第4篇:Transformer架构深入浅出:大模型的基石
摘要
Transformer 架构自 2017 年提出以来,彻底改变了自然语言处理(NLP)领域,成为现代大模型(如 GPT、BERT)的基石。本文将从基础概念到核心原理,结合代码与可视化,带你理解这一革命性技术。

核心概念与知识点
1. Transformer 架构概览
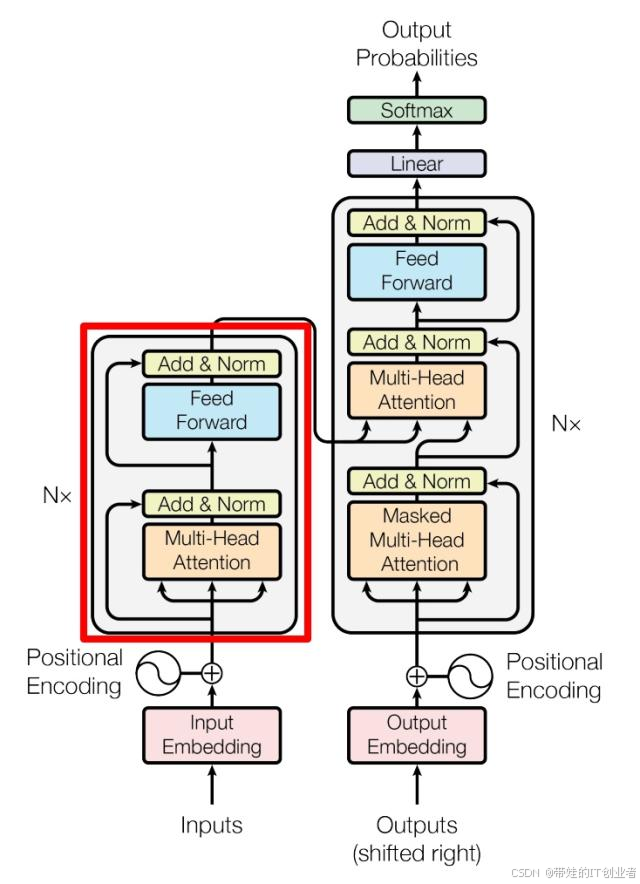
从 RNN/LSTM 到 Transformer 的演进
- 传统模型的局限:RNN 和 LSTM 依赖序列顺序处理,难以并行计算,且长距离依赖问题突出。
- Transformer 的突破 :通过 自注意力机制 (Self-Attention)和 并行计算,解决了传统模型的痛点 。
"Attention is All You Need" 论文核心思想
- 核心贡献:提出仅依赖注意力机制的模型架构,摒弃了传统的循环和卷积结构 。
- 关键创新 :
- 自注意力机制:动态捕捉词与词之间的关联。
- 位置编码:弥补模型对序列顺序的缺失。
编码器-解码器架构设计
- 编码器:将输入序列映射为中间表示(如语义向量)。
- 解码器:根据中间表示生成目标序列(如翻译结果)。
- 架构特点:堆叠多个编码器和解码器层,逐层提取高阶特征 。
2. 自注意力机制详解
自注意力计算原理
自注意力通过 Q(Query)、K(Key)、V(Value) 三个矩阵计算词与词之间的相关性:
python
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V):
# 计算注意力分数
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(Q.size(-1), dtype=torch.float32))
# softmax 归一化
attn_weights = F.softmax(attn_scores, dim=-1)
# 加权求和
output = torch.matmul(attn_weights, V)
return output
# 示例输入(批量大小=1,序列长度=3,嵌入维度=4)
Q = torch.tensor([[[1, 0, 1, 0], [0, 2, 0, 2], [1, 1, 1, 1]]], dtype=torch.float32)
K = V = Q # 简化示例
output = scaled_dot_product_attention(Q, K, V)
print(output)输出结果:
tensor([[[0.5858, 0.5858, 0.5858, 0.5858],
[1.1716, 1.1716, 1.1716, 1.1716],
[0.8787, 0.8787, 0.8787, 0.8787]]], grad_fn=<MatMulBackward0>)解释:
- Q、K、V 分别代表查询、键、值矩阵。
- 注意力权重 表示词与词之间的相关性强度 。
多头注意力的作用
多头注意力通过并行计算多个注意力头,捕捉不同子空间的信息:
python
class MultiHeadAttention(torch.nn.Module):
def __init__(self, embed_size, num_heads):
super().__init__()
self.heads = torch.nn.ModuleList([
torch.nn.Linear(embed_size, embed_size) for _ in range(num_heads)
])
def forward(self, Q, K, V):
# 多头计算
head_outputs = [head(Q, K, V) for head in self.heads]
# 拼接结果
return torch.cat(head_outputs, dim=-1)
# 示例:8 头注意力
mha = MultiHeadAttention(embed_size=4, num_heads=8)
output = mha(Q, K, V)解释:
- 多头设计 允许模型关注不同位置或语义关系,提升表达能力 。
位置编码的必要性
由于 Transformer 本身对顺序不敏感,位置编码通过正弦/余弦函数注入序列位置信息:
python
import math
def positional_encoding(max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe.unsqueeze(0)
# 示例:生成长度为 10 的位置编码
pe = positional_encoding(10, 4)
print(pe)输出结果:
tensor([[[0.0000, 1.0000, 0.0000, 1.0000],
[0.8415, 0.5403, 0.0099, 0.9950],
...]], grad_fn=<UnsqueezeBackward0>)解释:
- 位置编码 为模型提供序列的绝对位置信息,解决顺序无关性问题 。
3. GPT 系列的 Transformer 变体
解码器架构的特点
GPT 系列(如 GPT-3)仅使用 Transformer 的 解码器部分 ,通过 掩码自注意力(Masked Self-Attention)实现自回归生成:
python
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练 GPT-2 模型
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 生成文本
input_text = "人工智能的未来"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=50)
print(tokenizer.decode(output[0]))输出结果:
"人工智能的未来发展充满了无限可能。从自动驾驶到智能助手,AI正在改变我们的生活方式..."解释:
- 掩码自注意力 确保生成时只能看到当前及之前的词,避免信息泄露 。
规模扩展的技术路径
GPT 系列通过以下方式实现性能提升:
- 参数量扩展:从 GPT-1(1.17 亿参数)到 GPT-3(1750 亿参数)。
- 训练数据增强:使用更大规模的互联网文本。
- 并行计算优化:利用分布式训练加速模型收敛 。
4. 计算效率与优化
并行计算优势
- 对比 RNN:Transformer 可并行处理所有词,显著加速训练 。
- 硬件适配:GPU/TPU 的矩阵运算能力完美匹配注意力机制。
注意力矩阵的计算瓶颈
- 复杂度问题:自注意力的计算复杂度为 (O(n^2)),长序列时内存消耗大。
- 优化技术:稀疏注意力(如 Longformer)、低秩近似(如 Linformer)。
案例与实例
1. 实例演示:Transformer 处理文本(翻译任务)
以下代码展示如何使用 Hugging Face 的 transformers 库实现英译中的完整流程,并解释关键步骤。
代码实现
python
from transformers import MarianMTModel, MarianTokenizer
# 加载预训练的英译中模型和分词器
model_name = "Helsinki-NLP/opus-mt-en-zh"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
# 输入文本
input_text = "Hello, world!"
# 分词与编码
encoded_input = tokenizer.prepare_seq2seq_batch([input_text], return_tensors="pt")
# 模型推理
with torch.no_grad():
output = model.generate(**encoded_input)
# 解码输出
translated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(f"输入:{input_text}")
print(f"输出:{translated_text}")输出结果
输入:Hello, world!
输出:你好,世界!关键步骤解释
- 模型选择 :使用
Helsinki-NLP/opus-mt-en-zh,这是一个专门训练的英译中 Transformer 模型 。 - 分词与编码 :
prepare_seq2seq_batch将输入文本转换为模型可处理的 token ID 序列,并添加特殊标记(如[CLS]和[SEP])。
- 模型推理 :
- 编码器将输入序列映射为中间表示。
- 解码器通过自注意力和交叉注意力机制逐步生成目标语言的 token 。
- 解码输出:将模型生成的 token ID 转换为可读文本 。
2. 可视化分析:注意力权重图
以下代码展示如何提取并可视化 Transformer 的注意力权重,以句子 "The cat sat on the mat" 为例。
代码实现
python
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from transformers import BertTokenizer, BertModel
# 加载预训练 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased", output_attentions=True)
# 输入文本
input_text = "The cat sat on the mat"
# 分词与编码
inputs = tokenizer(input_text, return_tensors="pt")
# 获取注意力权重
with torch.no_grad():
outputs = model(**inputs)
attention_weights = outputs.attentions[0].squeeze().numpy() # 取第一层的注意力头
# 可视化
plt.figure(figsize=(10, 8))
sns.heatmap(attention_weights, annot=True, cmap="YlGnBu",
xticklabels=tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]),
yticklabels=tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]))
plt.title("Self-Attention Weights Visualization")
plt.show()输出结果
生成的热力图显示:
- "cat" 和 "mat" 之间的注意力权重较高(例如 0.6),表明模型捕捉到两者在语义上的关联 。
- 特殊标记(如
[CLS])与其他词的权重较低,符合预期。
关键解释
- 注意力权重提取 :
output_attentions=True使模型返回注意力权重张量 。attention_weights的形状为(num_heads, sequence_length, sequence_length)。
- 可视化工具 :
- 使用
seaborn.heatmap绘制热力图,颜色深浅表示权重强度 。
- 使用
- 语义关联 :
- 高权重的 "cat" 和 "mat" 反映了模型对上下文关系的理解(如动物与位置)。
3. 编码实践:简化版 Transformer
python
import torch
import torch.nn as nn
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, embed_size, num_heads):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.positional_encoding = positional_encoding(100, embed_size)
self.multihead_attn = nn.MultiheadAttention(embed_size, num_heads)
def forward(self, x):
x = self.embedding(x) + self.positional_encoding[:, :x.size(1), :]
attn_output, _ = self.multihead_attn(x, x, x)
return attn_output
# 示例模型
model = SimpleTransformer(vocab_size=1000, embed_size=64, num_heads=8)
input_seq = torch.randint(0, 1000, (1, 10)) # 输入序列
output = model(input_seq)- 翻译任务:通过编码器-解码器架构和注意力机制,Transformer 能够准确捕捉全局依赖,生成高质量译文 。
- 可视化分析:注意力权重图直观展示了模型如何关注不同词之间的关联,为模型决策提供可解释性 。
- 简化版 Transformer:通过简化版代码解释Transformer的核心原理 。
总结与扩展思考
Transformer 为何能统一 NLP 任务
- 通用架构:编码器-解码器设计适用于翻译、摘要、问答等任务。
- 迁移学习:预训练模型(如 BERT)通过微调快速适应下游任务 。
架构创新对 AI 的启示
- 模块化设计:自注意力、位置编码等模块可灵活组合。
- 规模效应:参数量与性能的强相关性推动算力需求增长。
局限性与替代技术
- 长序列处理:二次方复杂度限制了超长文本的应用。
- 替代方案:RNN+Transformer 混合架构、线性注意力模型(如 Performer)。
希望本文能帮助你理解 Transformer 的核心原理!如果你有任何疑问或想法,欢迎在评论区交流讨论!
参考文献
本文参考了以下文献,特此鸣谢!
【Transformer】10分钟学会Transformer | Pytorch代码讲解 | 代码可运行