AI(DeepSeek) + ODPS SDK :5分钟搞定ODPS元数据入MySQL!
为实现ODPS元数据向MySQL的全量覆盖同步,本方案通过以下设计确保数据一致性与执行效率:
1. 全量覆盖机制
- 数据清空 :每次同步前,基于事务机制按依赖顺序清空MySQL目标表 (先字段表
dacp_dge_coll_tab_field,后主表dacp_dge_coll_tab),避免外键约束冲突。 - TRUNCATE优化 :使用
TRUNCATE而非DELETE,快速重置表并释放存储,兼顾性能与自增ID管理。
2. 事务一致性保障
- 原子性操作 :通过JDBC事务控制(
AutoCommit=false),确保数据清空、插入过程整体成功或完全回滚,杜绝中间状态。 - 异常回滚:同步失败时自动回滚事务,保证数据完整性。
3. 元数据同步逻辑
- 表信息提取 :从ODPS提取表名、注释、字段数、存储大小等核心属性,并动态生成唯一
tab_id(UUID)作为主键。 - 字段处理 :解析ODPS字段类型、长度、默认值、分区键标识,自动映射至MySQL字段表,生成
field_id保证唯一性。 - 智能类型转换 :从ODPS类型(如
VARCHAR(255))中分离数据类型与长度,适配MySQL表结构。
4. 性能优化设计
- 批处理支持 :通过JDBC的
rewriteBatchedStatements=true参数启用批量插入,提升数据写入效率。 - 资源管理 :采用
try-with-resources自动释放数据库连接,避免内存泄漏。
5. 可维护性增强
- 配置解耦 :ODPS密钥、端点及MySQL连接信息均外置至
config.properties,便于环境切换与安全管理。 - 日志追踪:关键步骤(如清空表、提交事务)添加日志输出,便于监控与调试。
使用deepseek完善代码
1.将官网示例代码输入AI对话框
java
public static void main(String[] args) throws Exception {
Account account = new AliyunAccount("WwxxxxSio", "imdqsnO7Zxxxx5YMdtqFag");
Odps odps = new Odps(account);
String odpsUrl = "http://service.xxx.xj.hsip.gov.cn:80/api";
odps.setEndpoint(odpsUrl);
odps.setDefaultProject("xxx");
for (Table tbl : odps.tables()) {
System.out.println(tbl.getName());
}
}2并将设计好的表模型输入
3输入提示词获得代码
为了将ODPS表信息写入MySQL,需进行以下步骤:
步骤说明
- 配置文件管理 - 将ODPS和MySQL配置移至
config.properties - ODPS连接配置 - 使用配置文件中的参数初始化ODPS客户端
- MySQL连接管理 - 使用JDBC连接MySQL并准备插入SQL
- 元数据提取 - 从ODPS提取表和字段信息
- 数据写入 - 将提取的信息批量插入MySQL
实现代码
1. config.properties
properties
# ODPS配置
odps.access.id=
odps.access.key=
odps.endpoint=
odps.project=
# MySQL配置
mysql.url=jdbc:mysql://localhost:3306/your_database
mysql.user=your_user
mysql.password=your_password2. Java代码
java
import com.aliyun.odps.*;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import java.util.*;
import java.sql.*;
import java.io.InputStream;
public class OdpsToMysqlSync {
private static Properties config = new Properties();
public static void main(String[] args) throws Exception {
// 加载配置文件
loadConfig();
// 初始化ODPS客户端
Odps odps = initOdpsClient();
// 获取MySQL连接
try (Connection conn = DriverManager.getConnection(
config.getProperty("mysql.url"),
config.getProperty("mysql.user"),
config.getProperty("mysql.password"))) {
// 遍历所有表
for (Table tbl : odps.tables()) {
// 处理表信息
processTable(conn, tbl);
}
}
}
private static void loadConfig() throws Exception {
try (InputStream input = OdpsToMysqlSync.class.getClassLoader().getResourceAsStream("config.properties")) {
if (input == null) throw new RuntimeException("配置文件未找到");
config.load(input);
}
}
private static Odps initOdpsClient() {
Account account = new AliyunAccount(config.getProperty("odps.access.id"), config.getProperty("odps.access.key"));
Odps odps = new Odps(account);
odps.setEndpoint(config.getProperty("odps.endpoint"));
odps.setDefaultProject(config.getProperty("odps.project"));
return odps;
}
private static void processTable(Connection conn, Table tbl) throws SQLException {
// 生成表ID
String tabId = UUID.randomUUID().toString().replace("-", "");
// 提取表信息
String tabName = tbl.getName();
String modelTabName = tabName.toUpperCase();
String tabLabel = tbl.getComment() != null ? tbl.getComment() : "";
String tabSchema = tbl.getSchema() != null ? tbl.getSchema().getName() : "";
long tabRows = tbl.getNumRows(); // 需要确认ODPS API是否支持
String tabCapacity = formatSize(tbl.getSize()); // 假设有getSize方法
int fieldNum = tbl.getSchema().getColumns().size();
String createTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tbl.getCreatedTime());
String dsName = config.getProperty("odps.project");
// 插入表记录
insertTable(conn, tabId, tabName, modelTabName, tabLabel, tabSchema, tabRows, tabCapacity, fieldNum, createTime, dsName);
// 处理字段
processColumns(conn, tbl, tabId, tabName, dsName, tabSchema);
}
private static void insertTable(Connection conn, String tabId, String tabName, String modelTabName,
String tabLabel, String tabSchema, long tabRows, String tabCapacity,
int fieldNum, String createTime, String dsName) throws SQLException {
String sql = "INSERT INTO dacp_dge_coll_tab (tab_id, tab_name, model_tab_name, tab_label, " +
"tab_schema, tab_rows, tab_capacity, field_num, create_time, ds_name) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, tabId);
pstmt.setString(2, tabName);
pstmt.setString(3, modelTabName);
pstmt.setString(4, tabLabel);
pstmt.setString(5, tabSchema);
pstmt.setLong(6, tabRows);
pstmt.setString(7, tabCapacity);
pstmt.setInt(8, fieldNum);
pstmt.setString(9, createTime);
pstmt.setString(10, dsName);
pstmt.executeUpdate();
}
}
private static void processColumns(Connection conn, Table tbl, String tabId, String tabName,
String dsName, String tabSchema) throws SQLException {
List<Column> columns = tbl.getSchema().getColumns();
List<Column> partitions = tbl.getPartitionColumns();
for (int i = 0; i < columns.size(); i++) {
Column col = columns.get(i);
String fieldId = UUID.randomUUID().toString().replace("-", "");
String dataType = col.getTypeInfo().getTypeName();
String[] typeParts = dataType.split("\(");
String length = typeParts.length > 1 ? typeParts[1].replace(")", "") : "";
boolean isPartition = partitions.stream().anyMatch(p -> p.getName().equals(col.getName()));
String isnullable = col.isNullable() ? "YES" : "NO";
insertColumn(conn, fieldId, tabId, tabName, dsName, tabSchema, col, i + 1, length, isnullable, isPartition);
}
}
private static void insertColumn(Connection conn, String fieldId, String tabId, String tabName,
String dsName, String tabSchema, Column col, int pos,
String length, String isnullable, boolean isPartition) throws SQLException {
String sql = "INSERT INTO dacp_dge_coll_tab_field (field_id, tab_id, tab_name, ds_name, " +
"tab_schema, field_name, field_label, data_type, length, isnullable, " +
"field_posi, def_value, primary_key, partition_key) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, fieldId);
pstmt.setString(2, tabId);
pstmt.setString(3, tabName);
pstmt.setString(4, dsName);
pstmt.setString(5, tabSchema);
pstmt.setString(6, col.getName());
pstmt.setString(7, col.getComment() != null ? col.getComment() : "");
pstmt.setString(8, col.getTypeInfo().getTypeName());
pstmt.setString(9, length);
pstmt.setString(10, isnullable);
pstmt.setInt(11, pos);
pstmt.setString(12, col.getDefaultValue() != null ? col.getDefaultValue() : "");
pstmt.setString(13, "NO"); // ODPS无主键概念
pstmt.setString(14, isPartition ? "YES" : "NO");
pstmt.executeUpdate();
}
}
private static String formatSize(long bytes) {
// 实现字节到友好格式的转换
return String.format("%d KB", bytes / 1024);
}
}关键点说明
表模型
数据资产表信息dacp_dge_coll_tab
| tab_id | varchar(32) | 表的唯一标识 |
|---|---|---|
| tab_name | varchar(64) | 表名 |
| model_tab_name | varchar(64) | 模型表名(大写表名) |
| tab_label | varchar(512) | 表中文名 |
| tab_schema | varchar(64) | 表所属schema |
| tab_rows | bigint(20) | 数据行数 |
| tab_capacity | varchar(64) | 表存储大小 |
| field_num | int(11) | 字段数 |
| create_time | varchar(256) | 创建时间 |
| ds_name | varchar(128) | 数据库名 |
数据资产表信息(dacp_dge_coll_tab_field)
| field_id | varchar(64) | 盘点字段id |
|---|---|---|
| tab_id | varchar(64) | 表id |
| tab_name | varchar(64) | 表名 |
| ds_name | varchar(128) | 数据源名 |
| tab_schema | varchar(64) | 表所属schema |
| field_name | varchar(64) | 字段名 |
| field_label | varchar(512) | 字段中文名 |
| data_type | varchar(30) | 数据类型 |
| length | varchar(32) | 字段长度 |
| isnullable | varchar(3) | 是否可以为空 |
| field_posi | int(11) | 字段序号 |
| def_value | varchar(1024) | 默认值 |
| primary_key | varchar(3) | 是否主键 |
| partition_key | varchar(3) | 分区键标识 |
AI毕竟不是人所以代码还是需要细化
最终代码
java
package com.odps.api;
import com.aliyun.odps.*;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import java.text.SimpleDateFormat;
import java.util.*;
import java.sql.*;
import java.io.InputStream;
public class OdpsToMysqlSync {
private static Properties config = new Properties();
public static void main(String[] args) throws Exception {
// 加载配置文件
loadConfig();
// 初始化ODPS客户端
Odps odps = initOdpsClient();
// 获取MySQL连接
try (Connection conn = DriverManager.getConnection(
config.getProperty("mysql.url"),
config.getProperty("mysql.user"),
config.getProperty("mysql.password"))) {
// 开启事务,确保数据一致性
conn.setAutoCommit(false);
try {
// 清空目标表(按依赖顺序)
clearTables(conn);
// 遍历所有表
for (Table tbl : odps.tables()) {
// 处理表信息
processTable(conn, tbl);
}
conn.commit();
System.out.println("数据同步完成,事务已提交");
} catch (Exception e) {
conn.rollback();
System.err.println("数据同步失败,已回滚事务");
throw e;
}
}
}
private static void loadConfig() throws Exception {
try (InputStream input = OdpsToMysqlSync.class.getClassLoader().getResourceAsStream("config.properties")) {
if (input == null) throw new RuntimeException("配置文件未找到");
config.load(input);
}
}
private static void clearTables(Connection conn) throws SQLException {
// 注意清空顺序:先清字段表再清表表(外键约束)
String[] tablesToClear = {"dacp_dge_coll_tab_field", "dacp_dge_coll_tab"};
for (String table : tablesToClear) {
try (Statement stmt = conn.createStatement()) {
// 使用TRUNCATE快速清空表(自动提交需关闭)
stmt.execute("TRUNCATE TABLE " + table);
System.out.println("已清空表: " + table);
}
}
}
private static Odps initOdpsClient() {
Account account = new AliyunAccount(config.getProperty("odps.access.id"), config.getProperty("odps.access.key"));
Odps odps = new Odps(account);
odps.setEndpoint(config.getProperty("odps.endpoint"));
odps.setDefaultProject(config.getProperty("odps.project"));
return odps;
}
private static void processTable(Connection conn, Table tbl) throws SQLException {
// 生成表ID
String tabId = tbl.getTableID();
// 提取表信息
String tabName = tbl.getName();
String modelTabName = tabName.toUpperCase();
if (modelTabName.startsWith("ODS") || modelTabName.startsWith("STG")) {
String tabLabel = tbl.getComment() != null ? tbl.getComment() : "";
String tabSchema = "";
long tabRows = tbl.getRecordNum(); // 需要确认ODPS API是否支持
String tabCapacity = formatSize(tbl.getSize()); // 假设有getSize方法
int fieldNum = tbl.getSchema().getColumns().size();
String createTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(tbl.getCreatedTime());
String dsName = config.getProperty("odps.project");
// 插入表记录
insertTable(conn, tabId, tabName, modelTabName, tabLabel, tabSchema, tabRows, tabCapacity, fieldNum, createTime, dsName);
// 处理字段
processColumns(conn, tbl, tabId, tabName, dsName, tabSchema);
}
}
private static void insertTable(Connection conn, String tabId, String tabName, String modelTabName,
String tabLabel, String tabSchema, long tabRows, String tabCapacity,
int fieldNum, String createTime, String dsName) throws SQLException {
String sql = "INSERT INTO dacp_dge_coll_tab (tab_id, tab_name, model_tab_name, tab_label, " +
"tab_schema, tab_rows, tab_capacity, field_num, create_time, ds_name, clt_log_id) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, tabId);
pstmt.setString(2, tabName);
pstmt.setString(3, modelTabName);
pstmt.setString(4, tabLabel);
pstmt.setString(5, tabSchema);
pstmt.setLong(6, tabRows);
pstmt.setString(7, tabCapacity);
pstmt.setInt(8, fieldNum);
pstmt.setString(9, createTime);
pstmt.setString(10, dsName);
pstmt.setString(11, "-1");
pstmt.executeUpdate();
}
}
private static void processColumns(Connection conn, Table tbl, String tabId, String tabName,
String dsName, String tabSchema) throws SQLException {
List<Column> columns = tbl.getSchema().getColumns();
List<Column> partitions = tbl.getSchema().getPartitionColumns();
for (int i = 0; i < columns.size(); i++) {
Column col = columns.get(i);
String fieldId = UUID.randomUUID().toString().replace("-", "");
String dataType = col.getTypeInfo().getTypeName();
String[] typeParts = dataType.split("\(");
String length = typeParts.length > 1 ? typeParts[1].replace(")", "") : "";
boolean isPartition = partitions.stream().anyMatch(p -> p.getName().equals(col.getName()));
String isnullable = col.isNullable() ? "YES" : "NO";
insertColumn(conn, fieldId, tabId, tabName, dsName, tabSchema, col, i + 1, length, isnullable, isPartition);
}
}
private static void insertColumn(Connection conn, String fieldId, String tabId, String tabName,
String dsName, String tabSchema, Column col, int pos,
String length, String isnullable, boolean isPartition) throws SQLException {
String sql = "INSERT INTO dacp_dge_coll_tab_field (field_id, tab_id, tab_name, ds_name, " +
"tab_schema, field_name, field_label, data_type, length, isnullable, " +
"field_posi, def_value, primary_key, partition_key, clt_log_id) " +
"VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, fieldId);
pstmt.setString(2, tabId);
pstmt.setString(3, tabName);
pstmt.setString(4, dsName);
pstmt.setString(5, tabSchema);
pstmt.setString(6, col.getName());
pstmt.setString(7, col.getComment() != null ? col.getComment() : "");
pstmt.setString(8, col.getTypeInfo().getTypeName());
pstmt.setString(9, length);
pstmt.setString(10, isnullable);
pstmt.setInt(11, pos);
pstmt.setString(12, col.getDefaultValue() != null ? col.getDefaultValue() : "");
pstmt.setString(13, "NO"); // ODPS无主键概念
pstmt.setString(14, isPartition ? "YES" : "NO");
pstmt.setString(15, "-1");
pstmt.executeUpdate();
}
}
private static String formatSize(long bytes) {
if (bytes < 1024) return bytes + " B";
if (bytes < 1024 * 1024) return bytes / 1024 + " KB";
if (bytes < 1024 * 1024 * 1024) return bytes / 1024 / 1024 + " MB";
// 实现字节到友好格式的转换
return String.format("%d GB", bytes / 1024 / 1024 / 1024);
}
}数据入库
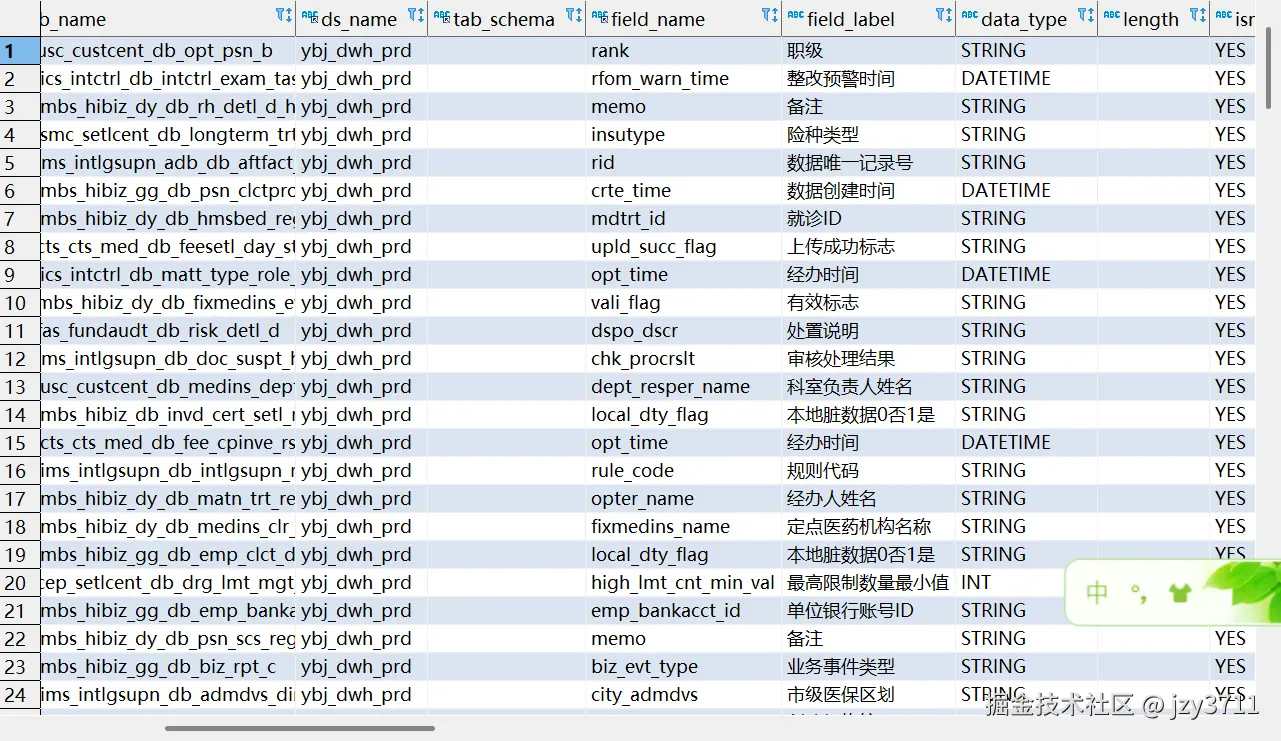
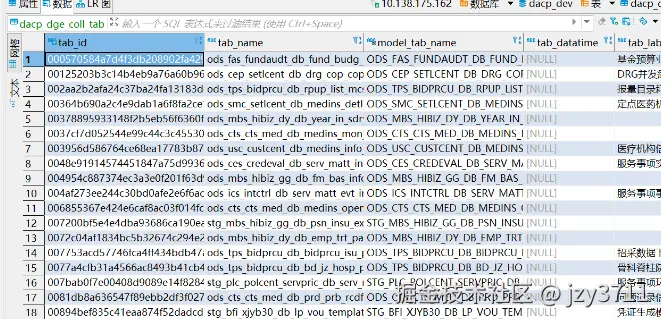
总结
AI还是一个工具,想要全靠AI完成code,我认为还是需要很多限定,比如指定编码规范,使用使用java语言,利用spring boot架构等等,我感觉市面上所有的AI不适合直接拿来用code,比如数据库模型的设置要符合默写规范比如国家的矿山规范,医保规范等等,AI只是按照要求完成,没办法使用时这规范,一个好的AI编程一定是要规范的。因为代码是一个逻辑性和规范性很强的东西,不是像AI发散思维完成的。
一、AI编程工具的现状与局限性
- 规范理解瓶颈:
- 现有AI(如GitHub Copilot、CodeWhisperer)主要基于通用代码库训练,对行业特殊规范(如医保DRG分组规则、矿山安全监测数据标准)缺乏专业认知
- 难以处理需要领域知识的设计约束(如医疗系统的HIPAA合规性、金融系统的SOX审计要求)
- 架构适配困境:
- 虽然能生成Spring Boot基础代码,但对复杂架构模式(Clean Architecture/DDD)的连贯性实现不足
- 微服务间的通信规范(如统一异常处理格式)容易在跨服务调用时断裂
- 数据建模缺陷:
- 无法自动应用特定行业的数据标准(如HL7医疗数据标准、PIDX石油数据交换规范)
- 对数据安全规范(GDPR/等保2.0)的字段级实现缺乏敏感性
二、规范驱动型AI编程的演进路径
- 知识注入技术:
python
复制
ruby
# 示例:将行业规范转化为可执行的规则约束
class MedicalInsuranceRuleEngine:
def __init__(self):
self.rules = self.load_rules("config/medical_insurance_spec.yaml")
def validate_model(self, entity):
for rule in self.rules['entity_rules']:
if not eval(rule['condition']):
raise ValidationError(rule['error_message'])- 混合式代码生成架构:
复制
css
[领域规范知识库] --> [规则引擎]
↓
[用户需求] → [AI代码生成] → [规范合规性校验] → [修正建议]
↑
[企业架构约束] ← [上下文感知]- 渐进式规范学习:
- 基于RAG(检索增强生成)技术实时获取最新规范
- 微调时注入企业私有规范文档(如《医保结算系统开发白皮书V3.2》)
三、面向行业的解决方案设计
- 规范标准化层:
java
复制
less
// 医保目录用药规范约束示例
@DrugSpecification(name="医保甲类药品")
public class MedicalInsuranceDrugSpec {
@Constraint(rule="dailyDosage <= maxDosage")
@Constraint(rule="ingredient in nationalDrugCatalog")
public void validate(DrugPrescription prescription) {
// 自动生成的校验逻辑
}
}- 架构模式引导:
prompt
复制
markdown
# 使用特定架构模板的提示词
"基于Spring Boot 3.x实现医保结算模块,要求:
1. 符合卫健委《电子病历系统功能规范》
2. 采用CQRS模式分离读写操作
3. 领域模型需包含:参保人、诊疗项目、费用明细等聚合根
请生成领域层基础代码"- 合规性验证流水线:
mermaid
复制
css
graph LR
A[AI生成代码] --> B{静态分析}
B -->|通过| C[单元测试]
B -->|拒绝| D[规则违反报告]
C --> E[行业规范测试套件]
E -->|通过| F[部署就绪]
E -->|失败| G[自动修正建议]四、未来突破方向
- 规范动态感知:
- 通过IDE插件实时获取企业最新编码规范
- 与Confluence等知识库系统深度集成
- 多模态规范理解:
- 解析PDF/扫描件中的表格、流程图等非结构化规范
- 自动生成UML图与代码实现的双向验证
- 可信代码生成:
- 基于形式化验证的代码正确性证明
- 区块链存证的规范符合性审计追踪
当前技术边界正在从"代码补全"向"规范感知型智能开发"演进。要实现真正可用的AI编程助手,需要构建"规范知识图谱+领域模型+架构约束"的三位一体系统。这不仅是技术挑战,更是需要行业专家深度参与的领域工程问题。未来的AI编程工具可能会演变为"规范执行系统",而开发者将更多承担"规范定义者"和"质量守门人"的角色。