1、redis整体涉及的结构
在redis中整体是KV键值对的方式进行访问的,redis的查询的时间复杂度O(1),底层的数据结构其实跟java中的HashMap底层实现类似,整体采用的是数组+链表的实现方式,哈希冲突的时候使用的是链表法解决;在redis中这个数组对应的数据结构是dictht,数组的每个节点是dictEntry,节点中的key使用的是SDS,value使用的是redisObject,redisObject中除了会存储value值,还会存储对应的type(String、hash、list、set、zset)以及对应的编码格式 (比如String类型会有int emstr raw)。在以上的结构基础上,为了处理redis扩缩容的实现使用到了两个dichht,即数组为了方便管理向上再封装了一层dict ,其次在redis中缓存淘汰的机制存在只针对设置了过期时间的key进行回收,所以在dict的基础上再封装了一层redisDb,所以整体应该是
redisDB->dict->dictht->dictEntry->SDS、redisObject
以下将重点使用到的数据结构在源码中的定义归纳总成以下
1.1 server.h==>redisDb数据结构
objectivec
typedef struct redisDb {
dict *dict; /* 所有的键值对 */ /* The keyspace for this DB */
dict *expires; /* 设置了过期时间的键值对*//* Timeout of keys with a timeout set */
dict *blocking_keys; /* 处于阻塞状态的键和对应的client(主要用于List类型的阻塞操作) *//* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* 准备好数据可以解除阻塞状态的健和相应的client *//* Blocked keys that received a PUSH */
dict *watched_keys; /* 被watch命令监控的key和client */ /* WATCHED keys for MULTI/EXEC CAS */
int id; /* 数据库ID标识 *//* Database ID */
long long avg_ttl; /* 数据内所有键的平均TTL(生存时间) *//* Average TTL, just for stats */
unsigned long expires_cursor; /*主动过期循环的游标*//* Cursor of the active expire cycle. */
list *defrag_later; /* key组成的链表,用来进行内存碎片整理 *//* List of key names to attempt to defrag one by one, gradually. */
} redisDb;1.2 dich.h==>dict数据结构
objectivec
typedef struct dict {
dictType *type; /* 字典类型 */
void *privdata; /* 私有数据 */
dictht ht[2]; /* 一个字典有两个hash表 */
long rehashidx; /* rehash索引 *//* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* 当前正在使用的迭代器数量 *//* If >0 rehashing is paused (<0 indicates coding error) */
} dict;1.3 dich.h==>dictht数据结构
objectivec
typedef struct dictht {
dictEntry **table; /* 哈希表数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 掩码大小,用于计算索引值,总是等于size-1 */
unsigned long used; /* 已有节点数 */
} dictht;1.4 dich.h==>dictEntry数据结构
objectivec
typedef struct dictEntry {
void *key; /* key关键字定义 */
union {
void *val; /* value定义 */
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;1.5 server.h==>redisObject数据结构
objectivec
typedef struct redisObject {
unsigned type:4; /* 对象类型 包括:OBJ_STRING OBJ_LIST OBJ_HASH OBJ_SET OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24位,对象最后一次被命令程序访问的时间,与内存回收有关 *//* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; /* 引用计数器,当refcount为0的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收 */
void *ptr; /* 指向对象的实际数据结构 */
} robj;2 redis整体结构图
存储键值的数据结构dictEntry
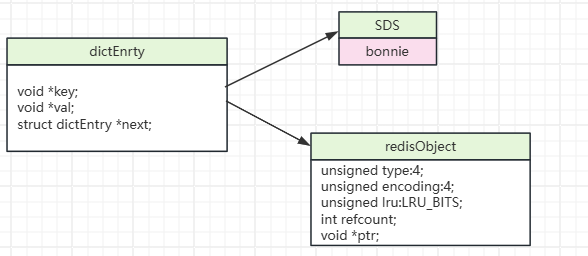
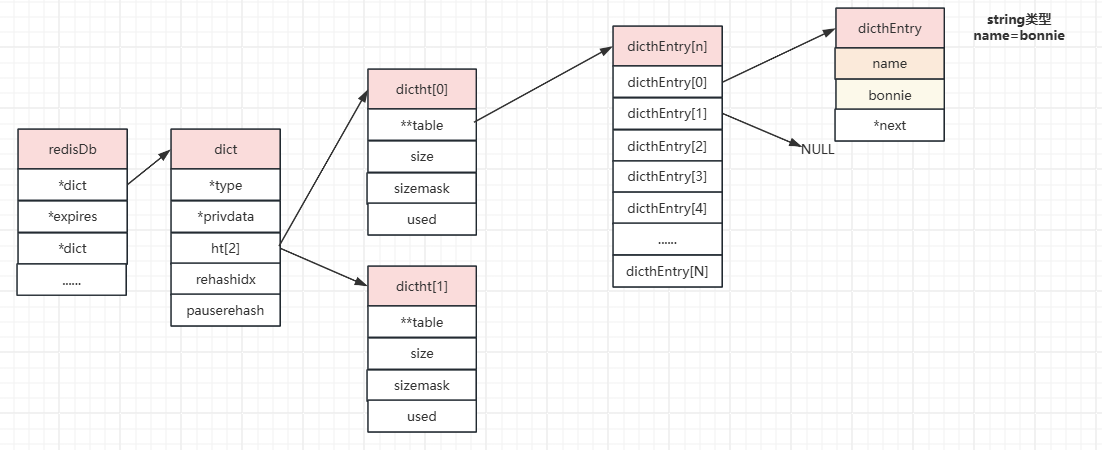
整体结构关系
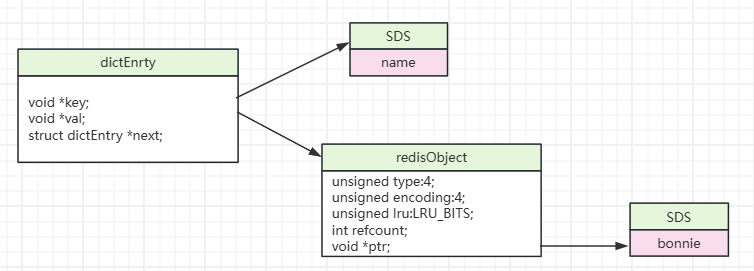
3 基本数据类型
下面整理下5中基本的数据类型的底层实现
3.1 String字符串
存储类型:
可以用来存储INT(整数)、float(单精度浮点数)、String(字符串)
数据模型:比如存储name=bonnie
以下举例说明String三种字符编码int embstr raw
set number l
set bonnie "cengjingnianshaoaizhuimengyixinzhixiangwangqianfei'
set huihui yes
type number
type huihui
type bonnie
object encoding number # int
object encoding huihui # embstr
object encoding bonnie # raw虽然对外都是String的命令,但是出现了三种不同的编码。
这三种编码的区别是:
1、int 存储8个字节的长整型(long 2的63次方-1)
2、embstr,代表embstr格式的SDS,存储小于44个字节的字符串
3、raw,存储大于44个字节的字符串
SDS(Simple Dynamic String)简单动态字符串
源码文件:sds.h
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 当前字符串数组的长度 used */
uint8_t alloc; /* 当前字符数组总共分配的内存大小 excluding the header and null terminator */
unsigned char flags; /* 当前字符数组的属性,用来标识到底是sdshdr8还是sdshdr16等3 lsb of type, 5 unused bits */
char buf[]; /* 字符串真正的值 */
};本质上其实还是字符数组,SDS有多种结构(sds.h):sdshdr5 sdshdr8 sdshdr16 sdshdr32 sdshdr64用于存储不同的长度的字符串,分别代表:2^5=32byte 2^8=256byte 2^16=65536byte 2^32=4GB
使用SDS实现字符串可以解决那些问题?
redis使用C语言实现的,因为C语言本身没有字符串类型,只能用字符数组char\[\]实现。
1、使用字符数组必须先给目标变量分配足够的空间,否则可能会溢出 。
2、如果要获取字符长度,必须遍历字符数组,时间复杂度是O(n)
3、C字符串长度的变更会对字符数组做内存重分配
4、通过字符串开始到结尾碰到的第一个'\0'来标记字符串的结束,因此不能保存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全。
SDS的特点:
1、不用担心内存溢出问题,如果需要会对SDS进行扩容
2、获取字符串长度时间复杂度O(1),因此定义了len属性
3、通过"空间惰性"(sdsMakeRoomFor)和"惰性空间释放",防止多次重分配内存
4、判断是否结构的标志是len属性,可以包含'\0'(它同样以'\0'结尾是因为这样就可以使用C语言中函数操作字符串的函数了)
存储二进制:BytesTest.java
|------------------------|-----|
| C字符数组 | SDS |
| 获取字符串长度的复杂度为O(N) | |
| API是不安全的,可能会造成缓冲区溢出 | |
| 修改字符串长度N次必然需要执行N次内存重分配 | |
| 执能 | |
| | |
3.2 Hash
3.3 List
34 Set
3.5 Szet
objectivec
typedef struct zlentry {
unsigned int prevrawlensize; /* 存储上一个节点长度数值所需要的字节数 *//* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* 上一个链表节点占用的长度 *//* Previous entry len. */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的节点数 *//* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* 当前链表节点占用的长度 *//* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* 当前链表节点头部大小(prevrawlensize+lensize),即非数据域的大小 *//* prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式 *//* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 *//* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;