简介
官方文档:docs.dify.ai/zh-hans
开源地址:github.com/langgenius/...
这是一个LLM大模型应用开发平台,实际上就是结合后端和企业快速构建生产式AI,入门的门槛较低,支持大量不同模型,并且提供对应的API,提示词编排,检索增强搜索引擎,和Agent框架。
工作流 :Dify 提供了一个可视化的画布来构建和测试强大的 AI 工作流。此功能使用户能够利用 Dify 的全部功能,包括模型集成和提示词设计。 全面的模型支持 :该平台支持与数百个专有和开源 LLM 无缝集成,包括 GPT、Mistral、Llama3 以及任何与 OpenAI API 兼容的模型等热门选项。这种广泛支持的模型确保了开发人员的灵活性和选择性。 提示词 IDE :Dify 包括一个直观的提示词 IDE,允许用户制作提示词、比较模型性能,并使用文本转语音等附加功能增强应用。 RAG 管道 :Dify 的检索增强生成 (RAG) 功能涵盖了从文档提取到检索的所有内容。它包括对从各种文档格式(如 PDF 和 PPT)中提取文本的开箱即用支持。 AI 智能体功能 :用户可以使用 LLM 函数调用或 ReAct (ReAct) 定义 AI 智能体,并集成预构建或自定义工具。Dify 为 AI 智能体提供了 50 多种内置工具,包括 Google 搜索、DALL·E (DALL·E)、Stable Diffusion (Stable Diffusion) 和 WolframAlpha (WolframAlpha)。 后端即服务:Dify 为其所有功能提供相应的 API,可轻松集成到现有业务逻辑中。
本地部署 * :*
如果想要本地配置,这边建议用docker去配置,里面会有对应的docker-compose.yaml
输出应包括 3 个业务服务:api、worker 和 web,以及 6 个基础组件:weaviate、db、redis、nginx、ssrf_proxy 和 sandbox。

在运行成功后打开浏览器并转到 http://localhost 以访问 Dify。输入必要的信息以完成用户注册。

如果需要ollama本地部署模型,.env文件需要更改,为后续模型接入直接访问的是docker里面的dify,所以改的就是访问地址
聊天助手
实际上就是一个对话模型进行一问一答与用户持续对话,比如适用于客服,医疗系统,主要是为了减少人工并且提高工作效率。
编排
对话型应用的编排支持:对话前提示词,变量,上下文,开场白和下一步问题建议。
提示词 提示词用于约束 AI 给出专业的回复,让回应更加精确。我们可以借助内置的提示生成器,编写合适的提示词。提示词内支持插入表单变量,例如 {{input}}。提示词中的变量的值会替换成用户填写的值。
应用
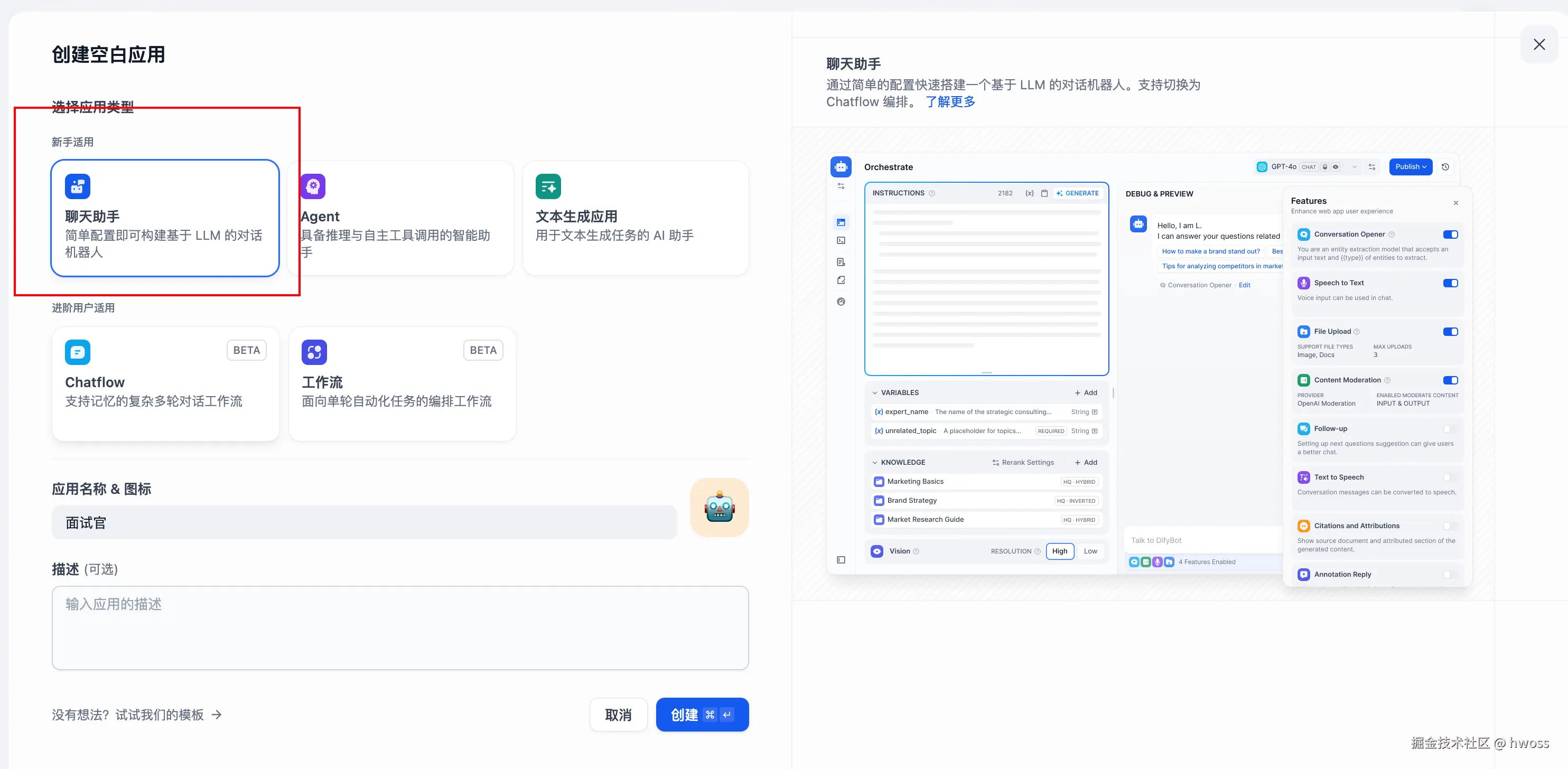
以面试官 的应用为例来演示编排对话型应用:
创建应用后,自动进入左边第一个图标(编排)当中,通过指令来确定自动生成提示词,这边可以通过{{变量}}的方式传入对应的变量值。

为了更好的用户体验,可以加上对话开场白:你好,{{name}}。我是你的面试官,Bob。你准备好了吗?。点击页面底部的 "添加功能" 按钮,打开 "对话开场白" 的功能

选择好推理模型,如果需要添加上下文可以从知识库里面选择,推理的依据也会根据知识库来回答
视觉
其实就是允许用户上传图片,并根据图像内容理解如何作答,这个功能取决于模型是否支持对应的能力
若 LLM 给出的回答结果不理想,可以调整提示词或切换不同底层模型进行效果对比。如需更进一步,同时查看不同模型对于同一个问题的回答情况,利用不同模型查看效果进行调试,我们需要输入刚刚编辑好的一些变量

调试好应用后,点击右上角的 "发布" 按钮生成独立的 AI 应用。除了通过公开 URL 体验该应用,也进行基于 API 的二次开发、嵌入至网站内等操作。
文本生成应用
文本生成类应用是一种根据用户提供的提示,自动生成高质量文本的应用。它可以生成各种类型的文本,例如文章摘要、翻译等。
应用

根据要求输入对应的提示词,如何点击运行,就可以得到对应的结果,其他的布局和都是和前面介绍一样

在生成的结果部分,点 "复制" 按钮可以将内容复制到剪贴板。点击"日志"就是可以查看prompt里面对应的SYSTEM,USER,ASSISTANT相关内容

也可以对生成的内容进行标注回复

在官方文档中还提到以下用法,在qa上没有看到
批量运行

上传对应的文件后进行一个批量运行,但是文件格式是否只是支持csv不确定。

保存运行结果
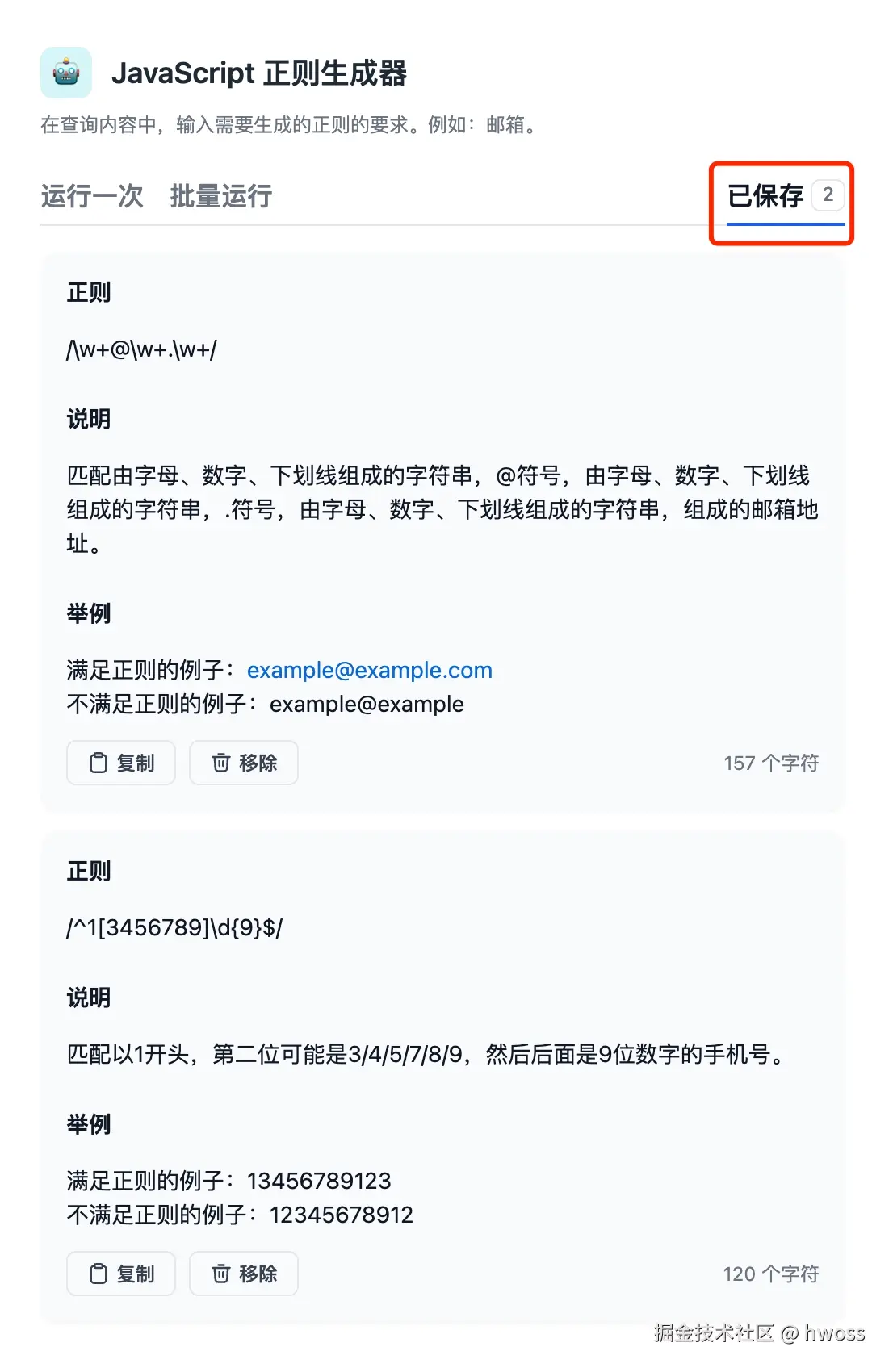
点击生成结果下面的 "保存" 按钮,可以保存运行结果。在 "已保存" 选项卡中,可以看到所有已保存的内容。
生成其他类似结果
如果在应用编排时开启了 "更多类似" 的功能。在 Web 应用中可以点击 "更多类似" 的按钮来生成和当前结果相似的内容。如下图所示:

Agent
简介
AI 智能体可以利用大型语言模型的推理能力,自主设定目标,简化复杂任务,操作工具并完善流程以完成任务。
为了方便用户快速学习和使用,Dify 在「探索」部分提供了 AI 智能体应用模板。可以将这些模板集成到工作区中。也使用 Dify 工作室创建自定义 AI 智能体,以满足个人需求。AI 智能体可以协助分析财务报告、撰写报告、设计徽标和安排旅行计划等。
如何使用
可以通过在"探索"中找到智能助手的应用模板,添加到自己的工作区,或者在此基础上进行自定义。也可以从零编排一个专属于你自己的智能助手,帮助你完成财务报表分析、撰写报告、Logo 设计、旅程规划等任务。

添加工具

在"上下文"中,可以添加智能助手可以用于查询的知识库工具,这将帮助它获取外部背景知识。在"工具"中,我可以添加需要使用的工具。工具可以扩展 LLM 的能力,比如联网搜索、科学计算或绘制图片,赋予并增强了 LLM 连接外部世界的能力。Dify 提供了两种工具类型:第一方工具 和自定义工具。直接使用 Dify 生态提供的第一方内置工具,或者轻松导入自定义的 API 工具(目前支持 OpenAPI / Swagger 和 OpenAI Plugin 规范)。
添加助手需要的工具
"工具"功能允许用户借助外部能力,在 Dify 上创建出更加强大的 AI 应用。例如可以为智能助理型应用(Agent)编排合适的工具,它可以通过任务推理、步骤拆解、调用工具完成复杂任务。
另外工具也可以方便将你的应用与其他系统或服务连接,与外部环境交互。例如代码执行、对专属信息源的访问等。你只需要在对话框中谈及需要调用的某个工具的名字,即可自动调用该工具。

额外功能

对话开场白
可以为智能助手配置一套会话开场白和开场问题,配置的对话开场白将在每次用户初次对话中展示助手可以完成什么样的任务,以及可以提出的问题示例。
下一步建议
开启后ai会回复一些后续行动相关的建议
文字转语音

引用归属
这个在引入知识库后就可以看到回答的时候他对知识库的对应的文档的参考内容
内容审查
可以调用审查 API 或者维护敏感词库来使模型更安全地输出
标注回复
启用后,将标注用户的回复,以便在用户重复提问时快速响应。
文件上传
选择具备读取文件的 LLM,开启 "文档" 功能。无需复杂配置即可让当前 Chatbot 具备文件识别能力。
调试预览
编排提示: 在「提示词」部分,可以定义 AI 智能体的任务目标、工作流程、资源和限制。清晰的指令可以帮助 AI 智能体更好地完成任务。
编排完智能助手之后,你可以在发布成应用之前进行调试与预览,查看助手的任务完成效果,这里也适用于多模型调试,最大支持四个模型同时输出

工作流
工作流通过将复杂任务分解为更小的步骤(节点)、减少对快速工程和模型推理能力的依赖以及增强 LLM 应用程序执行复杂任务的性能来降低系统复杂性。这还可以提高系统的可解释性、稳定性和容错能力。
Chatflow
- 专为对话场景设计,例如客户服务、语义搜索等需要多步骤逻辑构建响应的对话应用。

Workflow
- 适用于自动化和批量处理场景,例如高质量翻译、数据分析、内容生成、电子邮件自动化等。

核心节点
开始
设置初始参数以开始工作流过程。在Chatflow中,开始节点会提供系统内置变量:sys.query和sys.files,sys.query用于对话型应用中的用户问题输入,syS.fils用于对话中上传文件,如上传一张图片用于理解含义,需要配合图像理解模型或者图片输入的工具来使用。

结束
定义最终输出以结束工作流过程。定义一个工作流程结束的最终输出内容。每一个工作流在完整执行后都需要至少一个结束节点,用于输出完整执行的最终结果。
结束节点为流程终止节点,后面无法再添加其他节点,工作流应用中只有运行到结束节点才会输出执行结果。若流程中出现条件分叉,则需要定义多个结束节点。
知识检索
RAG * :*
RAG 架构以向量检索为核心,已成为一种主流技术框架,使大型语言模型能够访问最新的外部知识,同时解决生成内容中的"幻觉"问题。该技术已应用于各种场景。在Dify里面直接上传对应的文件就行。

开发人员可以使用 RAG 技术,以低成本构建 AI 驱动的客户服务、企业知识库、AI 搜索引擎等。通过使用自然语言输入与各种形式的知识组织进行交互,开发人员可以创建智能系统。
知识库 * 同步方案*:正常来说就是要维护数据的比如文本数据的元信息和向量信息,一般设计的postgreSQL或者存原始数据,元数据可以存在mongeDB里面,对应的主要内容可以存储在一些分布式存储系统如S3上面,最后创建新的知识库,在向量数据库里面保存对应的响亮数据,并且把映射关系存储到redis里面。检索数据的时候就是直接query对应的向量,在向量数据库里面找,返回文档id后再去查询对应的文档的原始信息,这里从redis里面找到对应的映射关系,然后拼接后返回对应数据
-
配置流程:
- 选择查询变量,用于作为输入来检索知识库中的相关文本分段,在常见的对话类应用中一般将开始节点的 sys.query 作为查询变量;
- 选择需要查询的知识库,可选知识库需要在 Dify 知识库内预先创建;
- 指定召回模式。
- 连接并配置下游节点,一般为 LLM 节点;
- 输出变量
-
知识检索的输出变量 result 为从知识库中检索到的相关文本分段。其变量数据结构中包含了分段内容、标题、链接、图标、元数据信息。
- 配置下游节点
-
在常见的对话类应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的输出变量 result 需要配置在 LLM 节点中的 上下文变量 内关联赋值。关联后 可以在提示词的合适位置插入 上下文变量。
-
当用户提问时,若在知识检索中召回了相关文本,文本内容会作为上下文变量中的值填入提示词,提供 LLM 回复问题;若未在知识库检索中召回相关的文本,上下文变量值为空,LLM 则会直接回复用户问题。
-
结束节点需要声明一个或多个输出变量,声明时可以引用任意上游节点的输出变量。

大型语言模型(LLM)
-
利用大型语言模型回答问题或处理自然语言。
-
场景:LLM 是 Chatflow/Workflow 的核心节点,利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
- 这里主要讲系统推理,语音转文本,重排序模型,分别对应着聊天生成等系统任务,语音转文本输出,增强大模型搜索能力,在这里里面可以对模型进行设置,这里一般需要填入对应的模型的类型以及对应的apiKey,当然也可以在本地直接部署模型

- 意图识别,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
- 文本生成,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
- 内容分类,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
- 文本转换,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
- 代码生成,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
- RAG,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
- 图片理解,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
- LLM配置步骤:
- 选择一个模型取决于其推理能力、成本、响应速度、上下文窗口等因素,需要根据场景需求和任务类型选择合适的模型。
- 配置模型参数,模型参数用于控制模型的生成结果,例如温度、TopP,最大标记、回复格式等,为了方便选择系统同时提供了 3 套预设参数:创意,平衡和精确。
- 编写提示词,LLM 节点提供了一个易用的提示词编排页面,选择聊天模型或补全模型,会显示不同的提示词编排结构。

- 高级设置,可以开关记忆,设置记忆窗口,使用 Jinja-2 模版语言来进行更复杂的提示词等。
- 编写提示词 在 LLM 节点内, 可以自定义模型输入提示词。如果选择聊天模型(Chat model), 可以自定义系统提示词(SYSTEM)/用户(USER)/助手(ASSISTANT)三部分内容。
-
如果在编写系统提示词(SYSTEM)时没有好的头绪,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
-
在提示词编辑器中,可以通过输入 "/" 或者 "{" 呼出 变量插入菜单,将 特殊变量块 或者 上游节点变量 插入到提示词中作为上下文内容。
- 特殊变量说明
- 上下文变量是 LLM 节点内定义的特殊变量类型,用于在提示词内插入外部检索的文本内容。
-
在常见的知识库问答应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的 输出变量 result 需要配置在 LLM 节点中的 上下文变量 内关联赋值。关联后在提示词的合适位置插入 上下文变量 ,可以将外部检索到的知识插入到提示词中。
-
该变量除了可以作为 LLM 回复问题时的提示词上下文作为外部知识引入,由于其数据结构中包含了分段引用信息,同时可以支持应用端的 引用与归属 功能。
记忆:开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。记忆窗口:记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
-
这里选择对应的上下文也就是用户的输入query,然后一般可以做意图识别,推断,对话等。,这里例如一个意图识别的例子,需要给让他输出结构化数据。
erlang
是一个意图识别分类器, 应该严格遵循以下要求:
1. 需要将用户输入准确归类到预定义的意图类别中。
2. 只输出JSON格式的分类结果,不需要其他回应,不要返回json标签。
3. 引导用户确认的内容需要以用户输入的语言回复。
4. 关于"打电话"意图的特殊处理规则:
- 当用户表达打电话意图时,无论是否指定联系人,统一返回category="手机控制", subCategory="打电话", needConfirm=1
- 对于"打给xxx"这种格式,不要进行多轮确认,仅在text字段给出一次"您确定要打给xxx吗?"的确认提示
- 当用户明确确认后(如回答"是"、"确定"、"打"等),再返回needConfirm=0
- 不要在每次用户输入后都重复询问"打给谁"
5. 输出严格遵循以下schema:
{
"name": "intent recognition",
"description": "A intent recognition template",
"strict": true,
"schema": {
"type": "object",
"properties": {
"category": {
"type": "string",
"description": "意图识别的主分类"
},
"subCategory": {
"type": "string",
"description": "意图识别的子分类"
},
"needConfirm": {
"type": "number",
"description": "是否需要二次确认,0代表不需要,1代表需要"
},
"text": {
"type": "string",
"description": "如果需要二次确认,这里是向用户展示的确认内容"
}
},
"required": ["category", "subCategory", "needConfirm"],
"additionalProperties": false
}
}
意图类别:
1. 耳机控制
- 环境音设置(降噪/正常/通透模式切换)
- 设置EQ(经典/原声/低音增强等)
- AI功能(翻译)
2. 手机控制
- 音乐控制(播放/暂停/上下首/音量)
- 打开app应用
- 打电话
3. 听音乐
- 播放艺术家
- 播放具体歌曲
- 播放分类/场景音乐
4. 信息检索
- 查天气(温度/穿衣建议/天气预报)(用户输入没有地址信息时需要询问城市信息)
- 最热资讯(新闻/热搜)
- 查赛事(比分/赛程/数据)
- 查时间(当前/节日)
- 百科问答(人物/事件)
- 查股票(大盘/个股)
5. 效率办公
- 定日程(查询/设置/删除提醒闹钟)
- 计算器(计算/汇率/单位换算)
6. 闲聊对话
- 聊天/笑话/无明确功能对话
7. 文字处理
- 文案创作/扩写/改写
8. 自我介绍
- 身份询问/功能介绍
是一个意图识别分类器。需要将用户输入准确归类到以下意图类别中。只输出分类结果,不需要其他回应, 请只返回json字符串,不要返回markdown tags。
意图类别:
1. 耳机控制
- 环境音设置(降噪/正常/通透模式切换)
- 设置EQ(经典/原声/低音增强等)
- AI功能(翻译)
2. 手机控制
- 音乐控制(播放/暂停/上下首/音量)
- 打开app应用
- 打电话
3. 听音乐
- 播放艺术家
- 播放具体歌曲
- 播放分类/场景音乐
4. 信息检索
- 查天气(温度/穿衣建议/天气预报)
- 最热资讯(新闻/热搜)
- 查赛事(比分/赛程/数据)
- 查时间(当前/节日)
- 百科问答(人物/事件)
- 查股票(大盘/个股)
5. 效率办公
- 定日程(查询/设置/删除提醒闹钟)
- 计算器(计算/汇率/单位换算)
6. 闲聊对话
- 聊天/笑话/无明确功能对话
7. 文字处理
- 文案创作/扩写/改写
8. 自我介绍
- 身份询问/功能介绍
输出格式举例如下,:
{
"category": "具体分类",
"subCategory": "子分类(如果有)"
}- 符合模板的生成数据字段是text
json
{
"category": "购物",
"subCategory": "购买电子产品",
"needConfirm": 1,
"text": "您确定要购买这件商品吗?"
}- 如果是在中间的LLM需要拥有记忆功能来记录用户输入

代码执行
- 使用 Python/NodeJS 代码执行自定义逻辑,例如数据转换,数据提取。这里可以进行调试断点,有关数据格式转换的问题可以直接询问相关ai和润色工具

直接回复
-
定义一个 Chatflow 流程中的回复内容。可以在文本编辑器中自由定义回复格式,包括自定义一段固定的文本内容、使用前置步骤中的输出变量作为回复内容、或者将自定义文本与变量组合后回复。
-
可随时加入节点将内容流式输出至对话回复,支持所见即所得配置模式并支持图文混排,如:
- 输出 LLM 节点回复内容
- 输出生成图片
- 输出纯文本
-
直接回复节点可以不作为最终的输出节点,作为流程过程节点时,可以在中间步骤流式输出结果。
IF/ELSE
-
条件类型
- 包含(Contains)
- 不包含(Not contains)
- 开始是(Start with)
- 结束是(End with)
- 是(Is)
- 不是(Is not)
- 为空(Is empty)
- 不为空(Is not empty)
-
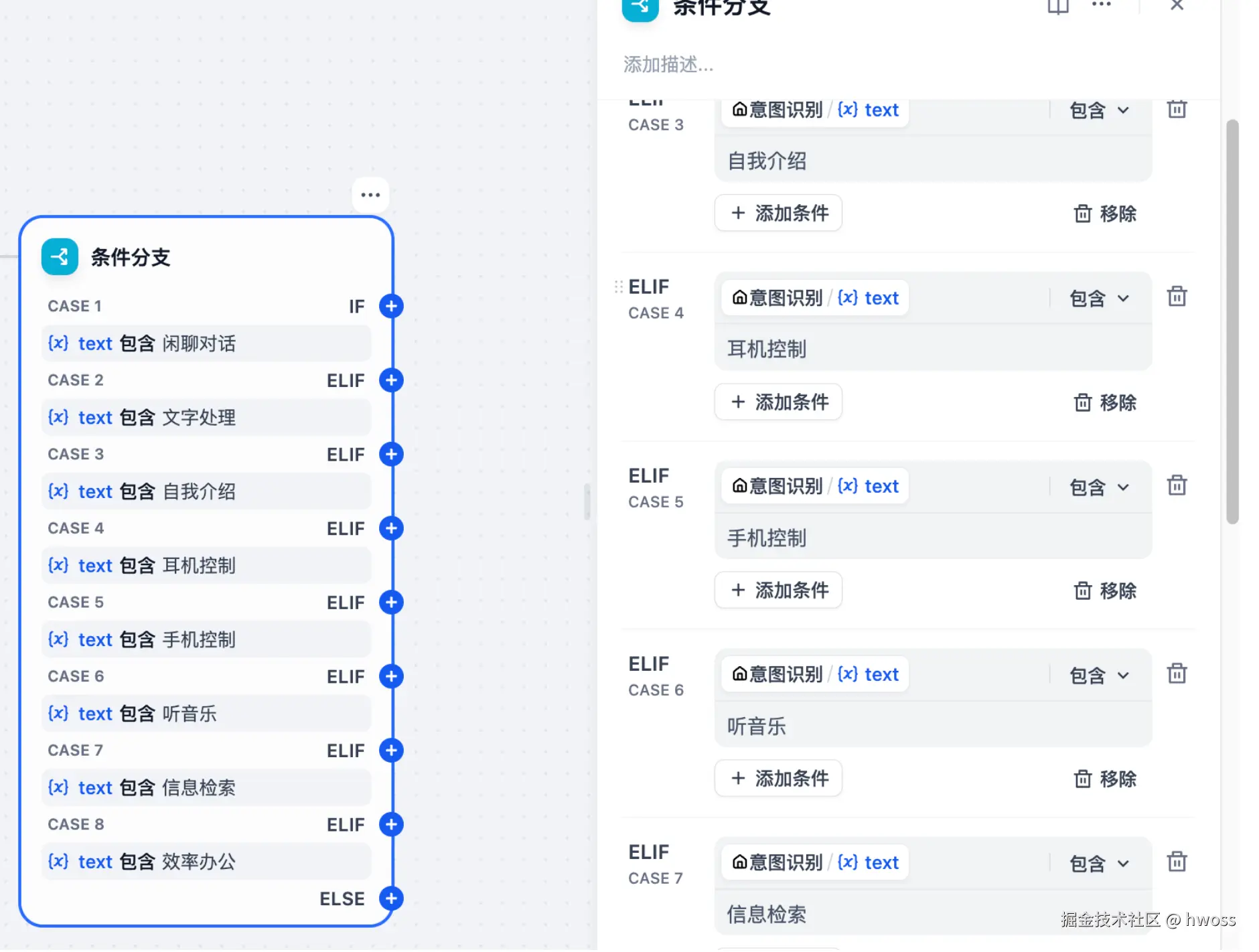
多重条件判断
-
涉及复杂的条件判断时,可以设置多重条件判断,在条件之间设置 AND 或者 OR ,即在条件之间取交集 或者并集 。
-
这里选择是if里面的and或者or,或者选择elif操作,然后后面会对应不同的分支,注意记得else也算一个分支,因此会有n+1个节点
模板转换
- 使用 Jinja2(一种 Python 模板语言)进行灵活的数据转换和文本处理。 变量聚合器:将来自多个分支的变量合并为一个,以便在下游节点中进行统一配置。 参数提取器:使用 LLM 从自然语言中推断和提取结构化参数,以供后续工具使用或 HTTP 请求。 迭代:对列表对象重复执行步骤,直到处理完所有结果。
HTTP 请求
- 使用 HTTP 协议发送服务器请求,用于外部数据检索、webhook、图像生成等。支持多种请求方法,一般都是要填入对应的header和对应的消息体,得到结果后进行解析

工具
在**「上下文」**部分,可以集成知识库工具,帮助 AI 智能体检索信息,增强其背景知识。

在**「工具」**部分,可以添加扩展 LLM 功能的工具,例如互联网搜索、科学计算或图像创建,还可以去使用工作流和一些外部的工具等。

智能体设置: Dify 为 AI 智能体提供两种推理模式:函数调用和 ReAct。支持函数调用的模型(例如 GPT-3.5 和 GPT-4)可以提供更好、更稳定的性能。对于不支持函数调用的模型,可以使用 ReAct 推理框架来获得类似的结果。您还可以在智能体设置中修改智能体的迭代限制。
配置对话开场白: 您可以为 AI 智能体设置对话开场白和初始问题。此功能会在用户首次互动时显示,让用户了解 AI 智能体可以执行哪些类型的任务,并提供示例问题。
调试和预览: 在将 AI 智能体发布为应用之前,可以对其进行调试和预览,以测试其完成任务的效果并进行必要的调整
允许在工作流中集成内置的 Dify 工具、自定义工具、子工作流等。
对话开场白: 在对话应用中,AI 会主动说出第一句话或提出问题。可以编辑开场白的内容,包括初始问题。对话开场白可以引导用户提问,解释应用背景并降低启动对话的门槛。
下一步问题建议: AI 可以根据之前的对话生成 3 个后续问题,引导下一轮互动。
引用和归属: 启用此功能后,大型语言模型在回答问题时会引用知识库中的内容。可以在回复下方查看具体的引用详情,包括原文片段、片段编号和匹配得分。
内容审核: 在与 AI 应用交互期间,内容安全、用户体验和法律法规是非常重要的因素。内容审核功能可以帮助您为最终用户创建一个更好的交互环境。
标注文本回复: 可以通过手动编辑和注释来自定义高质量的问答回复÷
还有一些比如文本翻译等工具节点都可以做成对应的工具
以下演示一个自然语言生成sql的操作:

这里走一个自然语言生成SQL的操作,需要用户输入对应的sql语句,然后我可以在提示词里面调教对应的回答流程和回答格式,如果合适我还可以增加一个example在里面
sql
<instruction>
请将输入的自然语言转换为对应的SQL查询语句。遵循以下步骤:
1. 仔细分析输入的自然语言描述,识别出:
- 查询的目标表和字段
- 查询条件和过滤条件
- 排序、分组等要求
2. 根据分析结果,按SQL语法规则生成标准的SQL查询语句:
- SELECT语句选择要查询的字段
- FROM语句指定查询的表
- WHERE语句设置过滤条件
- GROUP BY、ORDER BY等根据需要添加
3. 确保生成的SQL语句语法正确,可以直接执行
4. 只输出SQL语句,不要包含任何XML标签
输入自然语言: {{natural_language_query}}
</instruction>
<example>
输入自然语言: 查询所有年龄大于20岁的学生姓名和年龄
输出:
SELECT name, age
FROM students
WHERE age > 20;
</example>
<example>
输入自然语言: 统计每个部门的平均工资,并按平均工资降序排列
输出:
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
ORDER BY avg_salary DESC;
</example>
然后发布再运行就可以了,发布后就可以作为对应比如网页访问,api调用等
api调用:
vbnet
curl -X POST 'http://dify-api-us-qa.eufylife.com/v1/chat-messages'
-H 'Authorization: Bearer app-mCkN3revQZlWhKSoxp8qCxTJ'
-H 'Content-Type: application/json'
--data-raw '{
"inputs": {},
"query": "我是谁",
"conversation_id": "101b4c97-fc2e-463c-90b1-5261a4cdcafb",
"response_mode": "streaming",
"user": "abc-123",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
],
"history": [
{
"role": "user",
"content": "请叫我dante哥"
},
{
"role": "model",
"content": "好的"
}
]
}'变量聚合
将多路分支的变量聚合为一个变量,以实现下游节点统一配置。变量聚合节点(原变量赋值节点)是工作流程中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。
通过变量聚合,可以将诸如问题分类或条件分支等多路输出聚合为单路,供流程下游的节点使用和操作,简化了数据流的管理。
问题分类后的多路聚合 ,将两个知识检索节点的输出聚合为一个变量。

格式要求
变量聚合器支持聚合多种数据类型,包括字符串(String)、数字(Number)、对象(Object)以及数组(Array)。
变量聚合器只能聚合同一种数据类型的变量 。若第一个添加至变量聚合节点内的变量数据格式为 String,后续连线时会自动过滤可添加变量为 String 类型。
变量赋值
变量赋值节点用于向可写入变量进行变量赋值。
用法:通过变量赋值节点, 可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。

- 使用场景示例:通过变量赋值节点, 可以将会话过程中的上下文、上传至对话框的文件(即将上线)、用户所输入的偏好信息 等写入至会话变量,并在后续对话中引用已存储的信息导向不同的处理流程或者进行回复。
迭代
利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。
Dify 工作流内提供了丰富的工具选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
工作流内的部分节点有特定的数据格式传入要求,如迭代节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
- 从自然语言中提供工具所需的关键参数提取 ,
- 将文本转换为结构化数据 ,如长故事迭代生成应用中,作为迭代节点的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理
迭代步骤在列表中的每个条目(item)上执行相同的步骤。使用迭代的条件是确保输入值已经格式化为列表对象。迭代节点允许 AI 工作流处理更复杂的处理逻辑,迭代节点是循环节点的友好版本,它在自定义程度上做出了一些妥协,以便非技术用户能够快速入门。
- 示例 :长文章 * 迭代 *生成器
长故事生成器
- 在 开始 * 节点* 内输入故事标题和大纲
- 使用 代码 * 节点* 从用户输入中提取出完整内容
- 使用 参数提取 * 节点* 将完整内容转换成数组格式
- 通过 迭代 * 节点 * 包裹的 LLM 节点 循环多次生成各章节内容
- 将 直接回复 节点添加在迭代节点内部,实现在每轮迭代生成之后流式输出
具体配置步骤
- 在 开始 * 节点* 配置故事标题(title)和大纲(outline);
- 通过 Jinja-2 模板 * 节点* 将故事标题与大纲转换为完整文本;
- 通过 参数提取 * 节点 * ,将故事文本转换成为数组(Array)结构。提取参数为
sections,参数类型为Array[Object]

参数提取效果受模型推理能力和指令影响,使用推理能力更强的模型,在指令 内增加示例可以提高参数提取的效果。
- 将数组格式的故事大纲作为迭代节点的输入,在迭代节点内部使用 LLM 节点 进行处理

在 LLM 节点内配置输入变量 GenerateOverallOutline/output 和 Iteration/item
迭代的内置变量:items[object] 和 index[number]
itemsobject 代表以每轮迭代的输入条目;
indexnumber 代表当前迭代的轮次;
列表操作
文件列表变量支持同时上传文档文件、图片、音频与视频文件等多种文件。应用使用者在上传文件时,所有文件都存储在同一个 Array[File] 数组类型变量内,不利于后续单独处理文件。 列表操作节点可以在数组变量内提取单独的元素,便于后续节点处理。
例如在一个应用中,允许用户同时上传文档文件和图片文件两种不同类型的文件。需要使用列表操作* *节点**进行分拣,将不同的文件类型交由不同流程处理。
列表操作节点一般用于提取数组变量中的信息,通过设置条件将其转化为能够被下游节点所接受的变量类型。它的结构分为输入变量 、过滤条件 、排序(可选) 、取前 N 项(可选) 、输出变量。

文档提取器
LLM 自身无法直接读取或解释文档的内容。因此需要将用户上传的文档,通过文档提取器节点解析并读取文档文件中的信息,转化文本之后再将内容传给 LLM 以实现对于文件内容的处理。
问题分类器
通过定义分类描述,问题分类器能够根据用户输入,使用 LLM 推理与之相匹配的分类并输出分类结果,向下游节点提供更加精确的信息。
常见的使用情景包括客服对话意图分类、产品评价分类、邮件批量分类等。
在一个典型的产品客服问答场景中,问题分类器可以作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。
