 | 饿汉模式 |
|---|---|---|
| 初始化时机 | 首次请求时 | 类加载时 |
| 资源占用 | 按需占用,更节省 | 启动即占用,可能浪费 |
| 线程安全性 | 需额外处理(如锁、DCLP) | 天然线程安全(JVM/C++加载机制) |
| 代码复杂度 | 较高(需处理同步) | 极简 |
| 适用场景 | 高开销、非必需使用的单例 | 低开销、必需使用的单例 |
三、类型转换:
1、C语言中的类型转换:
C语言和C++都是强类型语言,也就是=两边如果不一样就必须进行类型的转换,在C语言中有两种转换的方式,显示类型转换 和隐式类型转换
- 隐式类型转换:编译器在编译阶段自动进行转化,能转化就转化,不能就编译报错,隐式类型转换只会发生在相近类型如int和double,或者是单参数的构造函数支持隐式类型的转换
- 显示类型转换:需要用户自定义进行处理
cpp
int main()
{
//隐式类型转换
int m = 2;
double n = m;//这里就发生了隐式类型的转换
cout << "m = " << m << endl;
cout << "n = " << n << endl;
//显示类型转换
int* p = &m;
int ptr = (int)p;
cout << "p = " << p << endl;
cout << "ptr = " << ptr << endl;
return 0;
}缺陷:
1、隐式类型转化有些情况下可能会出问题:比如数据精度丢失
2、显式类型转换将所有情况混合在一起,代码不够清晰
因此在C++中就增加了四种强制类型转换
2、C++中的四种类型转换:
static_cast:
用途:用于编译已知的,相近类型的,相对安全的类型转换,但是不能由于两个毫不相干的类型
- 基本数据类型转换,如int -> double
- 类层次中的向上转型(派生类指针/引用→基类指针/引用)
- 显式调用构造函数
特点:
- 不检查运行时类型,向下转型(基类→派生类)可能不安全
- 不能移除 const或volatile属性
cpp
int main()
{
double d = 12.34;
int a = static_cast<int>(d);
cout << a << endl;
int* p = &a;
// int address = static_cast<int>(p); //error
return 0;
}reinterpret_cat:
用途:用于两个不相关类型之间的转换,低层次的位模式重新解释(如指针→整数、无关类型指针互转),常见于系统编程、硬件操作或序列化
特点:
- **高度危险,**可能导致未定义行为
- 转换结果依赖具体平台,不可移植
cpp
int main()
{
int a = 10;
int* p = &a;
cout << p << endl;
int address = reinterpret_cast<int>(p);
cout << address << endl;
return 0;
}
const_cast:
用途:删除变量的const或者volatile属性,转换后就可以对const变量的值进行修改
特点:
- 不改变底层数据,但修改原始const对象可能导致未定义行为。
- 无法用于不同类型之间的转换
cpp
int main()
{
const int a = 10;
//如下是不可修改的
//const int* pa = &a;
//*pa = 20;
int* pa = const_cast<int*>(&a);
*pa = 20;
cout << "&a = " << &a << endl;
cout << "a = " << a << endl;
cout <<"a * 10 = " << a * 10 << endl;
cout << "pa = " << pa << endl;
cout << "*pa = " << *pa << endl;
return 0;
}这里需要注意的是不能够直接修改a,要通过指针来间接修改,代码中用const_cast删除了变量a的地址的const属性,这时就可以通过这个指针来修改变量a的值
cpp
a = const_cast<int>(a);//error
如下是实验结果:
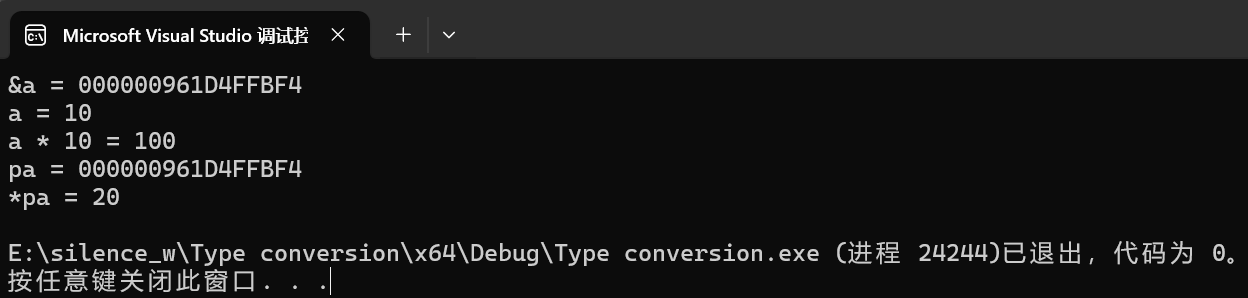
可以发现二者的值居然不一样,但是他们的地址却是一样的,这是为什么呢?
因为编译器默认是认为const的值是不能够被修改的,所以就会将被const修饰的变量放到寄存器中,在进行打印或使用的时候,就直接从寄存器中读取,使用寄存器中的值,当我们进行地址解引用修改的时候,修改的是内存中的值,因此通过地址打印出来的a是修改后的值
如果想让编译器每一次都在内存中读取,而不是在寄存器中读取,可以用volatile修饰对应的const变量,这样就是让编译器每次都在内存中读取,保持了该变量在内存中的可见性
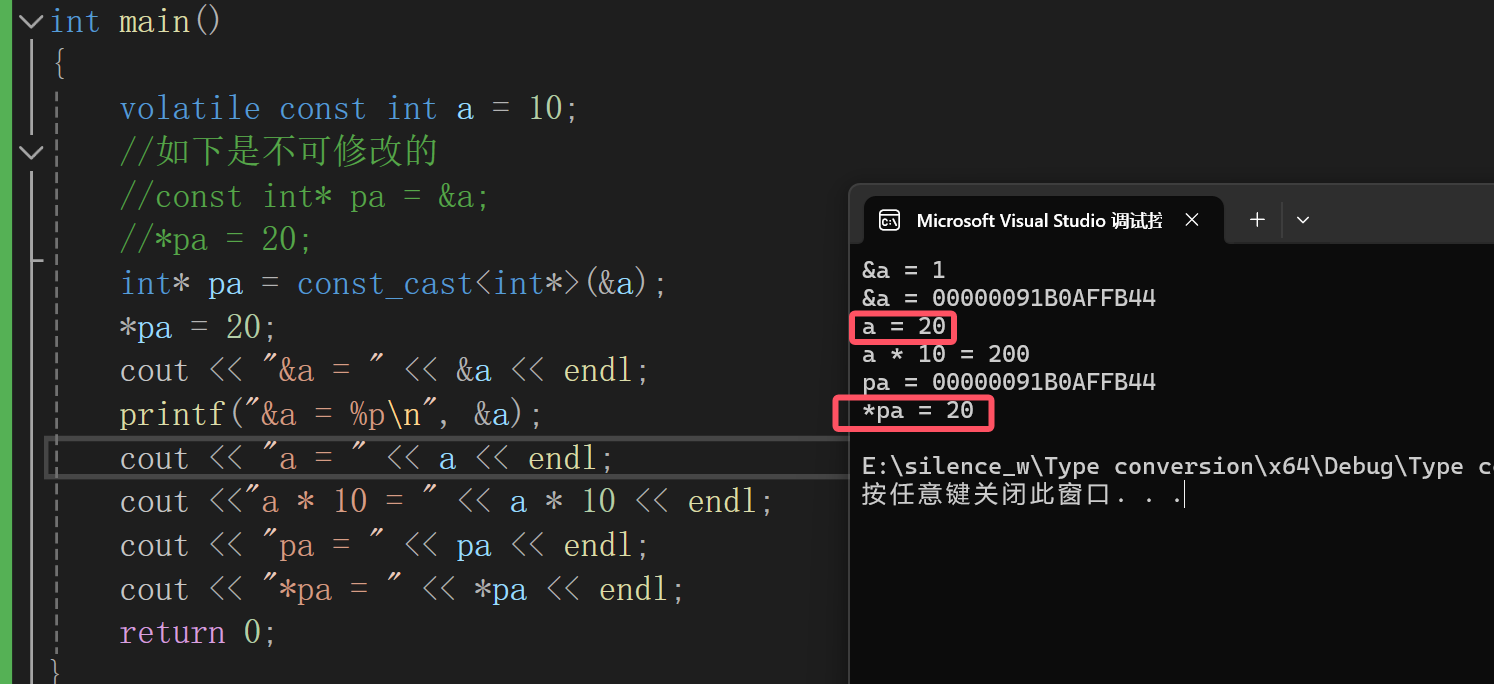
这样就能够从内存中读取了
但是上述我们发现了一个问题,第一行中&a=1,这又是为什么呢?
因为cout这里有一个坑,就是他是采取函数重载的方式匹配的,但是对于地址这种,匹配起来就有点模糊了,可能会匹配到类型是打印值的函数重载上去,简单说,就是将地址以类似于int这种值的方式打印了,所以一般情况下,都很少使用cout来输出地址这种信息的
dynamic_cast:
用途:将父类的指针(或引用)转换成子类的指针(或引用),用于多态类型(含虚函数)的安全向下转型,是一种专门用于多态类型安全转换 的操作符,主要解决向下转型(父类指针/引用→子类指针/引用)时的类型安全问题
dynamic_cast会先检查是否能转换成功,能成功则转换,不能则返回0
向上转型: 子类的指针(或引用)→ 父类的指针(或引用)
向下转型: 父类的指针(或引用)→ 子类的指针(或引用)
向下转型的安全性确实取决于 父类指针(或引用)实际指向的对象类型
1、父类指针实际指向的是父类对象,但尝试将其转换为子类指针
风险:
- 子类可能包含父类没有的成员
- 转换后的指针访问这些成员时,会操作无效内存,导致崩溃
2、父类指针实际指向的是子类对象,此时转换为子类指针是安全的
cpp
class A
{
virtual void func()
{}
};
class B : public A
{
public:
int data = 1;
};
int main()
{
A a;
A* APtr = &a; // 指向父类对象
B* BPtr = dynamic_cast<B*>(APtr); // 危险!这里转换失败,应该是空
printf("%p\n", BPtr);
B b;
A* aPtr = &b; // 指向子类对象
B* bPtr = dynamic_cast<B*>(aPtr); // 安全,转换成功
printf("%p\n", bPtr);
return 0;
}
explicit:
我们知道,单参数的构造函数支持隐式类型的转换,如果不想要这个发生,我们可以用explicit修饰构造函数进而禁止
cpp
class A
{
public:
A(int a)
:_a(a)
{}
int _a;
};
int main()
{
A a = 1;//这里发生了隐式类型的转换
return 0;
}
在早期的编译器中,A a = 1这是先构建一个临时对象,然后在进行拷贝赋值,在如今的编译器中,优化了,如果是单参数的,这样就是直接按照A a(1);这样的方式进行处理,这就是隐式类型的转换