目录
简述6种系统聚类法
(一)单链接聚类法:也称为最小距离聚类法,它通过计算两个簇中最近的成员之间的距离来确定簇之间的距离。该方法通常会产生长而细的簇,对异常值敏感。
(二)完全链接聚类法:也称为最大距离聚类法,它通过计算两个簇中最远的成员之间的距离来确定簇之间的距离。该方法通常会产生紧凑的簇,对异常值不敏感。
(三)平均链接聚类法:它通过计算两个簇中所有成员之间的平均距离来确定簇之间的距离。该方法可以在一定程度上平衡单链接和完全链接的缺点。
(四)中心链接聚类法:它通过计算两个簇的质心之间的距离来确定簇之间的距离。质心是指簇中所有成员的平均值。该方法产生的簇具有更加均衡的大小。
(五)Ward聚类法:它基于最小方差准则,通过计算将两个簇合并后整体的方差增加量来确定簇之间的距离。该方法倾向于产生方差相对较小的簇。
(六)类平均聚类法:它通过计算两个簇中所有成员之间的平均距离来确定簇之间的距离。类平均聚类法与平均链接聚类法类似,但不同于平均链接聚类法使用所有成员之间的距离,而是只使用两个簇之间的成员之间的距离。
实验实例和数据资料:
P212:2) 为了比较我国 31个省、市、自治区 1996年和2007年(数据见本章例7.2:d3.1)城镇居民生活消费的分布规律,根据调查资料作区域消费类型划分。并将1996年和2007年的数据进行对比分析。今收集了八个反映城镇居民生活消费结构的指标(1996年数据见表1和表2):
表1 八个反映城镇居民生活消费结构的指标
|-------------------------|----------------------------------------------------------------------------------|---------------------------------|
| 符号 | 指标 | 单位 |
| X1 X2 X3 X4 X5 X6 X7 X8 | 人均食品支出 人均衣着商品支出 人均家庭设备用品及服务支出 人均医疗保健支出 人均交通和通信支出 人均娱乐教育文化服务支出 人均居住支出 人均杂项商品和服务支出 | 元/人 元/人 元/人 元/人 元/人 元/人 元/人 元/人 |
表2 1996年全国31个省、市、自治区城镇居民消费数据
|-----|---------|---------|---------|---------|---------|---------|---------|---------|
| | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 |
| 北京 | 8170.22 | 2794.87 | 1974.25 | 1717.58 | 4106.04 | 3984.86 | 2125.99 | 1401.08 |
| 天津 | 7943.06 | 1950.68 | 1205.62 | 1694.29 | 3468.86 | 2353.43 | 2088.62 | 1007.31 |
| 河北 | 4404.4 | 1488.11 | 977.46 | 1117.3 | 2149.57 | 1550.63 | 1526.28 | 426.29 |
| 山西 | 3676.65 | 1627.53 | 870.91 | 1020.61 | 1775.3 | 2065.44 | 1612.36 | 516.84 |
| 内蒙古 | 6117.93 | 2777.25 | 1233.39 | 1394.8 | 2719.92 | 2111 | 1951.05 | 943.72 |
| 辽宁 | 5803.9 | 2100.71 | 1145.57 | 1343.05 | 2589.18 | 2258.46 | 1936.10 | 852.69 |
| 吉林 | 4658.13 | 1961.2 | 908.43 | 1692.11 | 2217.87 | 1935.04 | 1932.24 | 627.3 |
| 黑龙江 | 5069.89 | 1803.45 | 796.38 | 1334.8 | 1661.35 | 1396.38 | 1543.29 | 556.16 |
| 上海 | 9822.88 | 2032.28 | 1705.47 | 1350.28 | 4736.36 | 4122.07 | 2847.88 | 1537.78 |
| 江苏 | 7074.11 | 2013 | 1378.85 | 1122 | 3135 | 3290 | 1564.3 | 794.00 |
| 浙江 | 8008.16 | 2235.21 | 1400.57 | 1244.37 | 4568.32 | 2848.75 | 2004.69 | 947.13 |
| 安徽 | 6370.23 | 1687.49 | 898.55 | 869.89 | 2411.16 | 1904.15 | 1633.55 | 480.16 |
| 福建 | 7424.67 | 1685.07 | 1416.94 | 935.5 | 3219.46 | 2448.36 | 2013.53 | 949.19 |
| 江西 | 5221.1 | 1566.49 | 1004.15 | 672.5 | 1812.78 | 1671.24 | 1414.89 | 471.58 |
| 山东 | 5625.94 | 2277.03 | 1269.65 | 1109.37 | 2474.83 | 1909.84 | 1780.07 | 665.52 |
| 河南 | 4913.87 | 1916.99 | 1281.06 | 1054.54 | 1768.28 | 1911.16 | 1315.28 | 660.81 |
| 湖北 | 6259.22 | 1881.85 | 1059.22 | 1033.46 | 1745.05 | 1922.83 | 1456.30 | 391.57 |
| 湖南 | 5583.99 | 1520.35 | 1146.65 | 1078.82 | 2409.83 | 2080.46 | 1529.50 | 537.51 |
| 广东 | 8856.91 | 1614.87 | 1539.09 | 1122.71 | 4544.21 | 3222.40 | 2339.12 | 893.95 |
| 广西 | 5841.16 | 1015.88 | 1086.46 | 776.26 | 2564.92 | 2093.99 | 1622.50 | 386.46 |
| 海南 | 6979.22 | 932.63 | 1030.79 | 734.28 | 2005.73 | 1923.48 | 1578.65 | 408.26 |
| 重庆 | 7245.12 | 2333.81 | 1325.91 | 1245.33 | 1976.19 | 1722.66 | 1376.15 | 588.70 |
| 四川 | 6471.84 | 1727.92 | 1196.65 | 1019.04 | 2185.94 | 1877.55 | 1321.54 | 542.99 |
| 贵州 | 4915.02 | 1401.85 | 1083.77 | 633.72 | 1870.08 | 1950.28 | 1496.49 | 351.66 |
| 云南 | 5741.01 | 1356.91 | 987.24 | 1085.46 | 2197.73 | 2045.29 | 1384.91 | 357.61 |
| 西藏 | 5889.48 | 1528.14 | 541.46 | 617.97 | 500.6 | 1551.34 | 963.99 | 638.89 |
| 陕西 | 6075.58 | 1915.33 | 1060.49 | 1310.19 | 2019.08 | 2208.06 | 1465.81 | 626.16 |
| 甘肃 | 5162.87 | 1747.32 | 939.48 | 1117.42 | 1503.61 | 1547.65 | 1596 | 406.37 |
| 青海 | 4777.1 | 1675.06 | 890.08 | 813.13 | 1742.96 | 1471.98 | 1684.78 | 484.41 |
| 宁夏 | 4895.2 | 1737.21 | 1001.82 | 1158.83 | 2503.65 | 1868.42 | 1497.98 | 657.99 |
| 新疆 | 5323.5 | 2036.94 | 977.8 | 1179.77 | 2210.25 | 1597.99 | 1275.35 | 604.55 |
试对该数据进行聚类分析。
上机实验步骤:
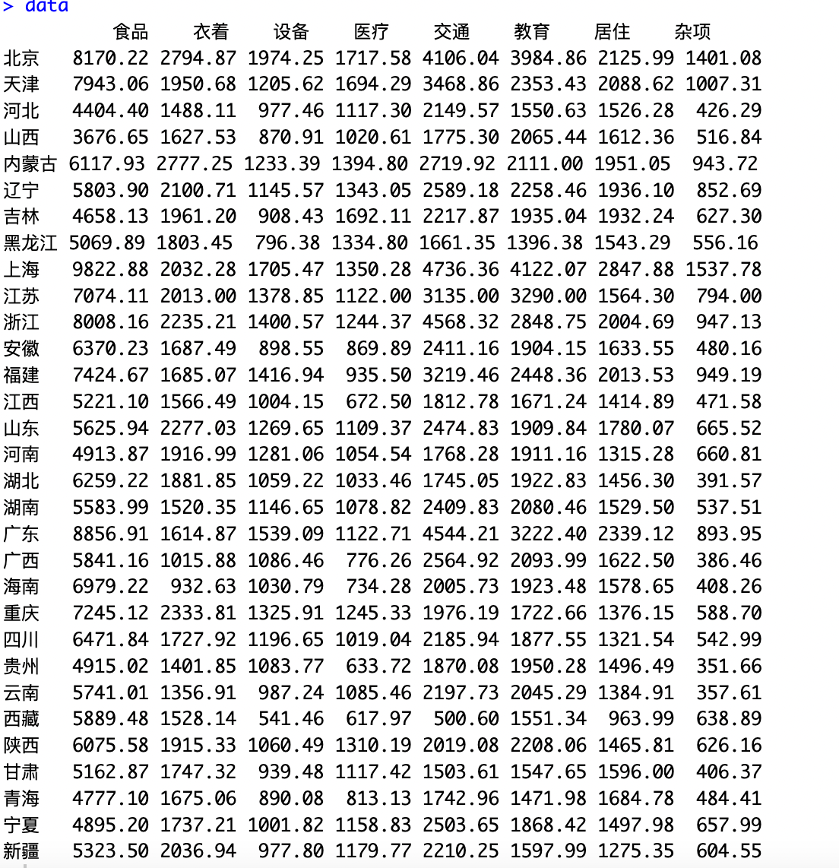
1.准备数据:根据提供的消费数据,将数据保存在一个Excel文件中,并确保每个地区在所有指标上都有完整的数据。将文件命名为"1996年数据.xlsx"。
- 加载数据并计算距离矩阵
R
data=read.xlsx('1996年数据.xlsx',rowNames=T);data
dist_matrix <- dist(data) 结果如下
进行最短距离聚类:
R
j1 <- hclust(dist_matrix, method = "single")
plot(j1, main = "最短距离聚类树状图") 结果如下

进行最长距离聚类:
R
j2 <- hclust(dist_matrix, method = "complete")
plot(j2, main = "最长距离聚类树状图") 结果如下

进行中间距离聚类:
R
j3 <- hclust(dist_matrix, method = "median")
plot(j3, main = "中间距离聚类树状图") 结果如下

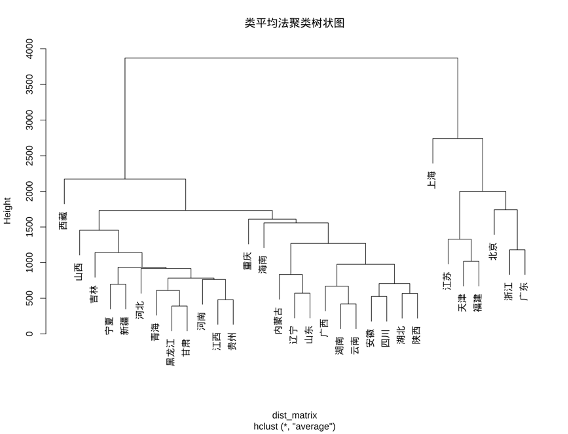
进行类平均法聚类:
R
j4 <- hclust(dist_matrix, method = "average")
plot(j4, main = "类平均法聚类树状图") 结果如下
进行重心法聚类:
R
j5 <- hclust(dist_matrix, method = "centroid")
plot(j5, main = "重心法聚类树状图")结果如下

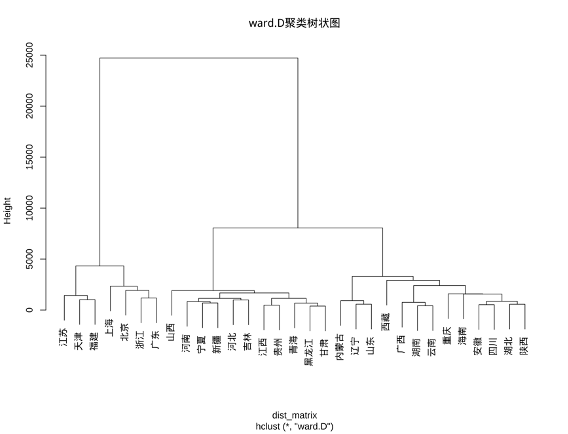
进行ward.D 聚类:
R
j6 <- hclust(dist_matrix, method = "ward.D")
plot(j6, main = "ward.D聚类树状图") 结果如下
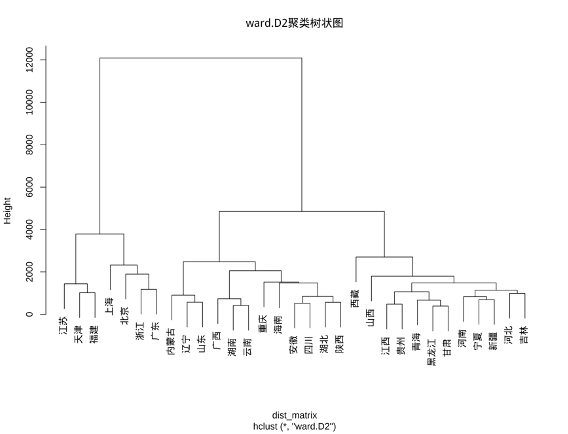
进行ward.D2 聚类:
R
j7 <- hclust(dist_matrix, method = "ward.D2")
plot(j7, main = "ward.D2聚类树状图") 结果如下