论文阅读笔记:Adaptive Multi-Modal Cross-Entropy Loss for Stereo Matching
- [1 背景](#1 背景)
- [2 创新点](#2 创新点)
- [3 方法](#3 方法)
- [4 模块](#4 模块)
-
- [4.1 基础和问题描述](#4.1 基础和问题描述)
- [4.2 自适应多模态概率模型](#4.2 自适应多模态概率模型)
- [4.3 主模态视差估计器](#4.3 主模态视差估计器)
- [5 效果](#5 效果)
- [6 结论](#6 结论)
1 背景
尽管深度学习在立体匹配方面取得了巨大成功,但恢复准确的视差图仍然具有挑战性。目前,L1 和交叉熵是立体网络训练中使用最广泛的两种损失。与前者相比,后者通常表现更好,这要归功于它的概率建模和对成本量的直接监督。然而,如何准确模拟交叉熵损失的立体真实值在很大程度上仍未得到充分探索。现有的工作只是假设 GT 分布是单模态的,这忽略了大多数边缘像素可以是多模态的事实。
立体匹配作为计算机视觉领域一个由来已久且活跃的话题,在自动驾驶和虚拟现实等广泛应用中发挥着至关重要的作用。虽然传统方法在处理光照变化和弱纹理方面的可靠性较差,但基于学习的立体方法在这些复杂场景中显示出其优越性。
立体匹配通常被视为深度学习中的回归任务。在这些工作中,L1 损失用于训练,然后是 soft-argmax 估计器来预测亚像素视差。L1 loss 的主要问题是它缺乏对成本量的直接监督,因此容易出现过拟合。此外,soft-argmax 基于以下假设:输出分布是单峰的,并且以真实值为中心,这并不总是正确的,特别是对于具有模糊深度的边缘像素。如图 1a 所示,边缘像素上的 soft-argmax 存在严重的过度平滑问题,导致边缘出现渗色伪影。

另一条研究线将立体匹配视为分类任务,其中可以使用交叉熵损失。为了指导网络输出单峰分布,研究人员使用离散的拉普拉斯分布或高斯分布对真实视差进行建模。单模态视差估计器 (SME)进一步用于从预测分布中提取正确的模态。交叉熵损失可以直接监督成本量的学习,从而取得比 L1 损失更好的结果。然而,单模态模式的执行似乎并不那么有效,图 1b 中存在的错位伪影证明了这一点。
本文的工作旨在探索更好的立体GT建模并改进视差估计器。与以前对成本量施加单模态约束的工作相反,作者认为边缘像素应该自然地建模为多模态分布。在图像捕获过程中,边缘像素从不同深度的多个物体中收集光线,这意味着边缘像素的深度本身就带有歧义。强制网络在所有区域学习单模态模式可能会令人困惑和误导,从而导致边缘和非边缘像素的错误估计。因此,非常需要一个更好的概率模型来编码每个像素的真实模式。
2 创新点
(1)提出了一种新的自适应多模态交叉熵损失 (ADL) 来指导网络学习每个像素的不同分布模式。
(2)优化了视差估计器,以进一步减轻推理中的渗色或错位伪影。
(3)提出了一种用于训练立体网络的自适应多模态交叉熵损失。它可以有效引导网络学习清晰的分布模式并抑制异常值
(4)提出了一种主模态视差估计器,可以在多模态输出上获得准确的结果
3 方法
在本文中,提出了像素的自适应多模态分布模型,并将其集成到交叉熵损失中以进行网络训练。作者在每个像素的局部窗口内应用视差聚类以获得所需数量的模态。然后采用拉普拉斯分布对每个簇进行建模。作者进一步依靠窗口内的局部结构信息来确定每个模态的相对权重,从而最终确定交叉熵损失的拉普拉斯混合。此外,提出了一种主模态视差估计器(DME),以更好地解决网络多模态输出带来的困难。对公共数据集的大量实验结果表明,本文的方法是通用的,可以帮助经典立体网络重新获得最先进的性能。图1中的比较结果例证了本文的方法的显着改进。此外,本文的方法实现了出色的跨域泛化性能,并对稀疏的GT表现出更高的鲁棒性。
4 模块
4.1 基础和问题描述
给定校准的立体图像对,立体匹配的目的是为左图像中的每个像素找到右图像中对应的像素。基于成本量的立体声网络遵循通用工作流13。首先,分别通过权重共享 2D CNN 模块提取左右图像的特征。然后根据获得的两个特征块构建 4D 成本体积。成本聚合模块将此 4D 体积作为输入,输出大小为 D × H × W D×H×W D×H×W 的分布体积,其中 D 是视差搜索的最大范围,H 和 W 分别是输入图像的高度和宽度。然后沿着视差维度应用 Softmax 算子来标准化每个像素的概率分布 p(·)。最后,通过全带加权平均操作来估计得到的视差 d ^ \hat{d} d^ ,也称为 soft-argmax。
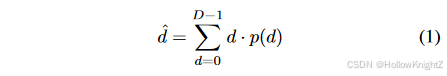
为了训练立体网络,可以采用基于回归的平滑 L1 损失:
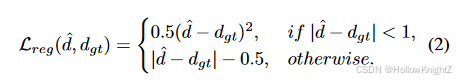
其中, d g t d_{gt} dgt 是视差真值。
在这个工作流中,分布量是由平滑的L1损失间接监督的,这阻碍了最终的性能。通过将立体匹配视为分类任务,交叉熵损失提供了对分布体的直接监督,如:

新问题是式-3中的真实分布 p g t ( ⋅ ) p_{gt}(·) pgt(⋅) 不存在。现有的工作简单地将 p g t ( ⋅ ) p_{gt}(·) pgt(⋅) 建模为以 d g t d_{gt} dgt 为中心的单峰拉普拉斯或高斯分布。然而,这些简单的模型似乎无法对不同的图像区域(尤其是边缘)施加足够的监督。如图2所示,边缘像素的训练损失仍然远大于非边缘像素,表明这些区域的学习难度。

对所得输出分布体的进一步统计(详细信息见表3)表明,超过一半的边缘和部分非边缘像素实际上分配了多个模态,这与伪真值的单模态假设相冲突。这些不需要的多模态输出直接导致对象边缘上的未对准伪影和非边缘区域上的异常值,如图 1b 所示。因此,作者认为问题的根源在于对所有领域的真实情况的单模态建模不恰当。事实上,边缘像素聚合了来自不同深度的多个物体的光度信息,这意味着边缘像素的强度本质上是不明确的。在整个图像上施加单峰分布模式不仅会导致边缘像素的学习困难,而且还会混淆非边缘像素的学习。
4.2 自适应多模态概率模型
受到上一节观察的启发,作者致力于探索更好的交叉熵损失的真实概率模型。作者认为边缘像素的概率分布应该由多个模态组成,每个模态对应于特定的深度/视差。为此,提出了一种自适应多模态GT建模方法。作者的想法是为边缘像素上的每个潜在深度生成单独的拉普拉斯分布,然后将它们融合在一起以构造拉普拉斯混合。作者参考每个像素的邻域来完成任务,如 图3 所示。
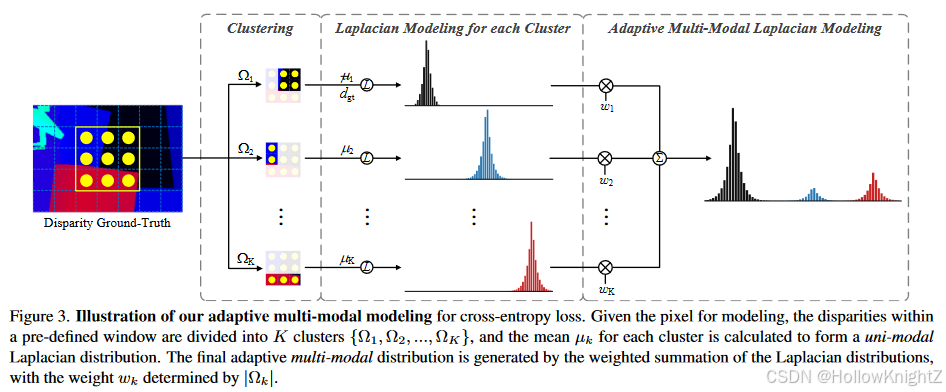
对于标有真实视差的每个像素,考虑以它为中心的 m × n m×n m×n 局部窗口。然后,通过 DBScan 聚类算法将窗口内的整组视差值分为 K ( K ≥ 1 ) K(K≥1) K(K≥1) 个不相交子集 { Ω 1 , Ω 2 , . . . , Ω K } \{Ω_1, Ω_2, ..., Ω_K\} {Ω1,Ω2,...,ΩK} ,每个簇对应不同的潜在深度。在 DBScan 中,手动设置距离阈值 ε ε ε 和密度阈值 m i n P t s minP_{ts} minPts 以调整生成的聚类数量。这种聚类方法具有以下优点:
(1)不需要预先定义聚类的数量
(2)K=1可以视为无边缘的指标
(3)对于具有连续但变化深度的倾斜平面是鲁棒的
然后可以将每个像素的真实分布建模为拉普拉斯算子的混合:
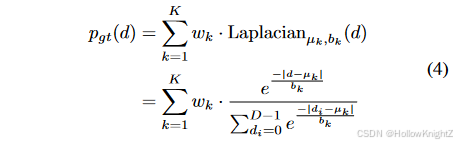
其中拉普拉斯算子在视差候选 d ∈ { 0 , 1 , . . . , D − 1 } d∈\{0, 1, ..., D−1\} d∈{0,1,...,D−1} 上进行离散化和归一化, μ k μ_k μk 、 b k b_k bk 和 w k w_k wk 分别是第 k 个拉普拉斯分布的平均值、尺度和权重参数。 μ k μ_k μk 设置为簇 Ω k Ω_k Ωk 内视差的平均值。定义 Ω 1 Ω_1 Ω1 包含要建模的中心像素, μ 1 μ_1 μ1 被中心像素的ground-truth替代,以确保监督的准确性。权重 w k w_k wk 旨在调整获得的多个模态的相对比例,并且可以基于窗口内的局部结构来分配。将 Ω k Ω_k Ωk 的基数作为局部结构的指标,例如较小的 ∣ Ω k ∣ |Ω_k| ∣Ωk∣ 对应于更薄的结构,其重量相应地应该更小。最后, w k w_k wk 定义为:

其中 α α α 是中心像素的固定权重。作者设置 α ≥ 0.5 α≥0.5 α≥0.5 以确保ground-truth模态的主导地位。其余 ( 1 − α ) (1 − α) (1−α) 权重平均分配给其余 ( m n − 1 ) (mn − 1) (mn−1) 个相邻像素。对于像 KITTI 这样具有稀疏真实值的数据集,仅计算本地窗口内的有效视差,并在式-5中的 m n mn mn 替换为 ∑ k = 1 K ∣ Ω k ∣ \sum^K_{k=1}|Ω_k| ∑k=1K∣Ωk∣ 。对于窗口内只有一个簇的非边缘像素, w 1 w_1 w1 等于1,式-4退化为单峰拉普拉斯分布。
4.3 主模态视差估计器
通过交叉熵损失训练的立体网络通常会产生比L1损失更多的多模态输出,因此需要更好的视差估计器。SME 通过仅在"最有可能"模态内聚合视差来缓解过度平滑问题,但仍然受到由错误模态选择引起的失调伪影的影响。与单模态损失相比,本文的新损失鼓励网络在边缘处产生更多的多模态模式。因此,一个增强的视差估计器成为必须的,以解决本文的方法引入的复杂性。
SME首先以最大概率密度定位视差候选,然后分别向左和向右遍历,直到概率停止下降,从而确定视差估计的主导模态 d l , d r d_l , d_r dl,dr 的范围。然而,这种像素级的赢者通吃策略对输出分布中能产生尖锐和狭窄模态的噪声非常敏感。
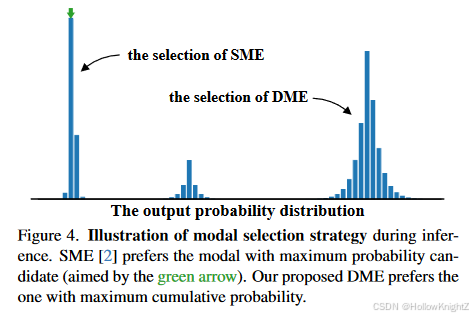
作者提出了DME来解决这个问题,如图4所示。具体来说,从多模态输出中分离出每个模态,并分别计算它们的累积概率。每个模态对应一个具有特定深度的潜在匹配对象,模态的累积概率反映了该对象的匹配可能性。因此,采用对象级 的赢者通吃策略,即选择累积概率最大的模态作为主导模态。然后将所选模态归一化为:

最后,式-1用 p ˉ ( d ) \bar{p}(d) pˉ(d) 代替 p ( d ) p(d) p(d) 来估计视差。
5 效果
PSMNet使用本文方法的消融实验可见表1。

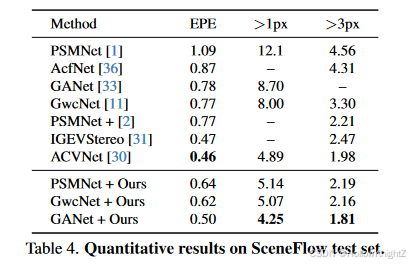
在SceneFlow测试集不同SOTA模型的效果可见表4。
在SceneFlow数据集的可视化效果可见图6。

6 结论
大量的实验结果表明,本文的方法是通用的,可以帮助经典立体声网络重新获得最先进的性能。特别是,使用本文方法的 GANet 在 KITTI 2015 和 2012 基准中均排名第一。同时,只需用本文的损失替换传统的损失,就可以实现出色的综合到现实的泛化性能。