一、spark core运行框架
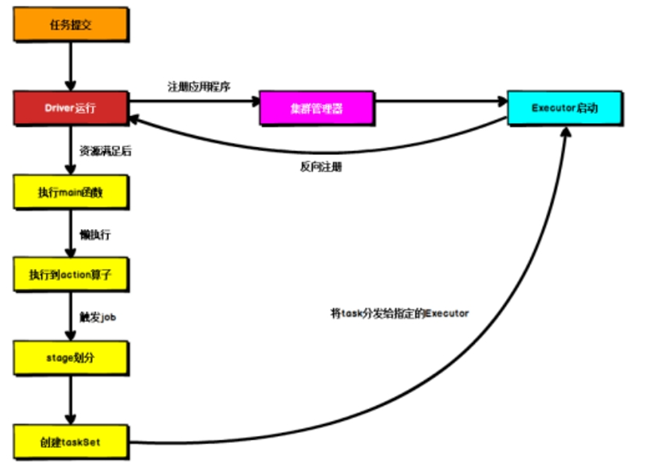
1.架构与组件:采用 master - slave 结构,Driver 为 master,负责作业调度;Executor 是 slave,执行任务。此外,独立部署有 Master(资源调度分配)和 Worker(数据处理计算),Yarn 环境有 ApplicationMaster(资源申请、任务监控)
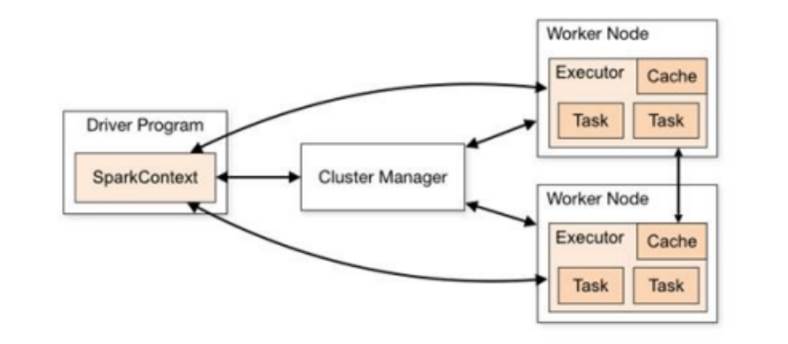
2.核心概念:Executor 是工作节点的 JVM 进程,利用 Core 计算,可配置数量、内存和 CPU 核数。并行度指集群并行执行任务数量,受框架默认配置影响且可动态修改。有向无环图(DAG)是程序计算执行过程的抽象模型,用于表示程序拓扑结构。
3.提交流程:有 Client 和 Cluster 两种模式。Client 模式下 Driver 在本地机器运行,用于测试;Cluster 模式下 Driver 在 Yarn 集群资源中运行,适用于生产环境 。
二、RDD相关概念(弹性分布式数据集)
1.RDD 特性与核心属性:RDD 是 Spark 中基本的数据处理模型,具有弹性(存储、容错、计算、分片方面)、分布式、数据集、数据抽象、不可变、可分区并行计算等特性。其核心属性包括分区列表用于并行计算、分区计算函数对每个分区进行计算、RDD 之间的依赖关系用于组合计算模型、分区器(可选,用于 K - V 类型数据分区)和首选位置(可选,根据节点状态选择计算位置) 。
2.执行原理与序列化:
执行时,Spark 先申请资源,将数据处理逻辑分解为任务,分发到计算节点按指定模型计算。在序列化方面,需进行闭包检查,确保算子外数据可序列化,否则无法在 Executor 端执行。Spark2.0 开始支持 Kryo 序列化机制,比 Java 序列化速度快 10 倍,部分简单数据类型、数组和字符串类型已默认使用,但仍需继承 Serializable 接口 。
3.依赖关系、持久化与分区器:
RDD 依赖关系包括血缘关系(记录元数据和转换行为用于恢复丢失分区)、宽窄依赖(窄依赖指父 RDD 分区最多被子 RDD 一个分区使用,宽依赖指父 RDD 分区被多个子 RDD 分区依赖且会引起 Shuffle),基于此划分阶段和任务;阶段划分(有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环);任务划分(RDD 任务切分中间分为:Application、Job、Stage 和 Task)
持久化方式有 Cache 缓存(默认 JVM 堆内存,action 算子触发,缓存容错机制保证计算正确执行)和 CheckPoint 检查点(将中间结果写入磁盘,切断血缘依赖,可靠性高,建议搭配 Cache 使用)
Spark 支持 Hash 分区、Range 分区和自定义分区,分区器影响 RDD 分区个数、数据分区及 Reduce 个数,只有 Key - Value 类型的 RDD 才有分区器
4.文件读取与保存:Spark 可读取和保存多种文件格式,如 text、csv、sequence、object 文件,支持本地文件系统、HDFS、HBASE、数据库等文件系统。针对不同文件格式有相应的读取和保存方法, textFile 用于读取文本文件,saveAsTextFile 用于保存为文本文件。
三、Spark - Core 编程(一)
1.环境准备与配置:需要 Jdk1.8、Scala2.12 版本,在 Idea 集成开发环境中安装 Scala 插件。创建 Maven 项目时,在 pom.xml 中添加 Spark - core 和相关插件依赖,如 scala - maven - plugin 用于编译 Scala 代码,maven - assembly - plugin 用于打包。
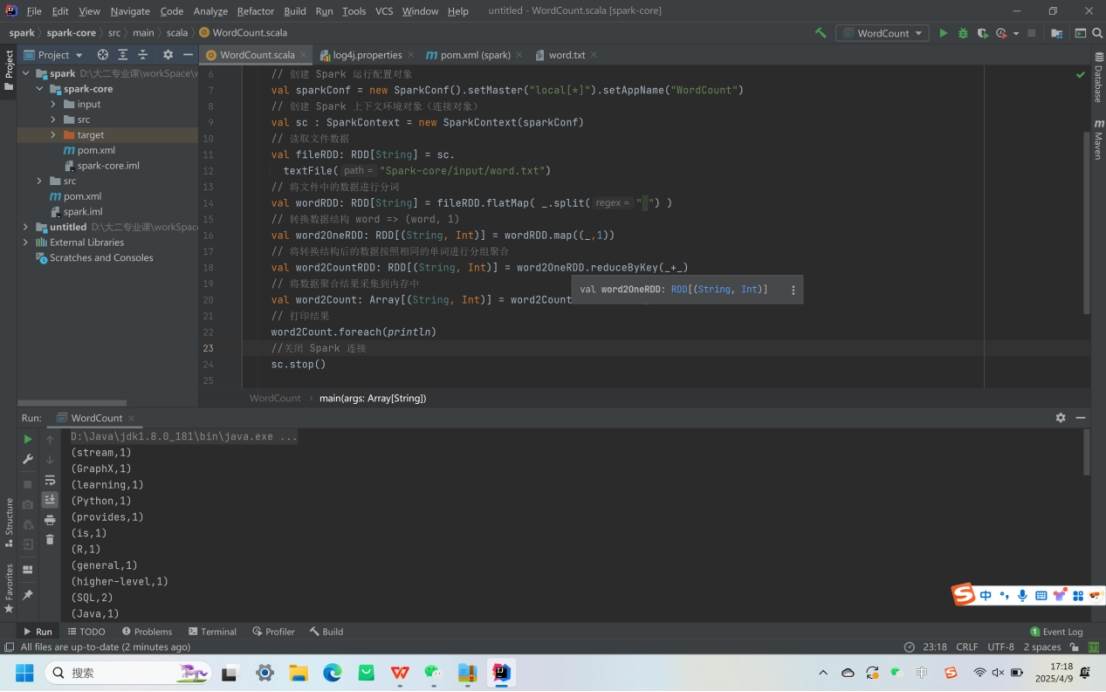
2.WordCount 程序实现:创建 Spark - core 子模块,将 java 文件夹重命名为 scala,在其中编写 WordCount 程序。程序通过读取文件、分词、转换数据结构、分组聚合统计单词数量,最后采集结果并打印。运行程序前需在项目 resources 目录中创建 log4j.properties 文件配置日志,降低日志级别以减少干扰,更好查看程序执行结果。