本节课围绕Spark Core展开深入学习,了解了Spark的运行架构、核心组件、核心概念以及提交流程,明晰其整体运行机制与各部分协作逻辑。重点聚焦于两个核心组件;对RDD相关概念进行了细致学习,包括其核心属性、执行原理、序列化方式、依赖关系、持久化操作、分区器的运用,以及文件读取与保存等内容。
代码
词频统计
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.
textFile("D:\\school\\workspace\\workspace-IJ\\Spark\\Spark-core\\input\\word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
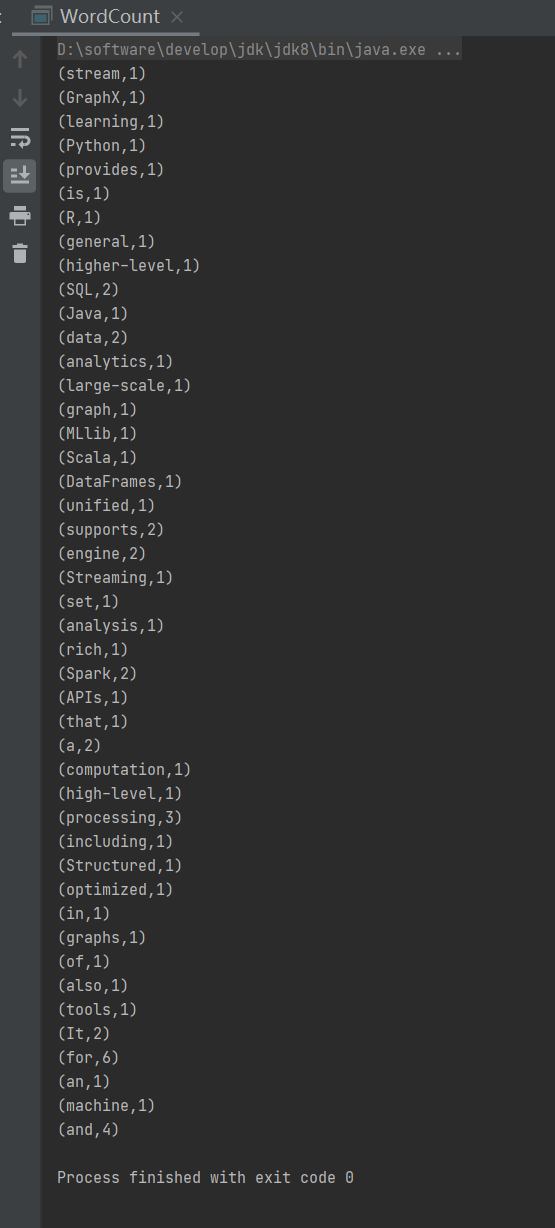
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
}
}
也可以配置日志文件:
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项
目的 resources 目录中创建 log4j.properties 文件,并添加日志配置信息
重新运行:
Spark Core
Spark运行架构
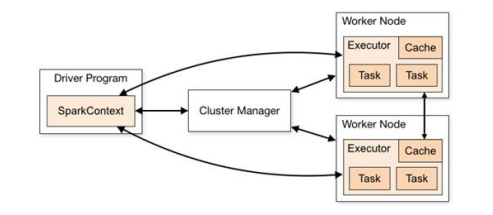
Spark Core 是整个 Apache Spark 框架的基础核心部分,它为上层的各类应用(如 Spark SQL、Spark Streaming 等)提供了通用的分布式计算功能以及数据处理能力
核心组件
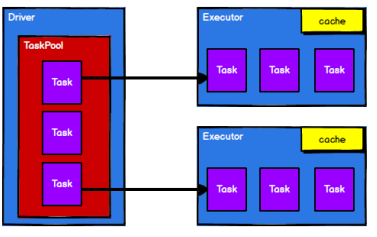
Driver:Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Executor:Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业 中运行具体任务( Task),任务彼此之间相互独立。
Master & Worker
ApplicationMaster
核心概念
Executor 与 Core

并行度(Parallelism)
有向无环图(DAG)
提交流程
所谓的提交流程,其实就是开发人员根据需求写的应用程序通过 Spark 客户端提交给 Spark 运行环境执行计算的流程。在不同的部署环境中,这个提交过程基本相同,但是又有细微的区别,这里不进行详细的比较,但是因为国内工作中,将 Spark 引用部署到Yarn 环境中会更多一些,所以这里提到的提交流程是基于 Yarn 环境的。
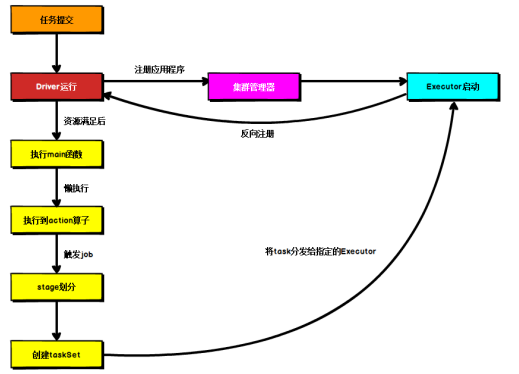
RDD
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
RDD的概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在大数据集群不同节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
可分区、并行计算
核心属性
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。
RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
分区器(可选)
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区。
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
执行原理
******1.******启动 Yarn 集群环境
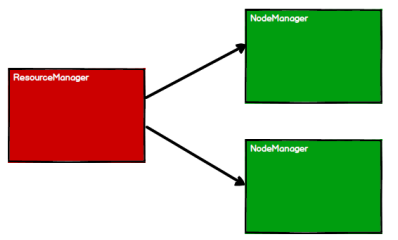
2.Spark 通过申请资源创建调度节点和计算节点
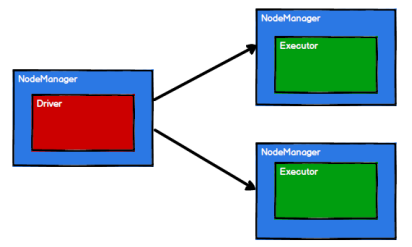
3.Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
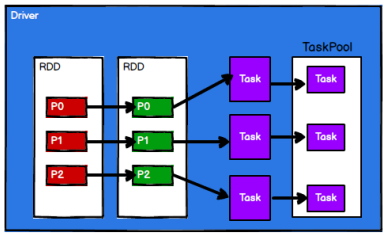
4.调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
RDD 序列化
-
闭包检查
-
序列化方法和属性
-
Kryo 序列化框架
注意:即使使用 Kryo 序列化,也要继承 Serializable 接口。
RDD 依赖关系
-
RDD 血缘关系
-
RDD 依赖关系
-
RDD 窄依赖
-
RDD 宽依赖
-
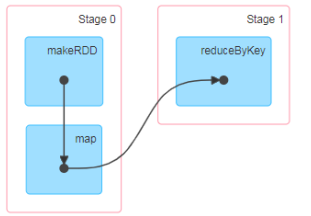
RDD 阶段划分

- RDD 任务划分
RDD 持久化
-
RDD Cache 缓存
-
RDD CheckPoint 检查点
-
缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
RDD 分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区
RDD 文件读取与保存
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。
text 文件

sequence 文件

object 对象文件
