统计子矩阵
给定一个 N×M 的矩阵 A,请你统计有多少个子矩阵 (最小 1×1,最大 N×M) 满足子矩阵中所有数的和不超过给定的整数 K?
输入格式
第一行包含三个整数 N,M 和 K。
之后 N 行每行包含 M 个整数,代表矩阵 A。
输出格式
一个整数代表答案。
数据范围
对于 30% 的数据,N,M≤20,
对于 70%70% 的数据,N,M≤100,
对于 100%100% 的数据,1≤N,M≤500;0≤ A i j A_{ij} Aij≤1000;1≤K≤2.5× 1 0 8 10^8 108。
输入样例:
3 4 10
1 2 3 4
5 6 7 8
9 10 11 12输出样例:
19样例解释
满足条件的子矩阵一共有 19,包含:
- 大小为 1×1 的有 10 个。
- 大小为 1×2 的有 3 个。
- 大小为 1×3 的有 2 个。
- 大小为 1×4 的有 1 个。
- 大小为2×1 的有 3 个。
【思路分析】这道题如果用二维前缀和加枚举矩阵左上角的x,y坐标和矩阵右下角的x,y坐标的话,无法通过所有的样例,所以要想办法优化掉一层循环
我们不妨通过i,j限制子矩阵的上界和下界
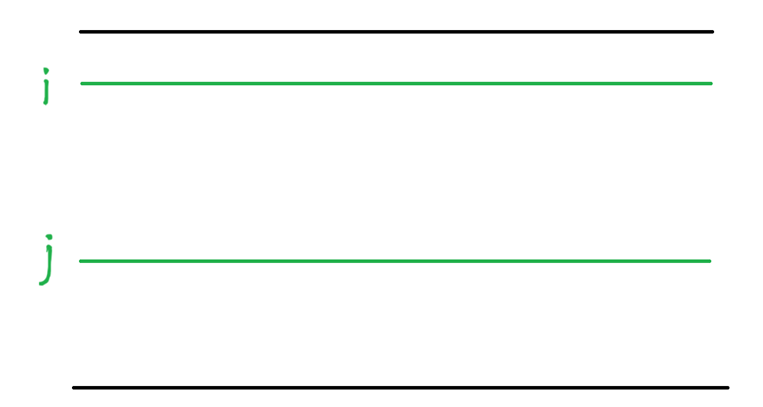
然后在上下界内的一列看做是一个元素,通过一位前缀和的方式计算
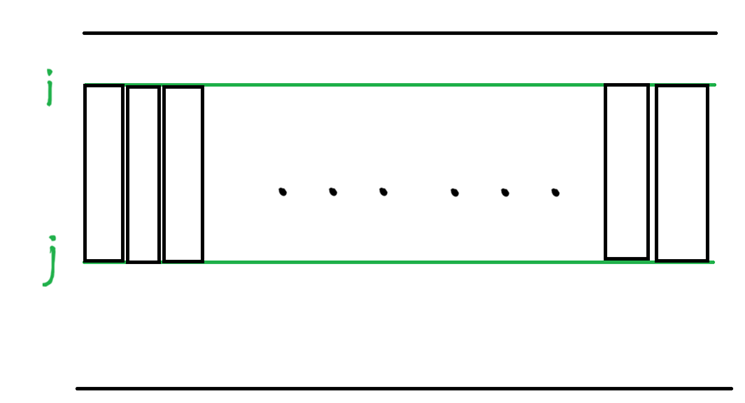
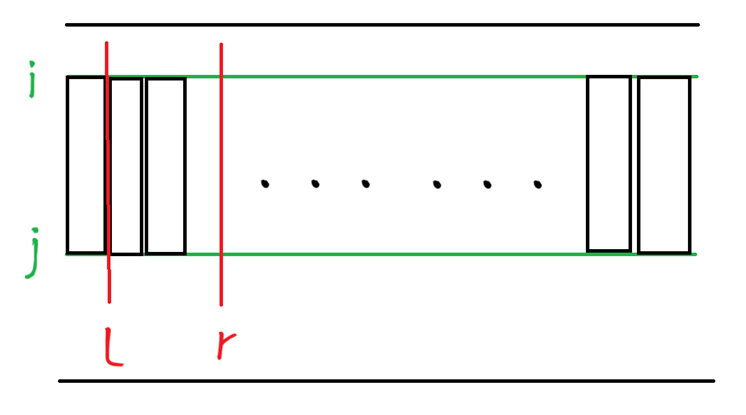
因为0≤ A i j A_{ij} Aij≤1000,所以可以通过l r两个指针限制矩阵的左右边界,固定r右边界,l向左移动,区间内子矩阵值减少,l向右移动,区间内子矩阵值增大
java
import java.io.*;
import java.util.*;
public class Main {
static final int N = 510;
static long[][] s = new long[N][N];
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] row1 = br.readLine().split(" ");
int n = Integer.parseInt(row1[0]);
int m = Integer.parseInt(row1[1]);
int k = Integer.parseInt(row1[2]);
//读入数据处理前缀和
for(int i = 1; i <= n; i++) {
String[] data = br.readLine().split(" ");
for(int j = 1; j <= m; j++) {
s[i][j] = Integer.parseInt(data[j - 1]);
s[i][j] += s[i - 1][j];
}
}
long res = 0;
//枚举上边界和下边界
for(int i = 1; i <= n; i++) {
for(int j = i; j <= n; j++) {
//枚举左右边界
for(int l = 1, r= 1, sum = 0; r <= m; r++) {
sum += s[j][r] - s[i - 1][r];
while(sum > k) {
sum -= s[j][l] - s[i - 1][l];
l++;
}
res += r - l + 1;
}
}
}
System.out.println(res);
br.close();
}
}