1、整体流程梳理
- 推理平台部署 7. GPU和集群配置 6. RDMA验证 5. RoCE v2设置 4. 链路聚合配置 3. RoCE v2驱动安装 2. 基础环境配置 1. 物理连接与规划 基础连接就绪 设备识别完成 RoCE设置完成 RDMA验证通过 集群建立完成 配置分布式推理服务 安装推理软件环境 测试推理性能和稳定性 监控和优化系统性能 配置GPU Direct RDMA 安装NVIDIA驱动和CUDA 配置NCCL使用bond0接口 测试GPU间通信性能 部署集群管理软件 验证RoCE v2和PFC配置 测试bond0基本连通性 测试带宽和延迟性能 验证RDMA over bond功能 为bond0和物理端口启用PFC 配置所有物理端口为RoCE v2模式 配置DSCP值和QoS设置 持久化RoCE v2配置 添加所有CX4端口到bond0 创建bond0接口 配置bond0为balance-xor模式 设置bond0的IP地址 配置MTU为9000 加载RDMA和bonding内核模块 安装Mellanox OFED驱动 识别CX4网卡端口名称 确认所有端口状态为Active 安装RDMA和bonding必要软件包 安装Ubuntu 22.04 LTS操作系统 配置主机名与hosts文件 禁用防火墙或开放必要端口 四对端口背靠背直连 准备硬件: 2台服务器各2张CX4网卡 确认物理连接状态良好 管理网络GE口配置
2、服务器组网拓扑图
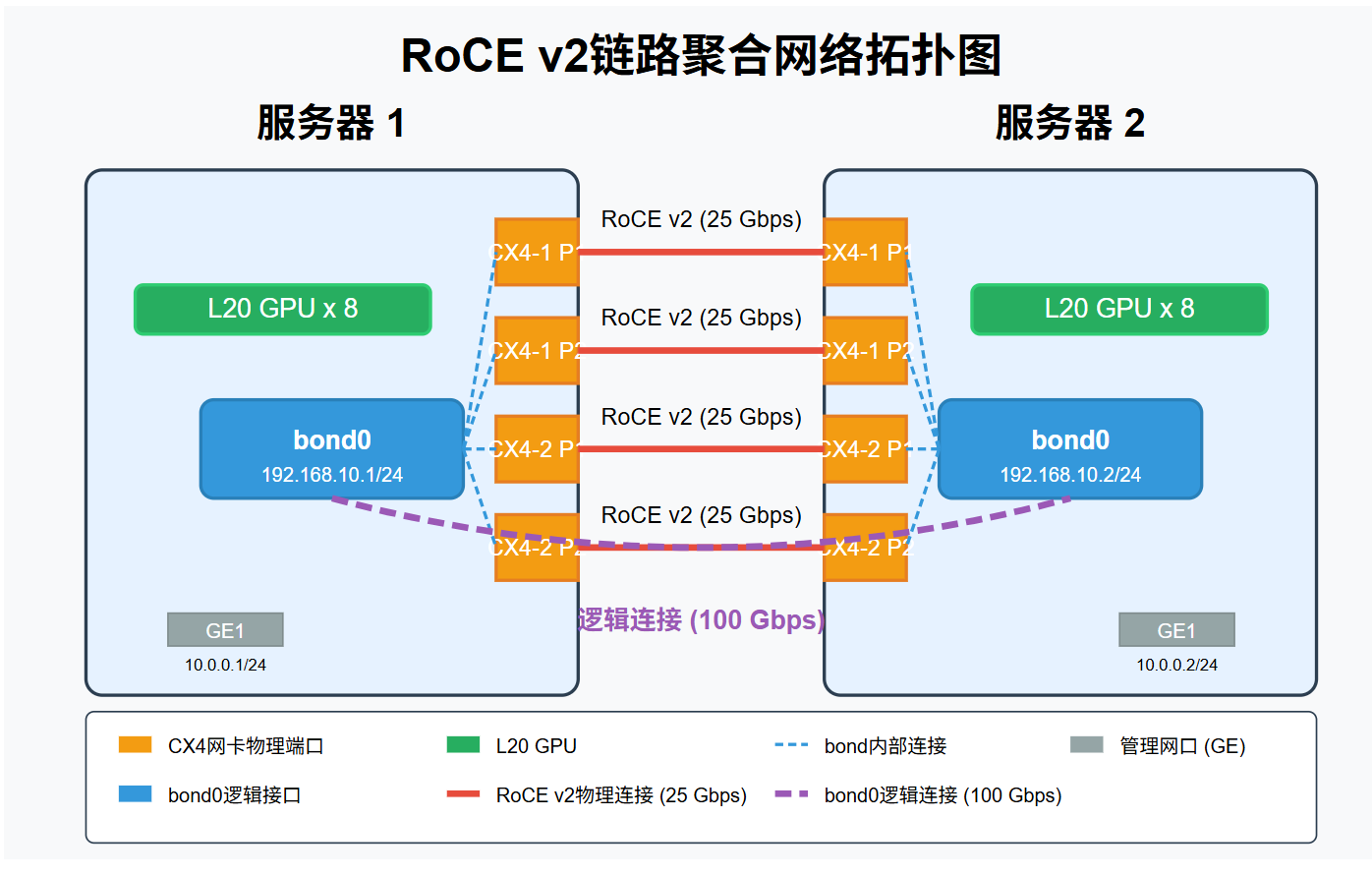
3、Roce v2详细组网方案
- 网络架构概述
采用链路聚合技术将每台服务器的4个25GbE端口组合成一个逻辑100GbE接口:
物理连接:2台服务器、每台2张CX4网卡(4个25GbE端口),背靠背直连
逻辑配置:每台服务器创建一个bond0接口,聚合所有物理端口
链路模式:balance-xor模式,采用layer3+4散列策略
MTU设置:9000字节(巨型帧)提升大包传输效率
- 详细部署步骤
2.1 物理环境准备
bash# 确认服务器硬件规格
CPU: Intel 6530 x2, 内存: 768GB, 显卡: L20 x8, 网卡: CX4 x2 (4x25GbE)
检查网卡识别情况
lspci | grep -i mellanox
确认网卡接口名称
ip a | grep -A 2 Mellanox
2.2 操作系统安装与基础配置
bash# 安装Ubuntu 22.04 LTS
完成基础系统安装后,确保系统更新到最新版本
sudo apt update && sudo apt upgrade -y
安装必要工具
sudo apt install -y rdma-core libibverbs-dev ibutils infiniband-diags perftest
iputils-ping net-tools ethtool ifenslave ntp
配置主机名和hosts文件
echo "server1" | sudo tee /etc/hostname # 第一台服务器
echo "server2" | sudo tee /etc/hostname # 第二台服务器
sudo tee -a /etc/hosts << EOF
192.168.10.1 server1
192.168.10.2 server2
EOF
配置NTP时间同步
sudo systemctl enable ntp
sudo systemctl start ntp
2.3 Mellanox OFED驱动安装
bash# 下载并安装OFED驱动
tar xzf MLNX_OFED_LINUX-23.10-1.1.8.0-ubuntu22.04-x86_64.tgz
cd MLNX_OFED_LINUX-23.10-1.1.8.0-ubuntu22.04-x86_64
安装带所有RoCE和bonding支持的OFED
sudo ./mlnxofedinstall --with-neohost-backend --with-nvmf --enable-gds --add-kernel-support --dpdk --upstream-libs --with-xpmem
重启OpenIB服务
sudo /etc/init.d/openibd restart
2.4 识别网卡端口和设备
bash# 列出所有IB设备
ibv_devices
查看网卡端口映射关系
sudo ibdev2netdev
输出可能如下(注意实际接口名称):
mlx5_0 port 1 ==> ens1f0 (Up)
mlx5_0 port 2 ==> ens1f1 (Up)
mlx5_1 port 1 ==> ens2f0 (Up)
mlx5_1 port 2 ==> ens2f1 (Up)
确认所有端口状态
for port in ens1f0 ens1f1 ens2f0 ens2f1; do
echo "=== $port ==="
ethtool $port | grep -E 'Link detected|Speed'
done
2.5 配置链路聚合
bash# 确保bonding模块已加载
sudo modprobe bonding
创建网络配置文件
sudo tee /etc/netplan/01-bond-roce.yaml << EOF
network:
version: 2
ethernets:
ens1f0:
mtu: 9000
ens1f1:
mtu: 9000
ens2f0:
mtu: 9000
ens2f1:
mtu: 9000
bonds:
bond0:
interfaces: ens1f0, ens1f1, ens2f0, ens2f1
parameters:
mode: balance-xor
mii-monitor-interval: 100
transmit-hash-policy: layer3+4
lacp-rate: fast
mtu: 9000
addresses: 192.168.10.1/24 # 服务器1使用192.168.10.1
服务器2使用192.168.10.2
EOF
应用配置
sudo netplan apply
验证bond配置
ip a show bond0
cat /proc/net/bonding/bond0
2.6 配置RoCE v2和PFC
bash# 确保所有CX4端口配置为RoCE v2模式
for mlx_dev in mlx5_0 mlx5_1; do
for port in 1 2; do
sudo cma_roce_mode -d {mlx_dev} -p {port} -m 2
done
done
配置PFC
sudo apt install -y dcbnetlink lldpd
为所有物理接口配置PFC
for iface in ens1f0 ens1f1 ens2f0 ens2f1; do
sudo mlnx_qos -i ${iface} --trust dscp
sudo mlnx_qos -i ${iface} --pfc 0,0,0,1,0,0,0,0
done
为bond0接口配置PFC
sudo mlnx_qos -i bond0 --trust dscp
sudo mlnx_qos -i bond0 --pfc 0,0,0,1,0,0,0,0
2.7 创建持久化RoCE v2配置
bash# 创建RoCE配置服务
sudo tee /etc/systemd/system/roce-config.service << EOF
Unit
Description=Configure RoCE v2 for bond and physical interfaces
After=network.target
Service
Type=oneshot
ExecStart=/usr/local/bin/roce-bond-setup.sh
RemainAfterExit=yes
Install
WantedBy=multi-user.target
EOF
创建RoCE和bond配置脚本
sudo tee /usr/local/bin/roce-bond-setup.sh << 'EOF'
#!/bin/bash
等待网络接口准备好
sleep 10
设置所有CX4端口为RoCE v2模式
for mlx_dev in mlx5_0 mlx5_1; do
for port in 1 2; do
cma_roce_mode -d {mlx_dev} -p {port} -m 2
done
done
配置PFC - 物理接口
for iface in ens1f0 ens1f1 ens2f0 ens2f1; do
if ip link show $iface &>/dev/null; then
mlnx_qos -i ${iface} --trust dscp
mlnx_qos -i ${iface} --pfc 0,0,0,1,0,0,0,0
fi
done
配置PFC - bond接口
if ip link show bond0 &>/dev/null; then
mlnx_qos -i bond0 --trust dscp
mlnx_qos -i bond0 --pfc 0,0,0,1,0,0,0,0
fi
设置MTU
for iface in ens1f0 ens1f1 ens2f0 ens2f1 bond0; do
if ip link show $iface &>/dev/null; then
ip link set dev $iface mtu 9000
fi
done
exit 0
EOF
sudo chmod +x /usr/local/bin/roce-bond-setup.sh
sudo systemctl enable roce-config.service
2.8 验证RDMA和RoCE配置
bash# 测试基本连通性
ping -c 4 192.168.10.2 # 从服务器1执行
ping -c 4 192.168.10.1 # 从服务器2执行
验证RDMA功能
在服务器1上
ibv_rc_pingpong -d mlx5_0 -g 0
在服务器2上
ibv_rc_pingpong -d mlx5_0 -g 0 192.168.10.1
测试RDMA带宽
在服务器1上
ib_write_bw -d mlx5_0 -a -F --report_gbits
在服务器2上
ib_write_bw -d mlx5_0 -a -F --report_gbits 192.168.10.1
多链路验证(并行启动多个测试)
for dev in mlx5_0 mlx5_1; do
for port in 1 2; do
ib_write_bw -d dev -i port -a -F --report_gbits 192.168.10.1 &
sleep 1
done
done
- GPU环境配置
3.1 安装NVIDIA驱动和CUDA
bash# 安装GPU驱动
sudo apt install -y nvidia-driver-535
安装CUDA 12.3
sudo sh cuda_12.3.2_545.23.08_linux.run --silent --driver --toolkit
配置环境变量
echo 'export PATH=/usr/local/cuda-12.3/bin: P A T H ′ ∣ s u d o t e e − a / e t c / p r o f i l e . d / c u d a . s h e c h o ′ e x p o r t L D L I B R A R Y P A T H = / u s r / l o c a l / c u d a − 12.3 / l i b 64 : PATH' | sudo tee -a /etc/profile.d/cuda.sh echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.3/lib64: PATH′∣sudotee−a/etc/profile.d/cuda.shecho′exportLDLIBRARYPATH=/usr/local/cuda−12.3/lib64:LD_LIBRARY_PATH' | sudo tee -a /etc/profile.d/cuda.sh
source /etc/profile.d/cuda.sh
验证安装
nvidia-smi
nvcc --version
3.2 配置GPU Direct RDMA
bash# 加载nvidia-peermem模块
sudo modprobe nvidia-peermem
验证GPU拓扑
nvidia-smi topo -m
持久化配置
echo "nvidia-peermem" | sudo tee -a /etc/modules
创建udev规则
sudo tee /etc/udev/rules.d/90-nvidia-peermem.rules << EOF
KERNEL=="nvidia_peermem", MODE="0666"
EOF
sudo udevadm control --reload-rules && sudo udevadm trigger
3.3 NCCL配置优化
bash# 创建NCCL配置文件
sudo tee /etc/nccl.conf << EOF
基本调试设置
NCCL_DEBUG=INFO
NCCL_DEBUG_SUBSYS=INIT,ENV,GRAPH,COLL
配置使用bond0接口
NCCL_SOCKET_IFNAME=bond0
仍然指定所有物理HCA设备
NCCL_IB_HCA=mlx5_0:1,mlx5_0:2,mlx5_1:1,mlx5_1:2
RoCE v2特定设置
NCCL_IB_GID_INDEX=3
NCCL_IB_TC=106
NCCL_IB_SL=3
NCCL_IB_RETRY_CNT=15
GPU Direct RDMA设置
NCCL_IB_CUDA_SUPPORT=1
NCCL_NET_GDR_LEVEL=5
NCCL_P2P_LEVEL=5
多通道优化
NCCL_MIN_NCHANNELS=4
NCCL_NSOCKS_PERTHREAD=4
NCCL_BUFFSIZE=4194304
优化选项
NCCL_ALGO=COLLNET_CHAIN
EOF
添加到环境变量
echo 'source /etc/nccl.conf' | sudo tee -a /etc/bash.bashrc
source /etc/nccl.conf
3.4 测试GPU通信性能
bash# 安装必要依赖
sudo apt install -y build-essential cmake openmpi-bin libopenmpi-dev
下载并编译NCCL测试
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make -j MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
测试单服务器内部GPU通信
./build/all_reduce_perf -b 8 -e 256M -f 2 -g 8
测试跨服务器GPU通信
mpirun -np 16 -H server1:8,server2:8 ./build/all_reduce_perf -b 8 -e 256M -f 2 -g 8
- 推理平台安装与配置
4.1 Python环境设置
bash# 安装Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p H O M E / m i n i c o n d a e c h o ′ e x p o r t P A T H = " HOME/miniconda echo 'export PATH=" HOME/minicondaecho′exportPATH="HOME/miniconda/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
创建环境
conda create -n inference python=3.10 -y
conda activate inference
安装PyTorch和依赖
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia -y
4.2 分布式推理架构配置 - Ray集群
bash# 安装Ray
pip install "raydefault>=2.9.0"
在服务器1(主节点)上启动Ray头节点
ray start --head --port=6379 --num-gpus=8 --resources='{"server": 1}' --dashboard-host=0.0.0.0
在服务器2上加入集群
ray start --address=192.168.10.1:6379 --num-gpus=8 --resources='{"server": 1}'
验证Ray集群状态
ray status
4.3 vLLM配置与部署
bash# 安装vLLM
pip install vllm transformers sentencepiece protobuf
创建vLLM启动脚本
cat > ~/start_vllm_service.sh << 'EOF'
#!/bin/bash
加载NCCL环境变量
source /etc/nccl.conf
设置线程亲和性
export FI_PROVIDER=mlx
export RAY_DEDUP_LOGS=0
export OMP_NUM_THREADS=36
export CUDA_DEVICE_ORDER=PCI_BUS_ID
启动vLLM OpenAI兼容服务
python -m vllm.entrypoints.openai.api_server
--model deepseek-ai/deepseek-v3-8b
--tensor-parallel-size 16
--quantization fp8
--dtype float16
--max-model-len 8192
--enforce-eager
--gpu-memory-utilization 0.9
--served-model-name deepseek
--host 0.0.0.0
--port 8000
--engine-use-ray
--ray-address auto
EOF
chmod +x ~/start_vllm_service.sh
4.4 SGLang配置与部署(可选)
bash# 安装SGLang
pip install sglang
创建SGLang启动脚本
cat > ~/start_sglang_service.sh << 'EOF'
#!/bin/bash
加载NCCL环境变量
source /etc/nccl.conf
export CUDA_DEVICE_ORDER=PCI_BUS_ID
在主节点上运行
if "$(hostname)" == "server1" ; then
python -m sglang.launch_server
--model deepseek-ai/deepseek-r1-70b
--tp-size 8
--quantization fp8
--max-tokens 8192
--max-batch-size 32
--host 0.0.0.0
--port 30000
--node-addr 192.168.10.1:30000
--worker-addr 192.168.10.2:30000
--num-nodes 2
--node-rank 0
--use-nccl
--distributed
--master
else
在从节点上运行
python -m sglang.launch_server
--model deepseek-ai/deepseek-r1-70b
--tp-size 8
--quantization fp8
--max-tokens 8192
--max-batch-size 32
--host 0.0.0.0
--port 30000
--node-addr 192.168.10.1:30000
--worker-addr 192.168.10.2:30000
--num-nodes 2
--node-rank 1
--use-nccl
--distributed
fi
EOF
chmod +x ~/start_sglang_service.sh
4.5 启动推理服务与性能测试
bash# 启动vLLM服务
./start_vllm_service.sh &
创建测试脚本
cat > test_inference.py << 'EOF'
import requests
import json
import time
import argparse
import numpy as np
def test_inference(prompt, n_tokens=100, temperature=0.7, n_samples=10):
url = "http://192.168.10.1:8000/v1/completions"
headers = {"Content-Type": "application/json"}
latencies = []
for i in range(n_samples):
payload = {
"model": "deepseek",
"prompt": prompt,
"max_tokens": n_tokens,
"temperature": temperature
}
start_time = time.time()
response = requests.post(url, headers=headers, json=payload)
end_time = time.time()
if response.status_code == 200:
result = response.json()
generated_text = result["choices"][0]["text"]
tokens = len(generated_text.split())
latency = end_time - start_time
throughput = tokens / latency if latency > 0 else 0
latencies.append(latency)
print(f"Request {i+1}: {latency:.2f}s, {throughput:.1f} tokens/s")
else:
print(f"Error: {response.text}")
if latencies:
print(f"\nAverage latency: {np.mean(latencies):.2f}s")
print(f"P90 latency: {np.percentile(latencies, 90):.2f}s")if name == "main ":
parser = argparse.ArgumentParser()
parser.add_argument("--prompt", default="人工智能在未来十年将如何改变我们的生活和工作方式?")
parser.add_argument("--tokens", type=int, default=1024)
parser.add_argument("--samples", type=int, default=10)
args = parser.parse_args()
test_inference(args.prompt, args.tokens, 0.7, args.samples)EOF
运行测试
python test_inference.py --tokens 1024 --samples 10RoCE v2链路聚合配置检查清单
使用此检查清单确保RoCE v2链路聚合配置的每个关键步骤均正确完成。在每个任务完成后打勾,并记录可能遇到的问题。
物理连接与硬件检查
- 确认所有CX4网卡已正确安装且被BIOS识别
- 使用DAC直连线缆连接对应端口(服务器1 CX4-x Px → 服务器2 CX4-x Px)
- 确认所有网口链路指示灯显示正常(通常为绿色或蓝色常亮)
- 确认服务器能识别所有L20 GPU(
nvidia-smi能显示8张卡) - 管理网络GE接口连接和IP配置正确
基础软件安装检查
- 安装Ubuntu 22.04 LTS系统并更新到最新补丁
- 安装RDMA和Bonding相关软件包:
rdma-core,ifenslave等 - 确认内核支持bonding和RDMA(
lsmod | grep bonding,lsmod | grep rdma) - 安装Mellanox OFED驱动包(版本与内核匹配)
- 验证OFED安装成功(
ofed_info -s显示"MLNX_OFED_LINUX... installed")
网卡识别与配置检查
- 确认所有CX4设备被识别(
ibv_devices显示所有设备) - 确认设备到接口映射正确(
ibdev2netdev输出映射关系) - 记录所有物理接口名称(例如:ens1f0, ens1f1, ens2f0, ens2f1)
- 确认所有物理接口状态为"UP"(
ip link show显示"state UP")
链路聚合配置检查
- 创建bonding配置(via Netplan或其他网络配置工具)
- 验证bonding模式设置为balance-xor
- 验证传输散列策略设置为layer3+4(
cat /proc/net/bonding/bond0) - 验证MTU设置为9000(
ip link show bond0显示"mtu 9000") - 验证bond0正确聚合了所有物理接口
- 验证bond0分配了正确的IP地址
- 测试bond0连通性(能ping通对端服务器的bond0 IP)
RoCE v2设置检查
- 所有CX4端口设置为RoCE v2模式(
cma_roce_mode -d mlx5_x -p y -s返回"RoCEv2") - 配置物理接口的PFC(
mlnx_qos -i <iface> --pfc_get显示正确状态) - 配置bond0接口的PFC
- 验证PFC工作正常(
perfquery不显示过多丢包) - 确认RoCE配置在重启后自动应用(服务或启动脚本)
RDMA功能验证检查
- 验证基本RDMA连接(ibv_rc_pingpong测试通过)
- 验证RDMA带宽性能(ib_write_bw测试结果>90Gbps)
- 验证RoCE v2正确工作(延迟<10微秒)
- 验证bond聚合的多链路功能(并发测试多条链路)
GPU环境与NCCL配置检查
- 安装NVIDIA驱动和CUDA(版本兼容L20)
- 启用GPU Direct RDMA(加载
nvidia-peermem模块) - 配置NCCL环境变量(指向bond0和所有物理HCA)
- 验证GPU间通信(all-reduce测试显示良好带宽)
- 确认NCCL实际使用所有链路(NCCL_DEBUG=INFO显示所有HCA)
推理平台配置检查
- 安装和配置Ray或其他集群管理工具
- 安装vLLM和/或SGLang
- 配置推理服务使用bond0和所有GPU
- 测试推理性能(能够达到预期吞吐量)
- 配置服务自动启动和健康检查
常见问题快速排查
如遇性能问题,按以下顺序检查:
-
网络带宽低于预期
- 检查MTU设置是否为9000
- 确认PFC配置正确(
mlnx_qos -i bond0 --pfc_get) - 检查bond模式和散列策略
- 查看/proc/net/bonding/bond0验证所有链路active
-
RDMA测试失败
- 确认OFED驱动安装正确
- 检查RoCE v2模式设置
- 确认bond0和物理接口的IP/MTU配置
- 检查防火墙是否阻止RDMA通信
-
GPU通信性能低
- 验证NCCL_SOCKET_IFNAME指向bond0
- 确认NCCL_IB_HCA包含所有物理HCA
- 检查nvidia-peermem是否加载
- 验证NCCL_IB_CUDA_SUPPORT=1已设置
-
链路聚合不平衡
- 检查transmit-hash-policy是否为layer3+4
- 确认mode为balance-xor而非active-backup
- 检查链路状态是否都为活跃
- 监控各链路流量分布(
cat /proc/net/bonding/bond0)
-
推理服务性能低
- 确认vLLM/SGLang配置正确使用所有GPU
- 检查tensor-parallel-size设置是否合理
- 监控GPU使用率和内存使用
- 检查KV缓存大小和批处理设置