Streamlit+LLM+RAG 测试智能体平台
项目简介
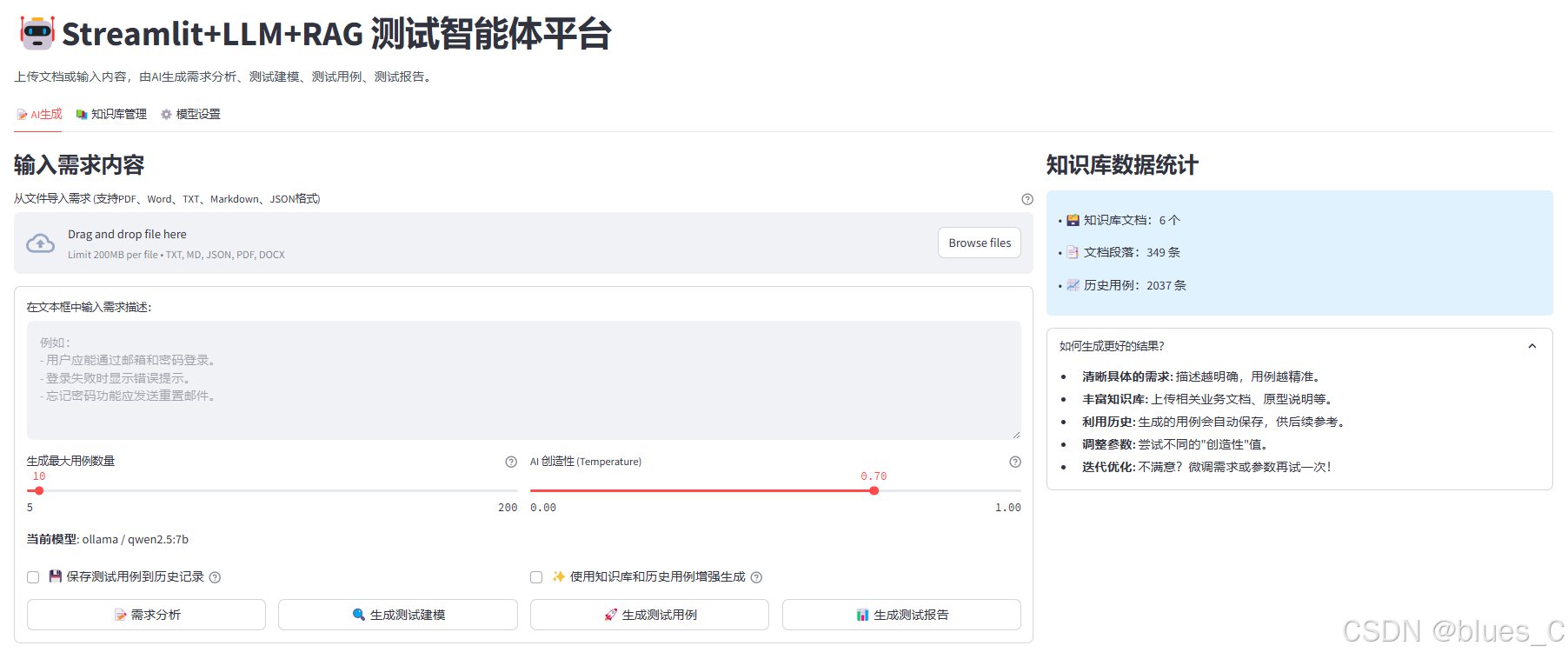
本项目是一个基于 Streamlit 构建的交互式 Web 应用,利用大语言模型 (LLM) 和检索增强生成 (RAG) 技术,辅助完成各种软件测试任务。用户可以输入需求描述,选择性地通过知识库和历史数据增强上下文,从而生成 需求规格说明书 、测试用例 、测试建模文档 、和 测试报告 。
✨ 主要功能
-
📝 AI 生成任务:
- 需求分析: 基于提供的需求描述,生成软件需求规格说明书 (SRS)。
- 测试分析 (建模): 创建详细的测试建模文档。
- 测试用例生成: 从需求描述自动生成结构化的测试用例。
- 测试报告生成: 根据输入信息生成专业的测试报告。

-
🔍 检索增强生成 (RAG):
- 知识库集成: 支持上传文档来构建知识库。系统会自动解析和切分这些文档。
- 上下文增强: 从知识库和相似的历史数据中检索相关片段,为 LLM 提供更丰富的上下文,从而提高生成内容的质量和相关性。

-
🧠 灵活的 LLM 集成:
- 支持多种 LLM 服务提供商:Ollama、OpenAI 以及自定义 API 端点。
- 允许从多种预定义模型中选择,或指定自定义模型名称。
- 可通过 UI 配置 API 端点和 API 密钥。
-
📊 用户界面与输出:
- 交互式 UI: 使用 Streamlit 构建,包含 AI 生成、知识库管理和模型设置等标签页。
- 多种输出视图: 以表格、JSON 和 Markdown 格式显示生成的测试用例。
- 导出功能: 允许将生成的需求规格说明书、测试建模文档、测试用例和测试报告下载为 Markdown 文件。
- 知识库查看器: 浏览已上传的文档及其提取的片段。
- 统计信息: 显示知识片段数量和历史测试用例数量等基本统计数据。
🚀 安装指南
前置条件
- Python 3.8+
- Ollama (推荐用于本地模型,如果使用默认设置,请先安装并运行)
- Git
步骤
-
克隆仓库:
bashgit clone <your-repository-url> (项目源码可联系我获取) cd <repository-folder-name> -
创建并激活虚拟环境:
bash# Windows python -m venv venv .\venv\Scripts\activate # Linux/macOS python -m venv venv source venv/bin/activate -
安装依赖:
bashpip install -r requirements.txt提示: 如果在国内遇到网络问题,可以尝试使用镜像源:
bashpip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
💡 使用方法
-
确保您选择的 LLM 服务正在运行:
- 如果使用 Ollama (默认),请确保 Ollama 应用程序正在运行。
- 如果使用 OpenAI 或自定义 API,请确保您拥有正确的 API 端点和凭据。
-
运行 Streamlit 应用:
bashstreamlit run rag_test_agent.py -
与应用交互:
- 📝 AI 生成标签页:
-
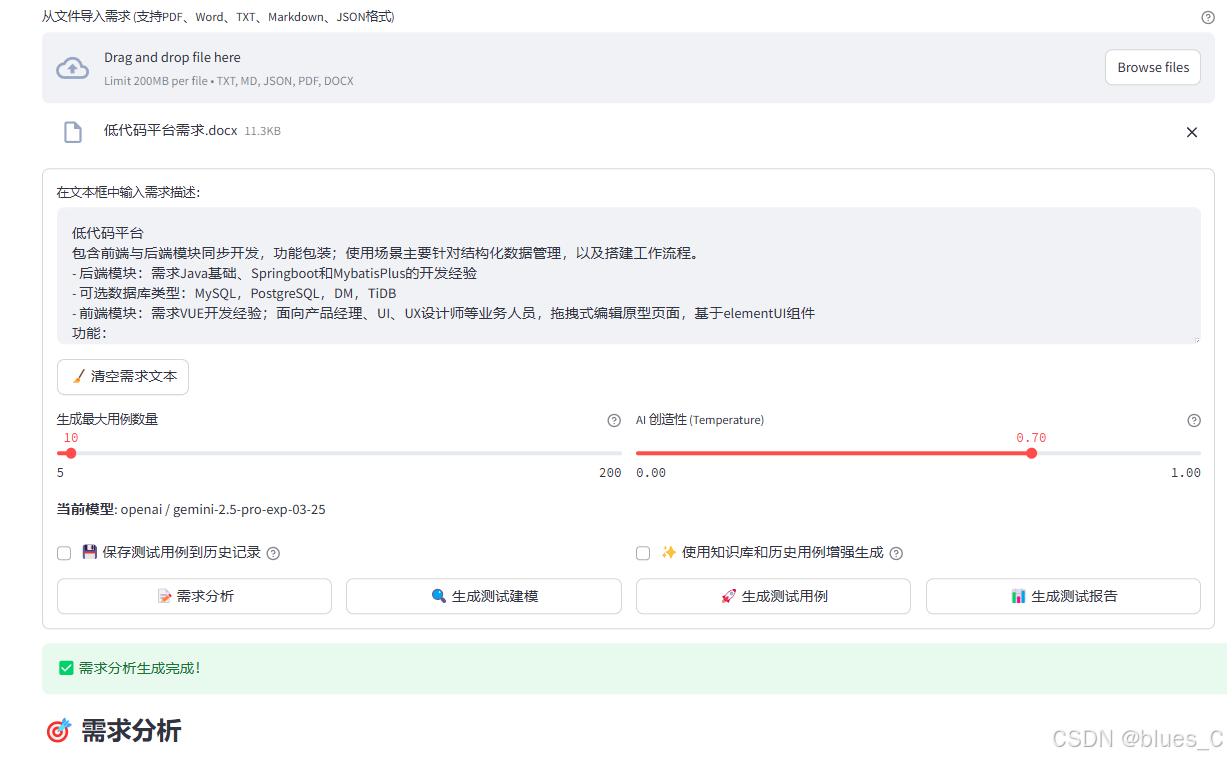
输入或通过文件上传导入需求描述。
-
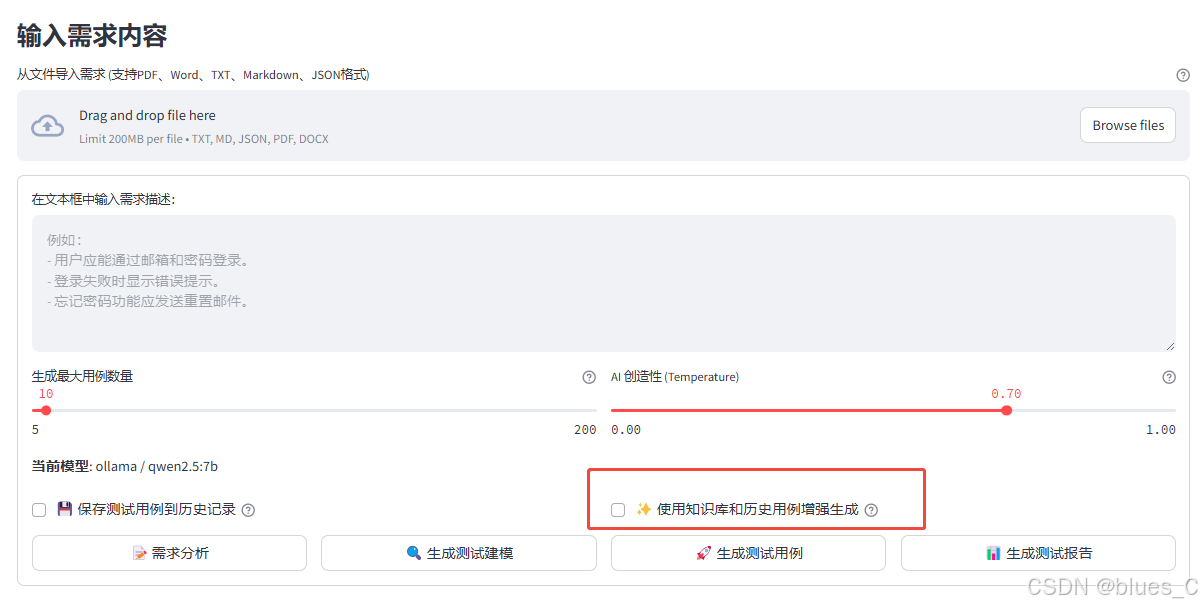
可选择勾选 "使用知识库和历史用例" 复选框以启用 RAG 来增强生成效果 (影响测试用例、测试分析、需求分析和测试报告的生成)。
-
调整生成参数,如最大用例数和温度 (创造性)。
-
点击相应的按钮:"需求分析"、"生成测试建模"、"生成测试用例" 或 "生成测试报告"。
-
查看并导出结果。
-
需求分析(部分示例):


-
测试建模(部分示例):
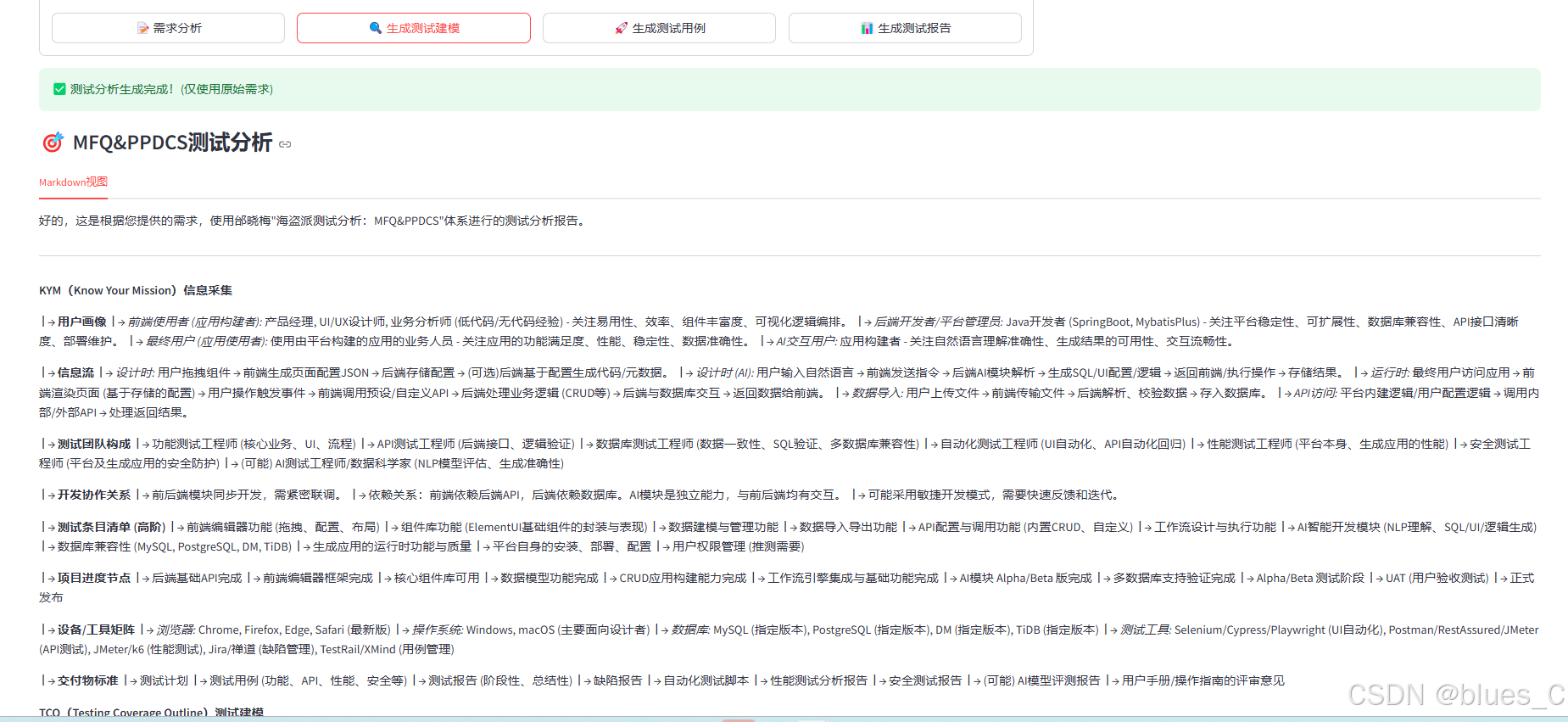
-
测试用例(部分示例):
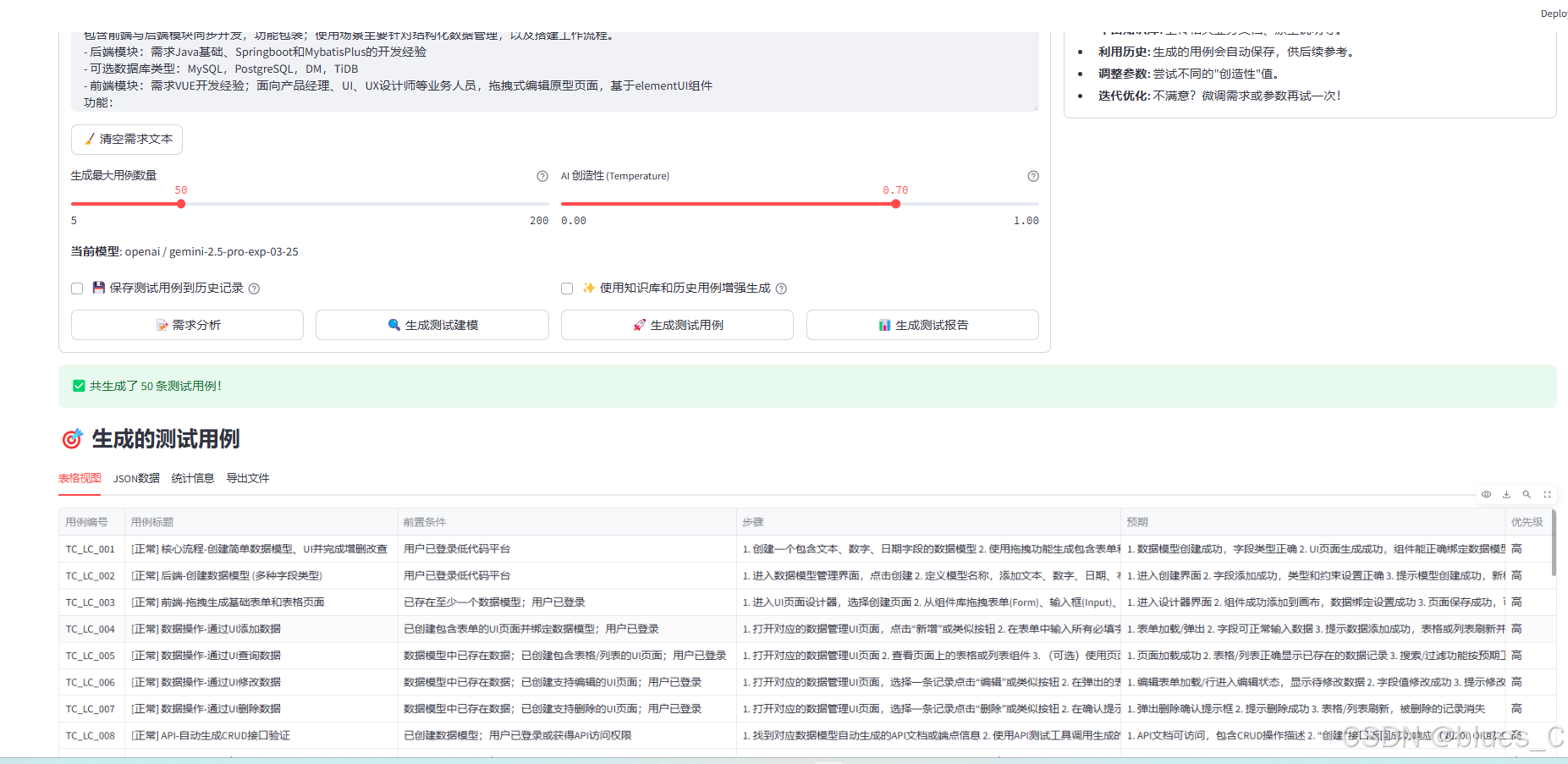
-
测试报告(部分示例):



-
- 📝 AI 生成标签页:
- 📚 知识库管理标签页: 上传相关文档 (PDF, DOCX, TXT, MD, JSON) 来构建您的知识库。可以查看已存在的知识片段。
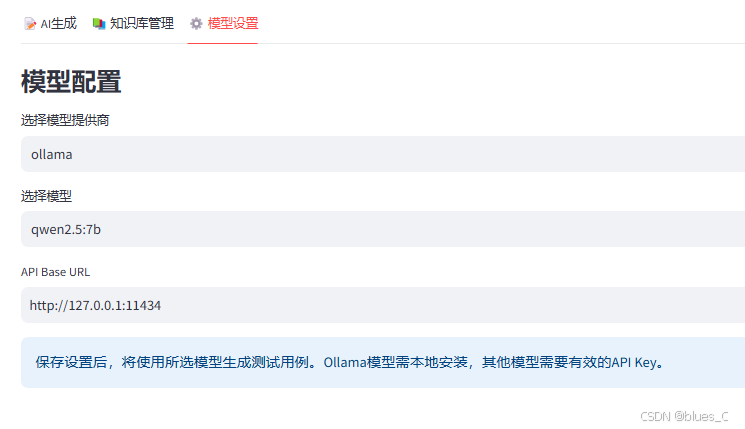
- ⚙️ 模型设置标签页: 配置您想要的 LLM 提供商、模型名称、API 基础 URL 和 API 密钥 (如果需要)。默认使用 Ollama 的
qwen2.5:7b模型,地址为http://127.0.0.1:11434。
💾 数据存储
- 存储历史需求描述及其对应的生成测试用例。用于测试用例生成时的 RAG。
- 存储从知识库上传文档中提取的文本片段。包含文档名称和来源页码 (针对 PDF)。用于所有生成任务的 RAG。
temp: 用于处理上传文件的临时目录。处理完毕后,此目录下的文件会被删除。
⚙️ 配置
所有的 LLM 配置都通过 UI 中的 "模型设置" 标签页进行管理:
- 模型提供商 (Model Provider): 在
ollama,openai, 或custom之间选择。 - 模型名称 (Model Name): 从列表中选择一个模型 (根据提供商而定) 或输入自定义名称。
- API 基础 URL (API Base URL): LLM API 的端点地址。为 Ollama 和 OpenAI 提供了默认值。
- API 密钥 (API Key): OpenAI 和 自定义 API 需要此项。