作者:vivo 互联网服务器团队- Zhang Yi 当前vivo的应用监控产品Vtrace经常遇到用户反馈某个Trace链路信息没法给他们提供到实质的帮肋,对此团队一直在持续完善JavaAgent的采集。经过不断增加各类插件的支持,同时想方设法去补全链路信息,但一直还是无法让用户满意。面对这样的困境,需要改变思路,从用户角度思考,在产品中找灵感。同时产品重新思考在应用监控中一条完整的Trace应该展现给用户哪些信息?业界其它产品对Trace的监控可以观测到什么程度?带着这些问题,Vtrace通过全面的同类产品对比分析,结合vivo实际情况自研Profile采集,从而开启涅槃之路。
专业术语
【Vtrace】:vivo应用监控系统,是一款vivo自研应用性能监控产品。
【Trace】:通常用于表示一系列相关的操作或事件,这些操作或事件通常跨越多个组件或服务,一个Trace可能由多个Span组成。
【Span】:属于Trace中的一个小部分,表示某个特定操作的时间跨度,比如执行一次查询SQL的记录。
【APM】:APM为Application Performance Monitoring 的缩写,意为应用性能监控。
【POC】:通常指的是 "Proof of Concept",即概念验证。在软件开发和信息技术领域,POC 是指为了验证某项技术、方法或想法的可行性而进行的实验或测试。在监控领域,一个监控POC通常指的是为了验证某个监控方案、工具或系统的可行性而进行的验证。
【Continuous Profiling】:持续剖析,有些厂商叫Continuing Profile或Profiler,也有人将Continuous Profiling和Trace、Metric、Log放在同一位置。总之是一种持续性的性能分析技术,它可以实时监测和记录程序的性能数据,以便开发人员可以随时了解程序的性能状况。这种技术可以帮助开发人员发现程序中的性能瓶颈和优化机会,从而改进程序的性能。通过持续性地监测程序的性能数据,开发人员可以更好地了解程序的行为和性能特征,从而更好地优化程序的性能。本文中Profile一般指持续剖析。
一、背景
当前应用监控产品Vtrace中的Trace链路数据只串联了服务与服务,服务与组件之间的Span信息,但对于发生于服务内部方法具体执行耗时是无法监控的,即所谓监控盲区。

图1
图1为当前Vtrace系统的一个Trace信息,这个Trace显示内部没有任何其它组件,事实上真的如此么?先看看下面实际代码:
java
@GetMapping("/profile/test")
public String testProfile() {
try {
//执行sleep方法
doSleep();
//执行查询MySQL,但方法使用synchronized修饰,多线程的时候会塞阻,同时查询SQL时一般会先获取数据库链接池
synchronizedBlockBySelectMysql();
//读取文件数据,并且将数据序列化转JSON
readFileAndToJson();
//发送数据到kafka
sendKafka();
return InetAddress.getLocalHost().getHostAddress();
} catch (Exception e) {
log.error("testProfile {}", e.getStackTrace());
}
return "";
}
private void doSleep() throws InterruptedException {
Thread.sleep(1000);
}
private synchronized void synchronizedBlockBySelectMysql() {
profileMapper.selectProfile();
}
private void readFileAndToJson() throws InterruptedException {
String fileName = VivoConfigManager.getString("profile.test.doc.path","D:\\json1.json");
StringBuilder builder = new StringBuilder();
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(fileName), "UTF-8"))) {
String line;
while ((line = br.readLine()) != null) {
builder.append(line);
}
br.close();
JSONArray jsonArray = JSON.parseArray(builder.toString());
} catch (Exception e) {
log.error("testProfile {}", e.getStackTrace());
}
}
private void sendKafka() {
for (int i = 0; i < 5; i++) {
kafkaTemplate.send(topic, "{\"metricName\":\"java.profile.test\",\"id\":1,\"isCollect\":false}");
}
}从上面的代码可以看出接口/profile/test的profileTest方法实际执行了四个私有方法:
-
doSleep()方法,让程序休眠1秒
-
synchronizedBlockBySelectMysql方法查询MySQL,但这个方法使用了synchronized修饰,多线程同时执行这个方法时会塞阻。另外查询MYSQL一般会使用连接池,这次测试的代码使用Hikari连接池
-
readFileAndToJson方法读取文件数据并且将数据转JSON为JSONArray
-
sendKafka方法主要是发送数据到Kafka
但这四个方法在Vtrace系统中的Trace信息中什么都体现不了,JavaAgent并没有采集到相关信息。这恰好说明了这里存在监控盲区,并且盲区远比想象中的要大,某些场景中连最基本的MySQL执行的信息都看不到。

图2
对于图1那种情况在实际中会经常遇到,用户会发现Trace中没有他想要的信息。有时会像图2中那样有几个组件的Span,但整个Trace中依然存在一大片空白的地方,不知道具体的代码执行情况。
针对上述的场景,为了让用户通过Trace获取更多有用信息,后续需要做的有两件事:
-
支持对更多组件的埋点采集
-
针对Trace进行方法调用栈的采集
而本文主要从下面几个角度论述我们如何改变当前Vtrace的现状:
-
同类产品对比分析:通过SkyWalking、DataDog和Dynatrace三款产品的Trace观测程度对比分析,从产品的视角去获得Vtrace的优化思路。
-
程序设计:通过同类的产品功能引入行业中Continuous Profiling概念,结合同类产品的技术实现情况设计Vtrace JavaAgent对方法调用栈采集的技术方案。
-
压测分析:针对在JavaAgent增加方法调用栈采集之后进行压测,评估出JavaAgent改进后的资源影响,并且分析出资源消耗增加的根因与确定后续持续优化的方向。
-
落地评估:通过当前已经接入Vtrace产品的服务情况与JavaAgent压测结果去分析Vtrace的方法调用栈采集功能如何落地。
二、同类产品对比分析
在设计JavaAgent方法调用栈监控采集前,先看看业界的监控同类产品对Trace的分析能够做到何种程度。
下面我们使用SkyWalking、DataDag和Dynatrace三款同类产品,对上面/profile/test接口进行监控分析。通过对同类产品监控情况的分析会给我们带来一些启发,同类产品的一些优秀设计思路也会有助于我们完善的Vtrace产品。
2.1 Apache SkyWalking
Apache SkyWalking是一款优秀的开源应用性能监控产品,Vtrace的JavaAgent就是基于早期的SkyWalking 3.X版本开发的。

图3
上图为/profile/test接口在SkyWalking的trace信息,显然可以看出请求中访问MySQL与Kafka,其中SQL的执行时间大约为2秒(图3中的MySQL/JDBC/PrepardStatement/execute为实际执行SQL的Span)。同时使用Hikari链接池工具获取数据库链接的信息也记录了,这个记录很有用,如果数据库链接池满了,一些线程可能一直在等待数据库链接池释放,在某些情况下很可能是用户数据库链接池配置少了。
相对于Vtrace系统的trace信息,显然SkyWalking观测能力强了不少,但依然存在doSleep与readFileAndToJson这两个方法没有观测到。
对于这种情况,想到了SkyWalking的性能剖析功能,那再利用性能剖析看看能不能分析出doSleep与readFileAndToJson这两个方法。

图4
图4是SkyWalking对/profile/test接口配置性能剖析的交互,这里可以配置端点名称、监控的持续时间,监控间隔以及采集的最大样本数。而监控间隔配置的越小采集到的数据会越精确,同时对服务端的性能影响则越大。

图5
配置好性能剖析规则后,再次发出/profile/test请求。等待了一段时间,从图5中可以看到doSleep和synchronizedBlockBySelectMysql方法的执行情况。

图6
关于synchronizedBlockBySelectMysql方法的,如果是执行sql耗时,采集到的应该如图6左侧那样看到的是正在执行SQL的socketRead0方法,而这里显示的是synchronizedBlockBySelectMysql这个代码块,即性能剖析时SkyWalking采集到的数据方法栈的栈项为
synchronizedBlockBySelectMysql,这里由于synchronized的修饰在执行SQL前需要等待别的线程释放整个方法块。
从上述可以看出SkyWalking显然对profileTest方法能很有效地分析,但存在一个问题就是性能剖析不能自动持续分析,需要用户手动开启,遇到难以复现的情况时不好回溯分析。
虽然SkyWalking持续剖析存在这一点小瑕疵,但我们不得不承认Skywalking对Trace的分析还是挺强大的。Vtrace的JavaAgent是在SkyWalking3.X版本的基础上实现的,而SkyWalking成为Apache项目后经过这几年的持续迭代已经发展到10.X版本了。对比我们Vtrace JavaAgent,显然SkyWalking的进步巨大。
2.2 DataDog
与开源的SkyWalking不同,DataDog是一款商用可观测软件,在Gartner可观测排名靠前。接下来我们使用DataDog去分析刚才的/profile/test接口。

图7
图7是使用DataDog采集到/profile/test接口Trace数据,明显可以看出:
-
MySQL组件与Kafka组件的执行耗时
-
整个Trace的Safepoint和GC占用时间

图8
图8为本次trace的火焰图,从图中可以看到readFileAndTojson这个方法热点。
从DataDog的Trace信息中我们可以看出DataDog也能直接发现MySQL与kafka组件,同时提供这次trace的火焰图,从火焰图中能够看出readFileAndTojson方法执行。但doSleep方法与synchronizedBlockBySelectMysql方法关键字synchronized同步等待的时间没被观测到。
不过感觉到意外的是可以在DataDog中看到这次trace的Safepoint和GC占用时间,这样用户可以分析出该Trace是否受到Safepoint和GC影响。
2.3 Dynatrace
Dynatrace也是一款商用可观测产品,Gartner可观测排名常年第一,技术上遥遥领先。

图9
图9为/profile/test接口在Dyantrace中的一个Trace信息,图中左侧红框可以直接看到MySQL和Kafka组件,中间红框是这次trace的线程整体时间分布情况,包括CPU时间,Suspension挂起时间,还有Waiting、Locking、Disk I/O和网络I/O ,为了方便大家理解深层的性能特征他们用不同的颜色区分,具体说明如下:

表1
从图9右边红色框框的可以看到这个Trace整个生命周期的线程各个阶段的分布,再点击"View method hotspots",则本次trace的方法热点如下图图10所示:

图10
看到图10的内容非常惊讶,源代码中的四个私有方法全部被观测到,四个方法底层的实质也显露出来,具体如下:
-
发现doSleep与sendKafka这两个方法,并且他们的操作主要是在Waiting。
-
synchronizedBlockBySelectMysql方法图中浅蓝色部分显示他在Locking,等待着别的线程执行完synchronized修饰的方法;后半段粉色部分为查询MySQL的IO操作,细分为Network I/O。
-
readFileAndToJson方法中有一段紫色的部分 ,那是在读取文件的IO操作,分类为Disk I/O,而同时读取文件与将文件中的内容转换为JSON也是这次Trace消耗CPU的主要代码。
上面除了整个Trace的方法热点的总览信息,还可以下钻进入每个方法再深度分析。

图11
图11是展开doSleep与sendKafka两个Waiting方法分析,可以明显看出doSleep方法实际上底层耗费在Thread.sleep,而sendKafka方法的Waiting是Kafka底层工具类SystimeTime.waitObject中执行更底层的Object.wait。
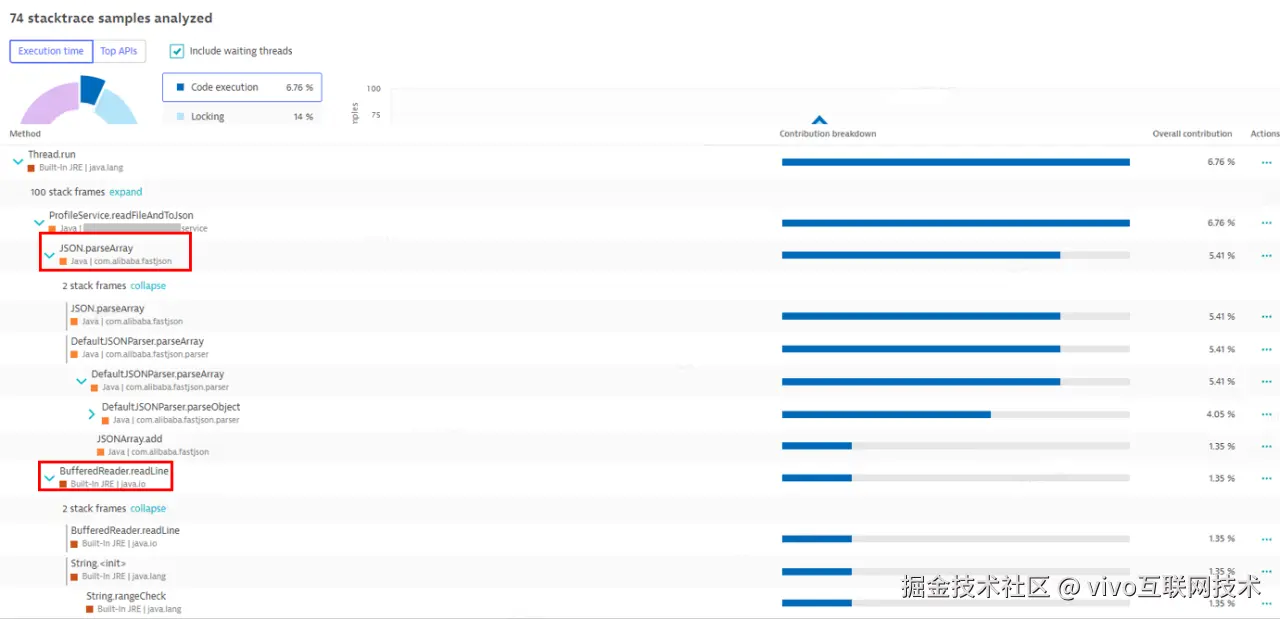
图12
图12为选定"Code execution"后再展开readFileAndToJson方法,这里两处主要耗费CPU的操作,一个是JSON.parseArray,一个是BufferedReader.readLine。

图13
除了方法热点分析,Dynatrace还提供了"Code level"的分析,从图13中可看到Hikari链接池的获取情况。
从结果上来看,Dynatrace的观测能力果然遥遥领先,他的观测能力不是仅仅简单告诉用户每个地方的执行耗时,他告诉用户代码执行情况的同时让用户更好地了解程序每个行为的底层原理和性能特征。
2.4 分析总结
在完成上述三个产品的Trace分析后,结合当前Vtrace产品,做了一些对比:

表2
通过同类产品对比分析发现当前Vtrace整体功能与业界领先的产品比较显得相对落后。另外,业界优秀的产品还有很多,而我们选择SkyWalking、DataDog和Dynatrace因为他们具有一定的典型性和代表性。而对于上述的三款产品,本文产品分析只是针对Trace链路的观测能力来测试来比较。
最初在考虑如何完善我们的Trace链路,我们的计划是参考新版SkyWalking的Profile功能,所以当时的同类产品分析只选SkyWalking,而/profile/test接口的四个私有方法也是提前就设计好的。
但在做设计评审时,发现只基于一个开源产品的能力去设计,最后可能得出的方案会是片面的。考虑到不同产品的Trace信息呈现会有所不同,于是我们决定再找一些同类的商用产品来对比分析。而同类产品Trace呈现出来的信息涉及数据采集,我们需要分析产品能力的同时也要去了解同行的采集技术方案。
因为曾经主导过一个可观测项目,邀请了国内外的主要APM厂商来企业内部私有化部署产品,用了长达半年多的时间对大概10款产品进行POC测试,大部分产品的Trace信息展示是差不多的,而当时很多产品的Trace观测能力并不比现在的SkyWalking会好。同时,简单看了当前一些国内大厂可观测产品Trace的交互后,为了避免同质化,便选择了当时POC没法私有化部署的DataDog与POC测试时效果远超同行的Dynatrace。
由于/profile/test接口的四个私有方法是在SkyWalking测试前就已经设计好的,所以在要把DataDog和Dynatrace加入测试时并不知道这两款产品会呈现出什么样的实际效果。现在都知道DataDog和Dynatrace的测试结果,这两个产品的Trace中都有出乎意料的重要信息,这带给我们不少启发。
本节最后说些题外话,相信国内很多大厂都有自己的可观测产品或者正在使用一些其它厂商可观测产品,你们可以将/profile/test接口的代码用你们现在使用的监控产品测试一下,看看你们的Trace能观测到什么,如果有一些意外的发现,不防联系我们,大家一起相互学习学习。
三、程序设计
通过同类产品的对比分析,为了让我们的Trace信息更完整,第一件事是需要完善组件。同时同类产品可以观测到更多有用的信息,所以第二件事我们需要知道这些信息同类产品是如何采集的。另外也不能只顾着单一完善Trace信息而设计 ,设计上需要考虑后续的整体规划。
随着对同类产品的深入了解知道同类产品使用了一种叫Continuous Profiling技术手段,通过这种手段他们才有如此丰富Trace信息。比如DataDog的火焰图和Dynatrace的方法热点正是这技术手段的体现。同时在他们产品中Continuous Profiling有明确的定位,常见有下面四个功能:
-
CPU Profiling:深入了解进程的方法热点,按代码执行、网络 I/O、磁盘 I/O、锁定时间和等待时间分解和过滤数据,常见的火焰图正是CPU Profiling的产品体现。
-
Memory Profiling:内存分析可以了解应用程序随时间变化的内存分配和垃圾回收行为,识别分配了最多内存的上下文中的方法调用,并将此信息与分配的对象数量相结合。
-
Memory Dump Aalysis:通过进程的内存使用进行dump并分析。
-
Continuous Thread Analysis:对线程持续分析,主要是后台线程组,记录每个线程各个时间段的线程状态以及资源使用情况。
不难看出上述功能在很多同类产品都有,比如Vtrace现在利用Vivo运维工具实现了CPU Profiling、Memory Profiling以及Memory Dump Analysis。但是Vtrace的CPU Profiling与Memory Profiling并不是持续的,需要用户手动触发,每次最多只能剖析5分钟。后续我们会慢慢实现或优化Continuous Profiling的各个功能,而现在Vtrace系统是借助CPU Profiling的技术手段去完善每个Trace的方法调用栈信息。
3.1 方案选择
在分析SkyWalking、DataDog和Dynatrace是如何实现他们的Profile信息采集前,我们先看看Java应用在业界主流实现CPU profling的技术方案:JMX 、JFR 和 JVMTI AsyncGetCallTrace。
(1)JMX
Java Management Extensions(JMX)是Java平台上的一种管理和监控技术,它允许开发人员在运行时监视和管理Java应用程序,一般使用ThreadMXBean中的dumpAllThreads可以获取当前线程执行的方法栈情况,利用每次获得的线程调用栈栈帧信息,可以实现方法热点的监测。
(2)JFR
Java Flight Recorder(JFR)是Java平台上的一种性能监控和故障诊断工具,JFR的特点包括低性能开销、低停顿、持续监控、动态配置和丰富的数据。它可以在应用程序运行时收集性能数据,而几乎不会对应用程序的性能产生影响。但JFR的支持对Java版本有一定的要求。
(3) JVMTI AsyncGetCallTrace
AsyncGetCallTrace是JVMTI中的一个非标函数,用于异步获取线程的调用堆栈信息。使用AsyncGetCallTrace,开发人员可以在应用程序运行时异步去获取线程的调用堆栈信息,且不会阻塞线程的执行。这对于性能分析和故障诊断非常有用,因为它允许开发人员在不影响应用程序性能的情况下获取线程的调用堆栈信息,从而更好地了解应用程序的执行情况和性能特征。
上述三种方案便是实现CPU Profiling的主流方案,这三个方案在我们之前分析的三个产品中使用情况如下:

表3
SkyWalking使用JMX实现性能剖析。他的实现是通过将采集到的Trace在JVM内部开启线程任务,线程任务通过segmentId绑定当前segmentId所在的线程,按照采集频率定时使用getStackTrace获取各个时段的调用栈信息。但它的设计并不是为了实现CPU Profiling,他只是一个补全Trace的链路分析快速实现,针对一些已知问题,常复现的问题,可以快速定位到根因。后续SkyWalking也不一定会使用上述三种方法实现Java语言的CPU profling。
DataDog最开始是用JFR实现CPU Profiling,后来结合开源工具Async-profiler,完善整个Continuous Profiling功能。Async-profiler实现完全基于JVMTI,其中它的CPU热力图就是得益于AsyncGetCallTrace接口。
Dynatrace是个异类,它做分布式Trace链路监控的时候,谷歌Dapper论文还要几年才出世,谷歌Dapper流行后,它已放弃了通过"-javaagent"指令的方式实现字节码增强,在java,.net,go,python等众多语言实现无需引用相应的agent即可深入监控代码级别的内部链路。它早期使用JavaAgent实现的产品AppMon可能使用过JMX实现CPU Profiling,10年前它改版后便完全基于JVMTI的AsyncGetCallTrace实现。
基于JFR或AsyncGetCallTrace实现CPU Profiling性能开销会低很多。我们vivo的每个人都追求极致的性能,在技术选型上更偏向性能好的方案。而从厂商DataDog已经从JFR转向通过结合Async-profile来实现整个Continuous Profiling,JFR可能并不是一个好选择,所以剩下AsyncGetCallTrace的实现方式。或许最终我们也会利用Async-profiler。
但是无论利用Async-profiler或者像Dynatrace一样独自去实现基于AsyncGetCallTrace采集,这对于我们监控团队来说都存在困难,因为我们团队缺少这方面的人力储备。如果我们选择基于AsyncGetCallTrace实现,要从零开始,需要学习c++与Async-profiler。这样整个研发周期会被拉得很长,短则至少三个月长则半年,同时有较大的不确定性,交付存在风险。
另外基于JMX实现的采集方案被认为性能不够好,但真正的性能损耗情况需要实践去检验。如果10ms和20ms的采集频率消耗资源太高,可以尝试降低采集频率。为了快速解决用户痛点,现阶段我们先选择基于JMX在Vtrace的JavaAgent中实现,在JavaAgent中实现后再基于压测情况决定后续落地方案。
3.2 基于JMX Profile采集设计

图14
事实上我们这次的设计并不是为了实现CPU Profiling,更多是为了补全Trace的信息。而对Trace的方法堆调用栈情况采集,我们基于JMX Profile设计如下:
1、JavaAgent启动时,如图14所示开启一个采集频率 50ms Profile采集线程,当然这里采集频率用户是可以自行配置的。
2、Trace进入时将traceId与当前trace线程id合并成一个traceSegmentId(基于SkyWalking 6以上实现的JavaAgent可以直接使用他们自身的traceSegmentId),同时将这traceSegmentId与当前线程Id绑定放到一个叫TRACE_PROFILE_MAP(Map)的集合中。TRACE_PROFILE_MAP除了记录traceSegmentId和线程id,同时会记录后续被Profile线程采集到的快照。
3、Profile数据采集的线程会定时将TRACE_PROFILE_MAP集合当前的所有线程id通过ThreadMXBean.getThreadInfo获得每个线程当前栈帧信息。记录当前栈帧顶部信息并按照我们设置的深度保留栈帧的一些信息当作本次快照。如果这个trace线程下一次被采集的栈帧顶部信息与栈深度与这次一样,我们不需要记录本次快照,只需将上次快照出现的次数+1,如图14中栈顶为Thread.sleep的快照被我们记录了4次。如果相邻的两次采集栈帧顶部信息不一样,我们则记录两次快照信息,如图14对于这个trace我们最后记录了栈顶为Object.wait的快照3次。
4、trace结束时,先根据traceSegmentId获取到本次trace采集到的Profile快照数据,然后交给后续Profile数据上报线程异步处理,同时将TRACE_PROFILE集合记录当前trace线程的相关数据从集合中移除。
5、如果这个trace是使用到多线程会整个trace会多个不同的traceSegmentId,每个异步线程的相关Profile数据也会被采集到。
从流程上来看,基于JMX实现CPU profiling采集确实简单,但也可以看出定时采样的方式本身的缺陷,如图11中readFileToJson方法中显示的采集频率太大两次采样会中间的读取文件的Disk I/O会被忽略,但这也是无法避免的,用其它技术方案来实现也一样会有这种问题。因此在实现Profile采集后,后续需要测试不同场景下不用采集频率对资源的利用情况,然后结合当前vivo服务的整体情况,再最终决定这个方案是否用于生产。
3.3 基于AsyncGetCallTrace Profile采集设计
虽然我们先尝试基于JMX的方式实现Profile采集,但不妨碍我们探讨别的实现方案,很可能后续团队能力起来后再转向基于AsyncGetCallTrace实现。
通过分析AsyncGetCallTrace源码与Async-Profiler的实现,发现基于AsyncGetCallTrace Profile的采集流程和上述流程相差不大,无非就是怎么触发采集,在Liunx系统一般使用信号量来触发,这也会大大地降低采集时的性能损耗。
有些操作系统不支持使用信号量来调用AsyncGetCallTrace函数,可能需要用c++实现一个不受JVM管理的线程,避免采集时受JVM SavePiont或GC的影响。
另外并不是所有操作系统的JVM中都提供AsyncGetCallTrace这个函数。
上述基于AsyncGetCallTrace的采集设计只是通过简单的一些了解而设想的,并不一定正确,欢迎指正。
后续如果我们完全实现了基于AsyncGetCallTrace Profile采集我们再向大家介绍实现的细节。
3.4 存储设计
介绍了Profile数据的采集设计,接下来聊一下存储设计。
一个时间跨度为1秒的Trace,在采集频率为50ms时最多可能会被采集到10个副本。假设Profile采集记录stack深度为20,一份快照信息大约1KB,这样的话每个Trace最多可能需要增加10KB的存储。如果记录stack深度为100时快照信息大小则6KB左右。

图15
上图为我们Prfoile采集的一个快照文本内容,这个数据大约1kb。如果每个快照数据都这样存储,则会占用大量的存储。同一个接口不同Trace的Profile数据会存在大量相同的快照文本,相同的快照文本用同一个UID来保存。UID可以为快照文体的MD5值,每个UID只占16字节。后续在分析Trace信息时再将UID对应快照文本显示给用户,这样会节省大量的存储成本 。

图16
图16为Vtrace基于JMX实现Profile采集到数据,为了快速验采集的效果直接让采集到的快照数据作为Span存储。图中第一行数据为整个请求的trace耗时,而红色框中的则为这个在trace我们Profile采集线程采集到的调用栈信息,从结果来看把我们原先的一些监控盲区补上来了。这图的数据只是临时处理,实际后续产品交互并不会这样展示。
现在存在的问题就是Vtrace JavaAgent对所有Trace采集会整个服务的性能有哪些影响,而这些影响,是否在我们的接受范围内。我们需要对增加Profile采集后对JavaAgent进行压力测试,需要对比开启Profile采集与未开启Profile采集的性能指标差异。
四、压测分析
4.1 测试设计
测试时需要考虑很多因素,因此在测试前先对测试做好设计,有以下的测试要点:
-
测试需要考虑环境,比如cpu核心数,容器或虚机,有条件最好使用物理机测试
-
测试考虑不同采集频率时对性能的影响
-
需要在不同TPS的情况下对比资源的消耗
-
要考虑同一TPS下,IO不同的密集程度下资源消耗差异
4.2 测试结果
测试的时候我们记录了很多指标,有很多数据,本文中就不一一展示了。Vtrace的Profile采集对应用性能的产生实质影响在这里我们只需考虑CPU使用和GC情况,因为采集增加的内存会侧面反映在GC情况中。
下面为不同场景下开启与不开启Profile持续剖析时的资源利用情况对比:

表4
-
上述场景中TPS小于等50时,GC次数很少,开启Profile采集对GC的影响相差不多。而开启Profile采集后对内存的影响主机体现在GC上。
-
场景1与场景2、场景3与场景4、场景5与场景6三组采集频率不同的对比测试,可以看出Profile采集频率直接影响服务的资源消耗。
-
随着测试TPS的上升,Profile采集消耗的资源也相应的增加,1000 TPS内,从容器与虚机,CPU 4核心时,开启Profile采集CPU消耗整体增加不高于5%; CPU 2核心时100 TPS内开启Profile采集CPU消耗整体增加不高于4%。
对于这个结果并不能说很理想,但又比预期要好一些,后续我们再结合我们当前应用的情况再分析是我们基于JMX实现的Profile是否可以投入生产使用。
而从上面的性能压测结果可以看出通过降低采集频率,CPU资源消耗有明显减少。但采集频率不宜过低,50ms对于大部分应用来说可以采集到很多有效的信息,这是我们的一个推荐值。
4.3 资源消耗增加原因
在压力测试后我们知道开启Profile采集后CPU资源会有所增加,接下来需要确定导致资源消耗增加的地方有哪些。
为了找出根因,最初我们想使用Arthas来生成火焰图来分析,虽然这个场景应该也能分析出根因,但并不是很直观,分析过程不会很流畅。Arthas分析这个场景大概是这样的,在开启Profile采集前后分别生成火焰图,但这样没法直观地去对比出开启采集后额外增量的热点。同样针对线程分析,Arthas并没有将线程归类分组,显示了大量的http-nio-?-exec线程(?为线程ID)。后来我们再次想起了前提到的Dynatrace中的Cpu Profiling与Continuous thread analysis功能,后续可能我们也会去实现类似的功能,抱着学习下商业化产品的Continuous thread analysis功能,于是便使用Dynatrace来分析。
虽然这个场景可以直接使用Dynatrace的方法热点分析,但从进程到线程对比开启Profile采集前后指标,整个流程会更加顺畅,同时这样的排查思路与产品呈现会带来一些设计上的启发。

图17
图17是流量相同的情况下,开启Profile采集前后指标的变化,从中可以看出:
-
整个java进程CPU变化从8.51%增加到12%
-
后台线程CPU变化从4.81%增加到8.4%
-
GC线程CPU变化从0.15%增加0.3%
上述结论我们知道开启采集后导致进程CPU使用率增加的主要有后台线程和GC线程,GC线程略有增加主要还是采集时额外使用的内存增加导致,所以下面我们重点对后台线程分析,这里用到的便是Continuous thread analysis功能。

图18
图18为开启Profile采集后的后台线程分析,展示了某段时间内主要所有后台线程组的运行情况,我们可以看出增加的两个进程组正好是我们的Profile采集线程与Profile数据发送线程,而Profile采集线程的奉献度占比远大于Profile数据发送线程。

图19
针对Profile采集线程我们再深入这个线程一段时间内的方法热点去看,从图19的结果上看Profile采集线程消耗CPU主要在调用JVMTI方法(ThreadImpl.getThreadInfo1)获取当前线程的信息。
对这个判断有点怀疑,认为线程信息采集到后处理调用栈的逻辑会有所消耗资源。对这个疑问,简单的方法可以先将Profile采集线程中调用ThreadImpl.getThreadInfo1方法之后的所有代码注释然后压力测试。接着加上线程栈数据处理的代码同时注释Profile采集发送的代码,然后再在同样的条件下压测,之后再对比两次压测的性能差异。当然也可以使用Arthas来生成火焰图分析,但我们并不是这样做的,明显有更加直观的办法,可以看看下面的Profile采集伪代码:
ini
//第1步,记录当前Profile采线程cpu使用时间。getCpuTime实际是直接调用ThreadMXBean的getCurrentThreadCpuTime
long cpuTime = ThreadProvider.INSTANCE.getCurrentThreadCpuTime();
//第2步,获取线程集合的stackTrace信息。ids为当前正在执行的trace的线程ID集合,MAX_TACK_DEPTH为采集stackTrace的最大深度
//ThreadProvider.INSTANCE.getThreadInfos实际是直接调用ThreadMXBean的getThreadInfos,底层最终是调ThreadImpl.getThreadInfo1
ThreadInfo[] threadInfos = ThreadProvider.INSTANCE.getThreadInfos(ids, MAX_TACK_DEPTH);
//第3步,计算第2步的程序执行CPU使用时间
long threadDumpCpuTime = ThreadProvider.INSTANCE.getCurrentThreadCpuTime() - cpuTime;
//第4步,线程数据threadInfos的处理逻辑
for (ThreadInfo threadInfo : threadInfos) {
//获得单个线程StackTrace信息,后续处理代码省略
StackTraceElement[] stackTrace = threadInfo.getStackTrace();
int stackDepth = Math.min(stackTrace.length, MAX_TACK_DEPTH);
for (int i = stackDepth - 1; i > 0; i--) {
StackTraceElement element = stackTrace[i];
}
......
}
//第5步,计算整个采集线程结束时CPU的使用时间以及ThreadMXBean的getThreadInfos消耗CPU的时间占比。之后我们对比threadDumpCpuTime与processCpuTime便可知道整个线程CPU消耗在哪里
long processCpuTime = ThreadProvider.INSTANCE.getCurrentThreadCpuTime() - cpuTime;
float threadDumpCost = threadDumpCpuTime * 1.0f / processCpuTime * 100通过上述代码测试后发现第4步的代码确实上也会有一些消耗,但几乎99%以上都是消耗在第2步中。而Dynatrace显示ThreadImpl.getThreadInfo1占比为100%,这是因为Dynatrace的Profiiling功能一样也是有采样频率的,只是时间段内采集到的样本全部显示Profile采集线程获得CPU时间片的方法是ThreadImpl.getThreadInfo1,而这个测试恰好印证了Dynatrace方法热点的准确性。
而对于JMX中的ThreadImpl.getThreadInfo1,这是一个native方法,是无法直接优化的,只能等后续我们有能力基于AsyncGetCallTrace去实现Profile采集再解决。
4.4 压测小结
通过本次压力测试,我们清楚了基于JMX实现的Profile采集的性能消耗大致情况,也知道了性能瓶颈在哪里以及后续的优化方向。
五、落地评估
接下来我们需要分析当前接入Vtrace产品vivo服务的情况,后面基于上面的测试结果与现状去评估我们Profile采集能否最终落地。
5.1 当前vivo服务情况
目前接入Vtrace的2500+个服务中有200多个服务他们实例的平均TPS大于100 ,而单实例平均TPS小于100的服务占91.2%。下面表格中的数据是基于工作日某一分钟统计得出的当前Vtrace所有服务实例平均TPS值的分布情况:

表5
5.2 落地分析
通过上表可以看出vivo当前服务的情况,我们之前的测试结果表明在2c4g和4c8g的机器上服务TPS为20时 Profile采集频率设置50ms,cpu消耗增加1%不到。而我们约75%的服务TPS小于20,也就是说这些服务如果愿意接受1%的CPU资源消耗,基于JMX的Profile采集也能服务到大量的用户。
对于TPS大于100的服务,如果只是某些固定接口需要排查,可以通过配置对需要Profile采集的接口进行过滤,这样可以扩大落地的范围。
因为考虑压力测试的测试场景覆盖场景有限,我们会更谨慎一些,先完善一下Profile采集保护机制,后面一些服务中试点再逐步铺开。如果TPS小于20的服务顺利展开,之后再考虑覆盖TPS在20以上到100之间的服务。TPS超100的服务可以针对需要分析的接口开启Profile采集。至于所有服务全量采集覆盖可能需要等于我们攻克基于AsyncGetCallTrace的采集设计之后。
很多大型企业可能和vivo差不多,大部分90%以上的服务单个实例TPS在100之内。而传统企业TPS小于100的占比则更高,如果是制造业的话可能90%的服务TPS不到20。不过很多企业部署方式与vivo不同,他们可能在一个8c16g的机器上部署好几个服务实例,这样的话每个实例增加1%的资源消耗对于单个机器可能就显得多了。还好vivo基本上都是单机单实例部署或者容器部署,所以避免了上服务混合部署的情况。
最后,我们基于JMX的Profile设计虽然不是业界内的最优解,但却是当前快速解决vivo Vtrace监控的一个痛点的最优解。
六、未来展望
面对着困境我们努力优化却回报不高,在同类产品的分析后我们探索出改进方向,而在技术选型上我们做了一些妥协,最后随着对压测结果与vivo的实际情况分析发现我们还算交了一份不错的答卷。

图20
上图展示了Profile采集的最终效果,与图1相比,我们取得了巨大的进步。在优化了MySQL与Kafka的插件支持后,我们再次将Vtrace与同类产品进行对比:

表6
重新对比,可以看出Vtrace的Trace分析能力有了显著的变化,从最初无法识别基本组件,提升到与头部同类产品不相上下。这样的Trace分析能力在国内可观测领域属于顶尖水准,全球范围内也达到一流水平。
后续我们会重新整体去规划Continuous Profiling的相关设计,同时团队慢慢学习提升技术让团队能够基于AsyncGetCallTrace将Profile采集的性能优化到最低。这并不只是为了优化Profile采集的性能,而是考虑到实现整个Continuous Profiling团队也必须提升相关的技术能力。强大齐全的Continuous Profiling能力可观测系统根因分析的关键,采集端消耗资源越小观测能力的上限才会越高。
涅槃之路已经开启,涅槃之路就在脚下,但这也只是刚刚开始。未来Vtrace不需要用户配置任何的检测规则,服务出现异常时Vtrace能够自动检测出问题。自动检测出来的问题会自动定位出异常的的根因及异常影响业务的范围,比如受到影响的接口上下文、接口请求量与用户数量。而告警通知用户可以按照自己的团队要求去分派告警或者按照个人需求去订阅告警,告警按照着每个团队或个人的喜好方式流转。