之前文章:Mysql锁_exclusivelock for update写锁-CSDN博客 中有提到通过MVCC来实现快照读,从而解决幻读问题,这里详细介绍下MVCC。
一、前言
|----|---|
| id | k |
| 1 | 1 |
| 2 | 2 |
[表1:实例表t]
|--------------------------------------------|--------------------------------------------------------------|--------------------------------|
| 事务A | 事务B | 事务C |
| start transaction with consistent snaption | | |
| | start transaction with consistent snaption | |
| | | update t set k=k+1 where id =1 |
| | update t set k=k+1 where id =1; select k from t where id =1; | |
| select k from t where id =1; commit; | | |
| | commit | |
[表2:事务A、B、C的执行流程]
先看上面执行流程,先思考下事务A和B两次查询结果都是什么。
注:
1、begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作InnoDB表的语句(第一个快照读语句),事务才真正启动。这里使用start transaction with consistent snaption命令立即开始事务。
2、事务C没有使用命令开启事务,因为update语句本身就是一个事务,执行完毕后执行commit
二、MVCC 的核心思想
MVCC 的核心是通过 数据多版本 和 一致性视图(Consistent Read View) 来实现高并发下的读写隔离。其核心思想是:
-
每个数据行有多个版本,每次更新生成新版本,旧版本通过 undo log 保留。
-
事务根据可见性规则判断应读取哪个版本,而非直接读取最新数据。
1. 事务ID与行版本
-
事务ID(Transaction ID) :每个事务启动时,InnoDB会为其分配一个全局唯一且递增的ID(
trx_id)。 -
行数据的版本 :每次事务修改数据时,会生成一个新的数据版本,并将事务ID记录在该版本的
row trx_id字段中。旧版本的数据通过 Undo Log 保存,形成版本链。
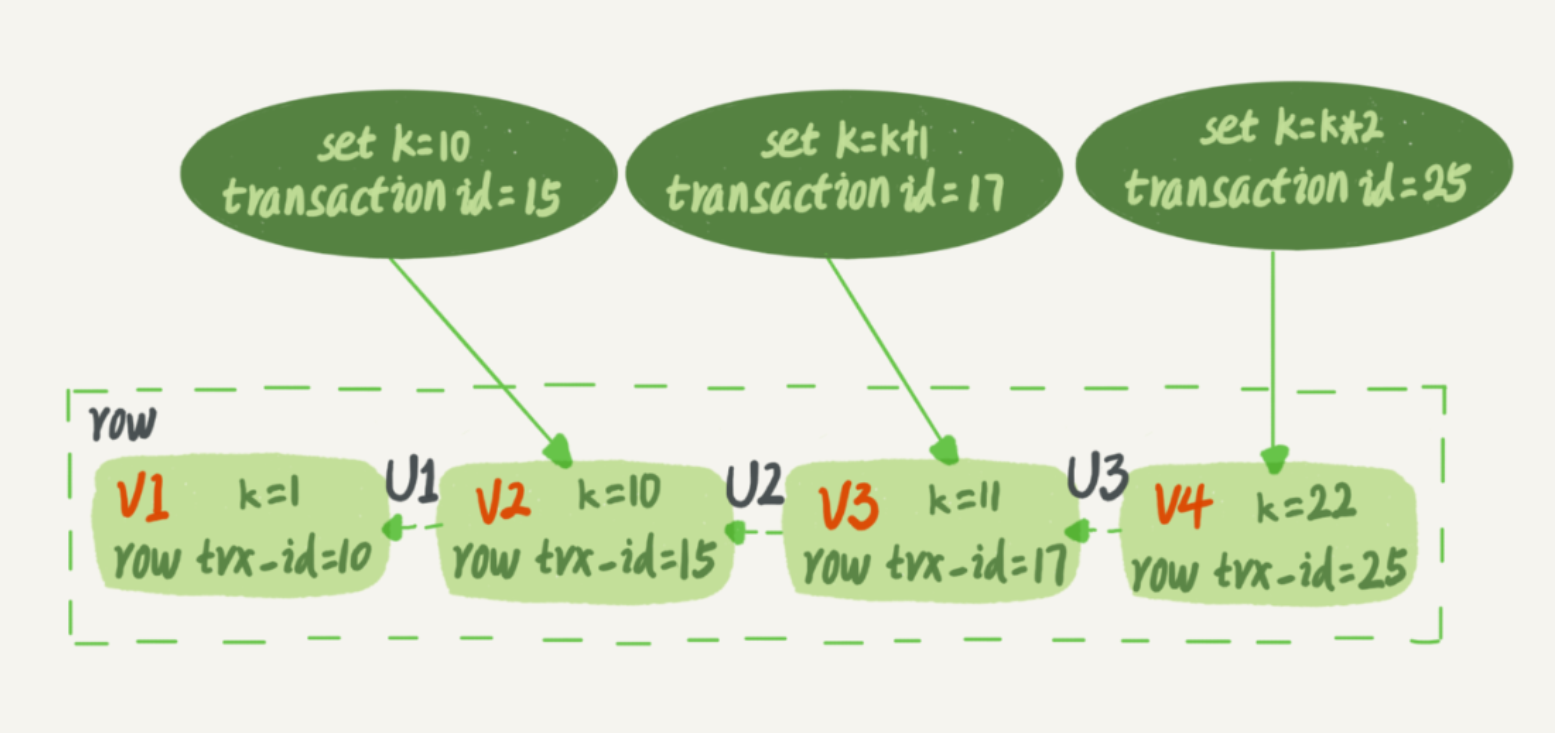
图1:行状态变更图
上图就是一个记录被多个事务连续更新后的状态。图中虚线框里是同一行数据的4个版本,当前最新版本是V4,k的值是22,它是被transaction id 为25的事务更新的,因此它的row trx_id也是25。U1,U2,U3则是undo log的记录的日志。
2. 一致性读视图(Consistent Read View)
事务启动时(RR 级别)或语句执行时(RC 级别),InnoDB 会生成一个 一致性视图,用于判断数据版本的可见性。
Read View 的四大核心属性
- trx_ids(活跃事务 ID 集合)
- 含义:生成 Read View 时,当前系统中所有未提交的活跃事务 ID 的集合。
- 作用:用于判断数据版本的事务是否在 Read View 生成时处于活跃状态。若在集合中,则该版本对当前事务不可见(除了自身事务,自身事务对于表的修改对于自己当然是可见的)。
- up_limit_id(最小活跃事务 ID)
- 含义 :trx_ids集合中的最小事务 ID。
- 作用:若数据版本的事务 ID < low_trx_id → 该版本在 Read View 生成前已提交,可见。
- low_limit_id(最大事务 ID 上限)
- 含义:生成 Read View 时,系统中尚未分配的下一个事务 ID(并非实际存在的事务 ID)。
- 作用:若数据版本的事务 ID ≥ up_trx_id → 该版本在 Read View 生成后才被创建,不可见。
- creator_trx_id(当前事务 ID)
- 含义:生成该 Read View 的当前事务 ID。
- 作用:若数据版本的事务 ID == creator_trx_id → 当前事务自己修改的数据,可见。
数据可见性判断规则
当事务读取一行数据时,需根据以下条件判断版本是否可见:
- 版本事务 ID < up_limit_id → 可见(已提交且早于 Read View 生成)。
- 版本事务 ID >= low_limit_id → 不可见(生成时间晚于 Read View)。
- 版本事务 ID 在 [up_limit_id, low_limit_id) 区间内 :
- 若在 trx_ids中 → 不可见(活跃未提交)。
- 若不在 trx_ids中 → 可见(已提交且在 Read View 生成后提交)。
- 版本事务 ID == creator_trx_id → 可见(当前事务自己修改的)。
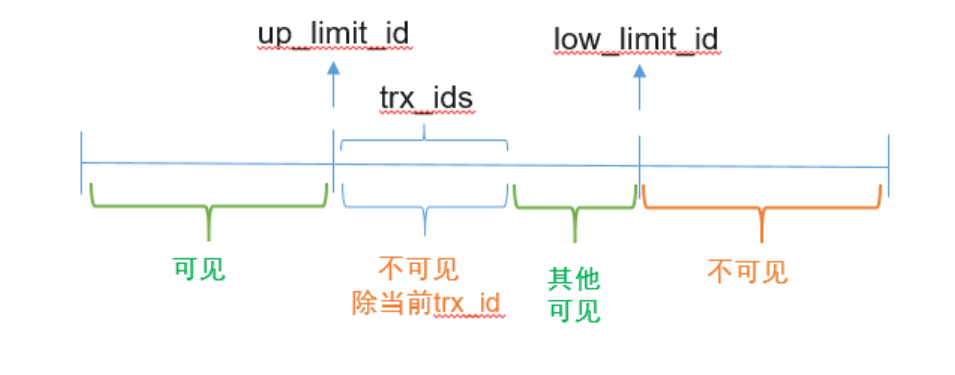
注意:一旦一个Read View被创建,这三个参数将不再发生变化,其中low_limit_id 和 up_limit_id分别是 trx_Ids数组的上下界(注意:从单词上来区分的话很容易弄反)。
三、MVCC 如何实现隔离级别
1. 可重复读(RR)
-
视图创建时机:事务启动时创建一致性视图,后续所有读操作基于此视图。
-
效果:事务内看到的数据始终一致,不受其他事务提交的影响。
示例分析:
如上面表格2中:
假设事务开始前,当前活跃事务id=99,则事务A、B、C的事务id依次是100、101、102,事务开始前id=1 k=1的这一行数据的row trx_ids是90。(版本V1)
那么,我们看下在 RR 隔离级别下执行过程:
视图建立时,事务A的trx_ids=99,100,同样事务B的trx_ids=99,100,101、事务C的trx_ids=99,100,101,102。先执行事务C的update,当前版本从V1(k=1)变成V2(k=2),V1则变为历史版本,执行事务B的update,历史版本从V2(k=2)变成V3(k=3),V2变成历史版本。
这里为啥执行事务B,从k=2变成3,不是事务隔离吗?这个我们在后面解释。
事务B执行查询操作时:
trx_ids: 99,100,101
up_limit_id: 99
low_limit_id: 102
creator_trx_id=101,先查看V3版本,事务id=101在trx_ids中,但是等于我们当前事务,所以可见,所以最后结果k=3
事务A执行查询操作时:
trx_ids: 99,100
up_limit_id: 99
low_limit_id: 101
creator_trx_id=100,先查看V3版本,事务id=101 >= low_limit_id 不可见,然后查找V2版本,事务id=102 >= low_limit_id,不可见,在查找V1版本,事务id=90,不在trx_ids中,可见。所有我们通过undo log,从V3 -> V2 -> V1,我们获取数据,最后结果k=1
这样执行下来,虽然期间这一行数据被修改过,但是事务A不论在什么时候查询,看到这行数据的结果都是一致的,所以我们称之为一致性读。
2. 读提交(RC)
-
视图创建时机:每条语句执行前重新生成一致性视图。
-
效果:每次查询能看到已提交的最新数据。
示例分析
表2中的"start transaction with consistent snapshot; "的意思是从这个语句开始,创建一个持续整个事务的一致性快照。所以,在读提交隔离级别下,这个用法就没意义了,等效于普通的start transaction。
在 RC 隔离级别下:
事务B的查询结果和RR一致。
-
事务 C 已提交(ID=102),不在活跃事务数组中。
-
事务 B 未提交(ID=101),仍在活跃事务数组中。
-
事务 A 执行查询时:
-
trx_ids:
[101](仅事务 B 未提交)。 -
up_limit_id:101(活跃事务最小 ID)。
-
low_limit_id:103(当前最大事务 ID=102,+1 后为 103)。
数据可见性判断:
-
若数据的最新版本由事务 B(ID=101)更新:
-
row trx_id=101在活跃数组中,不可见。 -
继续查找历史版本,找到事务 C(ID=102)提交的版本:
row trx_id=102 < 高水位(103),且不在活跃数组中,可见。
-
-
因此,事务 A 的第一次查询会读到事务 C 提交后的数据,即k=2。
-
如果事务B提交后,事务A再执行一次查询呢?
事务 B 提交后
-
事务 B 提交后,ID=101 不再属于活跃事务。
-
事务 A 执行第二次查询:
-
活跃事务数组 :
[](无未提交事务)。 -
低水位:无(数组为空)。
-
高水位:103(最大事务 ID 仍为 102,+1 后为 103)。
数据可见性判断:
-
数据的最新版本由事务 B(ID=101)提交:
row trx_id=101 < 高水位(103),且不在活跃数组中,可见。
-
因此,事务 A 的第二次查询会读到事务 B 提交后的数据。
-
四、当前读与一致性读
MVCC 的读操作分为两种模式:
-
一致性读(Consistent Read) :基于视图读取历史版本,用于普通
SELECT。 -
当前读(Current Read) :读取最新数据并加锁,用于更新操作(如
UPDATE、SELECT ... FOR UPDATE)。
为什么更新需要当前读?
假设事务 B 要更新数据:
-
若使用一致性读,可能基于旧版本数据计算新值,导致其他事务的更新丢失。
-
因此,更新操作必须读取最新版本(当前读),并对记录加锁,确保数据一致性。
所以这里可以解释,为什么事务B执行update操作k是从2变成3,读到了事务C提交的数据,因为在更新的时候,当前读拿到的数据是(k=2),更新后生成了新版本的数据(k=3),这个新版本的row trx_id是101。所以,在执行事务B查询语句的时候,一看自己的版本号是101,最新数据的版本号也是101,是自己的更新,可以直接使用,所以查询得到的k的值是3。
五、案例分析
除了文章开始案例,我们这里再列举几个案例分析下。
案例1
|--------------------------------------------|--------------------------------------------------------------|-----------------------------------------------------------------------------|
| 事务A | 事务B | 事务C |
| start transaction with consistent snaption | | |
| | start transaction with consistent snaption | |
| | | start transaction with consistent snaption; update t set k=k+1 where id =1; |
| | update t set k=k+1 where id =1; select k from t where id =1; | |
| select k from t where id =1; commit; | | commit |
| | commit | |
我们看上面实例,跟前面分析相比,事务C执行update操作后并没有立即提交,那么如何执行呢。
这里我们需要介绍二阶段协议:
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
执行流程:
-
事务C启动:
-
更新
id=1的行,将k从1改为2,但未提交(持有行锁)。 -
此时数据版本链为:
V1(row trx_id=90, k=1)→V2(row trx_id=102, k=2)(未提交)。
-
-
事务B启动:
-
尝试执行
UPDATE t SET k=k+1 WHERE id=1,需要获取行锁。 -
因事务C未提交,事务B被阻塞,进入锁等待状态。
-
-
事务A启动(RR隔离级别):
-
执行
SELECT k FROM t WHERE id=1。 -
根据一致性视图规则,事务A的视图数组包含启动时活跃事务(如事务C的ID=102)。
-
数据版本链中,
V2的row trx_id=102在活跃事务数组中,不可见;最终读取V1(k=1)。
-
-
事务C提交:
-
提交后释放行锁,数据版本
V2的row trx_id=102变为已提交。 -
事务B获得锁,执行当前读,读取最新版本
V2(k=2),更新为k=3,生成新版本V3(row trx_id=101)。
-
-
事务A再次查询:
- 仍基于启动时的视图,不可见事务B和C'的提交,结果仍为
k=1。
- 仍基于启动时的视图,不可见事务B和C'的提交,结果仍为
-
事务B提交:
-
提交后数据版本
V3的row trx_id=101变为已提交。 -
新事务查询会看到
k=3。
-
注意:上面没有死锁风险,因为只有事务C和事务B在竞争同一行的锁,且是单向等待(事务B等待事务C释放锁),无循环依赖,因此不会死锁。
案例2
|--------------------------------------------|--------------------------------------------|-----------------------------------------------------------------------------|
| 事务A | 事务B | 事务C |
| start transaction with consistent snaption | | |
| | start transaction with consistent snaption | |
| | | start transaction with consistent snaption; update t set k=k+1 where id =1; |
| | update t set k=k+1 where id =2; | |
| select k from t where id =1; commit; | | update t set k=k+1 where id =2; |
| | update t set k=k+1 where id =1; | |
| | commit | commit |
如果出现上面场景呢?
执行流程
-
事务C:更新行id=1 → 持有行1的锁。
-
事务B:更新行id=2 → 持有行2的锁。
-
事务C:尝试更新行2 → 等待事务B释放行2的锁。
-
事务B:尝试更新行1 → 等待事务C释放行1的锁。
此时,事务B和事务C互相等待对方释放资源,形成循环依赖,触发死锁。
死锁相关分析可以参考:Mysql死锁_mysql 死锁的条件-CSDN博客
案例3
|-------------------------------------------------|--------------------|
| 事务A | 事务B |
| begin | |
| select k from t | |
| | update t set k=k+1 |
| update t set k=0 where id = k; select k from t; | |
上面运行结果:数据库会拒绝事务A的修改(如报错或阻塞),"数据无法修改"。
六、MVCC 的优缺点
优点
-
高并发:读写不互相阻塞,读操作无需加锁。
-
避免脏读和不可重复读:通过版本链和可见性规则实现隔离。
缺点
-
存储开销:需保留多个数据版本和 undo log。
-
长事务问题:长事务可能导致大量历史版本无法清理,占用存储空间。
六、实际应用建议
-
避免长事务 :监控
information_schema.innodb_trx,及时终止长时间未提交的事务。 -
优先使用 RC 隔离级别:若业务允许,RC 比 RR 更节省资源。
-
更新前显式加锁 :如需确保数据一致性,使用
SELECT ... FOR UPDATE明确加锁。