F004 新闻可视化系统 flask + mysql架构
文章结尾部分有CSDN官方提供的学长 联系方式名片
博主开发经验15年,全栈工程师,专业搞定大模型、知识图谱、算法和可视化项目和比赛
关注B站,有好处!
编号:F004
视频
python+flask新闻爬虫可视化系统
✅ 可以根据观察者网站来 获取数据
✅ 爬虫: Requests + etree + Xpah
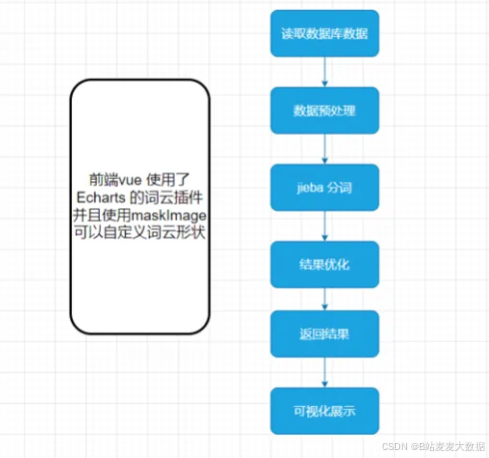
✅ 可视化: Flask + Echarts + WordCloud
✅ 文本分析:jieba分词
✅ 数据库: MySQL
系统设计
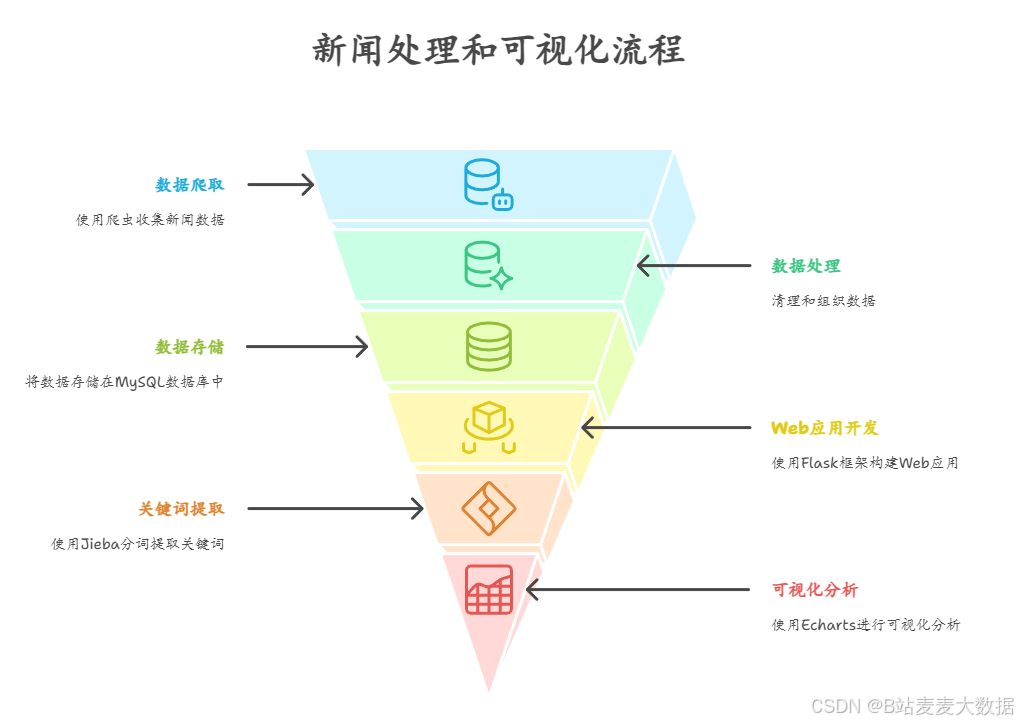
系统介绍
系统目标:实现对观察者网新闻的自动化抓取、结构化存储、智能搜索及多维度可视化分析,为时事研究提供数据支持。
代码目录:
核心功能模块
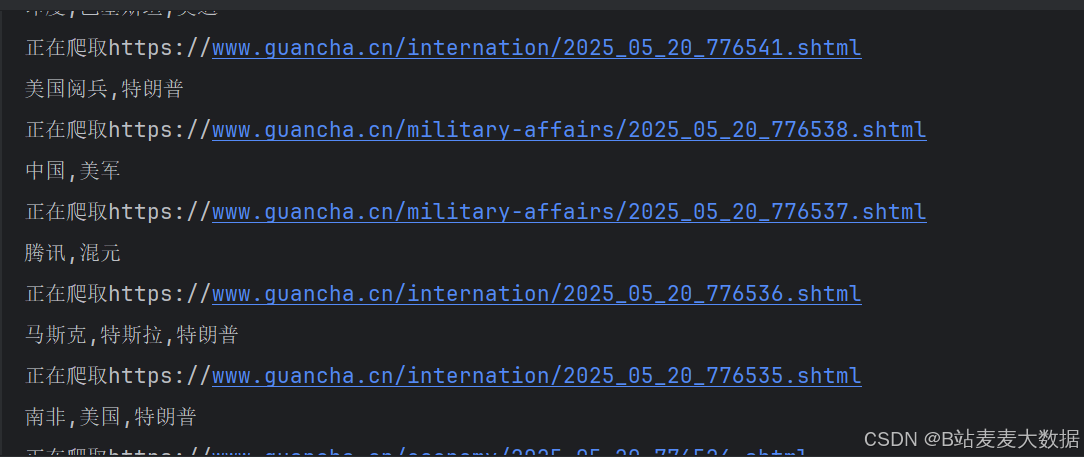
- 数据爬取引擎
来源:定向爬取观察者网全站新闻(含首页/分类/专题)
技术栈:
Requests 模拟HTTP请求(处理反爬策略)
lxml.etree + XPath 精准解析HTML(标题/正文/作者/发布时间/标签)
输出:结构化元数据+原始HTML存档
- 文本处理流水线
分词与清洗:
jieba分词 实现中文语义切分(支持自定义词典)
停用词过滤 + 关键词提取(TF-IDF算法)
数据增强:自动生成新闻摘要 & 情感倾向评分 - 数据库管理
架构:MySQL关系型数据库(5表结构)
新闻主表(url, title, publish_time, author)
内容表(正文+分词结果)
热词统计表(动态更新)
操作:
增量更新(基于时间戳去重)
索引优化(加速标题/内容检索) - 搜索与展示系统
新闻列表:
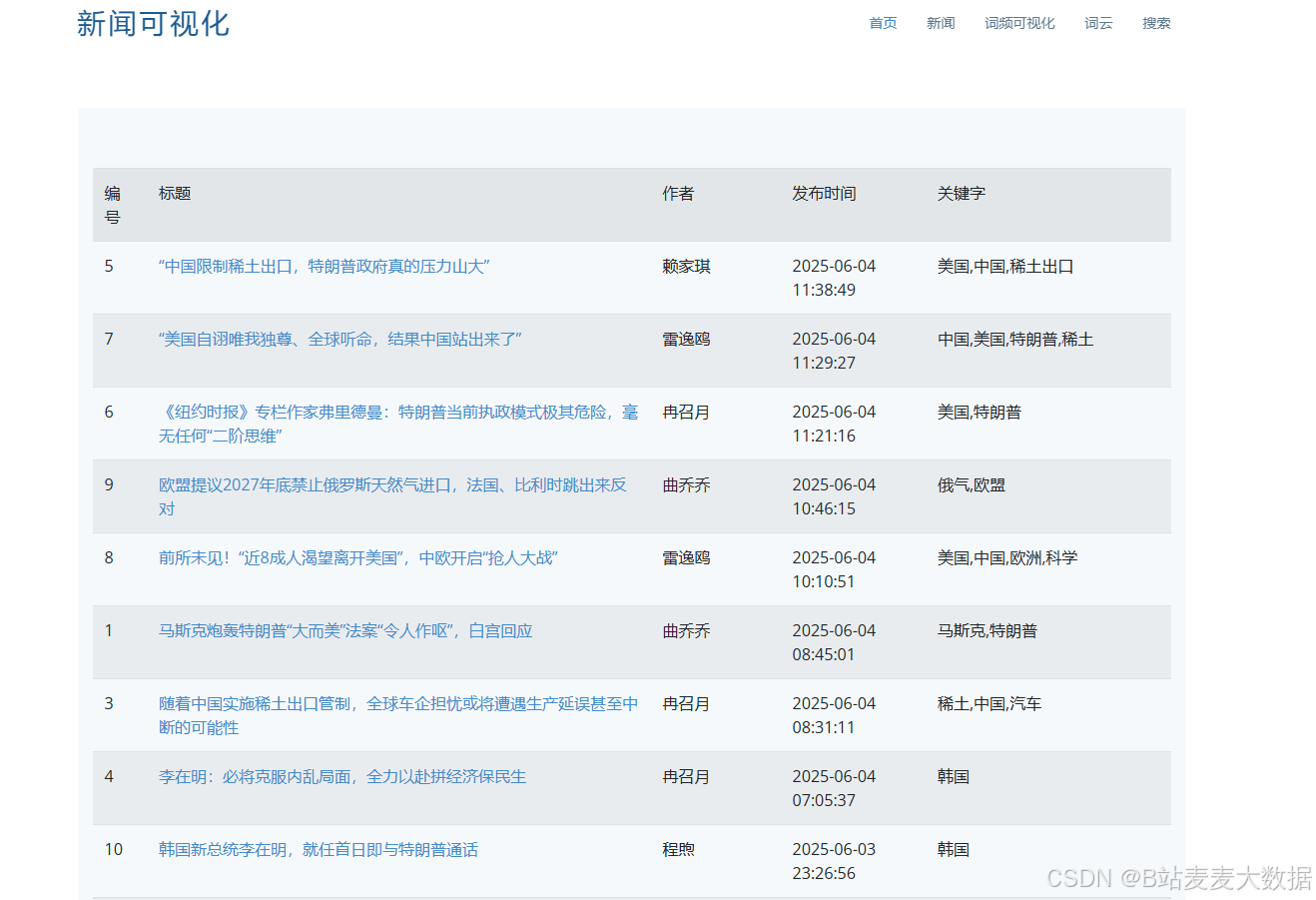
新闻搜索结果:
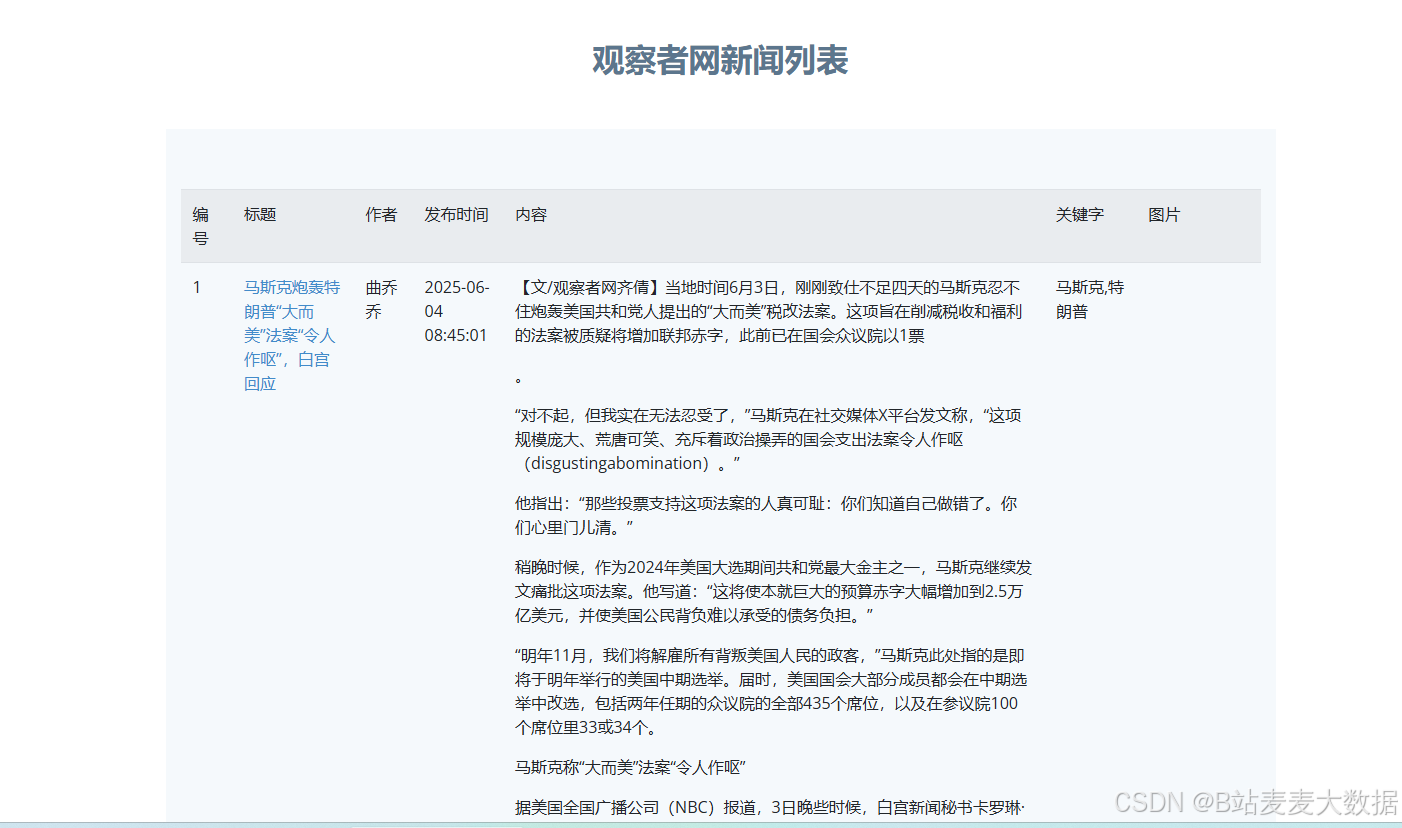
全文搜索:
支持关键词布尔检索(SQL LIKE + 分词匹配)
结果高亮显示
- 可视化中心
交互式图表(Flask + Echarts):
关键词分析
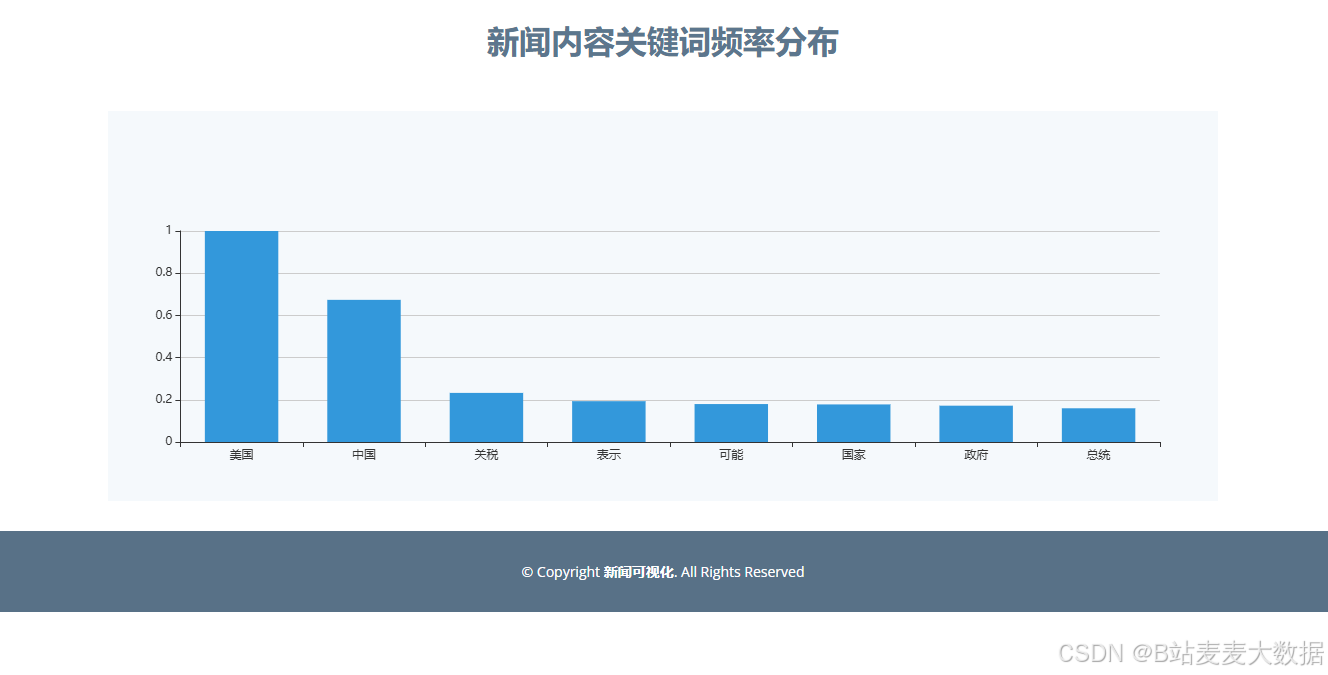
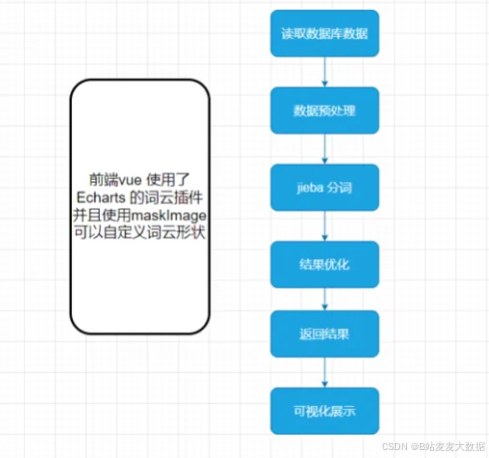
词云生成器(WordCloud动态渲染):
全局高频词云
单篇新闻关键词聚焦
支持自定义配色/形状模板

python
# 连接数据库并提取数据库内容
def get_datalist():
datalist = []
cnn = pymysql.connect(host=HOST, user=USER, password=PASSWORD, port=PORT, database=DATABASE,
charset=CHAREST)
cursor = cnn.cursor()
sql = ' select * from guanchazhe ORDER BY publish_time DESC'
cursor.execute(sql)
for item in cursor.fetchall():
datalist.append(item)
cursor.close()
cnn.close()
return datalist
# 对数据库文本内容进行分词,并返回 data_inf0 = [新闻数,词云数,词汇数,作者人数] ->首页展示的三个内容
def get_datalist_info(datalist):
text = ""
for item in datalist:
text = text + item[4]
# 分词
cut = jieba.cut(text)
string = ' '.join(cut)
data_info = [len(datalist), 1, len(string), 1]
return data_info,string
# 对输入文本进行分词,并返回词汇权重
def get_word_weights(string, topK):
words = []
weights = []
for x, w in jieba.analyse.textrank(string, withWeight=True, topK=topK):
words.append(x)
weights.append(w)
return words,weights
# 文本关键字提取
def get_keyword_from_content(content):
print(content)
cut = jieba.cut(content)
string = ' '.join(cut)
words,_=get_word_weights(string, topK=5)
return words.append('(自动生成)')